漫画趣解机器学习算法建模:买瓜

大数据开发如何转型算法?
算法建模主要做什么?调参为什么玄学?
如何通俗理解算法建模过程。。
夕阳下的村东头,有一人来买瓜。
1 引子(买瓜)
忙碌的一天刚刚结束,村里的小张就匆匆的骑上车,准备买个西瓜解暑。

天气可真热,等会一定要挑个又甜、又熟的大西瓜。
心里嘀咕着,小张慢慢的来到了村东头水果摊前(这里的瓜最好)。

老板,你这西瓜保熟吗?给我挑个甜的、熟点的。
放心好了,看看这瓜纹和瓜蒂,而且我都是自家种的,肯定保熟。
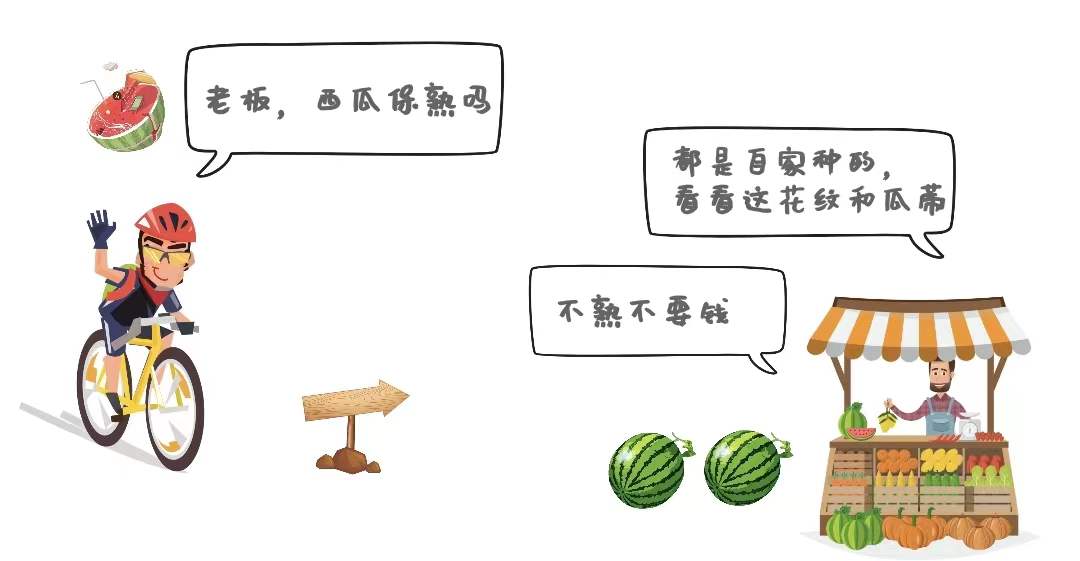
小张心里直打鼓: 瓜蒂蜷曲、瓜纹青绿,看起来貌似是好瓜。但是之前按这标准买的瓜,吃起来并不甜。
回想起父辈的挑瓜经验:敲声浊响的才是好瓜。于是就再敲了敲几个大瓜,嗯,声音倒是没错。

保险起见,还是货比三家靠谱。小张走向其他店铺,又挑了不同种类和大小的西瓜,并试吃了一些。
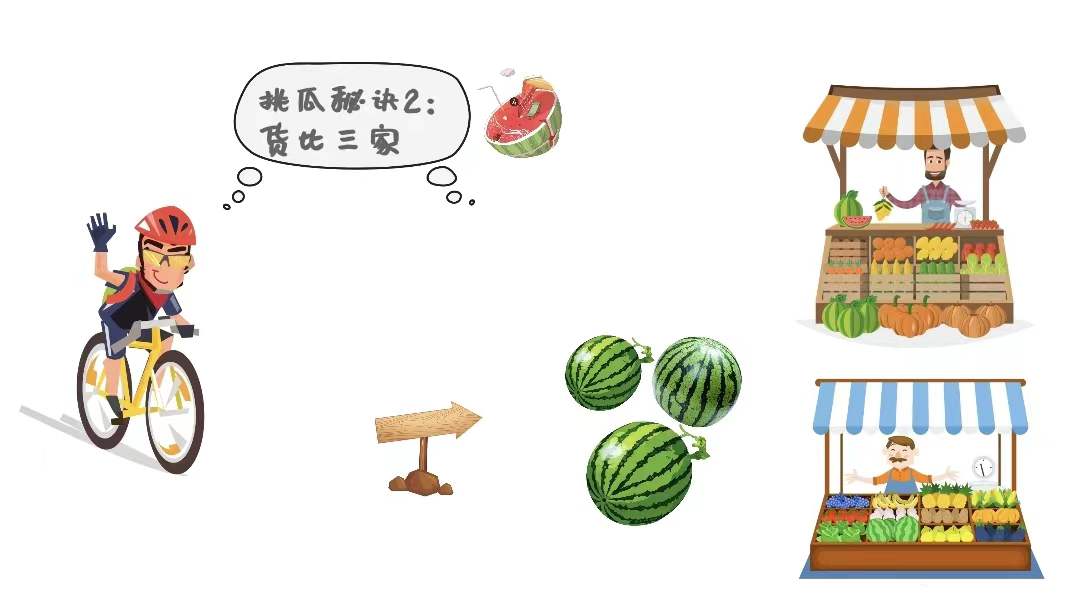
经过了几分钟斟酌,在众老板的欣慰目光中,小张终于选好了一个皮薄、颜色青绿、根蒂卷、敲击会发出浊响的大瓜。
现场切开尝了下,味道很甜。

开心的小张付完钱,嘴里哼着小调,骑行而去。。
2 算法建模到底在干什么
小张最后买到了好瓜,好奇的我们先来围观一下他的买瓜过程 :
-
自己想买个又甜又熟的大西瓜 -
筛选西瓜的 颜色、瓜蒂、声音、种类和大小 -
根据总结的 选瓜方法在不同的瓜摊中挑选试吃 -
综合对比,选出了 最好的一个瓜,实现了西瓜自由
大白话概括买瓜流程
先确定一个预期目标(买到好瓜)和选瓜环境(村东头);其次总结选瓜方法(父辈经验)和选瓜特征(颜色、瓜蒂等);最后根据这套方法论 + 实战,货比三家,对比得到了最好的预期结果(一个好瓜)。
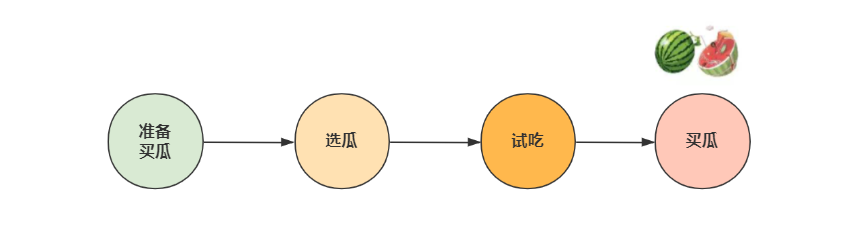 买瓜流程示意
买瓜流程示意
故事中的小张凭借多年挑瓜经验,总结好瓜的特征: 皮薄、青绿瓜纹、曲根蒂和浊响声。根据这些特征,现场进行望闻问切,多次实验,选出最好的瓜。
现在换个角度,假设有台机器可以帮我们这些事情。
我们给机器输入一些西瓜的数据:包括各种西瓜的大小、种类、颜色、瓜蒂和敲击声等信息,再提供一些计算好瓜的算法公式,希望机器能够稳定、准确的帮我们筛选出好瓜和坏瓜。
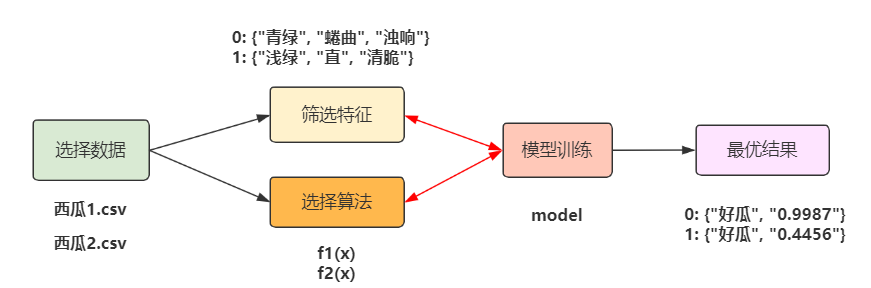 机器买瓜流程示意
机器买瓜流程示意
通俗理解,这就是大数据算法建模所做的工作。
大数据算法建模核心思想
在理解业务背景、数据含义的基础上确定预期目标;数据预处理后,选择合适的算法和数据特征并构建模型,训练最好的模型帮助我们最大化逼近(预测)预期目标。
 买瓜建模流程
买瓜建模流程
3 大白话讲解算法建模流程
前文介绍了算法建模帮我们解决了什么问题?接下来瞅瞅如何进行算法建模。
我会详细介绍算法建模的具体流程,并借助于买西瓜的例子说明。
为避免内容枯燥,后面画了大量示意图,方便理解
先来看看整体的算法建模流程:
 大数据算法建模整体流程
大数据算法建模整体流程
1)流程说明
整体大致可分为业务/数据理解、预处理、特征工程、模型训练、模型评估和预测几个步骤。
-
首先要理解
数据和业务目标,即明确目标和测试的数据。比如说我想挑一个好西瓜,你总不能去个早餐店拿两个包子回来吧? -
其次是数据预处理工作。一般读取的数据是存在一些空值、异常值等其他
非友好的特性,需要做些特殊处理。 -
在预处理基础上,进一步获取为模型所用的数据(
特征),被称作特征工程。在买瓜过程,小张就很老道的看瓜纹、瓜蒂、听敲击声,这些就是好瓜的特征。 -
特征工程完成后,可以选择合适算法进行
模型训练。此时通常将数据集分成测试集和验证集,以此检验模型效果,即区分好瓜的正确程度。 -
经过几轮模型训练和特征工程(过程可迭代、可双向),获取效果最好的模型,在真实数据集进行
预测(切瓜)。
2)数据、业务理解
常有的一个误区:
即无需事先确定目标和数据,总以为能够找到一个完美的算法,能够帮我们自动获取数据规律。
但是算法并不是万能的,需要与之适配的数据和使用场景。再好的剑也需要有温养的环境和一副好剑鞘。
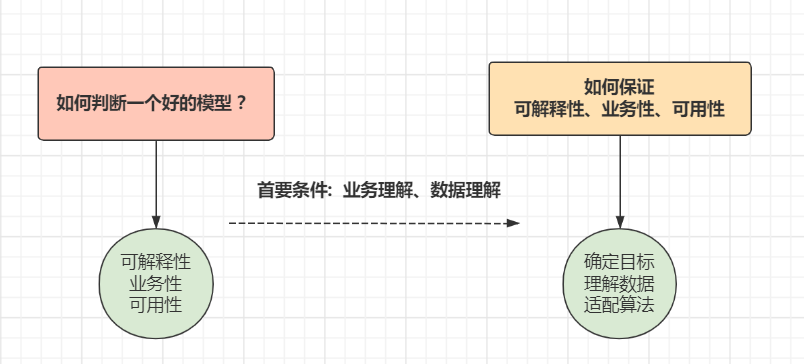
3)数据预处理
算法建模中的数据来源为数据同事开发的指标。比如用户产品推荐,就需要加工一些用户行为指标。
当然这些加工后的数据不能直接给模型使用,需要进行处理。
-
饱和度(空值填充、异常值过滤) -
无量纲化:将数据转换为同等规格。比如特征的少量数值过大,可以统一缩放到[0,1]范围,降低样本计算影响程度) -
定量数据转换:比如西瓜的敲击声(清脆、浊响)转换为数字形式(00、01),进行哑编码(定量编码的一种)。 -
定性数据转换: 比如根据西瓜的重量是否大于5斤,将西瓜的重量分为[0,1]两类,便于数学计算。
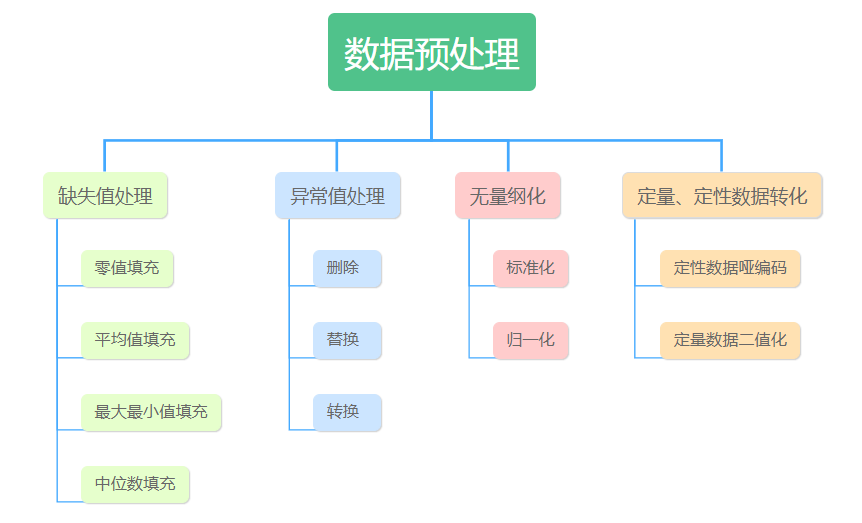 数据预处理工作内容
数据预处理工作内容
4)特征工程
特征工程的主要目的是选择具有价值的数据信息,帮助模型快速和准确训练和预测。
好的数据和特征可以决定训练模型的上限。
举个例子:选西瓜过程中,经验丰富的小明对比不同种类西瓜的纹路、瓜蒂、敲击声、尺寸和种类等特征,快速挑选出想要的好瓜。
假如小明是个新手,那么可能只会根据瓜的大小、颜色来区分,认为大而绿的就是好瓜,当然结果可能相差十万八千里。
特征工程的主要工作内容主要如下:
-
基于样本特性筛选特征: 使用数据
统计学知识,比如计算特征的方差、相关系数、分箱/WOE、IV值和信息熵等,筛选出结果比较好的特征。 -
基于模型筛选特征: 将部分特征放入到模型中训练,筛选效果好的特征,适用于特征数据量比较大的场景,比较精确。
-
特征衍生:需要引入一些衍生特征(组合旧特征、开发新特征),提高特征的丰富性
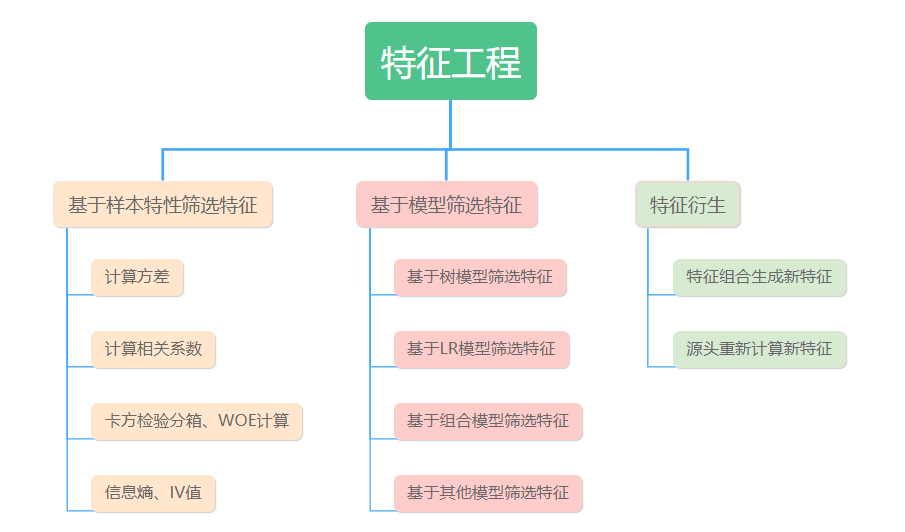 特征工程工作内容
特征工程工作内容
5)模型训练
在完成特征工程的基础上,需要选择适配的机器学习算法,构建模型。
这里建议可再次计算部分特征的IV值、信息熵等,确保特征完整性。
常见的机器学习算法:
-
监督学习:包含分类和回归两大类。常见的算法有LR、树算法、神经网络和GBRT等,其中
LR逻辑回归和树算法常用于解决风控场景 -
非监督学习:聚类算法、PCA算法和关联规则等算法。其中
Kmeans算法被广泛运用于数据挖掘分类场景,关联规则则应用于推荐中。
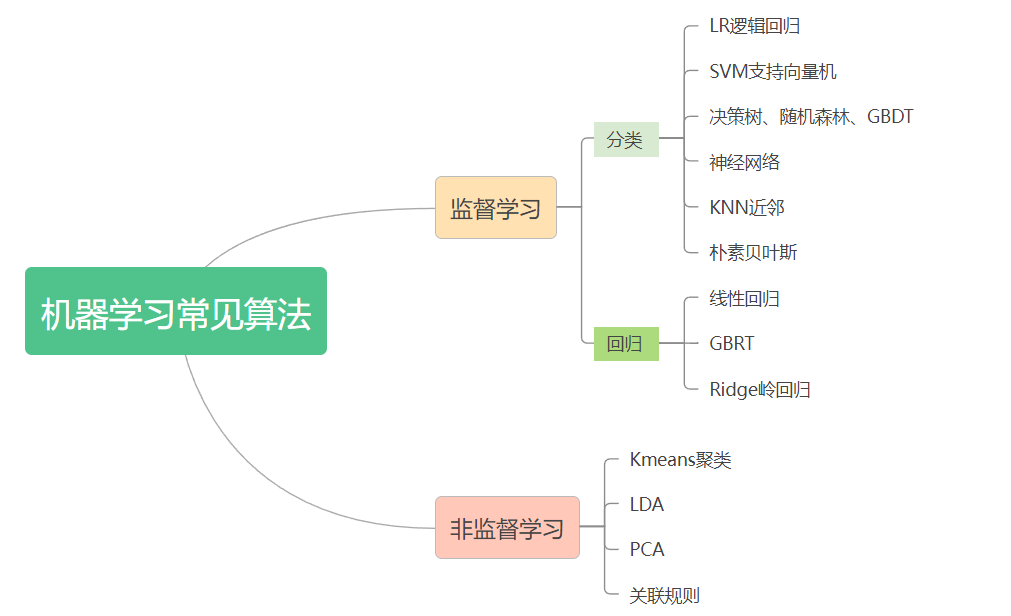
选择好算法和特征,开始训练模型。训练时间会很长且过程可逆,可适时调整特征和算法迭代。
6)模型评估
模型需要在训练集和验证集上进行训练,如何判断模型训练效果呢?
一般需要从两方面去考虑,即模型准确性和稳定性。
-
准确性评估
模型能否正确预测结果。比如判断一颗表皮青绿、瓜蒂蜷曲、敲击浊响的瓜有多大概率是好瓜。
常用方法:混淆矩阵、KS曲线、ROC曲线等
-
稳定性评估
即模型的稳定性,防止随着时间推移,应用模型的样本特征可能会发生变化,影响模型的预测结果。常通过计算特征的PSI值(变化程度),调整模型。
常用方法:PSI计算
小于10%,则无需更新模型;10%-20%, 需检查变化原因,加强监控频率;大于20%,则模型需要迭代。
7)预测
将模型带入到真实预测集中,预测结果。
| 序号 | 颜色 | 瓜蒂 | 敲击声 | 好瓜 |
|---|---|---|---|---|
| 1 | 青绿 | 蜷缩 | 浊响 | 0.958 |
| 2 | 乌黑 | 蜷缩 | 浊响 | 0.943 |
| 3 | 青绿 | 硬挺 | 清脆 | 0.412 |
| 4 | 乌黑 | 稍蜷 | 沉闷 | 0.533 |
4 算法建模如何学习
上面简单介绍了下大数据算法建模的基本流程。
由于篇幅问题,不详细之处,可添加我的wx: youlong525交流。
其实在实际工作中,我们可能大半时间都集中在特征处理和模型训练,当然还有玄学的调参。
一个模型运行的好坏,可能会和多种因素有关。需要在掌握底层原理和技术手段的基础上,根据自己的经验去慢慢调试。
而至于如何去学习入门算法建模,这里也提供个人学习方法和路线(仅供参考)。
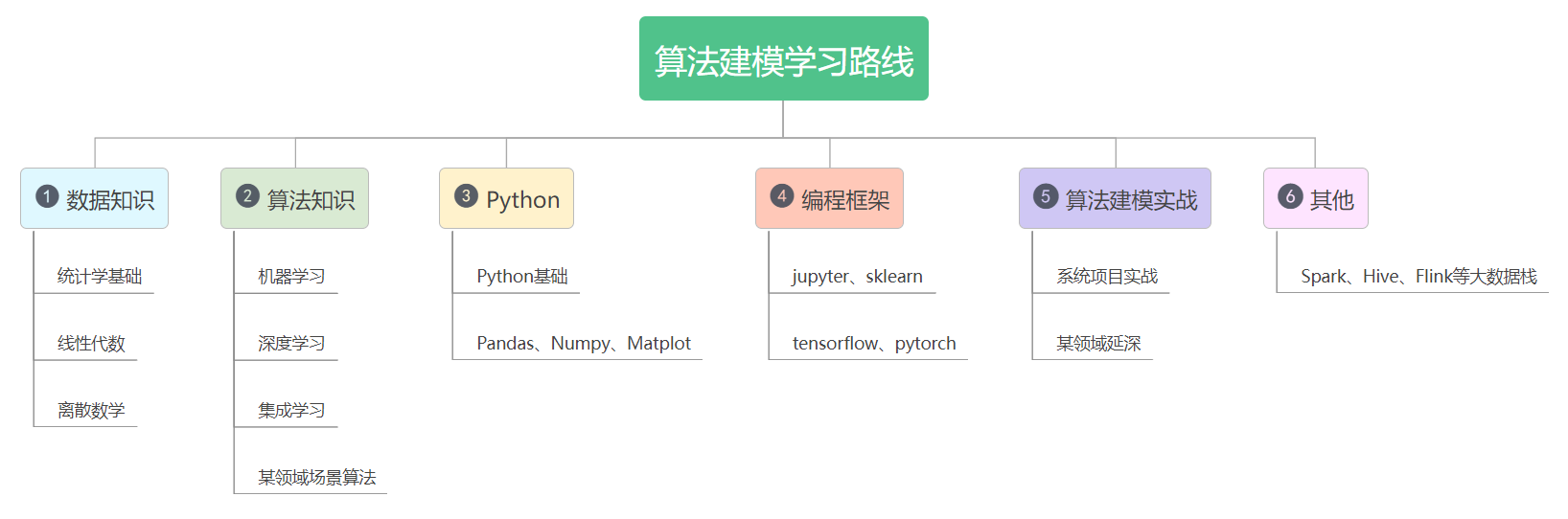
-
数据知识:统计学、线性代数和离散数学 -
算法知识:机器学习、深度学习算法、某领域场景算法 -
Python基础知识:可以对照菜鸟教程学习 -
Python数据分析:Pandas、Numpy、Matploblib -
框架学习:jupyter、sklearn、tensorflow、pytorch -
算法建模实战:系统项目实战、领域延深 -
其他:Spark、Hive等大数据技术
5 一些误区和建议
1)做算法建模是不是只会算法就好了?
并不能这么说,正如文中所说特征和数据是决定模型的上限。特征处理也要很精通,特别是python和pandas等技术
2)特征工程和数据预处理的关系?
其实这两者都可以归为特征处理,也即特征工程包含预处理,都是进行数据处理和特征筛选,只不过有的技术体系将其单独划分。
3)模型的准确度不好,如何调参?
我的建议是先去看你的数据,观察特征的饱和度、IV值、PSI值等,一般不好的特征很大程度影响模型好坏。随后再去调整模型的超参数,只有你的特征比较好,调整超参才能发挥更好的效果。
4)没基础怎么学习算法建模
建议可以按照我上面推荐的学习路线去看,其实算法建模对于没有基础的朋友来说是有蛮高门槛的,推荐一定要把算法理论和数学理论学扎实点,不要深究,理解并会使用即可。
5)那么多编程框架怎么选?学习哪个好
框架只是一个工具,方便编码和调试;重要的是把基础知识学好,任意选择一个即可,推荐pytorch。
6)一点点建议
建议先把基础知识打牢,包括算法和数学知识,这样在后面会学的很轻松。 至于python、pandas、pytorch等全是工具组件,比较好入门。一开始不用铺开学习所有算法,建议学习一些常用的,后面根据具体场景实战中学习即可。
6 写在最后
有一人来买瓜,这瓜保熟。。
》》》更多文章,欢迎关注我的gzh:大数据兵工厂

- 点赞
- 收藏
- 关注作者
评论(0)