[Python人工智能] 七.什么是过拟合及dropout解决神经网络中的过拟合问题 丨【百变AI秀】

从本专栏开始,作者正式开始研究Python深度学习、神经网络及人工智能相关知识。前一篇文章通过TensorFlow实现分类学习,以MNIST数字图片为例进行讲解;本文将介绍什么是过拟合,并采用droput解决神经网络中过拟合的问题,以TensorFlow和sklearn的load_digits为案例。本专栏主要结合作者之前的博客、AI经验和"莫烦大神"的视频介绍,后面随着深入会讲解更多的Python人工智能案例及应用。
基础性文章,希望对您有所帮助,如果文章中存在错误或不足之处,还请海涵~作者作为人工智能的菜鸟,希望大家能与我在这一笔一划的博客中成长起来。写了这么多年博客,尝试第一个付费专栏,但更多博客尤其基础性文章,还是会继续免费分享,但该专栏也会用心撰写,望对得起读者,共勉!

代码下载地址(欢迎大家关注点赞):
前文赏析:
- [Python人工智能] 一.TensorFlow2.0环境搭建及神经网络入门
- [Python人工智能] 二.TensorFlow基础及一元直线预测案例
- [Python人工智能] 三.TensorFlow基础之Session、变量、传入值和激励函数
- [Python人工智能] 四.TensorFlow创建回归神经网络及Optimizer优化器
- [Python人工智能] 五.Tensorboard可视化基本用法及绘制整个神经网络
- [Python人工智能] 六.TensorFlow实现分类学习及MNIST手写体识别案例
- [Python人工智能] 七.什么是过拟合及dropout解决神经网络中的过拟合问题 丨【百变AI秀】
实际生活中,神经网络过于自信,甚至自负,在自己的小圈子里非凡,但在大圈子里却处处碰壁,这就类似于过拟合。
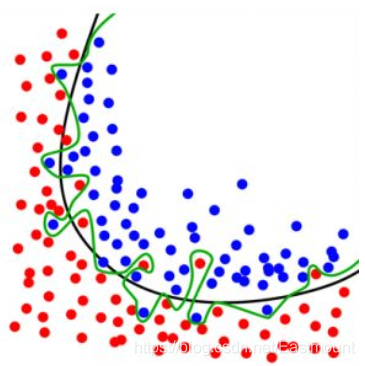
在机器学习领域,过拟合(Overfitting)是非常常见的一个问题。比如现在有一个分类问题,如果我正常预测,黑色曲线的右边是蓝色数据集区域,左边是红色数据集区域,我们能够很好地用肉眼进行区分并绘制一条黑色曲线。但如果机器学习学得太好的话,它会非常精准的将所有蓝色点囊括进去,形成这条绿色曲线,但这条绿色曲线就是过拟合的。因为在实际应用中,往往这条绿色曲线没有黑色曲线这么好的把数据集区分开来,反而我们需要让机器学习形成这条黑色曲线。
同样,如果是回归问题,这条蓝色直线是希望机器学习学到的直线。假设蓝色直线与所有黄色点的总误差为10,有时机器过于追求误差小,它学到的可能是红色这条虚曲线,它经过了所有的数据点,误差为1。

可是,误差小真的就好吗?当我们拿这个模型预测实际值时,如下图所示“+”号。这时,蓝色误差几乎不变,而红色误差突然升高,显然红线不能表达除训练数据以外的数据,这就叫做过拟合(Overfitting)。

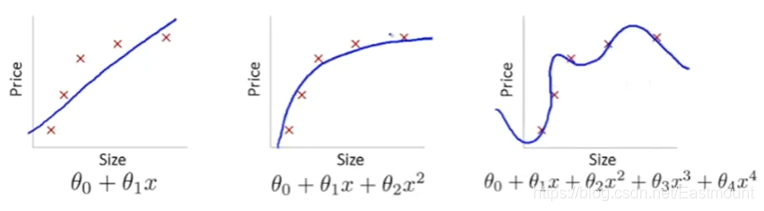
下图对比了欠拟合、正常和过拟合三种状态。假设真实的数据集(红色散点)是一条曲线分布,这里的第一条直线是欠拟合(underfit);第二条曲线很好地囊括了我们的特征;第三条曲线是过拟合,虽然这条曲线经过了每个数据点,但它往往不能预测其他新生节点。
那么,怎么解决过拟合呢?
方法一:增加数据量
大多数过拟合的原因是数据量太小,如果有成千上万数据,红线也会被拉直,没有这么扭曲,所以增加数据量能在一定程度上解决过拟合问题。
方法二:L1, L2 Regularization
正规化是处理过拟合的常见方法,该方法适合大多数机器学习。
机器学习:y = W · x
其中,W是参数。过拟合中W往往变化太大,为了让变化不会太大,我们在计算误差时需要做些手脚。
-
L1:cost = (W · x - real y)^2 + abs(W)
=>L1正规化是预测值与真实值平方,加上W的绝对值 -
L2:cost = (W · x - real y)^2 + (W)^2
=>L2正规化是预测值与真实值平方,加上W的平方 -
L3:加立方
-
L4:加四次方
由于过度依赖的权重W会很大,我们在上述L1和L2公式中惩罚了这些大的参数。如果W变化太大,我们让cost也跟着变大,变成一种惩罚机制,把W自己也考虑进来,从而解决过拟合。

方法三:Droput Regularization
该方法是训练时,随机忽略一些神经元和连接,神经网络会变得不完整,用不完整的神经网络训练一次,紧接着第二次再随机训练,忽略另一部分的神经元和连接,让每次结果不依赖特定的神经元,Droput从根本上解决过拟合。
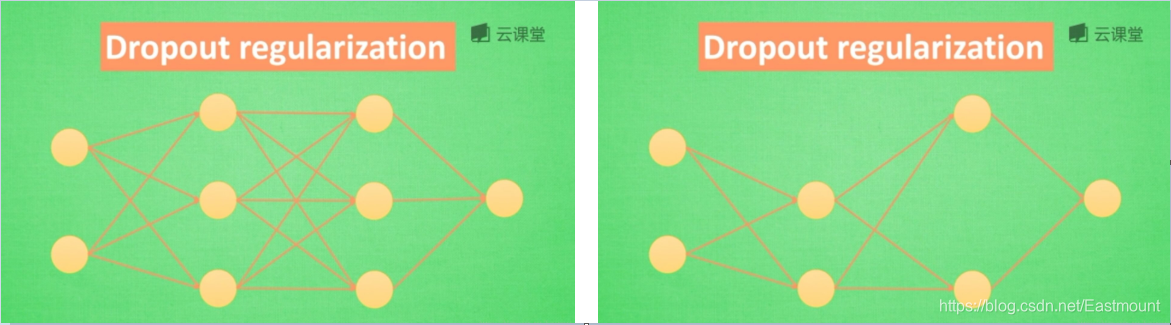
这里,我们使用TensorFlow提供的工具dropout,它能够非常好地解决过拟合问题。
接下来我们开始讲解如何在TensorFlow中去避免Overfitting,它提供了Dropout解决过拟合问题。
首先,我们需要在TensorFlow环境中安装Sklearn扩展包,否则会提示错误“ModuleNotFoundError: No module named ‘sklearn’”。调用Anaconda Prompt安装即可,如下图所示:
activate tensorflow
pip install scikit-learn

第一步,导入扩展包。
import tensorflow as tf
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelBinarizer
第二步,载入数据集并划分训练集和预测集。
# 加载数据data和target
digits = load_digits()
X = digits.data
y = digits.target
# 转换y为Binarizer 如果y是数字1则第二个长度放上1
y = LabelBinarizer().fit_transform(y)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.3)
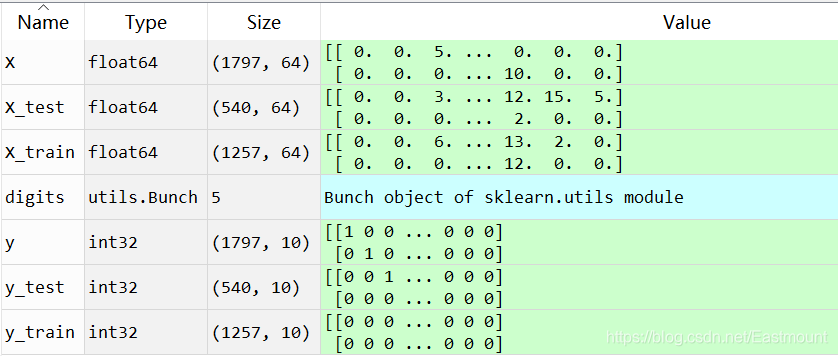
在Spyder中运行代码,点击“Variable explorer”可以看到被拆分的训练集和预测集,如下图所示。
第三步,定义增加神经层的函数add_layer()。
# 函数:输入变量 输入大小 输出大小 神经层名称 激励函数默认None
def add_layer(inputs, in_size, out_size, layer_name, activation_function=None):
# 权重为随机变量矩阵
Weights = tf.Variable(tf.random_normal([in_size, out_size])) #行*列
# 定义偏置 初始值增加0.1 每次训练中有变化
biases = tf.Variable(tf.zeros([1, out_size]) + 0.1) #1行多列
# 定义计算矩阵乘法 预测值
Wx_plus_b = tf.matmul(inputs, Weights) + biases
# 激活操作
if activation_function is None:
outputs = Wx_plus_b
else:
outputs = activation_function(Wx_plus_b)
tf.summary.histogram(layer_name+'/outputs', outputs)
return outputs
第四步,定义placeholder。
# 设置传入的值xs和ys
xs = tf.placeholder(tf.float32, [None, 64]) #8*8=64个点
ys = tf.placeholder(tf.float32, [None, 10]) #每个样本有10个输出
第五步,增加神经层,包括隐藏层和输出层。
- 隐藏层L1:输入是64(load_digits数据集每个样本64个像素点),输出为100个,从而更好地展示过拟合的问题,激励函数为tanh。
- 输出层prediction:输入是100(L1的输出),输出是10,对应数字0-9,激励函数为softmax。

# 隐藏层 输入是8*8=64 输出是100 激励函数tanh
L1 = add_layer(xs, 64, 100, 'L1', activation_function=tf.nn.tanh)
# 输入是100 10个输出值 激励函数softmax常用于分类
prediction = add_layer(L1, 100, 10, 'L2', activation_function=tf.nn.softmax)
第六步,定义loss和训练。
# 预测值与真实值误差
cross_entropy = tf.reduce_mean(-tf.reduce_sum(ys * tf.log(prediction),
reduction_indices=[1])) #loss
# 记录loss tensorboard显示变化曲线
tf.summary.scalar('loss', cross_entropy)
# 训练学习 学习效率通常小于1 这里设置为0.6可以进行对比
train_step = tf.train.GradientDescentOptimizer(0.6).minimize(cross_entropy) #减小误差
第七步,初始化操作。
# 定义Session
sess = tf.Session()
# 合并所有summary
merged = tf.summary.merge_all()
# summary写入操作
train_writer = tf.summary.FileWriter('logs/train', sess.graph)
test_writer = tf.summary.FileWriter('logs/test', sess.graph)
# 初始化
init = tf.initialize_all_variables()
sess.run(init)
第八步,神经网络学习。
for i in range(1000):
# 训练
sess.run(train_step, feed_dict={xs:X_train, ys:y_train})
# 每隔50步输出一次结果
if i % 50 == 0:
# 运行和赋值
train_result = sess.run(merged,feed_dict={xs:X_train, ys:y_train})
test_result = sess.run(merged,feed_dict={xs:X_test, ys:y_test})
# 写入Tensorboard可视化
train_writer.add_summary(train_result, i)
test_writer.add_summary(test_result, i)
最终完整代码如下所示:
# -*- coding: utf-8 -*-
"""
Created on Wed Dec 18 15:50:08 2019
@author: xiuzhang CSDN Eastmount
"""
import tensorflow as tf
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelBinarizer
#---------------------------------载入数据---------------------------------
# 加载数据data和target
digits = load_digits()
X = digits.data
y = digits.target
# 转换y为Binarizer 如果y是数字1则第二个长度放上1
y = LabelBinarizer().fit_transform(y)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.3)
#---------------------------------定义神经层---------------------------------
# 函数:输入变量 输入大小 输出大小 神经层名称 激励函数默认None
def add_layer(inputs, in_size, out_size, layer_name, activation_function=None):
# 权重为随机变量矩阵
Weights = tf.Variable(tf.random_normal([in_size, out_size])) #行*列
# 定义偏置 初始值增加0.1 每次训练中有变化
biases = tf.Variable(tf.zeros([1, out_size]) + 0.1) #1行多列
# 定义计算矩阵乘法 预测值
Wx_plus_b = tf.matmul(inputs, Weights) + biases
# 激活操作
if activation_function is None:
outputs = Wx_plus_b
else:
outputs = activation_function(Wx_plus_b)
tf.summary.histogram(layer_name+'/outputs', outputs)
return outputs
#--------------------------------定义placeholder-------------------------------
# 设置传入的值xs和ys
xs = tf.placeholder(tf.float32, [None, 64]) #8*8=64个点
ys = tf.placeholder(tf.float32, [None, 10]) #每个样本有10个输出
#---------------------------------增加神经层---------------------------------
# 隐藏层 输入是8*8=64 输出是100 激励函数tanh
L1 = add_layer(xs, 64, 100, 'L1', activation_function=tf.nn.tanh)
# 输入是100 10个输出值 激励函数softmax常用于分类
prediction = add_layer(L1, 100, 10, 'L2', activation_function=tf.nn.softmax)
#------------------------------定义loss和训练-------------------------------
# 预测值与真实值误差
cross_entropy = tf.reduce_mean(-tf.reduce_sum(ys * tf.log(prediction),
reduction_indices=[1])) #loss
# 记录loss tensorboard显示变化曲线
tf.summary.scalar('loss', cross_entropy)
# 训练学习 学习效率通常小于1 这里设置为0.6可以进行对比
train_step = tf.train.GradientDescentOptimizer(0.6).minimize(cross_entropy) #减小误差
#-----------------------------------初始化-----------------------------------
# 定义Session
sess = tf.Session()
# 合并所有summary
merged = tf.summary.merge_all()
# summary写入操作
train_writer = tf.summary.FileWriter('logs/train', sess.graph)
test_writer = tf.summary.FileWriter('logs/test', sess.graph)
# 初始化
init = tf.initialize_all_variables()
sess.run(init)
#---------------------------------神经网络学习---------------------------------
for i in range(1000):
# 训练
sess.run(train_step, feed_dict={xs:X_train, ys:y_train})
# 每隔50步输出一次结果
if i % 50 == 0:
# 运行和赋值
train_result = sess.run(merged,feed_dict={xs:X_train, ys:y_train})
test_result = sess.run(merged,feed_dict={xs:X_test, ys:y_test})
# 写入Tensorboard可视化
train_writer.add_summary(train_result, i)
test_writer.add_summary(test_result, i)
接着先删除之前的logs文件夹,然后运行我们的程序,会生成新的logs文件夹,并且包括train和test文件夹及event文件。
然后我们需要在Anaconda Prompt中调用Tensorboard可视化展示图形,输入命令如下。
activate tensorflow
cd\
cd C:\Users\xiuzhang\Desktop\TensorFlow\blog
tensorboard --logdir=logs
最后用浏览器打开网址“http://localhost:6006/”,GRAPHS面板显示如下图所示:

DISTRIBUTIONS面板如下图所示:

最重要的是SCALARS面板,它展现了训练和测试loss曲线的对比。

在SCALARS面板中,蓝色线显示的是train data,红色线显示的是test data。它们到拐点的时候开始存在差别,测试集的精准度会小于训练集,而误差会大于训练集的,因为存在过拟合问题。

PS:如文代码运行报错"InvalidArgumentError: You must feed a value for placeholder tensor ‘Placeholder_6’ with dtype float and shape [?,10]"。从字面理解是placeholder占位符(理解为声明)没有被赋值(成为变量),你必须给占位符喂入一个向量值即赋值。解决方法:
- 重新关闭运行环境Spyder或删除logs再运行,怀疑是内存中有很多Placeholder需要释放。
- sess.run(train_step, feed_dict = {xs: batch_xs, ys: batch_ys}) 中 feed_dict 缺少参数,增加keep_prob:0.5。
前面第二部分的曲线以及存在过拟合现象了,那怎么克服它呢?
这里使用dropout把我们的过拟合现象解决掉。其实就是把dropout加载到“Wx_plus_b = tf.matmul(inputs, Weights) + biases”这个结果中,把这个结果的50%舍弃掉,每次训练任意从中取出50%的数据进行,从而避免过拟合的影响。其原理是忽略一部分的神经元和连接,让每次结果不依赖特定的神经元,Droput从根本上解决了过拟合。
第一步,在之前的代码上增加keeping probability。
这里引入一个keeping probability,表示保持多少结果不被drop掉,并且定义成placeholder。
keep_prob = tf.placeholder(tf.float32)
第二步,将keep_prob加载到feed_dict中,神经网络学习的代码修改如下:
- 训练的时候保留50%的结果,keep_prob设置为0.5
- 输出loss记录的时候,需要显示所有的结果,故keep_prob设置为1.0
for i in range(1000):
# 训练 保留50%结果
sess.run(train_step, feed_dict={xs:X_train, ys:y_train, keep_prob:0.5})
# 每隔50步输出一次结果
if i % 50 == 0:
# 运行和赋值
train_result = sess.run(merged,feed_dict={xs:X_train, ys:y_train, keep_prob:1.0})
test_result = sess.run(merged,feed_dict={xs:X_test, ys:y_test, keep_prob:1.0})
# 写入Tensorboard可视化
train_writer.add_summary(train_result, i)
test_writer.add_summary(test_result, i)
第三步,接着在增加神经网络函数add_layer()中增加dropout的代码。
# 函数:输入变量 输入大小 输出大小 神经层名称 激励函数默认None
def add_layer(inputs, in_size, out_size, layer_name, activation_function=None):
# 权重为随机变量矩阵
Weights = tf.Variable(tf.random_normal([in_size, out_size])) #行*列
# 定义偏置 初始值增加0.1 每次训练中有变化
biases = tf.Variable(tf.zeros([1, out_size]) + 0.1) #1行多列
# 定义计算矩阵乘法 预测值
Wx_plus_b = tf.matmul(inputs, Weights) + biases
# dropout
Wx_plus_b = tf.nn.dropout(Wx_plus_b, keep_prob)
# 激活操作
if activation_function is None:
outputs = Wx_plus_b
else:
outputs = activation_function(Wx_plus_b)
tf.summary.histogram(layer_name+'/outputs', outputs)
return outputs
最终完整代码如下所示:
# -*- coding: utf-8 -*-
"""
Created on Wed Dec 18 15:50:08 2019
@author: xiuzhang CSDN Eastmount
"""
import tensorflow as tf
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelBinarizer
#---------------------------------载入数据---------------------------------
# 加载数据data和target
digits = load_digits()
X = digits.data
y = digits.target
# 转换y为Binarizer 如果y是数字1则第二个长度放上1
y = LabelBinarizer().fit_transform(y)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.3)
#---------------------------------定义神经层---------------------------------
# 函数:输入变量 输入大小 输出大小 神经层名称 激励函数默认None
def add_layer(inputs, in_size, out_size, layer_name, activation_function=None):
# 权重为随机变量矩阵
Weights = tf.Variable(tf.random_normal([in_size, out_size])) #行*列
# 定义偏置 初始值增加0.1 每次训练中有变化
biases = tf.Variable(tf.zeros([1, out_size]) + 0.1) #1行多列
# 定义计算矩阵乘法 预测值
Wx_plus_b = tf.matmul(inputs, Weights) + biases
# dropout
Wx_plus_b = tf.nn.dropout(Wx_plus_b, keep_prob)
# 激活操作
if activation_function is None:
outputs = Wx_plus_b
else:
outputs = activation_function(Wx_plus_b)
tf.summary.histogram(layer_name+'/outputs', outputs)
return outputs
#--------------------------------定义placeholder-------------------------------
# 设置传入的值xs和ys
xs = tf.placeholder(tf.float32, [None, 64]) #8*8=64个点
ys = tf.placeholder(tf.float32, [None, 10]) #每个样本有10个输出
# keeping probability
keep_prob = tf.placeholder(tf.float32)
#---------------------------------增加神经层---------------------------------
# 隐藏层 输入是8*8=64 输出是100 激励函数tanh
L1 = add_layer(xs, 64, 50, 'L1', activation_function=tf.nn.tanh)
# 输入是100 10个输出值 激励函数softmax常用于分类
prediction = add_layer(L1, 50, 10, 'L2', activation_function=tf.nn.softmax)
#------------------------------定义loss和训练-------------------------------
# 预测值与真实值误差
cross_entropy = tf.reduce_mean(-tf.reduce_sum(ys * tf.log(prediction),
reduction_indices=[1])) #loss
# 记录loss tensorboard显示变化曲线
tf.summary.scalar('loss', cross_entropy)
# 训练学习 学习效率通常小于1 这里设置为0.6可以进行对比
train_step = tf.train.GradientDescentOptimizer(0.6).minimize(cross_entropy) #减小误差
#-----------------------------------初始化-----------------------------------
# 定义Session
sess = tf.Session()
# 合并所有summary
merged = tf.summary.merge_all()
# summary写入操作
train_writer = tf.summary.FileWriter('logs/train', sess.graph)
test_writer = tf.summary.FileWriter('logs/test', sess.graph)
# 初始化
init = tf.initialize_all_variables()
sess.run(init)
#---------------------------------神经网络学习---------------------------------
for i in range(1000):
# 训练 保留50%结果
sess.run(train_step, feed_dict={xs:X_train, ys:y_train, keep_prob:0.5})
# 每隔50步输出一次结果
if i % 50 == 0:
# 运行和赋值
train_result = sess.run(merged,feed_dict={xs:X_train, ys:y_train, keep_prob:1.0})
test_result = sess.run(merged,feed_dict={xs:X_test, ys:y_test, keep_prob:1.0})
# 写入Tensorboard可视化
train_writer.add_summary(train_result, i)
test_writer.add_summary(test_result, i)
同样,先删除掉之前的logs文件夹,再运行我们修改后的代码。loss显示如下图所示,可以看到两条曲线非常接近,很好地接近了过拟合问题,核心代码:
sess.run(train_step, feed_dict={xs:X_train, ys:y_train, keep_prob:0.5})

如果keep_prob设置为1.0则会存在过拟合现象,如下图所示:
sess.run(train_step, feed_dict={xs:X_train, ys:y_train, keep_prob:1.0})

写到这里,这篇文章就结束了。本文详细讲解了什么是过拟合,并且通过TensorFlow和sklearn的数字分类案例呈现了现实项目中的过拟合,并通过dropout接近该问题。下一篇文章,我们开始讲解CNN和RNN相关知识。
最后,希望这篇基础性文章对您有所帮助,如果文章中存在错误或不足之处,还请海涵~作为人工智能的菜鸟,我希望自己能不断进步并深入,后续将它应用于图像识别、网络安全、对抗样本等领域,指导大家撰写简单的学术论文,一起加油!
感恩能与大家在华为云遇见!
希望能与大家一起在华为云社区共同成长。原文地址:https://blog.csdn.net/Eastmount/article/details/103586271
【百变AI秀】有奖征文火热进行中:https://bbs.huaweicloud.com/blogs/296704
(By:娜璋之家 Eastmount 2021-09-05 夜于武汉)
参考文献:
[1] 神经网络和机器学习基础入门分享 - 作者的文章
[2] 斯坦福机器学习视频NG教授: https://class.coursera.org/ml/class/index
[3] 书籍《游戏开发中的人工智能》、《游戏编程中的人工智能技术》
[4] 网易云莫烦老师视频(强推 我付费支持老师一波):https://study.163.com/course/courseLearn.htm?courseId=1003209007
[5] 神经网络激励函数 - deeplearning
[6] tensorflow架构 - NoMorningstar
[7] Tensorflow实现CNN用于MNIST识别 - siucaan
[8] MNIST手写体识别任务 - chen645096127
[9] https://github.com/siucaan/CNN_MNIST
[10] https://github.com/eastmountyxz/AI-for-TensorFlow

- 点赞
- 收藏
- 关注作者
评论(0)