[Python人工智能] 十八.Keras搭建卷积神经网络及CNN原理详解

从本专栏开始,作者正式研究Python深度学习、神经网络及人工智能相关知识。前一篇文章详细讲解了Keras实现分类学习,以MNIST数字图片为例进行讲解。本篇文章详细讲解了卷积神经网络CNN原理,并通过Keras编写CNN实现了MNIST分类学习案例。基础性文章,希望对您有所帮助!

本专栏主要结合作者之前的博客、AI经验和相关视频(强推"莫烦大神"视频)及论文介绍,后面随着深入会讲解更多的Python人工智能案例及应用。基础性文章,希望对您有所帮助,如果文章中存在错误或不足之处,还请海涵~作者作为人工智能的菜鸟,希望大家能与我在这一笔一划的博客中成长起来。写了这么多年博客,尝试第一个付费专栏,但更多博客尤其基础性文章,还是会继续免费分享,但该专栏也会用心撰写,望对得起读者,共勉!
代码下载地址:https://github.com/eastmountyxz/AI-for-TensorFlow
代码下载地址:https://github.com/eastmountyxz/AI-for-Keras
华为云社区前文赏析:
- [Python人工智能] 一.TensorFlow2.0环境搭建及神经网络入门
- [Python人工智能] 二.TensorFlow基础及一元直线预测案例
- [Python人工智能] 三.TensorFlow基础之Session、变量、传入值和激励函数
- [Python人工智能] 四.TensorFlow创建回归神经网络及Optimizer优化器
- [Python人工智能] 五.Tensorboard可视化基本用法及绘制整个神经网络
- [Python人工智能] 六.TensorFlow实现分类学习及MNIST手写体识别案例
- [Python人工智能] 七.什么是过拟合及dropout解决神经网络中的过拟合问题
- [Python人工智能] 八.卷积神经网络CNN原理详解及TensorFlow编写CNN
- [Python人工智能] 九.gensim词向量Word2Vec安装及《庆余年》中文短文本相似度计算
- [Python人工智能] 十.Tensorflow+Opencv实现CNN自定义图像分类及与KNN图像分类对比
- [Python人工智能] 十一.Tensorflow如何保存神经网络参数
- [Python人工智能] 十二.循环神经网络RNN和LSTM原理详解及TensorFlow编写RNN分类案例
- [Python人工智能] 十三.如何评价神经网络、loss曲线图绘制、图像分类案例的F值计算
- [Python人工智能] 十四.循环神经网络LSTM RNN回归案例之sin曲线预测 丨【百变AI秀】
- [Python人工智能] 十五.无监督学习Autoencoder原理及聚类可视化案例详解
- [Python人工智能] 十六.Keras环境搭建、入门基础及回归神经网络案例
- [Python人工智能] 十七.Keras搭建分类神经网络及MNIST数字图像案例分析
- [Python人工智能] 十八.Keras搭建卷积神经网络及CNN原理详解
一般的神经网络在理解图片信息的时候还是有不足之处,这时卷积神经网络就成为了计算机处理图片的助推器。卷积神经网络的英文是Convolutional Neural Network,简称CNN。它通常应用于图像识别和语音识等领域,并能给出更优秀的结果,也可以应用于视频分析、机器翻译、自然语言处理、药物发现等领域。著名的阿尔法狗让计算机看懂围棋就是基于卷积神经网络的。
神经网络是由很多神经层组成,每一层神经层中存在很多神经元,这些神经元是识别事物的关键,当输入是图片时,其实就是一堆数字。
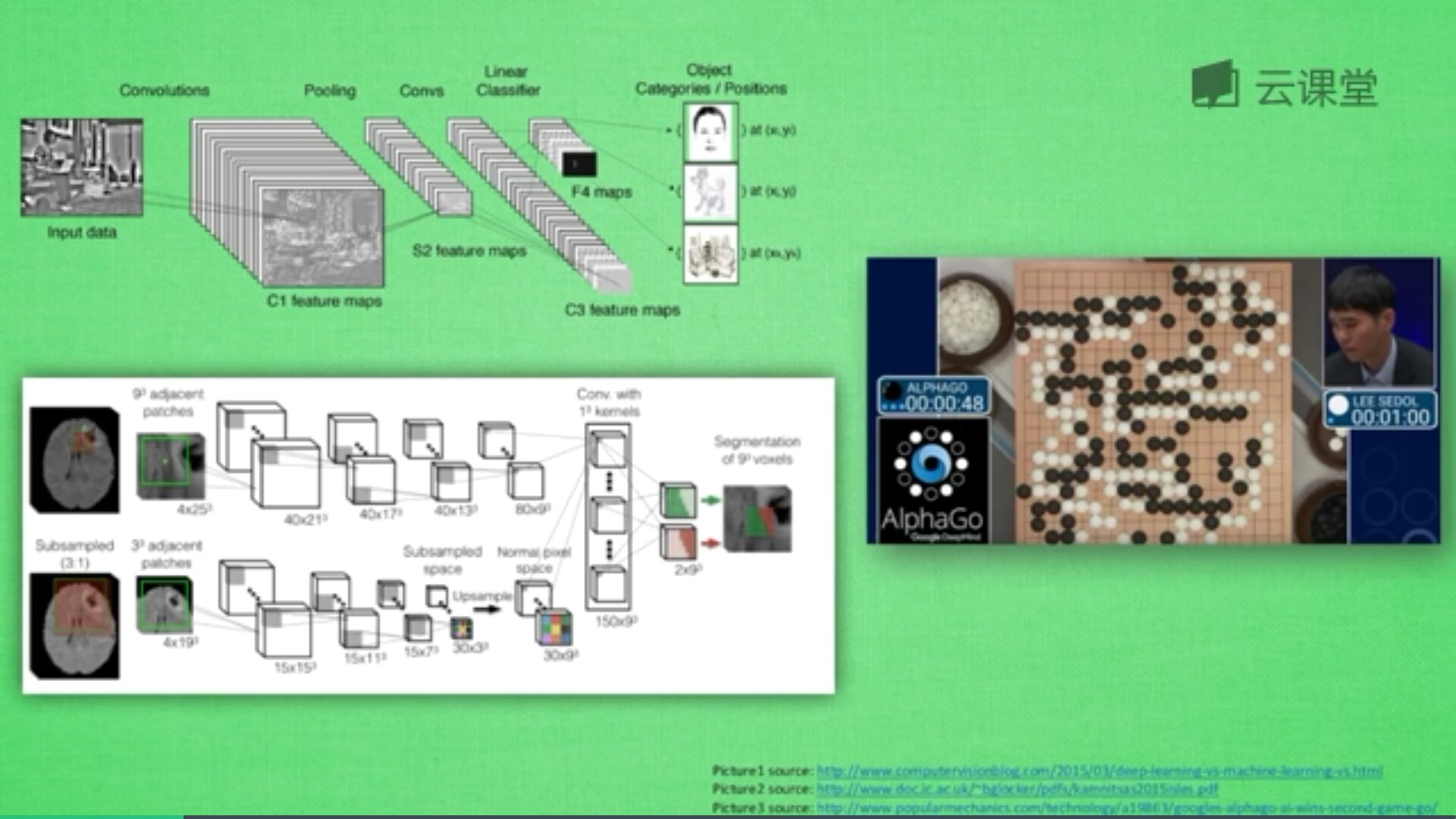
首先,卷积是什么意思呢?卷积是指不在对每个像素做处理,而是对图片区域进行处理,这种做法加强了图片的连续性,看到的是一个图形而不是一个点,也加深了神经网络对图片的理解。
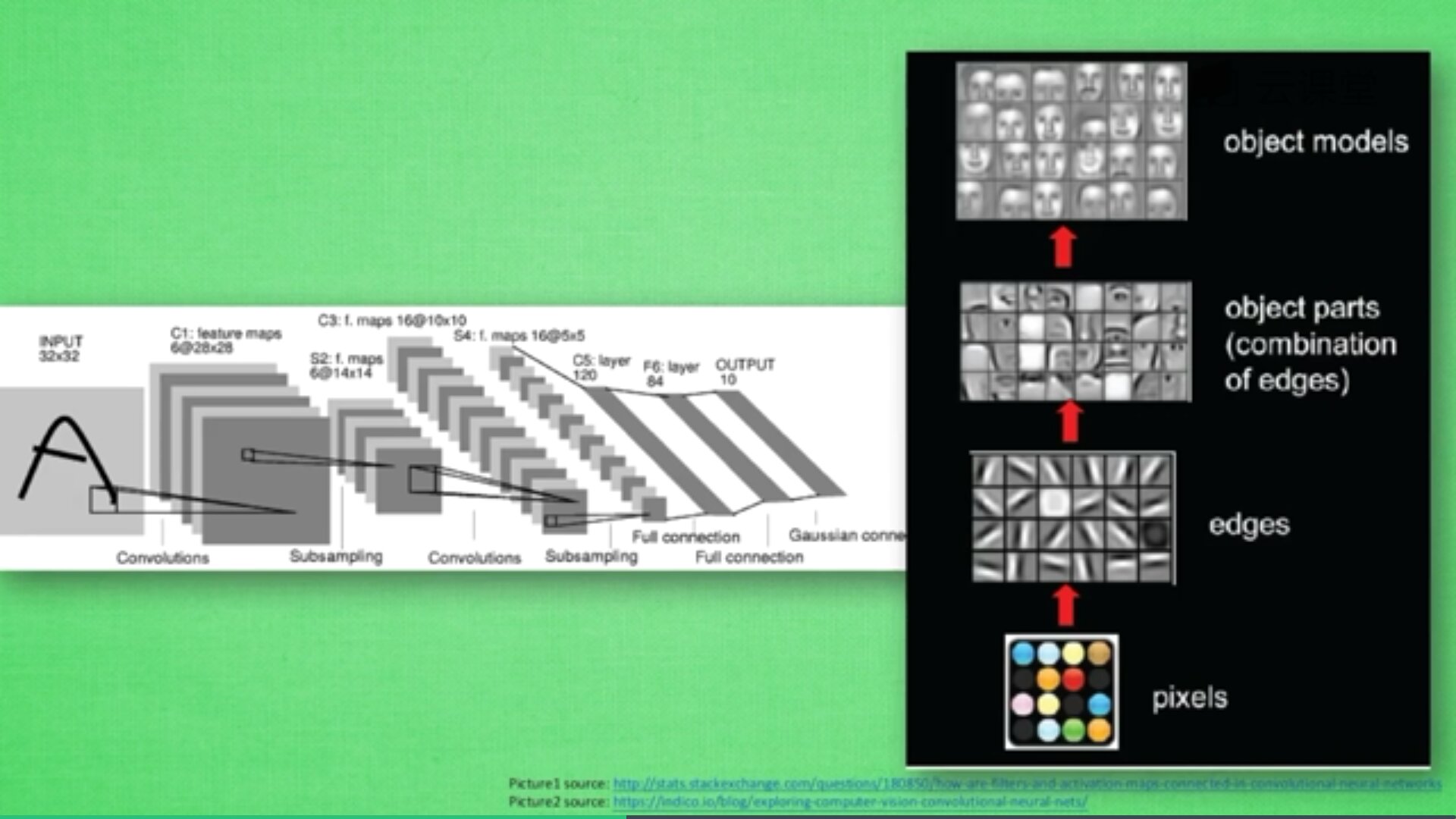
卷积神经网络批量过滤器,持续不断在图片上滚动搜集信息,每一次搜索都是一小块信息,整理这一小块信息之后得到边缘信息。比如第一次得出眼睛鼻子轮廓等,再经过一次过滤,将脸部信息总结出来,再将这些信息放到全神经网络中进行训练,反复扫描最终得出的分类结果。如下图所示,猫的一张照片需要转换为数学的形式,这里采用长宽高存储,其中黑白照片的高度为1,彩色照片的高度为3(RGB)。

过滤器搜集这些信息,将得到一个更小的图片,再经过压缩增高信息嵌入到普通神经层上,最终得到分类的结果,这个过程即是卷积。Convnets是一种在空间上共享参数的神经网络,如下图所示,它将一张RGB图片进行压缩增高,得到一个很长的结果。
近几年神经网络飞速发展,其中一个很重要的原因就是CNN卷积神经网络的提出,这也是计算机视觉处理的飞跃提升。关于TensorFlow中的CNN,Google公司也出了一个非常精彩的视频教程,也推荐大家去学习。
本文主要讲解如何去应用CNN,下面我们先简单看看CNN是如何处理信息的。这里参考Google官方视频介绍,强烈推荐大家学习。
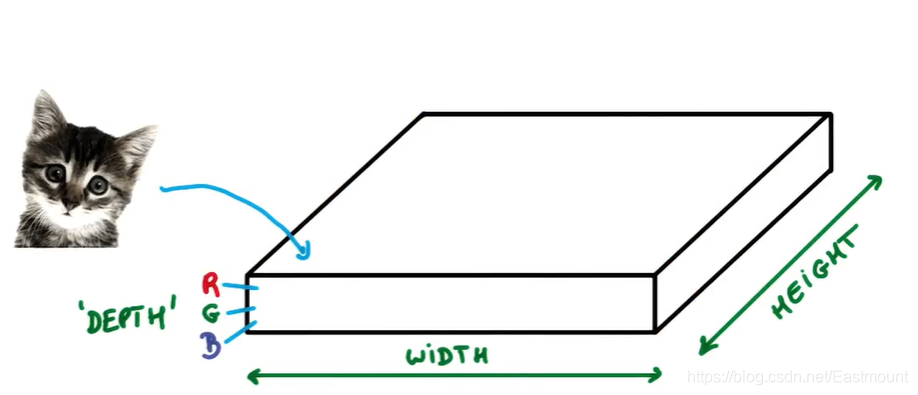
假设你有一张小猫咪的照片,如下图所示,它可以被表示为一个博饼,它有宽度(width)和高度(height),并且由于天然存在红绿蓝三色,它还拥有RGB厚度(depth),此时你的输入深度为3。
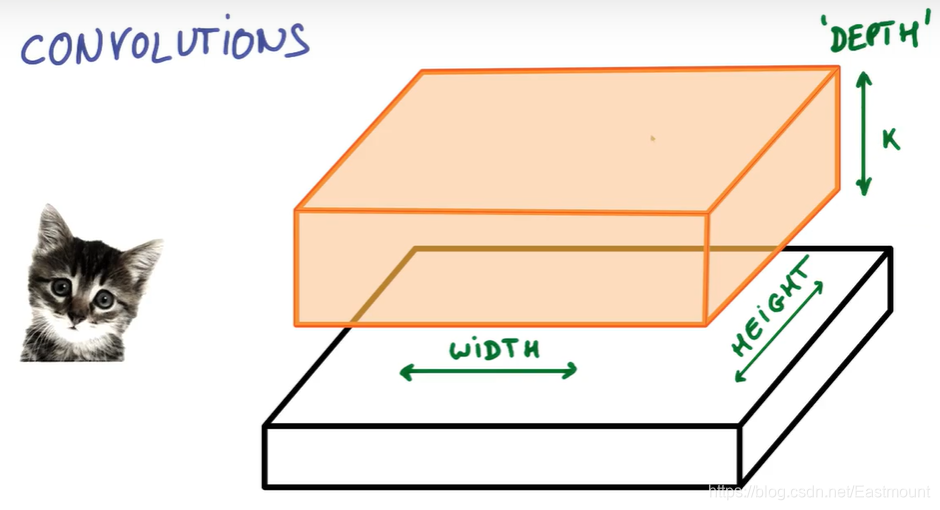
假设我们现在拿出图片的一小块,运行一个具有K个输出的小神经网络,像图中一样把输出表示为垂直的一小列。
在不改变权重的情况下,通过小神经网络滑动扫遍整个图片,就像我们拿着刷子刷墙一样水平垂直的滑动。

此时,输出端画出了另一幅图像,如下图中红色区域所示。它与之前的宽度和高度不同,更重要的是它跟之前的深度不同,而不是仅仅只有红绿蓝,现在你得到了K个颜色通道,这种操作称为——卷积。
如果你的块大小是整张图片,那它跟普通的神经网络层没有任何区别,正是由于我们使用了小块,我们有很多小块在空间中共享较少的权重。卷积不在对每个像素做处理,而是对图片区域进行处理,这种做法加强了图片的连续性,也加深了神经网络对图片的理解。
一个卷积网络是组成深度网络的基础,我们将使用数层卷积而不是数层的矩阵相乘。如下图所示,让它形成金字塔形状,金字塔底是一个非常大而浅的图片,仅包括红绿蓝,通过卷积操作逐渐挤压空间的维度,同时不断增加深度,使深度信息基本上可以表示出复杂的语义。同时,你可以在金字塔的顶端实现一个分类器,所有空间信息都被压缩成一个标识,只有把图片映射到不同类的信息保留,这就是CNN的总体思想。
上图的具体流程如下:
- 首先,这是有一张彩色图片,它包括RGB三原色分量,图像的长和宽为256*256,三个层面分别对应红(R)、绿(G)、蓝(B)三个图层,也可以看作像素点的厚度。
- 其次,CNN将图片的长度和宽度进行压缩,变成12812816的方块,压缩的方法是把图片的长度和宽度压小,从而增高厚度。
- 再次,继续压缩至646464,直至3232256,此时它变成了一个很厚的长条方块,我们这里称之为分类器Classifier。该分类器能够将我们的分类结果进行预测,MNIST手写体数据集预测结果是10个数字,比如[0,0,0,1,0,0,0,0,0,0]表示预测的结果是数字3,Classifier在这里就相当于这10个序列。
- 最后,CNN通过不断压缩图片的长度和宽度,增加厚度,最终会变成了一个很厚的分类器,从而进行分类预测。
如果你想实现它,必须还要正确实现很多细节。此时,你已经接触到了块和深度的概念,块(PATCH)有时也叫做核(KERNEL),如下图所示,你堆栈的每个薄饼都被叫做特征图(Feature Map),这里把三个特性映射到K个特征图中,PATCH/KERNEL的功能是从图片中抽离一小部分进行分析,每次抽离的小部分都会变成一个长度、一个宽度、K个厚度的数列。
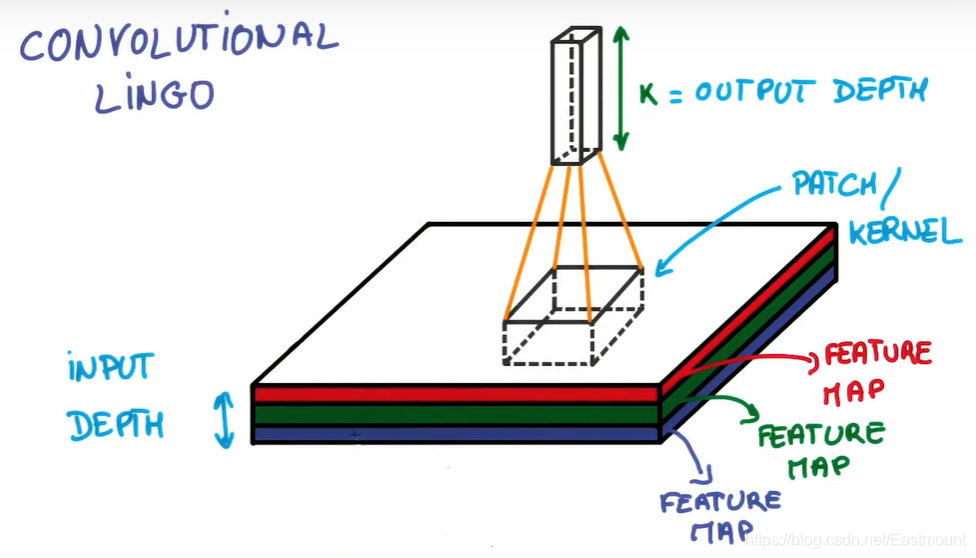
另一个你需要知道的概念是——步幅(STRIDE)。它是当你移动滤波器或抽离时平移的像素的数量,每一次跨多少步去抽离图片中的像素点。
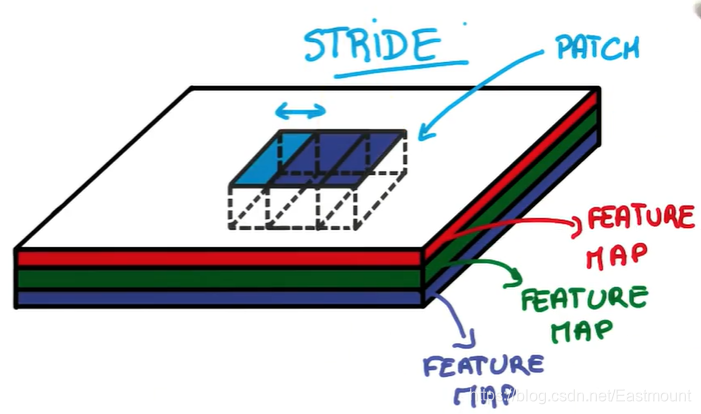
如果步幅STRIDE等于1,表示每跨1个像素点抽离一次,得到的尺寸基本上和输入相同。
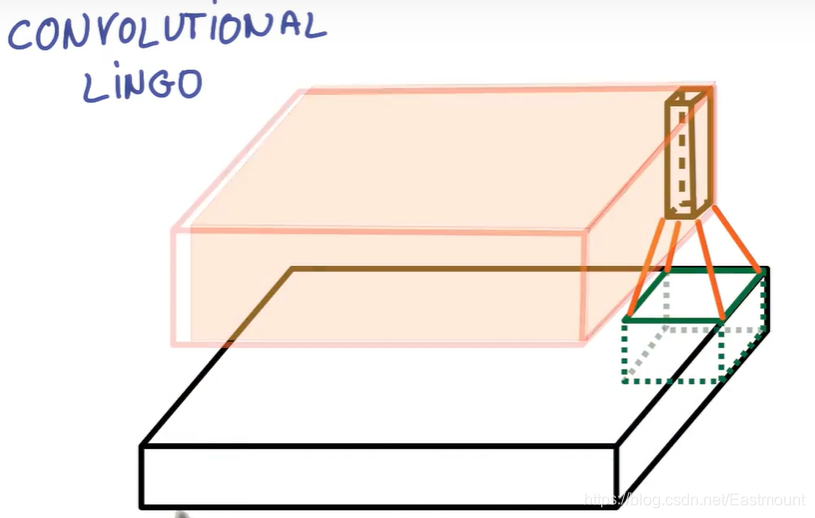
如果步幅STRIDE等于2,表示每次跨2个像素点抽离,意味着变为一半的尺寸。它收集到的信息就会被缩减,图片的长度和宽度被压缩了,压缩合并成更小的一块立方体。
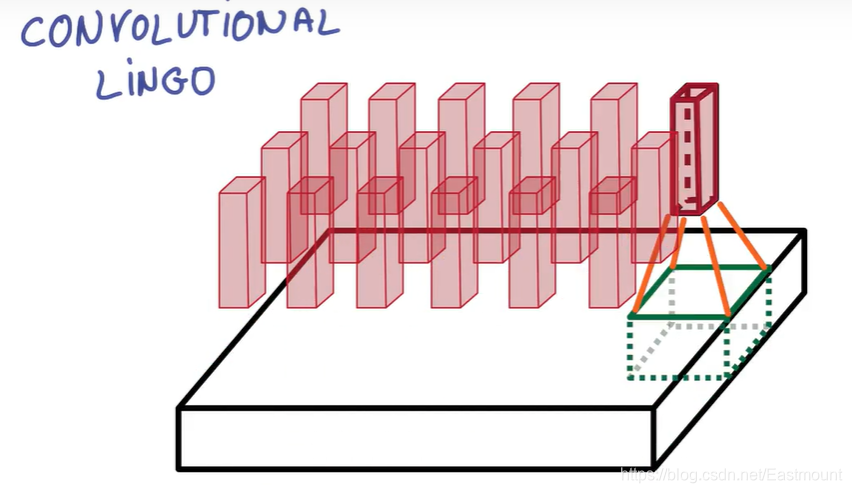
压缩完之后再合并成一个立方体,它就是更小的一块立方体,包含了图片中的所有信息。

抽离图片信息的方式称为PADDING(填充),一般分为两种:
- VALID PADDING: 抽出来这层比原先那层图片宽和长裁剪了一点,抽取的内容全部是图片内的。
- SAME PADDING: 抽离出的那层与之前的图片一样的长和宽,抽取的内容部分再图片外,图片外的值用0来填充。

研究发现,卷积过程会丢失一些信息,比如现在想跨2步去抽离原始图片的重要信息,形成长宽更小的图片,该过程中可能会丢失重要的图片信息。为了解决这个问题,通过POOLING(持化)可以避免。其方法是:卷积时不再压缩长宽,尽量保证更多信息,压缩工作交给POOLING。经过图片到卷积,持化处理卷积信息,再卷积再持化,将结果传入两层全连接神经层,最终通过分类器识别猫或狗。

总结:整个CNN从下往上依次经历“图片->卷积->持化->卷积->持化->结果传入两层全连接神经层->分类器”的过程,最终实现一个CNN的分类处理。
- IMAGE 图片
- CONVOLUTION 图层
- MAX POOLING 更好地保存原图片的信息
- CONVOLUTION 图层
- MAX POOLING 更好地保存原图片的信息
- FULLY CONNECTED 神经网络隐藏层
- FULLY CONNECTED 神经网络隐藏层
- CLASSIFIER 分类器

写到这里,CNN的基本原理讲解完毕,希望大家对CNN有一个初步的理解。同时建议大家处理神经网络时,先用一般的神经网络去训练它,如果得到的结果非常好,就没必要去使用CNN,因为CNN结构比较复杂。
接着我们讲解如何在Keras代码中编写CNN。
第一步,打开Anaconda,然后选择已经搭建好的“tensorflow”环境,运行Spyder。

第二步,导入扩展包。
import numpy as np
from keras.datasets import mnist
from keras.utils import np_utils
from keras.models import Sequential
from keras.layers import Dense, Activation, Convolution2D, MaxPooling2D, Flatten
from keras.optimizers import Adam
第三步,载入MNIST数据及预处理。
- X_train.reshape(-1, 1, 28, 28) / 255
将每个像素点进行标准化处理,从0-255转换成0-1的范围。 - np_utils.to_categorical(y_train, nb_classes=10)
调用up_utils将类标转换成10个长度的值,如果数字是3,则会在对应的地方标记为1,其他地方标记为0,即{0,0,0,1,0,0,0,0,0,0}。
由于MNIST数据集是Keras或TensorFlow的示例数据,所以我们只需要下面一行代码,即可实现数据集的读取工作。如果数据集不存在它会在线下载,如果数据集已经被下载,它会被直接调用。
# 下载MNIST数据
# training X shape (60000, 28x28), Y shape (60000, )
# test X shape (10000, 28x28), Y shape (10000, )
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# 数据预处理
# 参数-1表示样例的个数 1表示灰度照片(3对应RGB彩色照片) 28*28表示像素长度和宽度
X_train = X_train.reshape(-1, 1, 28, 28) / 255 # normalize
X_test = X_test.reshape(-1, 1, 28, 28) / 255 # normalize
# 将类向量转化为类矩阵 数字 5 转换为 0 0 0 0 0 1 0 0 0 0 矩阵
y_train = np_utils.to_categorical(y_train, num_classes=10)
y_test = np_utils.to_categorical(y_test, num_classes=10)
第四步,创建神经网络第一层及池化层。
小方块的长度和宽度是5,in size为1是图片的厚度,输出的高度是32。conv1输出的大小为28 * 28 * 32,因为padding采用“SAME”的形式,conv1输出值为32,故厚度也为32,长度和宽度相同为28。而由于POOLING处理设置的strides步长为2,故其输出大小也有变化,其结果为14 * 14 * 32。
核心代码如下。卷积层利用Convolution2D,池化层利用MaxPooling2D。
- nb_filters表示滤波器,其值为32,每个滤波器扫描之后都会产生一个特征
- nb_row表示宽度5
- nb_col表示高度5
- border_mode表示过滤,采用same方式(Padding method)
- input_shape表示输入形状,1个高度,28个长度,28个宽度
#---------------------------创建第一层神经网络---------------------------
# 创建CNN
model = Sequential()
# Conv layer 1 output shape (32, 28, 28)
# 第一层利用Convolution2D卷积
model.add(Convolution2D(
filters = 32, # 32个滤波器
nb_row = 5, # 宽度
nb_col = 5, # 高度
border_mode = 'same', # Padding method
input_shape = (1, 28, 28), # 输入形状 channels height width
))
# 增加神经网络激活函数
model.add(Activation('relu'))
# Pooling layer 1 (max pooling) output shape (32, 14, 14)
# 池化层利用MaxPooling2D
model.add(MaxPooling2D(
pool_size = (2, 2), # 向下取样
strides = (2,2), # 取样跳2个
padding='same', # Padding method
))
为了防止跨度太大,丢失东西太多,这里添加了POOLING处理,strides值为2,减小跨度。最终得到结果的形状都一样,但它能保留更多的图片信息。
第五步,创建第二层神经网络及取样。
conv2定义的patch为5*5,传入大小为32,传出大小为64,不断将其变厚,类似于下图所示。图片最早的厚度为1(MNIST数据集是黑白图片,如果是彩色则为3),接着第一层厚度变成32,第三层厚度增长为64。
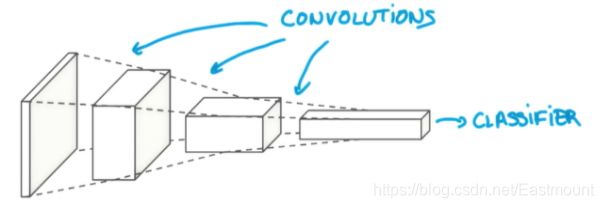
此时conv2的输出结果为14 * 14 * 64,第二层POOLING处理会继续缩小一半,pool2输出结果为7 * 7 * 64,高度不变。
# Conv layer 2 output shape (64, 14, 14)
model.add(Convolution2D(64, 5, 5, border_mode='same'))
model.add(Activation('relu'))
# Pooling layer 2 (max pooling) output shape (64, 7, 7)
model.add(MaxPooling2D(pool_size = (2, 2), border_mode='same'))
第六步,构建全连接层。
输入值为conv2 layer的输出值7 * 7 * 64,输出值为1024,让其变得更高更厚。接着第二个全连接层输出结果为分类的10个类标。
# Fully connected layer 1 input shape (64 * 7 * 7) = (3136), output shape (1024)
model.add(Flatten()) # 将三维层拉直
model.add(Dense(1024)) # 全连接层
model.add(Activation('relu')) # 激励函数
# Fully connected layer 2 to shape (10) for 10 classes
model.add(Dense(10)) # 输出10个单位
model.add(Activation('softmax')) # 分类激励函数
这里简单总结下神经网络:
- conv1 layer:经过卷积和POOLING处理,最终输出14 * 14 * 32
- conv2 layer:经过卷积和POOLING处理,最终输出7 * 7 * 64
- func1 layer:平常使用的神经网络,输入7 * 7 * 64,最终输出1024
- func2 layer:平常使用的神经网络,输入1024,最终输出10,代表10个数字,即为prediction
第七步,定义优化器并激活神经网络,接着进行训练预测,并输出相应结果。
# 优化器 optimizer
adam = Adam(lr=1e-4)
# We add metrics to get more results you want to see
# 激活神经网络
model.compile(optimizer=adam, # 加速神经网络
loss='categorical_crossentropy', # 损失函数
metrics=['accuracy']) # 计算误差或准确率
print('Training')
model.fit(X_train, y_train, epochs=1, batch_size=64,) # 训练次数及每批训练大小
print('Testing')
loss, accuracy = model.evaluate(X_test, y_test)
print('\ntest loss: ', loss)
print('\ntest accuracy: ', accuracy)
# -*- coding: utf-8 -*-
"""
Created on Wed Feb 19 19:47:37 2020
@author: xiuzhang Eastmount CSDN
Wuhan Fighting!
"""
import numpy as np
from keras.datasets import mnist
from keras.utils import np_utils
from keras.models import Sequential
from keras.layers import Dense, Activation, Convolution2D, MaxPooling2D, Flatten
from keras.optimizers import Adam
#---------------------------载入数据及预处理---------------------------
# 下载MNIST数据
# training X shape (60000, 28x28), Y shape (60000, )
# test X shape (10000, 28x28), Y shape (10000, )
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# 数据预处理
# 参数-1表示样例的个数 1表示灰度照片(3对应RGB彩色照片) 28*28表示像素长度和宽度
X_train = X_train.reshape(-1, 1, 28, 28) / 255 # normalize
X_test = X_test.reshape(-1, 1, 28, 28) / 255 # normalize
# 将类向量转化为类矩阵 数字 5 转换为 0 0 0 0 0 1 0 0 0 0 矩阵
y_train = np_utils.to_categorical(y_train, num_classes=10)
y_test = np_utils.to_categorical(y_test, num_classes=10)
#---------------------------创建第一层神经网络---------------------------
# 创建CNN
model = Sequential()
# Conv layer 1 output shape (32, 28, 28)
# 第一层利用Convolution2D卷积
model.add(Convolution2D(
filters = 32, # 32个滤波器
nb_row = 5, # 宽度
nb_col = 5, # 高度
border_mode = 'same', # Padding method
input_shape = (1, 28, 28), # 输入形状 channels height width
))
# 增加神经网络激活函数
model.add(Activation('relu'))
# Pooling layer 1 (max pooling) output shape (32, 14, 14)
# 池化层利用MaxPooling2D
model.add(MaxPooling2D(
pool_size = (2, 2), # 向下取样
strides = (2,2), # 取样跳2个
padding='same', # Padding method
))
#---------------------------创建第二层神经网络---------------------------
# Conv layer 2 output shape (64, 14, 14)
model.add(Convolution2D(64, 5, 5, border_mode='same'))
model.add(Activation('relu'))
# Pooling layer 2 (max pooling) output shape (64, 7, 7)
model.add(MaxPooling2D(pool_size = (2, 2), border_mode='same'))
#-----------------------------创建全连接层------------------------------
# Fully connected layer 1 input shape (64 * 7 * 7) = (3136), output shape (1024)
model.add(Flatten()) # 将三维层拉直
model.add(Dense(1024)) # 全连接层
model.add(Activation('relu')) # 激励函数
# Fully connected layer 2 to shape (10) for 10 classes
model.add(Dense(10)) # 输出10个单位
model.add(Activation('softmax')) # 分类激励函数
#--------------------------------训练和预测------------------------------
# 优化器 optimizer
adam = Adam(lr=1e-4)
# We add metrics to get more results you want to see
# 激活神经网络
model.compile(optimizer=adam, # 加速神经网络
loss='categorical_crossentropy', # 损失函数
metrics=['accuracy']) # 计算误差或准确率
print('Training')
model.fit(X_train, y_train, epochs=1, batch_size=64,) # 训练次数及每批训练大小
print('Testing')
loss, accuracy = model.evaluate(X_test, y_test)
print('\ntest loss: ', loss)
print('\ntest accuracy: ', accuracy)
训练一个批次的结果如下图所示,最终误差loss为“0.2520788”,正确率为“0.92650”。

训练两个批次的结果如下图所示,最终误差loss为“0.156024”,正确率为“0.95590”。

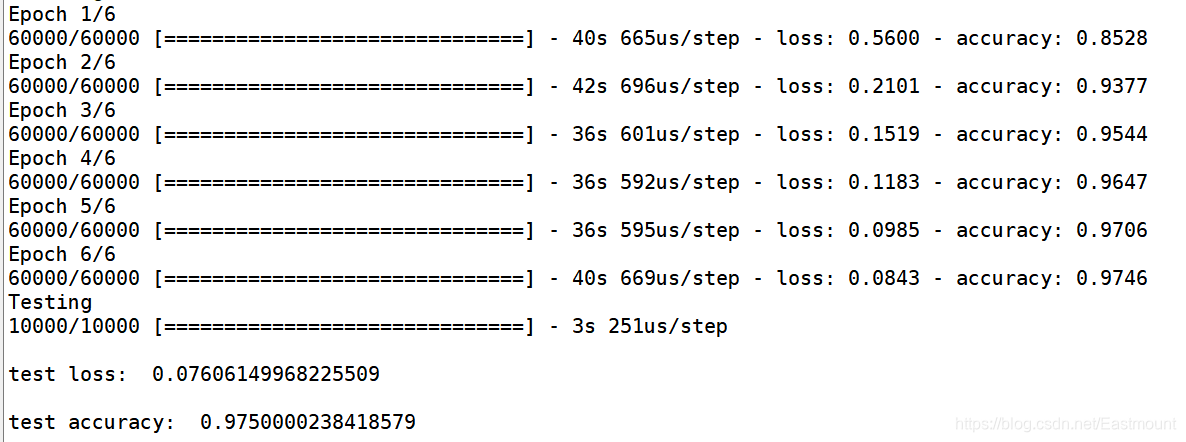
训练六个批次的结果如下图所示,最终误差loss为“0.07606”,正确率为“0.97500”。可以看到误差不断减小,正确率不断提高,说明CNN在不断学习。真正做神经网络实验时,我们会针对不同的参数和样本、算法进行比较,也希望这篇文章对您有帮助。
写到这里,这篇文章就结束了。本文主要通过Keras实现了一个CNN分类学习的案例,并详细介绍了卷积神经网络原理知识。最后,希望这篇基础性文章对您有所帮助,如果文章中存在错误或不足之处,还请海涵~作为人工智能的菜鸟,我希望自己能不断进步并深入,后续将它应用于图像识别、网络安全、对抗样本等领域,指导大家撰写简单的学术论文,一起加油!

感恩能与大家在华为云遇见!
希望能与大家一起在华为云社区共同成长。原文地址:https://blog.csdn.net/Eastmount/article/details/104399015
(By:娜璋之家 Eastmount 2021-11-09 夜于武汉)
参考文献:
[1] 神经网络和机器学习基础入门分享 - 作者的文章
[2] 斯坦福机器学习视频NG教授: https://class.coursera.org/ml/class/index
[3] 书籍《游戏开发中的人工智能》、《游戏编程中的人工智能技术》
[4] 网易云莫烦老师视频(强推 我付费支持老师一波)
[5] [Python人工智能] 八.卷积神经网络CNN原理详解及TensorFlow编写CNN
[6] 机器学习实战—MNIST手写体数字识别 - RunningSucks
[7] https://github.com/siucaan/CNN_MNIST
[8] https://study.163.com/course/courseLearn.htm?courseId=1003340023
[9] https://github.com/MorvanZhou/tutorials/blob/master/kerasTUT/

- 点赞
- 收藏
- 关注作者
评论(0)