[Python人工智能] 二十六.基于BiLSTM-CRF的医学命名实体识别研究(上)数据预处理

这篇文章写得很冗余,但是我相信你如果真的看完,并且按照我的代码和逻辑进行分析,对您以后的数据预处理和命名实体识别都有帮助,只有真正对这些复杂的文本进行NLP处理后,您才能适应更多的真实环境,坚持!毕竟我写的时候也看了20多小时的视频,又写了20多个小时,别抱怨,加油~
本专栏主要结合作者之前的博客、AI经验和相关视频及论文介绍,后面随着深入会讲解更多的Python人工智能案例及应用。基础性文章,希望对您有所帮助,如果文章中存在错误或不足之处,还请海涵!作者作为人工智能的菜鸟,希望大家能与我在这一笔一划的博客中成长起来。该专栏也会用心撰写,望对得起读者。如果有问题随时私聊我,只望您能从这个系列中学到知识,一起加油喔~
- Keras下载地址:https://github.com/eastmountyxz/AI-for-Keras
- TensorFlow下载地址:https://github.com/eastmountyxz/AI-for-TensorFlow
文章目录
华为云社区前文赏析:
- [Python人工智能] 一.TensorFlow2.0环境搭建及神经网络入门
- [Python人工智能] 二.TensorFlow基础及一元直线预测案例
- [Python人工智能] 三.TensorFlow基础之Session、变量、传入值和激励函数
- [Python人工智能] 四.TensorFlow创建回归神经网络及Optimizer优化器
- [Python人工智能] 五.Tensorboard可视化基本用法及绘制整个神经网络
- [Python人工智能] 六.TensorFlow实现分类学习及MNIST手写体识别案例
- [Python人工智能] 七.什么是过拟合及dropout解决神经网络中的过拟合问题
- [Python人工智能] 八.卷积神经网络CNN原理详解及TensorFlow编写CNN
- [Python人工智能] 九.gensim词向量Word2Vec安装及《庆余年》中文短文本相似度计算
- [Python人工智能] 十.Tensorflow+Opencv实现CNN自定义图像分类及与KNN图像分类对比
- [Python人工智能] 十一.Tensorflow如何保存神经网络参数
- [Python人工智能] 十二.循环神经网络RNN和LSTM原理详解及TensorFlow编写RNN分类案例
- [Python人工智能] 十三.如何评价神经网络、loss曲线图绘制、图像分类案例的F值计算
- [Python人工智能] 十四.循环神经网络LSTM RNN回归案例之sin曲线预测 丨【百变AI秀】
- [Python人工智能] 十五.无监督学习Autoencoder原理及聚类可视化案例详解
- [Python人工智能] 十六.Keras环境搭建、入门基础及回归神经网络案例
- [Python人工智能] 十七.Keras搭建分类神经网络及MNIST数字图像案例分析
- [Python人工智能] 十八.Keras搭建卷积神经网络及CNN原理详解
- [Python人工智能] 十九.Keras搭建循环神经网络分类案例及RNN原理详解
- [Python人工智能] 二十.基于Keras+RNN的文本分类vs基于传统机器学习的文本分类
- [Python人工智能] 二十一.Word2Vec+CNN中文文本分类详解及与机器学习算法对比
- [Python人工智能] 二十二.基于大连理工情感词典的情感分析和情绪计算
- [Python人工智能] 二十三.基于机器学习和TFIDF的情感分类(含详细的NLP数据清洗)
- [Python人工智能] 二十四.易学智能GPU搭建Keras环境实现LSTM恶意URL请求分类
- [Python人工智能] 二十六.基于BiLSTM-CRF的医学命名实体识别研究(上)数据预处理
实体是知识图谱最重要的组成,命名实体识别(Named Entity Recognition,NER)对于知识图谱构建具有很重要意义。命名实体是一个词或短语,它可以在具有相似属性的一组事物中清楚地标识出某一个事物。命名实体识别(NER)则是指在文本中定位命名实体的边界并分类到预定义类型集合的过程。
这篇文章将详细介绍医学实体识别的过程,其数据预处理极其复杂,但值得大家去学习。下面我们先简单回顾命名实体的几个问题。
1.什么是实体?
实体是一个认知概念,指代世界上存在的某个特定事物。实体在文本中通常有不同的表示形式,或者不同的提及方式。命名实体可以理解为有文本标识的实体。实体在文本中的表示形式通常被称作实体指代(Mention,或者直接被称为指代)。比如周杰伦,在文本中有时被称作“周董”,有时被称作“Jay Chou”。因此,实体指代是语言学层面的概念。
2.什么是命名实体识别?
命名实体识别(Named Entity Recognition,NER)就是从一段自然语言文本中找出相关实体,并标注出其位置以及类型。是信息提取、问答系统、句法分析、机器翻译等应用领域的重要基础工具,在自然语言处理技术走向实用化的过程中占有重要地位,包含行业领域专有名词,如人名、地名、公司名、机构名、日期、时间、疾病名、症状名、手术名称、软件名称等。具体可参看如下示例图:

NER的输入是一个句子对应的单词序列 s=<w1,w2,…,wn>,输出是一个三元集合,其中每个元组形式为<Is,Ie,t>,表示s中的一个命名实体,其中Is和Ie分别表示命名实体在s中的开始和结束位置,而t是实体类型。命名实体识别的作用如下:
- 识别专有名词,为文本结构化提供支持
- 主体识别,辅助句法分析
- 实体关系抽取,有利于知识推理
3.命名实体识别常用方法
可以根据各种属性划分为不同的方法,但划分大同小异。本文按照下图划分为始终类别:
- 早期方法:基于规则的方法、基于字典的方法
- 传统机器学习方法:HMM、MEMM、CRF
- 深度学习方法:RNN-CRF、CNN-CRF
- 机器方法:注意力模型、迁移学习、半监督学习

4.命名实体识别最新发展
最新的方法是注意力机制、迁移学习和半监督学习,一方面减少数据标注任务,在少量标注情况下仍然能很好地识别实体;另一方面迁移学习(Transfer Learning)旨在将从源域(通常样本丰富)学到的知识迁移到目标域(通常样本稀缺)上执行机器学习任务。常见的模型如下:
- BiLSTM网络应用于迁移学习
双向LSTM的网络可以同时捕捉正向信息和反向信息,使得对文本信息的利用更全面,效果也更好。

- BERT-BiLSTM-CRF模型
该模型在数据挖掘比赛和论文中很经典,也是非常新的一个模型,值得大家使用。

上面内容参考了肖仰华老师《知识图谱概念与技术》书籍,以及“阁下和不同风起”朋友的文章,再次感谢,也非常推荐大家去阅读这位朋友的文章,非常棒。
数据集如下图所示,它由两个文件组成
- ann文件
- txt文件

我们打开txt文件,可以看到它们是一些文本,这些文本很多是通过文字识别软件识别出来的,所以存在一些错误。

对应的ann文件如下图所示,它相当于标注数据,主要用于训练,包括:
- 标号:T1、T2、T8
- 实体类型:疾病(Disease)、检测(Test)、检测值(Test_Value)、症状(Symptom)
- 起始位置:30
- 结束位置:35
- 实体内容:2型糖尿病

换句话说,通过专家知识已经将文本中的症状、疾病、级别、检测手段等进行了标注,这些数据也是我们要提取的信息。接下来我们设计一个模型,通过算法实现实体识别,而不需要通过专家去标注。
当我们拿到这样的数据怎么去做呢?
首先我们需要把标签设计好,通过BIO对每个字打一个标签(BIO标注)。注意,我们不能拿ANN文件直接去训练,而需要标注成如下图所示的模样。每个字都对应一个标记,这些字相当于可观测序列,而这些标记是不可观测的隐状态序列(隐马尔可夫模型)。
这相当于监督学习,预测的时候就没有相应标记了,需要算法自动完成这些标记的预测。所以接下来我们需要想办法将数据标记成下图的格式。
- BIO标注法
– B表示实体起始位置,I表示实体中间位置,E表示实体结束位置
– O表示非实体标记
– DRU、ANT、DIS等表示不同类型的标记,比如症状、疾病、级别、检测手段等

注意,数据集预处理通常都很枯燥,但需要我们熟悉基本流程,这将为后续的实验提供良好的基础。同时,下面的代码会讲解得非常详细,甚至有些啰嗦,但只希望读者能学到我编写Python代码的过程,包括调试、打桩,大神可以直接看最终完整代码或github的分享。
命名实体识别是企业中常见的任务,数据标注是其基础。那么,我们怎么才能完成该标注任务呢?
首先,我们需要获取总共存在多少种实体。
遍历训练集文件夹中所有ANN文件,统计所有的命名实体种类。下面我们写代码完成这部分实验。
下面的代码是统计所有实体类型,以及各个类型的实体个数。

第一步,获取指定文件夹的文件目录。
#encoding:utf-8
import os
#----------------------------功能:获取实体类别及个数---------------------------------
def get_entities(dir):
entities = {} #字段实体类别
files = os.listdir(dir) #遍历路径
return files
#-------------------------------功能:主函数--------------------------------------
if __name__ == '__main__':
path = "data/train_data"
print(get_entities(path))
显示目录如下图所示:

接着通过split分割提取所有文件的名字,并进行去重操作,如下图所示。

第二步,获取每个ANN文件中的第二个字段,即实体类型。
#encoding:utf-8
import os
#----------------------------功能:获取实体类别及个数---------------------------------
def get_entities(dirPath):
entities = {} #字段实体类别
files = os.listdir(dirPath) #遍历路径
#获取所有文件的名字并去重 0.ann => 0
filenames = set([file.split('.')[0] for file in files])
filenames = list(filenames)
#print(filenames)
#重新构造ANN文件名并遍历文件
for filename in filenames:
path = os.path.join(dirPath, filename+".ann")
print(path)
#读文件
with open(path, 'r', encoding='utf8') as f:
for line in f.readlines():
#TAB键分割获取实体类型
name = line.split('\t')[1]
print(name)
return filenames
#-------------------------------功能:主函数--------------------------------------
if __name__ == '__main__':
path = "data/train_data"
print(get_entities(path))
输出结果如下图所示:
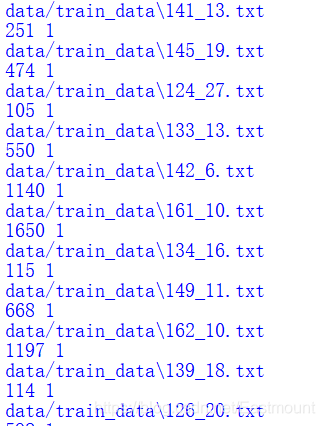
data/train_data\126_20.ann
Disease 6938 6940;6941 6945
Disease 6998 7000;7001 7005
Disease 7053 7059
Disease 7873 7879
Anatomy 7144 7148
Drug 33 37
Drug 158 162
Drug 324 328
Drug 450 454
.....
对应的126_20.ann文件如下图所示,接着我们可以从提取的字段中按照空格获取实体类别,比如Disease、Anatomy、Drug等。

第三步,通过循环判断实体是否存在,存在个数加1,否则新实体加入字典。
#encoding:utf-8
import os
#----------------------------功能:获取实体类别及个数---------------------------------
def get_entities(dirPath):
entities = {} #存储实体类别
files = os.listdir(dirPath) #遍历路径
#获取所有文件的名字并去重 0.ann => 0
filenames = set([file.split('.')[0] for file in files])
filenames = list(filenames)
#print(filenames)
#重新构造ANN文件名并遍历文件
for filename in filenames:
path = os.path.join(dirPath, filename+".ann")
print(path)
#读文件
with open(path, 'r', encoding='utf8') as f:
for line in f.readlines():
#TAB键分割获取实体类型
name = line.split('\t')[1]
#print(name)
value = name.split(' ')[0]
#print(value)
#实体加入字典并统计个数
if value in entities:
entities[value] += 1 #在实体集合中数量加1
else:
entities[value] = 1 #创建键值且值为1
#返回实体集
return entities
#-------------------------------功能:主函数--------------------------------------
if __name__ == '__main__':
path = "data/train_data"
print(get_entities(path))
输出结果如下图所示:

总共有15个实体,我们可以通过len函数计算其个数,然后每个实体包括B和I两个标注,再加上O标注,攻击31个标注。至此,我们成功获取了实体类别。
接下来我们进行实体标记,这也是深度学习或NLP领域中非常基础的知识,这段代码也非常有意思。
第一步,获取实体标记名称。
#----------------------------功能:命名实体BIO标注--------------------------------
def get_labelencoder(entities):
#排序
entities = sorted(entities.items(), key=lambda x: x[1], reverse=True)
print(entities)
#获取实体类别名称
entities = [x[0] for x in entities]
print(entities)
输出结果如下图所示,成功获取了实体类型名称,如Test、Disease、Anatomy等。

第二步,生成不同实体类型的标记,包括B起始位置和I中间位置。
#encoding:utf-8
import os
#----------------------------功能:获取实体类别及个数---------------------------------
def get_entities(dirPath):
entities = {} #存储实体类别
files = os.listdir(dirPath) #遍历路径
#获取所有文件的名字并去重 0.ann => 0
filenames = set([file.split('.')[0] for file in files])
filenames = list(filenames)
#print(filenames)
#重新构造ANN文件名并遍历文件
for filename in filenames:
path = os.path.join(dirPath, filename+".ann")
#print(path)
#读文件
with open(path, 'r', encoding='utf8') as f:
for line in f.readlines():
#TAB键分割获取实体类型
name = line.split('\t')[1]
#print(name)
value = name.split(' ')[0]
#print(value)
#实体加入字典并统计个数
if value in entities:
entities[value] += 1 #在实体集合中数量加1
else:
entities[value] = 1 #创建键值且值为1
#返回实体集
return entities
#----------------------------功能:命名实体BIO标注--------------------------------
def get_labelencoder(entities):
#排序
entities = sorted(entities.items(), key=lambda x: x[1], reverse=True)
print(entities)
#获取实体类别名称
entities = [x[0] for x in entities]
print(entities)
#标记实体
id2label = []
id2label.append('O')
#生成实体标记
for entity in entities:
id2label.append('B-'+entity)
id2label.append('I-'+entity)
#字典键值生成
label2id = {id2label[i]:i for i in range(len(id2label))}
return id2label, label2id
#-------------------------------功能:主函数--------------------------------------
if __name__ == '__main__':
path = "data/train_data"
#获取实体类别及个数
entities = get_entities(path)
print(entities)
print(len(entities))
#完成实体标记 列表 字典
#得到标签和下标的映射
label, label_dic = get_labelencoder(entities)
print(label)
print(len(label))
print(label_dic)
输出结果如下图所示,共计31个标记(15个实体类型、O标记)。

由于每个文本都由很多字符组成,比如0.ann包含了六千多个汉字,因此转换成单个字和标记后,它是一个很长的序列,这会影响深度学习模型的效果及运算速度。因此,我们需要将文本切分成短句。那么,它切割的方法是什么呢?

文本切割可以采用断句的方式实现,定义一个列表将我们要断句的地方包含。通常需要进行综合考虑,比如句号、问号、换行等断句,而逗号不执行断句等。 由于本文采用的医疗数据集是图像识别生成的,因此存在一些错误,比如“使HBA1C 。<6.5%,患者” 该部分的句号不能直接断句,否则会影响前后语义依赖。
第一步,定义分隔符并获取字符下标。
下列代码是个简单示例,能获取某些字符的前后5个字符串。
import re
#-------------------------功能:自定义分隔符文本分割------------------------------
def split_text(text):
pattern = '。|,|,|;|?'
#获取字符的下标位置
for m in re.finditer(pattern, text):
print(m)
start = m.span()[0] #标点符号位置
print(text[start])
start = m.span()[0] - 5
end = m.span()[1] + 5
print('****', text[start:end], '****')
break
#-------------------------------功能:主函数--------------------------------------
if __name__ == '__main__':
path = "data/train_data"
#自定义分割文本
text = path + "/0.txt"
print(text)
with open(text, 'r', encoding='utf8') as f:
text = f.read()
split_text(text)
输出结果如下图所示:

第二步,如果特殊字符前面是换行符情况,我们跳过该操作不分割。
#encoding:utf-8
import os
import re
#----------------------------功能:获取实体类别及个数---------------------------------
def get_entities(dirPath):
entities = {} #存储实体类别
files = os.listdir(dirPath) #遍历路径
#获取所有文件的名字并去重 0.ann => 0
filenames = set([file.split('.')[0] for file in files])
filenames = list(filenames)
#print(filenames)
#重新构造ANN文件名并遍历文件
for filename in filenames:
path = os.path.join(dirPath, filename+".ann")
#print(path)
#读文件
with open(path, 'r', encoding='utf8') as f:
for line in f.readlines():
#TAB键分割获取实体类型
name = line.split('\t')[1]
#print(name)
value = name.split(' ')[0]
#print(value)
#实体加入字典并统计个数
if value in entities:
entities[value] += 1 #在实体集合中数量加1
else:
entities[value] = 1 #创建键值且值为1
#返回实体集
return entities
#----------------------------功能:命名实体BIO标注--------------------------------
def get_labelencoder(entities):
#排序
entities = sorted(entities.items(), key=lambda x: x[1], reverse=True)
print(entities)
#获取实体类别名称
entities = [x[0] for x in entities]
print(entities)
#标记实体
id2label = []
id2label.append('O')
#生成实体标记
for entity in entities:
id2label.append('B-'+entity)
id2label.append('I-'+entity)
#字典键值生成
label2id = {id2label[i]:i for i in range(len(id2label))}
return id2label, label2id
#-------------------------功能:自定义分隔符文本分割------------------------------
def split_text(text):
pattern = '。|,|,|;|;|?|\?|\.'
#获取字符的下标位置
for m in re.finditer(pattern, text):
"""
print(m)
start = m.span()[0] #标点符号位置
print(text[start])
start = m.span()[0] - 5
end = m.span()[1] + 5
print('****', text[start:end], '****')
"""
#特殊符号下标
idx = m.span()[0]
#判断是否断句
if text[idx-1]=='\n': #当前符号前是换行符
print(path)
print('****', text[idx-20:idx+20], '****')
#-------------------------------功能:主函数--------------------------------------
if __name__ == '__main__':
dirPath = "data/train_data"
#获取实体类别及个数
entities = get_entities(dirPath)
print(entities)
print(len(entities))
#完成实体标记 列表 字典
#得到标签和下标的映射
label, label_dic = get_labelencoder(entities)
print(label)
print(len(label))
print(label_dic, '\n\n')
#遍历路径
files = os.listdir(dirPath)
filenames = set([file.split('.')[0] for file in files])
filenames = list(filenames)
for filename in filenames:
path = os.path.join(dirPath, filename+".txt") #TXT文件
#print(path)
with open(path, 'r', encoding='utf8') as f:
text = f.read()
#分割文本
split_text(text)
print("\n")
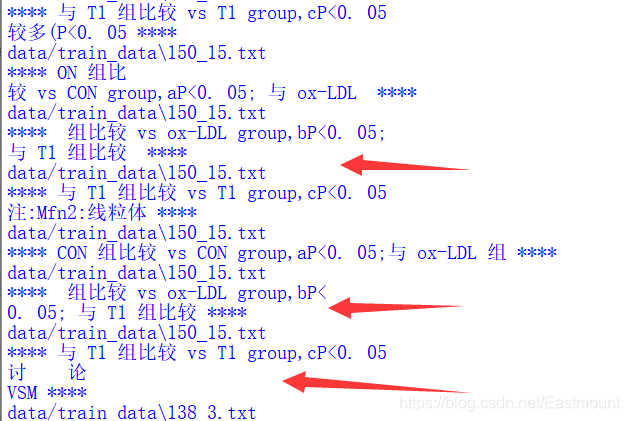
输出结果如下图所示,我们可以看到此时的结果很多被错误识别,因此不需要进行句子分割,增加continue即可。注意,因为ANN标记数据是按照原始TXT文件位置标记,我们也不能进行删除操作,当然如果你的数据集干净则预处理更简单。

第三步,如果特殊符号前后是数字的情况,此时不应该分割保留。
比如[3,5]区间、OR=1.66、支撑项目(81270913,81070640)、(0. 888,0. 975)等,注意如果数字后面是空格也需要跳过。
if text[idx-1].isdigit() and text[idx+1].isdigit():
continue
if text[idx-1].isdigit() and text[idx+1].isspace() and text[idx+2].isdigit():
continue

第四步,前后都是字母的情况,此时不应该分割保留。
if text[idx-1].islower() and text[idx+1].islower():
continue
输出如下图所示,它们同样不能切割成句子。
第五步,前后字母和数字的组合情况也不能切割。
if text[idx-1].islower() and text[idx+1].isdigit():
continue
if text[idx-1].isupper() and text[idx+1].isdigit():
continue
if text[idx-1].isdigit() and text[idx+1].islower():
continue
if text[idx-1].isdigit() and text[idx+1].isupper():
continue

第六步,增加能某些分割句子的正则表达式。
pattern2 = '\([一二三四五六七八九十零]\)|[一二三四五六七八九十零]、|'
pattern2 += '注:|附录 |表 \d|Tab \d+|\[摘要\]|\[提要\]|表\d[^。,,;;]+?\n|'
pattern2 += '图 \d|Fig \d|\[Abdtract\]|\[Summary\]|前 言|【摘要】|【关键词】|'
pattern2 += '结 果|讨 论|and |or |with |by |because of |as well as '
for m in re.finditer(pattern2, text):
idx = m.span()[0]
print('****', text[idx-20:idx+20], '****')
输出如下图所示:

第七步,如果数字序列后面包含汉字,则进行分割。
比如“2.接下来…”,同时小数不能切割,这里通过自定义函数实现。
#------------------------功能:判断字符是不是汉字-----------------------
def ischinese(char):
if '\u4e00' <=char <= '\u9fff':
return True
return False
def split_text(dirPath):
.....
#判断序列且包含汉字的分割(2.接下来...) 同时小数不进行切割
pattern3 = '\d\.' #数字+点
for m in re.finditer(pattern3, text):
idx = m.span()[0]
if ischinese(text[idx+2]): #第三个字符为中文汉字
print('****', text[idx-20:idx+20], '****')
如下图所示的结果都需要分割。

最终句子分割组合的完整代码如下所示:
- data_process_01_.py
#encoding:utf-8
import os
import re
#----------------------------功能:获取实体类别及个数---------------------------------
def get_entities(dirPath):
entities = {} #存储实体类别
files = os.listdir(dirPath) #遍历路径
#获取所有文件的名字并去重 0.ann => 0
filenames = set([file.split('.')[0] for file in files])
filenames = list(filenames)
#print(filenames)
#重新构造ANN文件名并遍历文件
for filename in filenames:
path = os.path.join(dirPath, filename+".ann")
#print(path)
#读文件
with open(path, 'r', encoding='utf8') as f:
for line in f.readlines():
#TAB键分割获取实体类型
name = line.split('\t')[1]
#print(name)
value = name.split(' ')[0]
#print(value)
#实体加入字典并统计个数
if value in entities:
entities[value] += 1 #在实体集合中数量加1
else:
entities[value] = 1 #创建键值且值为1
#返回实体集
return entities
#----------------------------功能:命名实体BIO标注--------------------------------
def get_labelencoder(entities):
#排序
entities = sorted(entities.items(), key=lambda x: x[1], reverse=True)
print(entities)
#获取实体类别名称
entities = [x[0] for x in entities]
print(entities)
#标记实体
id2label = []
id2label.append('O')
#生成实体标记
for entity in entities:
id2label.append('B-'+entity)
id2label.append('I-'+entity)
#字典键值生成
label2id = {id2label[i]:i for i in range(len(id2label))}
return id2label, label2id
#-------------------------功能:自定义分隔符文本分割------------------------------
def split_text(text):
#分割后的下标
split_index = []
#--------------------------------------------------------------------
# 文本分割
#--------------------------------------------------------------------
#第一部分 按照符号分割
pattern = '。|,|,|;|;|?|\?|\.'
#获取字符的下标位置
for m in re.finditer(pattern, text):
"""
print(m)
start = m.span()[0] #标点符号位置
print(text[start])
start = m.span()[0] - 5
end = m.span()[1] + 5
print('****', text[start:end], '****')
"""
#特殊符号下标
idx = m.span()[0]
#判断是否断句 contniue表示不能直接分割句子
if text[idx-1]=='\n': #当前符号前是换行符
continue
if text[idx-1].isdigit() and text[idx+1].isdigit(): #前后都是数字或数字+空格
continue
if text[idx-1].isdigit() and text[idx+1].isspace() and text[idx+2].isdigit():
continue
if text[idx-1].islower() and text[idx+1].islower(): #前后都是小写字母
continue
if text[idx-1].isupper() and text[idx+1].isupper(): #前后都是大写字母
continue
if text[idx-1].islower() and text[idx+1].isdigit(): #前面是小写字母 后面是数字
continue
if text[idx-1].isupper() and text[idx+1].isdigit(): #前面是大写字母 后面是数字
continue
if text[idx-1].isdigit() and text[idx+1].islower(): #前面是数字 后面是小写字母
continue
if text[idx-1].isdigit() and text[idx+1].isupper(): #前面是数字 后面是大写字母
continue
if text[idx+1] in set('.。;;,,'): #前后都是标点符号
continue
if text[idx-1].isspace() and text[idx-2].isspace() and text[idx-3].isupper():
continue #HBA1C 。两个空格+字母
if text[idx-1].isspace() and text[idx-3].isupper():
continue
#print(path)
#print('****', text[idx-20:idx+20], '****')
#将分句的下标存储至列表中 -> 标点符号后面的字符
split_index.append(idx+1)
#--------------------------------------------------------------------
#第二部分 按照自定义符号分割
#下列形式进行句子分割
pattern2 = '\([一二三四五六七八九十零]\)|[一二三四五六七八九十零]、|'
pattern2 += '注:|附录 |表 \d|Tab \d+|\[摘要\]|\[提要\]|表\d[^。,,;;]+?\n|'
pattern2 += '图 \d|Fig \d|\[Abdtract\]|\[Summary\]|前 言|【摘要】|【关键词】|'
pattern2 += '结 果|讨 论|and |or |with |by |because of |as well as '
#print(pattern2)
for m in re.finditer(pattern2, text):
idx = m.span()[0]
#print('****', text[idx-20:idx+20], '****')
#连接词位于单词中间不能分割 如 goodbye
if (text[idx:idx+2] in ['or','by'] or text[idx:idx+3]=='and' or text[idx:idx+4]=='with')\
and (text[idx-1].islower() or text[idx-1].isupper()):
continue
split_index.append(idx) #注意这里不加1 找到即分割
#--------------------------------------------------------------------
#第三部分 中文字符+数字分割
#判断序列且包含汉字的分割(2.接下来...) 同时小数不进行切割
pattern3 = '\n\d\.' #数字+点
for m in re.finditer(pattern3, text):
idx = m.span()[0]
if ischinese(text[idx+3]): #第四个字符为中文汉字 含换行
#print('****', text[idx-20:idx+20], '****')
split_index.append(idx+1)
#换行+数字+括号 (1)总体治疗原则:淤在选择降糖药物时
for m in re.finditer('\n\(\d\)', text):
idx = m.span()[0]
split_index.append(idx+1)
#--------------------------------------------------------------------
#获取句子分割下标后进行排序操作 增加第一行和最后一行
split_index = sorted(set([0, len(text)] + split_index))
split_index = list(split_index)
#print(split_index)
#计算机最大值和最小值
lens = [split_index[i+1]-split_index[i] for i in range(len(split_index)-1)]
print(max(lens), min(lens))
#输出切割的句子
#for i in range(len(split_index)-1):
# print(i, '******', text[split_index[i]:split_index[i+1]])
#---------------------------功能:判断字符是不是汉字-------------------------------
def ischinese(char):
if '\u4e00' <=char <= '\u9fff':
return True
return False
#-------------------------------功能:主函数--------------------------------------
if __name__ == '__main__':
dirPath = "data/train_data"
#获取实体类别及个数
entities = get_entities(dirPath)
print(entities)
print(len(entities))
#完成实体标记 列表 字典
#得到标签和下标的映射
label, label_dic = get_labelencoder(entities)
print(label)
print(len(label))
print(label_dic, '\n\n')
#遍历路径
files = os.listdir(dirPath)
filenames = set([file.split('.')[0] for file in files])
filenames = list(filenames)
for filename in filenames:
path = os.path.join(dirPath, filename+".txt") #TXT文件
#print(path)
with open(path, 'r', encoding='utf8') as f:
text = f.read()
#分割文本
print(path)
split_text(text)
print("\n")
输出结果如下图所示,我们可以计算分割后每个TXT文档的最长句子和最短句子。
在进行预处理工作时,我们需要不断地观察原文本输出,再进行深入的文本预处理操作,尤其是中文数据。因此,预处理是非常复杂且重要的步骤,它决定着后续实验的好坏。
上面的步骤我们可以计算出最长的句子为2393,最短的句子为1。后续命名实体识别我们准备采用 BiLSTM+CRF 实现,而BiLSTM对长文本的处理效果不理想(只能很好地处理几十个字),因此需要对句子进行长短处理。当我们将长句拆分成短句后,如果句子过短,我们还需要样本增强,多个短句进行拼接处理。最终提升预处理语料的质量。
- 长句处理:句子长度超过150进行拆分
- 删除句子中的部分空格
- 短句处理:按照字符长度5进行比较,三个句子拼接
- 查看句子最大长度和最短长度,并进行文件保存
完整代码如下:
- data_process_02_sentenceCut.py
#encoding:utf-8
import os
import re
#----------------------------功能:获取实体类别及个数---------------------------------
def get_entities(dirPath):
entities = {} #存储实体类别
files = os.listdir(dirPath) #遍历路径
#获取所有文件的名字并去重 0.ann => 0
filenames = set([file.split('.')[0] for file in files])
filenames = list(filenames)
#print(filenames)
#重新构造ANN文件名并遍历文件
for filename in filenames:
path = os.path.join(dirPath, filename+".ann")
#print(path)
#读文件
with open(path, 'r', encoding='utf8') as f:
for line in f.readlines():
#TAB键分割获取实体类型
name = line.split('\t')[1]
#print(name)
value = name.split(' ')[0]
#print(value)
#实体加入字典并统计个数
if value in entities:
entities[value] += 1 #在实体集合中数量加1
else:
entities[value] = 1 #创建键值且值为1
#返回实体集
return entities
#----------------------------功能:命名实体BIO标注--------------------------------
def get_labelencoder(entities):
#排序
entities = sorted(entities.items(), key=lambda x: x[1], reverse=True)
print(entities)
#获取实体类别名称
entities = [x[0] for x in entities]
print(entities)
#标记实体
id2label = []
id2label.append('O')
#生成实体标记
for entity in entities:
id2label.append('B-'+entity)
id2label.append('I-'+entity)
#字典键值生成
label2id = {id2label[i]:i for i in range(len(id2label))}
return id2label, label2id
#-------------------------功能:自定义分隔符文本分割------------------------------
def split_text(text, outfile):
#分割后的下标
split_index = []
#文件写入
fw = open(outfile, 'w', encoding='utf8')
#--------------------------------------------------------------------
# 文本分割
#--------------------------------------------------------------------
#第一部分 按照符号分割
pattern = '。|,|,|;|;|?|\?|\.'
#获取字符的下标位置
for m in re.finditer(pattern, text):
"""
print(m)
start = m.span()[0] #标点符号位置
print(text[start])
start = m.span()[0] - 5
end = m.span()[1] + 5
print('****', text[start:end], '****')
"""
#特殊符号下标
idx = m.span()[0]
#判断是否断句 contniue表示不能直接分割句子
if text[idx-1]=='\n': #当前符号前是换行符
continue
if text[idx-1].isdigit() and text[idx+1].isdigit(): #前后都是数字或数字+空格
continue
if text[idx-1].isdigit() and text[idx+1].isspace() and text[idx+2].isdigit():
continue
if text[idx-1].islower() and text[idx+1].islower(): #前后都是小写字母
continue
if text[idx-1].isupper() and text[idx+1].isupper(): #前后都是大写字母
continue
if text[idx-1].islower() and text[idx+1].isdigit(): #前面是小写字母 后面是数字
continue
if text[idx-1].isupper() and text[idx+1].isdigit(): #前面是大写字母 后面是数字
continue
if text[idx-1].isdigit() and text[idx+1].islower(): #前面是数字 后面是小写字母
continue
if text[idx-1].isdigit() and text[idx+1].isupper(): #前面是数字 后面是大写字母
continue
if text[idx+1] in set('.。;;,,'): #前后都是标点符号
continue
if text[idx-1].isspace() and text[idx-2].isspace() and text[idx-3].isupper():
continue #HBA1C 。两个空格+字母
if text[idx-1].isspace() and text[idx-3].isupper():
continue
#print('****', text[idx-20:idx+20], '****')
#将分句的下标存储至列表中 -> 标点符号后面的字符
split_index.append(idx+1)
#--------------------------------------------------------------------
#第二部分 按照自定义符号分割
#下列形式进行句子分割
pattern2 = '\([一二三四五六七八九十零]\)|[一二三四五六七八九十零]、|'
pattern2 += '注:|附录 |表 \d|Tab \d+|\[摘要\]|\[提要\]|表\d[^。,,;;]+?\n|'
pattern2 += '图 \d|Fig \d|\[Abdtract\]|\[Summary\]|前 言|【摘要】|【关键词】|'
pattern2 += '结 果|讨 论|and |or |with |by |because of |as well as '
#print(pattern2)
for m in re.finditer(pattern2, text):
idx = m.span()[0]
#print('****', text[idx-20:idx+20], '****')
#连接词位于单词中间不能分割 如 goodbye
if (text[idx:idx+2] in ['or','by'] or text[idx:idx+3]=='and' or text[idx:idx+4]=='with')\
and (text[idx-1].islower() or text[idx-1].isupper()):
continue
split_index.append(idx) #注意这里不加1 找到即分割
#--------------------------------------------------------------------
#第三部分 中文字符+数字分割
#判断序列且包含汉字的分割(2.接下来...) 同时小数不进行切割
pattern3 = '\n\d\.' #数字+点
for m in re.finditer(pattern3, text):
idx = m.span()[0]
if ischinese(text[idx+3]): #第四个字符为中文汉字 含换行
#print('****', text[idx-20:idx+20], '****')
split_index.append(idx+1)
#换行+数字+括号 (1)总体治疗原则:淤在选择降糖药物时
for m in re.finditer('\n\(\d\)', text):
idx = m.span()[0]
split_index.append(idx+1)
#--------------------------------------------------------------------
#获取句子分割下标后进行排序操作 增加第一行和最后一行
split_index = sorted(set([0, len(text)] + split_index))
split_index = list(split_index)
#print(split_index)
#计算机最大值和最小值
lens = [split_index[i+1]-split_index[i] for i in range(len(split_index)-1)]
#print(max(lens), min(lens))
#--------------------------------------------------------------------
# 长短句处理
#--------------------------------------------------------------------
#遍历每一个句子 (一)xxxx 分割
other_index = []
for i in range(len(split_index)-1):
begin = split_index[i]
end = split_index[i+1]
#print("-----", text[begin:end])
#print(begin, end)
if (text[begin] in '一二三四五六七八九十零') or \
(text[begin]=='(' and text[begin+1] in '一二三四五六七八九十零'):
for j in range(begin,end):
if text[j]=='\n':
other_index.append(j+1)
#补充+排序
split_index += other_index
split_index = list(sorted(set([0, len(text)] + split_index)))
#--------------------------------------------------------------------
#第一部分 长句处理:句子长度超过150进行拆分
other_index = []
for i in range(len(split_index)-1):
begin = split_index[i]
end = split_index[i+1]
other_index.append(begin)
#句子长度超过150切割 并且最短15个字符
if end-begin>150:
for j in range(begin,end):
#这一次下标位置比上一次超过15分割
if(j+1-other_index[-1])>15:
#换行分割
if text[j]=='\n':
other_index.append(j+1)
#空格+前后数字
if text[j]==' ' and text[j-1].isnumeric() and text[j+1].isnumeric():
other_index.append(j+1)
split_index += other_index
split_index = list(sorted(set([0, len(text)] + split_index)))
#--------------------------------------------------------------------
#第二部分 删除空格的句子
for i in range(1, len(split_index)-1):
idx = split_index[i]
#当前下标和上一个下标对比 如果等于空格继续比较
while idx>split_index[i-1]-1 and text[idx-1].isspace():
idx -= 1
split_index[i] = idx
split_index = list(sorted(set([0, len(text)] + split_index)))
#--------------------------------------------------------------------
#第三部分 短句处理-拼接
temp_idx = []
i = 0
while i<(len(split_index)-1):
begin = split_index[i]
end = split_index[i+1]
#先统计句子中中文字符和英文字符个数
num_ch = 0
num_en = 0
if end - begin <15:
for ch in text[begin:end]:
if ischinese(ch):
num_ch += 1
elif ch.islower() or ch.isupper():
num_en += 1
if num_ch + 0.5*num_en>5: #大于5说明长度够用
temp_idx.append(begin)
i += 1 #注意break前i加1 否则死循环
break
#长度小于等于5和后面的句子合并
if num_ch + 0.5*num_en<=5:
temp_idx.append(begin)
i += 2
else:
temp_idx.append(begin) #大于15直接添加下标
i += 1
split_index = list(sorted(set([0, len(text)] + temp_idx)))
#查看句子长度 由于存在\n换行一个字符
lens = [split_index[i+1]-split_index[i] for i in range(len(split_index)-1)][:-1] #删除最后一个换行
print(max(lens), min(lens))
#for i in range(len(split_index)-1):
# print(i, '****', text[split_index[i]:split_index[i+1]])
#存储结果
result = []
for i in range(len(split_index)-1):
result.append(text[split_index[i]:split_index[i+1]])
fw.write(text[split_index[i]:split_index[i+1]])
fw.close()
#检查:预处理后字符是否减少
s = ''
for r in result:
s += r
assert len(s)==len(text) #断言
return result
#---------------------------功能:判断字符是不是汉字-------------------------------
def ischinese(char):
if '\u4e00' <=char <= '\u9fff':
return True
return False
#-------------------------------功能:主函数--------------------------------------
if __name__ == '__main__':
dirPath = "data/train_data"
outPath = 'data/train_data_pro'
#获取实体类别及个数
entities = get_entities(dirPath)
print(entities)
print(len(entities))
#完成实体标记 列表 字典
#得到标签和下标的映射
label, label_dic = get_labelencoder(entities)
print(label)
print(len(label))
print(label_dic, '\n\n')
#遍历路径
files = os.listdir(dirPath)
filenames = set([file.split('.')[0] for file in files])
filenames = list(filenames)
for filename in filenames:
path = os.path.join(dirPath, filename+".txt") #TXT文件
outfile = os.path.join(outPath, filename+"_pro.txt")
#print(path)
with open(path, 'r', encoding='utf8') as f:
text = f.read()
#分割文本
print(path)
split_text(text, outfile)
print("\n")
输出结果如下图所示,发现句子长短逐渐均衡,最短为6,最长150。

同时,作者写入了新的文件夹,将长短句分割的文件写入新的文件夹中,如下图所示。


命名实体识别需要获取词和边界,通常有许多标记类型,比如词边界、词性、偏旁部首、拼音等特征,接下来我们新建一个文件prepare_data.py。
- prepare_data.py
第一步,将所有文本标记为O。
#encoding:utf-8
import os
import pandas as pd
from collections import Counter
from data_process import split_text
from tqdm import tqdm #进度条 pip install tqdm
#词性标注
import jieba.posseg as psg
train_dir = "train_data"
#----------------------------功能:文本预处理---------------------------------
train_dir = "train_data"
def process_text(idx, split_method=None):
"""
功能: 读取文本并切割,接着打上标记及提取词边界、词性、偏旁部首、拼音等特征
param idx: 文件的名字 不含扩展名
param split_method: 切割文本方法
return
"""
#定义字典 保存所有字的标记、边界、词性、偏旁部首、拼音等特征
data = {}
#--------------------------------------------------------------------
#获取句子
if split_method is None:
#未给文本分割函数 -> 读取文件
with open(f'data/{train_dir}/{idx}.txt', encoding='utf8') as f: #f表示文件路径
texts = f.readlines()
else:
#给出文本分割函数 -> 按函数分割
with open(f'data/{train_dir}/{idx}.txt', encoding='utf8') as f:
outfile = f'data/train_data_pro/{idx}_pro.txt'
print(outfile)
texts = f.read()
texts = split_method(texts, outfile)
#提取句子
data['word'] = texts
print(texts)
#--------------------------------------------------------------------
#获取标签
tag_list = ['O' for s in texts for x in s] #双层循环遍历每句话中的汉字
return tag_list
#-------------------------------功能:主函数--------------------------------------
if __name__ == '__main__':
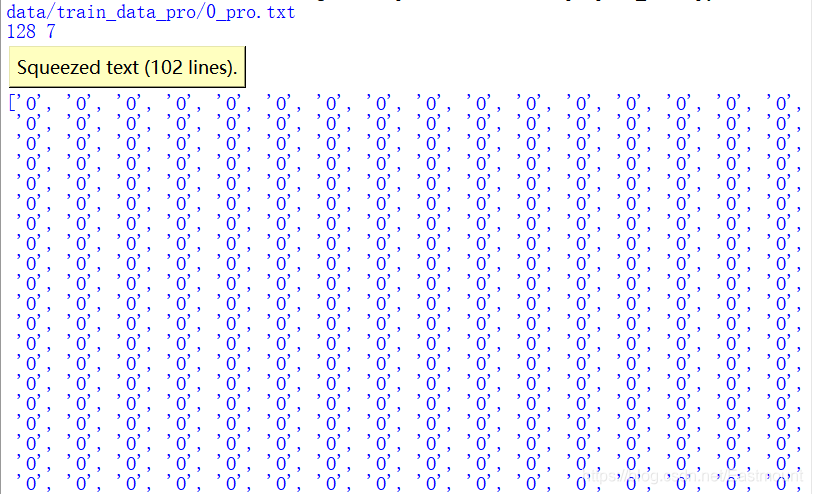
print(process_text('0',split_method=split_text))
输出结果如下图所示:
第二步,读取ANN文件获取每个实体的类型、起始位置和结束位置。

这里采用Pandas读取文件,并且分割符为Tab键,无表头,核心代码如下:
tag = pd.read_csv(f'data/{train_dir}/{idx}.ann', header=None, sep='\t')
return tag
输出结果如下图所示,我们需要提取下标为1的列。

接着我们提取实体类型、起始位置和结束位置,核心代码如下:
#读取ANN文件获取每个实体的类型、起始位置和结束位置
tag = pd.read_csv(f'data/{train_dir}/{idx}.ann', header=None, sep='\t') #Pandas读取 分隔符为tab键
for i in range(tag.shape[0]): #tag.shape[0]为行数
tag_item = tag.iloc[i][1].split(' ') #每一行的第二列 空格分割
print(tag_item)
但会存在某些实体包括两段位置区间的情况,这是因为有空格,这里我们进行简单处理,仅获取实体的起始位置和终止位置。
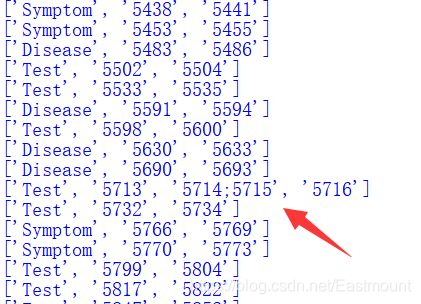
第三步,实体标记提取。
由于之前我们没有对原始TXT文件做任何修改,并且每个TXT和ANN文件的位置是一一对应的,所以接下来我们直接进行词语标记即可。如下图“2型糖尿病”实体位置为30到34。

此时的完整代码如下:
#encoding:utf-8
import os
import pandas as pd
from collections import Counter
from data_process import split_text
from tqdm import tqdm #进度条 pip install tqdm
#词性标注
import jieba.posseg as psg
train_dir = "train_data"
#----------------------------功能:文本预处理---------------------------------
train_dir = "train_data"
def process_text(idx, split_method=None):
"""
功能: 读取文本并切割,接着打上标记及提取词边界、词性、偏旁部首、拼音等特征
param idx: 文件的名字 不含扩展名
param split_method: 切割文本方法
return
"""
#定义字典 保存所有字的标记、边界、词性、偏旁部首、拼音等特征
data = {}
#--------------------------------------------------------------------
#获取句子
#--------------------------------------------------------------------
if split_method is None:
#未给文本分割函数 -> 读取文件
with open(f'data/{train_dir}/{idx}.txt', encoding='utf8') as f: #f表示文件路径
texts = f.readlines()
else:
#给出文本分割函数 -> 按函数分割
with open(f'data/{train_dir}/{idx}.txt', encoding='utf8') as f:
outfile = f'data/train_data_pro/{idx}_pro.txt'
print(outfile)
texts = f.read()
texts = split_method(texts, outfile)
#提取句子
data['word'] = texts
print(texts)
#--------------------------------------------------------------------
# 获取标签
#--------------------------------------------------------------------
#初始时将所有汉字标记为O
tag_list = ['O' for s in texts for x in s] #双层循环遍历每句话中的汉字
#读取ANN文件获取每个实体的类型、起始位置和结束位置
tag = pd.read_csv(f'data/{train_dir}/{idx}.ann', header=None, sep='\t') #Pandas读取 分隔符为tab键
#0 T1 Disease 1845 1850 1型糖尿病
for i in range(tag.shape[0]): #tag.shape[0]为行数
tag_item = tag.iloc[i][1].split(' ') #每一行的第二列 空格分割
#print(tag_item)
#存在某些实体包括两段位置区间 仅获取起始位置和结束位置
cls, start, end = tag_item[0], int(tag_item[1]), int(tag_item[-1])
#print(cls,start,end)
#对tag_list进行修改
tag_list[start] = 'B-' + cls
for j in range(start+1, end):
tag_list[j] = 'I-' + cls
return tag_list
#-------------------------------功能:主函数--------------------------------------
if __name__ == '__main__':
print(process_text('0',split_method=split_text))
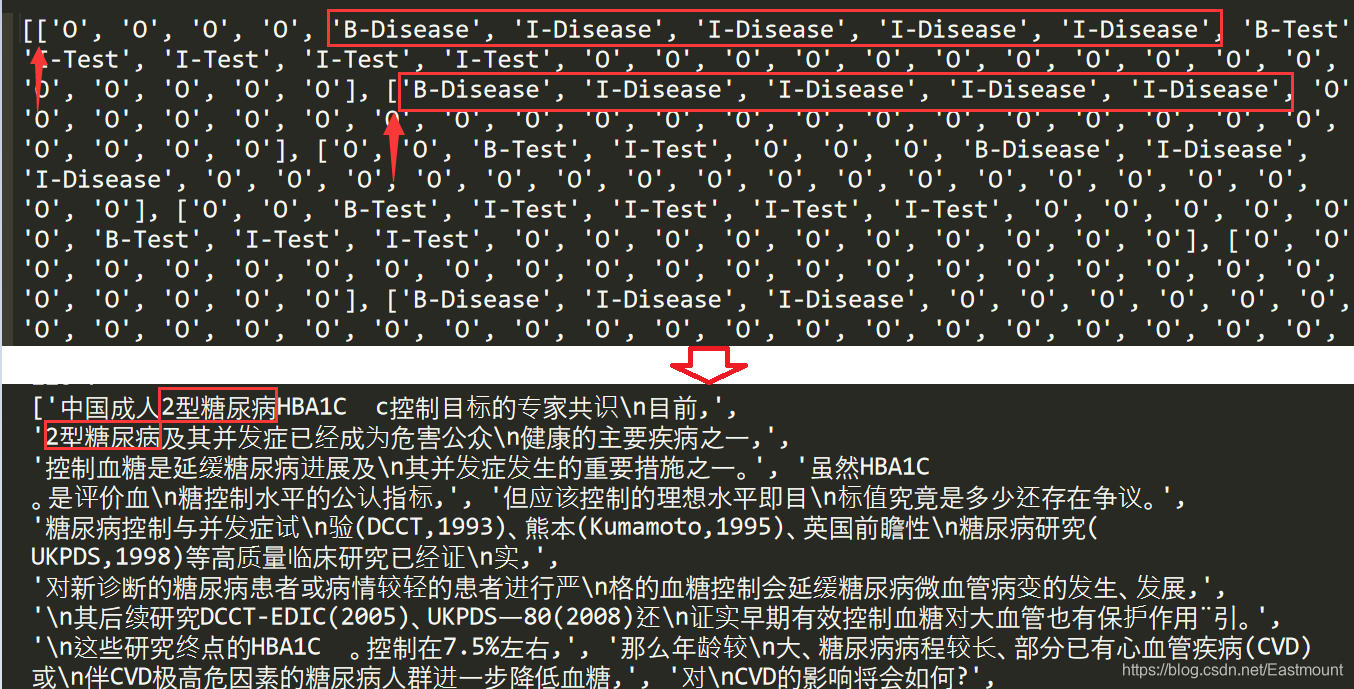
标记的位置如下图所示,发现它们是对应的。至此,我们成功提取了实体类型和位置。


第四步,将分割后的句子与标签匹配。
它将转换为两个对应的输出:
- 分割后的长短句
- 分割后长短句对应的标记数据
#--------------------------------------------------------------------
# 分割后句子匹配标签
#--------------------------------------------------------------------
tags = []
start = 0
end = 0
#遍历文本
for s in texts:
length = len(s)
end += length
tags.append(tag_list[start:end])
start += length
return tag_list, tags
输出结果如下图所示,我们可以看到第三部分“数据预处理”生成的长短句和我们的标签对应一致。
提取词性,通过jieba工具进行带词性的分词处理。
#--------------------------------------------------------------------
# 提取词性和词边界
#--------------------------------------------------------------------
#初始标记为M
word_bounds = ['M' for item in tag_list] #边界 M表示中间
word_flags = [] #词性
#分词
for text in texts:
#带词性的结巴分词
for word, flag in psg.cut(text):
if len(word)==1: #1个长度词
start = len(word_flags)
word_bounds[start] = 'S' #单个字
word_flags.append(flag)
else:
start = len(word_flags)
word_bounds[start] = 'B' #开始边界
word_flags += [flag]*len(word) #保证词性和字一一对应
end = len(word_flags) - 1
word_bounds[end] = 'E' #结束边界
#存储
bounds = []
flags = []
start = 0
end = 0
for s in texts:
length = len(s)
end += length
bounds.append(word_bounds[start:end])
flags.append(word_flags[start:end])
start += length
data['bound'] = bounds
data['flag'] = flags
#return texts, tags, bounds, flags
return texts[0], tags[0], bounds[0], flags[0]
我们输出第一行内容,看看结果。分别输出第一句话的字,第一句话的标签,第一句话的分词边界和第一句话的词性标注。
(
'中国成人2型糖尿病HBA1C c控制目标的专家共识\n目前,',
['O', 'O', 'O', 'O', 'B-Disease', 'I-Disease', 'I-Disease',
'I-Disease', 'I-Disease', 'B-Test', 'I-Test', 'I-Test',
'I-Test', 'I-Test', 'O', 'O', 'O', 'O', 'O', 'O',
'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O'],
['B', 'E', 'B', 'E', 'S', 'S', 'B', 'M', 'E',
'B', 'M', 'M', 'M', 'E', 'S', 'S', 'S', 'B',
'M', 'M', 'E', 'S', 'B', 'E', 'B', 'E', 'S', 'B', 'E', 'S'],
['ns', 'ns', 'n', 'n', 'm', 'k', 'n', 'n', 'n',
'eng', 'eng', 'eng', 'eng', 'eng', 'x', 'x',
'x', 'n', 'n', 'n', 'n', 'uj', 'n', 'n', 'n', 'n', 'x', 't', 't', 'x']
)
首先,我们安装一个工具包cnradical,它用于提取中文的偏旁部首和拼音。
- pip install cnradical
- https://github.com/wangchuan2008888/cn-radical

第二步,简单测试下这个包的功能。
from cnradical import Radical, RunOption
radical = Radical(RunOption.Radical)
pinyin = Radical(RunOption.Pinyin)
text = '你好,今天早上吃饭了吗?Eastmount'
radical_out = [radical.trans_ch(ele) for ele in text]
pinyin_out = [pinyin.trans_ch(ele) for ele in text]
print(radical_out)
print(pinyin_out)
radical_out = radical.trans_str(text)
pinyin_out = pinyin.trans_str(text)
print(radical_out)
print(pinyin_out)
输出结果如下图所示,成功获取了偏旁和拼音。

第三步,源代码进行拼音特征提取。
此时的完整代码如下所示:
#encoding:utf-8
import os
import pandas as pd
from collections import Counter
from data_process import split_text
from tqdm import tqdm #进度条 pip install tqdm
#词性标注
import jieba.posseg as psg
#获取字的偏旁和拼音
from cnradical import Radical, RunOption
train_dir = "train_data"
#----------------------------功能:文本预处理---------------------------------
train_dir = "train_data"
def process_text(idx, split_method=None):
"""
功能: 读取文本并切割,接着打上标记及提取词边界、词性、偏旁部首、拼音等特征
param idx: 文件的名字 不含扩展名
param split_method: 切割文本方法
return
"""
#定义字典 保存所有字的标记、边界、词性、偏旁部首、拼音等特征
data = {}
#--------------------------------------------------------------------
#获取句子
#--------------------------------------------------------------------
if split_method is None:
#未给文本分割函数 -> 读取文件
with open(f'data/{train_dir}/{idx}.txt', encoding='utf8') as f: #f表示文件路径
texts = f.readlines()
else:
#给出文本分割函数 -> 按函数分割
with open(f'data/{train_dir}/{idx}.txt', encoding='utf8') as f:
outfile = f'data/train_data_pro/{idx}_pro.txt'
print(outfile)
texts = f.read()
texts = split_method(texts, outfile)
#提取句子
data['word'] = texts
print(texts)
#--------------------------------------------------------------------
# 获取标签
#--------------------------------------------------------------------
#初始时将所有汉字标记为O
tag_list = ['O' for s in texts for x in s] #双层循环遍历每句话中的汉字
#读取ANN文件获取每个实体的类型、起始位置和结束位置
tag = pd.read_csv(f'data/{train_dir}/{idx}.ann', header=None, sep='\t') #Pandas读取 分隔符为tab键
#0 T1 Disease 1845 1850 1型糖尿病
for i in range(tag.shape[0]): #tag.shape[0]为行数
tag_item = tag.iloc[i][1].split(' ') #每一行的第二列 空格分割
#print(tag_item)
#存在某些实体包括两段位置区间 仅获取起始位置和结束位置
cls, start, end = tag_item[0], int(tag_item[1]), int(tag_item[-1])
#print(cls,start,end)
#对tag_list进行修改
tag_list[start] = 'B-' + cls
for j in range(start+1, end):
tag_list[j] = 'I-' + cls
#断言 两个长度不一致报错
assert len([x for s in texts for x in s])==len(tag_list)
#print(len([x for s in texts for x in s]))
#print(len(tag_list))
#--------------------------------------------------------------------
# 分割后句子匹配标签
#--------------------------------------------------------------------
tags = []
start = 0
end = 0
#遍历文本
for s in texts:
length = len(s)
end += length
tags.append(tag_list[start:end])
start += length
print(len(tags))
#标签数据存储至字典中
data['label'] = tags
#--------------------------------------------------------------------
# 提取词性和词边界
#--------------------------------------------------------------------
#初始标记为M
word_bounds = ['M' for item in tag_list] #边界 M表示中间
word_flags = [] #词性
#分词
for text in texts:
#带词性的结巴分词
for word, flag in psg.cut(text):
if len(word)==1: #1个长度词
start = len(word_flags)
word_bounds[start] = 'S' #单个字
word_flags.append(flag)
else:
start = len(word_flags)
word_bounds[start] = 'B' #开始边界
word_flags += [flag]*len(word) #保证词性和字一一对应
end = len(word_flags) - 1
word_bounds[end] = 'E' #结束边界
#存储
bounds = []
flags = []
start = 0
end = 0
for s in texts:
length = len(s)
end += length
bounds.append(word_bounds[start:end])
flags.append(word_flags[start:end])
start += length
data['bound'] = bounds
data['flag'] = flags
#--------------------------------------------------------------------
# 获取拼音特征
#--------------------------------------------------------------------
radical = Radical(RunOption.Radical) #提取偏旁部首
pinyin = Radical(RunOption.Pinyin) #提取拼音
#提取拼音和偏旁 None用特殊符号替代
radical_out = [[radical.trans_ch(x) if radical.trans_ch(x) is not None else 'PAD' for x in s] for s in texts]
pinyin_out = [[pinyin.trans_ch(x) if pinyin.trans_ch(x) is not None else 'PAD' for x in s] for s in texts]
#赋值
data['radical'] = radical_out
data['pinyin'] = pinyin_out
#return texts, tags, bounds, flags
return texts[0], tags[0], bounds[0], flags[0], radical_out[0], pinyin_out[0]
#-------------------------------功能:主函数--------------------------------------
if __name__ == '__main__':
print(process_text('0',split_method=split_text)
输出结果如下:
('中国成人2型糖尿病HBA1C c控制目标的专家共识\n目前,',
['O', 'O', 'O', 'O', 'B-Disease', 'I-Disease', 'I-Disease', 'I-Disease', 'I-Disease',
'B-Test', 'I-Test', 'I-Test', 'I-Test', 'I-Test', 'O', 'O', 'O',
'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O'],
['B', 'E', 'B', 'E', 'S', 'S', 'B', 'M', 'E', 'B', 'M',
'M', 'M', 'E', 'S', 'S', 'S', 'B', 'M', 'M', 'E', 'S',
'B', 'E', 'B', 'E', 'S', 'B', 'E', 'S'],
['ns', 'ns', 'n', 'n', 'm', 'k', 'n', 'n', 'n', 'eng',
'eng', 'eng', 'eng', 'eng', 'x', 'x', 'x', 'n', 'n',
'n', 'n', 'uj', 'n', 'n', 'n', 'n', 'x', 't', 't', 'x'],
['丨', '囗', '戈', '人', 'PAD', '土', '米', '尸', '疒', 'PAD',
'PAD', 'PAD', 'PAD', 'PAD', 'PAD', 'PAD', 'PAD', '扌', '刂',
'目', '木', '白', '一', '宀', '八', '讠', 'PAD', '目', '刂', 'PAD'],
['zhōng', 'guó', 'chéng', 'rén', 'PAD', 'xíng', 'táng', 'niào', 'bìng', 'PAD',
'PAD', 'PAD', 'PAD', 'PAD', 'PAD', 'PAD', 'PAD', 'kòng', 'zhì', 'mù', 'biāo',
'dí', 'zhuān', 'jiā', 'gòng', 'shí', 'PAD', 'mù', 'qián', 'PAD'])
第一步,获取样本数量并按照每个字进行标记。比如“中”对应的标签、词性、偏旁、拼音等。
#--------------------------------------------------------------------
# 存储数据
#--------------------------------------------------------------------
#获取样本数量
num_samples = len(texts) #行数
num_col = len(data.keys()) #列数 字典自定义类别数
print(num_samples)
print(num_col)
dataset = []
for i in range(num_samples):
records = list(zip(*[list(v[i]) for v in data.values()])) #压缩
records = list(zip(*[list(v[0]) for v in data.values()]))
for r in records:
print(r)
#return texts, tags, bounds, flags
#return texts[0], tags[0], bounds[0], flags[0], radical_out[0], pinyin_out[0]
注意,zip这里不加星号表示压缩,加星号(*)表示解压。第一行语句最终输出结果如下图所示。

第二步,依次处理不同行数据并进行存储。
每输出一句话,均增加一行sep,表示换行隔开处理。

核心代码如下所示:
#--------------------------------------------------------------------
# 存储数据
#--------------------------------------------------------------------
#获取样本数量
num_samples = len(texts) #行数
num_col = len(data.keys()) #列数 字典自定义类别数 6
print(num_samples)
print(num_col)
dataset = []
for i in range(num_samples):
records = list(zip(*[list(v[i]) for v in data.values()])) #压缩
dataset += records+[['sep']*num_col] #每处理一句话sep分割
#records = list(zip(*[list(v[0]) for v in data.values()]))
#for r in records:
# print(r)
#最后一行sep删除
dataset = dataset[:-1]
#转换成dataframe 增加表头
dataset = pd.DataFrame(dataset,columns=data.keys())
#保存文件 测试集 训练集
save_path = f'data/prepare/{split_name}/{idx}.csv'
dataset.to_csv(save_path,index=False,encoding='utf-8')
#--------------------------------------------------------------------
# 处理换行符 w表示一个字
#--------------------------------------------------------------------
def clean_word(w):
if w=='\n':
return 'LB'
if w in [' ','\t','\u2003']: #中文空格\u2003
return 'SPACE'
if w.isdigit(): #将所有数字转换为一种符号 数字训练会造成干扰
return 'NUM'
return w
#对dataframe应用函数
dataset['word'] = dataset['word'].apply(clean_word)
#存储数据
dataset.to_csv(save_path,index=False,encoding='utf-8')
前面都是针对某个txt文件进行的数据预处理,接下来我们自定义函数对所有文本进行处理操作。核心代码如下:
#----------------------------功能:预处理所有文本---------------------------------
def multi_process(split_method=None,train_ratio=0.8):
"""
功能: 对所有文本尽心预处理操作
param split_method: 切割文本方法
param train_ratio: 训练集和测试集划分比例
return
"""
#删除目录
if os.path.exists('data/prepare/'):
shutil.rmtree('data/prepare/')
#创建目录
if not os.path.exists('data/prepare/train/'):
os.makedirs('data/prepare/train/')
os.makedirs('data/prepare/test/')
#获取所有文件名
idxs = set([file.split('.')[0] for file in os.listdir('data/'+train_dir)])
idxs = list(idxs)
#随机划分训练集和测试集
shuffle(idxs) #打乱顺序
index = int(len(idxs)*train_ratio) #获取训练集的截止下标
#获取训练集和测试集文件名集合
train_ids = idxs[:index]
test_ids = idxs[index:]
#--------------------------------------------------------------------
# 引入多进程
#--------------------------------------------------------------------
#线程池方式调用
import multiprocessing as mp
num_cpus = mp.cpu_count() #获取机器CPU的个数
pool = mp.Pool(num_cpus)
results = []
#训练集处理
for idx in train_ids:
result = pool.apply_async(process_text, args=(idx,split_method,'train'))
results.append(result)
#测试集处理
for idx in test_ids:
result = pool.apply_async(process_text, args=(idx,split_method,'test'))
results.append(result)
#关闭进程池
pool.close()
pool.join()
[r.get for r in results]
#-------------------------------功能:主函数--------------------------------------
if __name__ == '__main__':
#print(process_text('0',split_method=split_text,split_name='train'))
multi_process(split_text)
输出结果如下图所示,训练集290个文件,测试集73个文件。我们可以看到“2型糖尿病”和“HBA1C”被成功标记,但是数字被转换成了NUM,后面我们可以去原文中替换出来即可。
- 2型糖尿病:Disease
- HBA1C:Test

完整代码如下所示:
#encoding:utf-8
import os
import re
#----------------------------功能:获取实体类别及个数---------------------------------
def get_entities(dirPath):
entities = {} #存储实体类别
files = os.listdir(dirPath) #遍历路径
#获取所有文件的名字并去重 0.ann => 0
filenames = set([file.split('.')[0] for file in files])
filenames = list(filenames)
#print(filenames)
#重新构造ANN文件名并遍历文件
for filename in filenames:
path = os.path.join(dirPath, filename+".ann")
#print(path)
#读文件
with open(path, 'r', encoding='utf8') as f:
for line in f.readlines():
#TAB键分割获取实体类型
name = line.split('\t')[1]
#print(name)
value = name.split(' ')[0]
#print(value)
#实体加入字典并统计个数
if value in entities:
entities[value] += 1 #在实体集合中数量加1
else:
entities[value] = 1 #创建键值且值为1
#返回实体集
return entities
#----------------------------功能:命名实体BIO标注--------------------------------
def get_labelencoder(entities):
#排序
entities = sorted(entities.items(), key=lambda x: x[1], reverse=True)
print(entities)
#获取实体类别名称
entities = [x[0] for x in entities]
print(entities)
#标记实体
id2label = []
id2label.append('O')
#生成实体标记
for entity in entities:
id2label.append('B-'+entity)
id2label.append('I-'+entity)
#字典键值生成
label2id = {id2label[i]:i for i in range(len(id2label))}
return id2label, label2id
#-------------------------功能:自定义分隔符文本分割------------------------------
def split_text(text, outfile):
#分割后的下标
split_index = []
#文件写入
fw = open(outfile, 'w', encoding='utf8')
#--------------------------------------------------------------------
# 文本分割
#--------------------------------------------------------------------
#第一部分 按照符号分割
pattern = '。|,|,|;|;|?|\?|\.'
#获取字符的下标位置
for m in re.finditer(pattern, text):
"""
print(m)
start = m.span()[0] #标点符号位置
print(text[start])
start = m.span()[0] - 5
end = m.span()[1] + 5
print('****', text[start:end], '****')
"""
#特殊符号下标
idx = m.span()[0]
#判断是否断句 contniue表示不能直接分割句子
if text[idx-1]=='\n': #当前符号前是换行符
continue
if text[idx-1].isdigit() and text[idx+1].isdigit(): #前后都是数字或数字+空格
continue
if text[idx-1].isdigit() and text[idx+1].isspace() and text[idx+2].isdigit():
continue
if text[idx-1].islower() and text[idx+1].islower(): #前后都是小写字母
continue
if text[idx-1].isupper() and text[idx+1].isupper(): #前后都是大写字母
continue
if text[idx-1].islower() and text[idx+1].isdigit(): #前面是小写字母 后面是数字
continue
if text[idx-1].isupper() and text[idx+1].isdigit(): #前面是大写字母 后面是数字
continue
if text[idx-1].isdigit() and text[idx+1].islower(): #前面是数字 后面是小写字母
continue
if text[idx-1].isdigit() and text[idx+1].isupper(): #前面是数字 后面是大写字母
continue
if text[idx+1] in set('.。;;,,'): #前后都是标点符号
continue
if text[idx-1].isspace() and text[idx-2].isspace() and text[idx-3].isupper():
continue #HBA1C 。两个空格+字母
if text[idx-1].isspace() and text[idx-3].isupper():
continue
#print('****', text[idx-20:idx+20], '****')
#将分句的下标存储至列表中 -> 标点符号后面的字符
split_index.append(idx+1)
#--------------------------------------------------------------------
#第二部分 按照自定义符号分割
#下列形式进行句子分割
pattern2 = '\([一二三四五六七八九十零]\)|[一二三四五六七八九十零]、|'
pattern2 += '注:|附录 |表 \d|Tab \d+|\[摘要\]|\[提要\]|表\d[^。,,;;]+?\n|'
pattern2 += '图 \d|Fig \d|\[Abdtract\]|\[Summary\]|前 言|【摘要】|【关键词】|'
pattern2 += '结 果|讨 论|and |or |with |by |because of |as well as '
#print(pattern2)
for m in re.finditer(pattern2, text):
idx = m.span()[0]
#print('****', text[idx-20:idx+20], '****')
#连接词位于单词中间不能分割 如 goodbye
if (text[idx:idx+2] in ['or','by'] or text[idx:idx+3]=='and' or text[idx:idx+4]=='with')\
and (text[idx-1].islower() or text[idx-1].isupper()):
continue
split_index.append(idx) #注意这里不加1 找到即分割
#--------------------------------------------------------------------
#第三部分 中文字符+数字分割
#判断序列且包含汉字的分割(2.接下来...) 同时小数不进行切割
pattern3 = '\n\d\.' #数字+点
for m in re.finditer(pattern3, text):
idx = m.span()[0]
if ischinese(text[idx+3]): #第四个字符为中文汉字 含换行
#print('****', text[idx-20:idx+20], '****')
split_index.append(idx+1)
#换行+数字+括号 (1)总体治疗原则:淤在选择降糖药物时
for m in re.finditer('\n\(\d\)', text):
idx = m.span()[0]
split_index.append(idx+1)
#--------------------------------------------------------------------
#获取句子分割下标后进行排序操作 增加第一行和最后一行
split_index = sorted(set([0, len(text)] + split_index))
split_index = list(split_index)
#print(split_index)
#计算机最大值和最小值
lens = [split_index[i+1]-split_index[i] for i in range(len(split_index)-1)]
#print(max(lens), min(lens))
#--------------------------------------------------------------------
# 长短句处理
#--------------------------------------------------------------------
#遍历每一个句子 (一)xxxx 分割
other_index = []
for i in range(len(split_index)-1):
begin = split_index[i]
end = split_index[i+1]
#print("-----", text[begin:end])
#print(begin, end)
if (text[begin] in '一二三四五六七八九十零') or \
(text[begin]=='(' and text[begin+1] in '一二三四五六七八九十零'):
for j in range(begin,end):
if text[j]=='\n':
other_index.append(j+1)
#补充+排序
split_index += other_index
split_index = list(sorted(set([0, len(text)] + split_index)))
#--------------------------------------------------------------------
#第一部分 长句处理:句子长度超过150进行拆分
other_index = []
for i in range(len(split_index)-1):
begin = split_index[i]
end = split_index[i+1]
other_index.append(begin)
#句子长度超过150切割 并且最短15个字符
if end-begin>150:
for j in range(begin,end):
#这一次下标位置比上一次超过15分割
if(j+1-other_index[-1])>15:
#换行分割
if text[j]=='\n':
other_index.append(j+1)
#空格+前后数字
if text[j]==' ' and text[j-1].isnumeric() and text[j+1].isnumeric():
other_index.append(j+1)
split_index += other_index
split_index = list(sorted(set([0, len(text)] + split_index)))
#--------------------------------------------------------------------
#第二部分 删除空格的句子
for i in range(1, len(split_index)-1):
idx = split_index[i]
#当前下标和上一个下标对比 如果等于空格继续比较
while idx>split_index[i-1]-1 and text[idx-1].isspace():
idx -= 1
split_index[i] = idx
split_index = list(sorted(set([0, len(text)] + split_index)))
#--------------------------------------------------------------------
#第三部分 短句处理-拼接
temp_idx = []
i = 0
while i<(len(split_index)-1):
begin = split_index[i]
end = split_index[i+1]
#先统计句子中中文字符和英文字符个数
num_ch = 0
num_en = 0
if end - begin <15:
for ch in text[begin:end]:
if ischinese(ch):
num_ch += 1
elif ch.islower() or ch.isupper():
num_en += 1
if num_ch + 0.5*num_en>5: #大于5说明长度够用
temp_idx.append(begin)
i += 1 #注意break前i加1 否则死循环
break
#长度小于等于5和后面的句子合并
if num_ch + 0.5*num_en<=5:
temp_idx.append(begin)
i += 2
else:
temp_idx.append(begin) #大于15直接添加下标
i += 1
split_index = list(sorted(set([0, len(text)] + temp_idx)))
#查看句子长度 由于存在\n换行一个字符
lens = [split_index[i+1]-split_index[i] for i in range(len(split_index)-1)][:-1] #删除最后一个换行
print(max(lens), min(lens))
#for i in range(len(split_index)-1):
# print(i, '****', text[split_index[i]:split_index[i+1]])
#存储结果
result = []
for i in range(len(split_index)-1):
result.append(text[split_index[i]:split_index[i+1]])
fw.write(text[split_index[i]:split_index[i+1]])
fw.close()
#检查:预处理后字符是否减少
s = ''
for r in result:
s += r
assert len(s)==len(text) #断言
return result
#---------------------------功能:判断字符是不是汉字-------------------------------
def ischinese(char):
if '\u4e00' <=char <= '\u9fff':
return True
return False
#-------------------------------功能:主函数--------------------------------------
if __name__ == '__main__':
dirPath = "data/train_data"
outPath = 'data/train_data_pro'
#获取实体类别及个数
entities = get_entities(dirPath)
print(entities)
print(len(entities))
#完成实体标记 列表 字典
#得到标签和下标的映射
label, label_dic = get_labelencoder(entities)
print(label)
print(len(label))
print(label_dic, '\n\n')
#遍历路径
files = os.listdir(dirPath)
filenames = set([file.split('.')[0] for file in files])
filenames = list(filenames)
for filename in filenames:
path = os.path.join(dirPath, filename+".txt") #TXT文件
outfile = os.path.join(outPath, filename+"_pro.txt")
#print(path)
with open(path, 'r', encoding='utf8') as f:
text = f.read()
#分割文本
print(path)
split_text(text, outfile)
print("\n")
输出结果:
#encoding:utf-8
import os
import pandas as pd
from collections import Counter
from data_process import split_text
from tqdm import tqdm #进度条 pip install tqdm
#词性标注
import jieba.posseg as psg
#获取字的偏旁和拼音
from cnradical import Radical, RunOption
#删除目录
import shutil
#随机划分训练集和测试集
from random import shuffle
train_dir = "train_data"
#----------------------------功能:文本预处理---------------------------------
train_dir = "train_data"
def process_text(idx, split_method=None, split_name='train'):
"""
功能: 读取文本并切割,接着打上标记及提取词边界、词性、偏旁部首、拼音等特征
param idx: 文件的名字 不含扩展名
param split_method: 切割文本方法
param split_name: 存储数据集 默认训练集, 还有测试集
return
"""
#定义字典 保存所有字的标记、边界、词性、偏旁部首、拼音等特征
data = {}
#--------------------------------------------------------------------
# 获取句子
#--------------------------------------------------------------------
if split_method is None:
#未给文本分割函数 -> 读取文件
with open(f'data/{train_dir}/{idx}.txt', encoding='utf8') as f: #f表示文件路径
texts = f.readlines()
else:
#给出文本分割函数 -> 按函数分割
with open(f'data/{train_dir}/{idx}.txt', encoding='utf8') as f:
outfile = f'data/train_data_pro/{idx}_pro.txt'
print(outfile)
texts = f.read()
texts = split_method(texts, outfile)
#提取句子
data['word'] = texts
print(texts)
#--------------------------------------------------------------------
# 获取标签(实体类别、起始位置)
#--------------------------------------------------------------------
#初始时将所有汉字标记为O
tag_list = ['O' for s in texts for x in s] #双层循环遍历每句话中的汉字
#读取ANN文件获取每个实体的类型、起始位置和结束位置
tag = pd.read_csv(f'data/{train_dir}/{idx}.ann', header=None, sep='\t') #Pandas读取 分隔符为tab键
#0 T1 Disease 1845 1850 1型糖尿病
for i in range(tag.shape[0]): #tag.shape[0]为行数
tag_item = tag.iloc[i][1].split(' ') #每一行的第二列 空格分割
#print(tag_item)
#存在某些实体包括两段位置区间 仅获取起始位置和结束位置
cls, start, end = tag_item[0], int(tag_item[1]), int(tag_item[-1])
#print(cls,start,end)
#对tag_list进行修改
tag_list[start] = 'B-' + cls
for j in range(start+1, end):
tag_list[j] = 'I-' + cls
#断言 两个长度不一致报错
assert len([x for s in texts for x in s])==len(tag_list)
#print(len([x for s in texts for x in s]))
#print(len(tag_list))
#--------------------------------------------------------------------
# 分割后句子匹配标签
#--------------------------------------------------------------------
tags = []
start = 0
end = 0
#遍历文本
for s in texts:
length = len(s)
end += length
tags.append(tag_list[start:end])
start += length
print(len(tags))
#标签数据存储至字典中
data['label'] = tags
#--------------------------------------------------------------------
# 提取词性和词边界
#--------------------------------------------------------------------
#初始标记为M
word_bounds = ['M' for item in tag_list] #边界 M表示中间
word_flags = [] #词性
#分词
for text in texts:
#带词性的结巴分词
for word, flag in psg.cut(text):
if len(word)==1: #1个长度词
start = len(word_flags)
word_bounds[start] = 'S' #单个字
word_flags.append(flag)
else:
start = len(word_flags)
word_bounds[start] = 'B' #开始边界
word_flags += [flag]*len(word) #保证词性和字一一对应
end = len(word_flags) - 1
word_bounds[end] = 'E' #结束边界
#存储
bounds = []
flags = []
start = 0
end = 0
for s in texts:
length = len(s)
end += length
bounds.append(word_bounds[start:end])
flags.append(word_flags[start:end])
start += length
data['bound'] = bounds
data['flag'] = flags
#--------------------------------------------------------------------
# 获取拼音和偏旁特征
#--------------------------------------------------------------------
radical = Radical(RunOption.Radical) #提取偏旁部首
pinyin = Radical(RunOption.Pinyin) #提取拼音
#提取拼音和偏旁 None用特殊符号替代
radical_out = [[radical.trans_ch(x) if radical.trans_ch(x) is not None else 'PAD' for x in s] for s in texts]
pinyin_out = [[pinyin.trans_ch(x) if pinyin.trans_ch(x) is not None else 'PAD' for x in s] for s in texts]
#赋值
data['radical'] = radical_out
data['pinyin'] = pinyin_out
#--------------------------------------------------------------------
# 存储数据
#--------------------------------------------------------------------
#获取样本数量
num_samples = len(texts) #行数
num_col = len(data.keys()) #列数 字典自定义类别数 6
print(num_samples)
print(num_col)
dataset = []
for i in range(num_samples):
records = list(zip(*[list(v[i]) for v in data.values()])) #压缩
dataset += records+[['sep']*num_col] #每处理一句话sep分割
#records = list(zip(*[list(v[0]) for v in data.values()]))
#for r in records:
# print(r)
#最后一行sep删除
dataset = dataset[:-1]
#转换成dataframe 增加表头
dataset = pd.DataFrame(dataset,columns=data.keys())
#保存文件 测试集 训练集
save_path = f'data/prepare/{split_name}/{idx}.csv'
dataset.to_csv(save_path,index=False,encoding='utf-8')
#--------------------------------------------------------------------
# 处理换行符 w表示一个字
#--------------------------------------------------------------------
def clean_word(w):
if w=='\n':
return 'LB'
if w in [' ','\t','\u2003']: #中文空格\u2003
return 'SPACE'
if w.isdigit(): #将所有数字转换为一种符号 数字训练会造成干扰
return 'NUM'
return w
#对dataframe应用函数
dataset['word'] = dataset['word'].apply(clean_word)
#存储数据
dataset.to_csv(save_path,index=False,encoding='utf-8')
#return texts, tags, bounds, flags
#return texts[0], tags[0], bounds[0], flags[0], radical_out[0], pinyin_out[0]
#----------------------------功能:预处理所有文本---------------------------------
def multi_process(split_method=None,train_ratio=0.8):
"""
功能: 对所有文本尽心预处理操作
param split_method: 切割文本方法
param train_ratio: 训练集和测试集划分比例
return
"""
#删除目录
if os.path.exists('data/prepare/'):
shutil.rmtree('data/prepare/')
#创建目录
if not os.path.exists('data/prepare/train/'):
os.makedirs('data/prepare/train/')
os.makedirs('data/prepare/test/')
#获取所有文件名
idxs = set([file.split('.')[0] for file in os.listdir('data/'+train_dir)])
idxs = list(idxs)
#随机划分训练集和测试集
shuffle(idxs) #打乱顺序
index = int(len(idxs)*train_ratio) #获取训练集的截止下标
#获取训练集和测试集文件名集合
train_ids = idxs[:index]
test_ids = idxs[index:]
#--------------------------------------------------------------------
# 引入多进程
#--------------------------------------------------------------------
#线程池方式调用
import multiprocessing as mp
num_cpus = mp.cpu_count() #获取机器CPU的个数
pool = mp.Pool(num_cpus)
results = []
#训练集处理
for idx in train_ids:
result = pool.apply_async(process_text, args=(idx,split_method,'train'))
results.append(result)
#测试集处理
for idx in test_ids:
result = pool.apply_async(process_text, args=(idx,split_method,'test'))
results.append(result)
#关闭进程池
pool.close()
pool.join()
[r.get for r in results]
#-------------------------------功能:主函数--------------------------------------
if __name__ == '__main__':
#print(process_text('0',split_method=split_text,split_name='train'))
multi_process(split_text)
输出结果:
data_process.py
get_entities(dirPath)函数功能:
- 获取实体类别及个数
get_labelencoder(entities)函数功能:
- 命名实体BIO标注
split_text(text, outfile)函数功能:
- 文本分割:自定义分隔符、continue分割、中文字判断、组合分割
- 长短句处理:长句长度超过150进行拆分、短句组合
- 存储结果
prepare_data.py
def process_text(idx, split_method=None, split_name=‘train’)函数功能:
- 获取句子
- 获取标签:读取ANN文件获取实体类型、起始位置(B)、结束位置(I)
- 分割后的句子匹配标签
- 提取词性和边界:通过Jieba分词提取词性,通过长度计算边界
- 提取拼音和偏旁部首特征:利用cnradical扩展包实现
- 存储数据:按照输入字典data的六种类别一组进行数据存储
def multi_process(split_method=None,train_ratio=0.8)函数功能:
- 多文件处理:通过线程池实现
思考:上面的代码我们可以通过正则表达式将“2型糖尿病”、“HBA1C”等词识别出来,但为什么要用神经网络去进行命名实体识别呢?
- 我们通过正则表达式只是单纯将某个词组识别出来,但是构建神经网络模型后,如果将这个位置的词换成其他实体,即使不是“2型糖尿病”,它也能被正确是识别出来。这种通过上下文环境的识别方法,是正则表达式不能替代的,并且能较好地识别新生的词组或实体,比如某种医学疾病或药房。但是,前期我们进行数据预处理时,可以通过正则表达式进行标注,再进一步校正。
思考:我们能将这些字直接输入到模型中训练吗?
- 这是不能计算的,比如词性、拼音、偏旁部首,我们还需要进行词嵌入,转换成词向量,每个词性、拼音、偏旁部首都转换成向量,再拼接再一起组成新的向量进行训练。
下一篇文章我们将详细讲解字典映射、词嵌入转换、数据增强和BiLSTM-CrF模型的构建。希望您喜欢这篇文章,从开视频到撰写代码,我真的写了一周时间,再次感谢视频的作者及B站UP主。真心希望这篇文章对您有所帮助,加油~
2022年加油,感恩能与大家在华为云遇见!
希望能与大家一起在华为云社区共同成长。原文地址:https://blog.csdn.net/Eastmount/article/details/111526240
(By:娜璋之家 Eastmount 2022-01-07 夜于武汉)

- 点赞
- 收藏
- 关注作者
评论(0)