基于Spark+Grafana可视化电商项目实战,好文收藏

本系列为大数据项目实战系列,每期内容将讲解项目背景、技术架构和核心代码部分,帮助相关小伙伴快速了解大数据项目与技术。
在上期的基于Spark GraphFrame社交网络实战项目中,介绍了Spark图计算与社交关系图谱,文章反响很好。
本期将继续介绍基于Spark和Grafana的电商零售分析项目,在文末附有电商数据集下载地址,欢迎大家自行领取。话不多说,我们开始。
项目环境:JAVA、IDEA 项目技术:Spark、Grafana 技术难度:中等
互联网背景下的大数据、AI领域不断创新,衍生出多样化的电商平台和商品推荐模式。
作为消费者,当我们打开某款购物APP时,随着你在平台上浏览商品并点击,计算机在后台会记录你的用户行为,并为你生成专有的客群画像,真正做到了千人千面、精准推荐的效果。
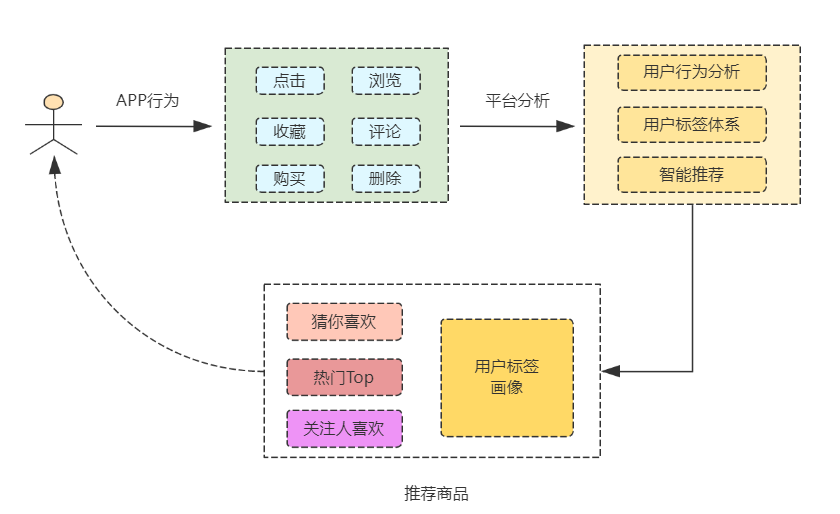
关于智能推荐和用户画像怎么实现,我们将在后期系列中讨论。
本项目主要对零售商品进行数据分析,通过技术手段,分析哪几款商品需求量最大(购买排行top5)、热门商品每日变化趋势、哪些省份是消费大省市(消费省份分布)、购买群体男女比率(用户群体分析)。
项目基于Spark组件和Grafana工具,通过Spark数据分析,进行数据清洗、转换、计算并保存,最终Grafana进行可视化大屏展示。
2 系统介绍
项目程序采用Java语言编写,技术组件采用Spark和Grafana工具。
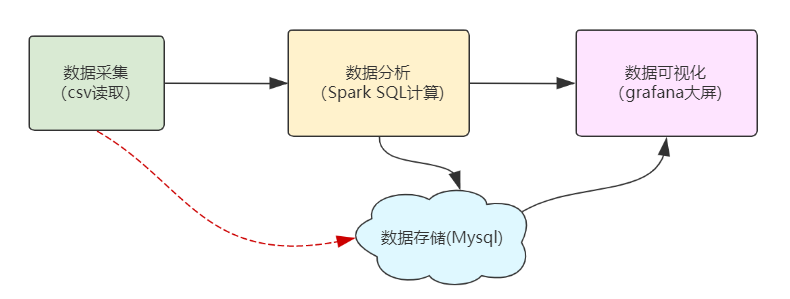
系统整体分为数据采集、数据分析、数据可视化核心部分。
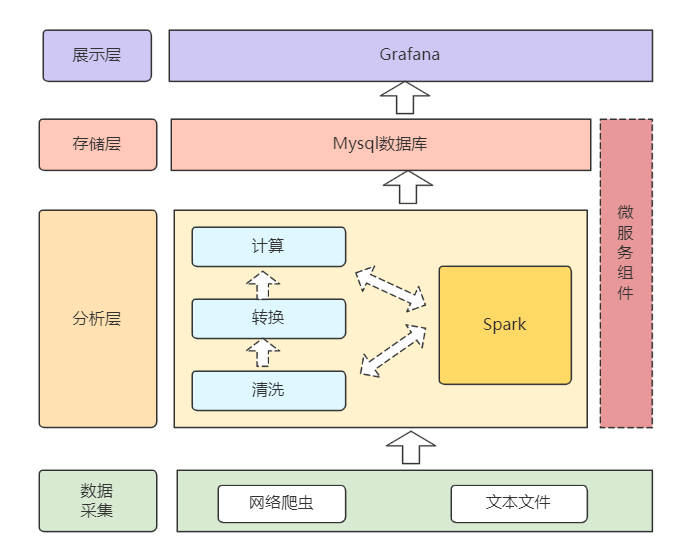
1)整体技术架构
-
数据采集层
通过
网络爬虫或者下载公开数据集的技术手段(文末提供免费数据集下载)收集电商零售数据,形成结构化文本文件、数据表。 -
数据分析层
基于微服务和Spark技术栈构建。微服务组件作为系统基础底座(
非必须),一般公司有专门的微服务团队去做。Spark作为数据分析组件,提供Spark内存计算、
Spark SQL数据查询统计等功能,完成数据的加工、查询和结果存储。 -
数据存储层
Spark计算后的数据落地到存储介质中,向外提供数据访问能力,项目中使用Mysql(redis、Hive也可)。
-
数据展示层
在展示层的技术选型方面,我选择了
Grafana: 一个提供几百种数据源、多种图形样式库的可视化大屏组件,且支持SQL,比较方便。
2)数据流程设计
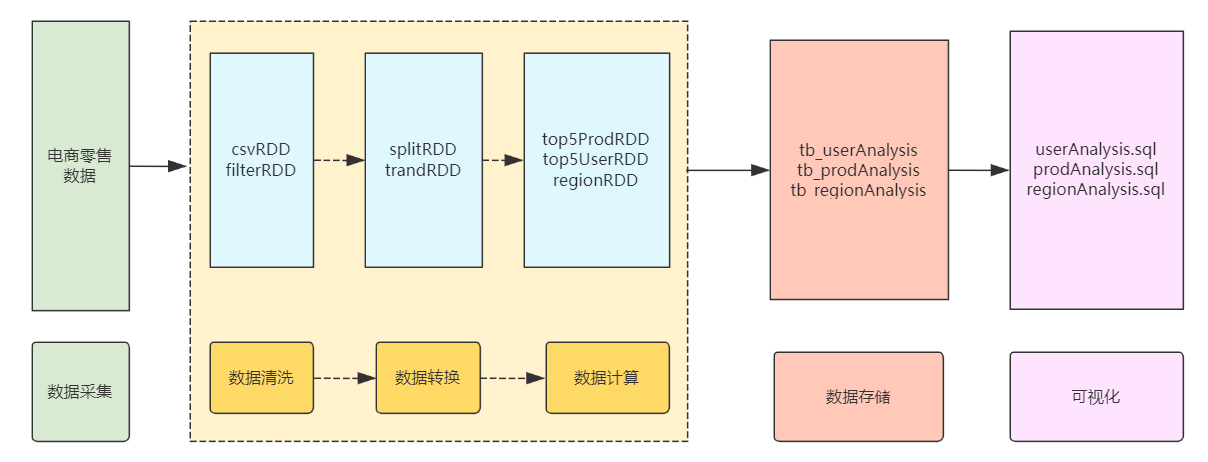
数据从源头的结构化形式(csv/table)转换为Spark的RDD形式,并最终流转到数据库中的table表形式存储。
-
Spark程序读取源数据(csv、table)并转成RDD(
csvRDD) -
经过重复值、异常值、时间格式处理,形成中间RDD(
transRDD) -
Spark SQL进行数据指标计算(
top5xxRDD),计算销售排行、用户省份分布等指标并保存到Mysql中(tb_xxAnalysis) -
Grafana中进行SQL查询展示,绘制大屏。
3)相关技术
-
Spark引擎
大数据生态圈常用
计算引擎,内存级分布式分析框架,包含Spark Core、Spark SQL、Spark Streaming、Spark MLlib和Spark Graph等模块。具体资料可以看我的相关文章,此处不再赘叙。
-
Grafana组件
Grafana是一个开源的
可视化和分析平台。提供查询、可视化、告警和监控等功能。内部支持多种数据源,提供多种面板、插件来快速将复杂的数据转换为漂亮的图形和可视化的工具,可自定义告警规则。
3 程序实现
前面铺垫了这么多,下面我们来看看代码方面怎么实现的。
先看下整体的架构,正如前面所说。我们在这里分成了数据采集、数据分析和数据可视化三个部分。
3.1 系统环境
-
Maven 3.5、Mysql 5.7
-
jdk1.8、scala 2.12
-
spark 3.0.2
-
grafana 8.5
3.2 Spark初始化
1)环境jar包依赖
这里使用了引入了spark-core和spark-sql的依赖包,且使用SparkSession方式创建SparkContext上下文。
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.0.3</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.0.3</version>
</dependency>2)Spark脚本
在系统入口这里,为了方便本地和服务器运行灵活性,可支持批量任务或者单个任务方式执行,通过参数传入控制。
-
包括执行的程序类名、执行标志
-
执行日期范围(不传默认全量)
// 计算kpi列表(kpi.txt)
ProductAnalysis 1 2019-11-24 2019-12-22
RegionAnalysis 2 2019-11-24 2019-12-22
UserAnalysis 1 2019-11-24
// 服务器执行脚本
#!/usr/bin/env bash
SPARK_HOME="/usr/hdp/xxxx/spark"
SPARK_MASTER="yarn"
MAIN_CLASS="com.demo.spark.analysis.launcher.AnalysisLauncher"
SPARK_SUBMIT_OPTS="--master yarn-client --driver-memory 20g --executor-cores 8 --executor-memory 40g --num-executors 5"
...
// 执行脚本命令
sh analysis.sh kpi.txt 3)Spark启动
这里为了方便观察,统一改为Local运行模式;将执行类放入数组,使用Java反射机制动态执行分析子类。
// 解析传递的kpi.txt中的执行类参数
// PRODUCT_CLASS_NAME、USER_CLASS_NAME
// String[] classNames = parseArgs(args);
String[] classNames = {PRODUCT_CLASS_NAME, USER_CLASS_NAME, REGION_CLASS_NAME};
for (String className: classNames) {
Class c = Class.forName(PACKAGE_NAME + className);
BaseHandler handler = (BaseHandler) c.getConstructors()[0].newInstance();
logger.info("数据分析开始...");
handler.execute(spark, sparkContext);
}3.3 数据采集模块
使用SparkSession的read()算子读取csv文件,设置编码格式,并进行简单的重复值、异常值及缺失值处理; 结果保存到数据库表中。
// 读取csv文件并处理
Dataset productCsvDS = spark.read()
.format("csv")
.option("delimiter", ",")
.option("encoding", "gbk")
.schema(productStructType)
.option("header", "true")
.load(ORDER_FILE_PATH)
.na() // 空值删除
.drop( new String[] {"name", "price"});
// 写入Mysql订单表 (解决中文乱码:设置Mysql 编码utf8)
productCsvDS.write()
.mode(SaveMode.Overwrite)
.jdbc(JDBC_URL, DB_TABLE_PRODUCT, jdbcProperties);
// 定义StructType
private static StructType getProductStructType() {
StructType productStructType = DataTypes.createStructType(new StructField[]{
DataTypes.createStructField("id", DataTypes.StringType, false),
DataTypes.createStructField("name", DataTypes.StringType, false),
DataTypes.createStructField("price", DataTypes.DoubleType, false)
...
});
return productStructType;
}3.4 数据分析模块
使用Spark SQL和Spark内置算子进行数据统计,不同场景的分析子类均需要实现execute()方法。
// 子类继承抽象父类execute()方法
public abstract class BaseService {
public void execute(SparkSession spark, JavaSparkContext sparkContext){
// TODO: 继承子类方法
// 1. 用户行为分析
// 2. 零售产品分析
}-
用户月度购买量省份分布分析(示例)
// 注册临时表
prodCsvDS.registerTempTable("product");
orderCsvDS.registerTempTable("orderinfo");
// 列换行;分割prod_ids
String prodSplitSQL = "select " +
" order_id,order_dt," +
" products, prod_view.prod_id," +
" user_id,user_region" +
" from orderinfo " +
" lateral view explode(
split(products, '-')) prod_view as prod_id";
Dataset prodSplitDS = spark.sql(prodSplitSQL);
prodSplitDS.registerTempTable("order_prod");
// 数据统计&结果保存
String top5regionSQL =
" select " +
" a.dt as dt," +
" a.region as region, " +
" a.cnt as cnt" +
" from (" +
" select " +
" max(order_dt) dt," +
" user_id,region," +
" count(1) cnt " +
" from orderInfoDS " +
" group by user_id,region" +
" ) a " +
" order by a.cnt desc" +
" limit 5 ";
Dataset top5regionDS = spark.sql(top5regionSQL);
top5regionDS.write()
.mode(SaveMode.Overwrite)
.jdbc(JDBC_URL, DB_TABLE_REGION_TOP5, jdbcProperties);
更多代码方面的问题以及获取电商零售数据集,欢迎咨询我的wx: youlong525
3.5 数据可视化模块
经过数据分析计算后,指标落表到Mysql数据库中。这时我们可以在Grafana界面中配置相应的图表。
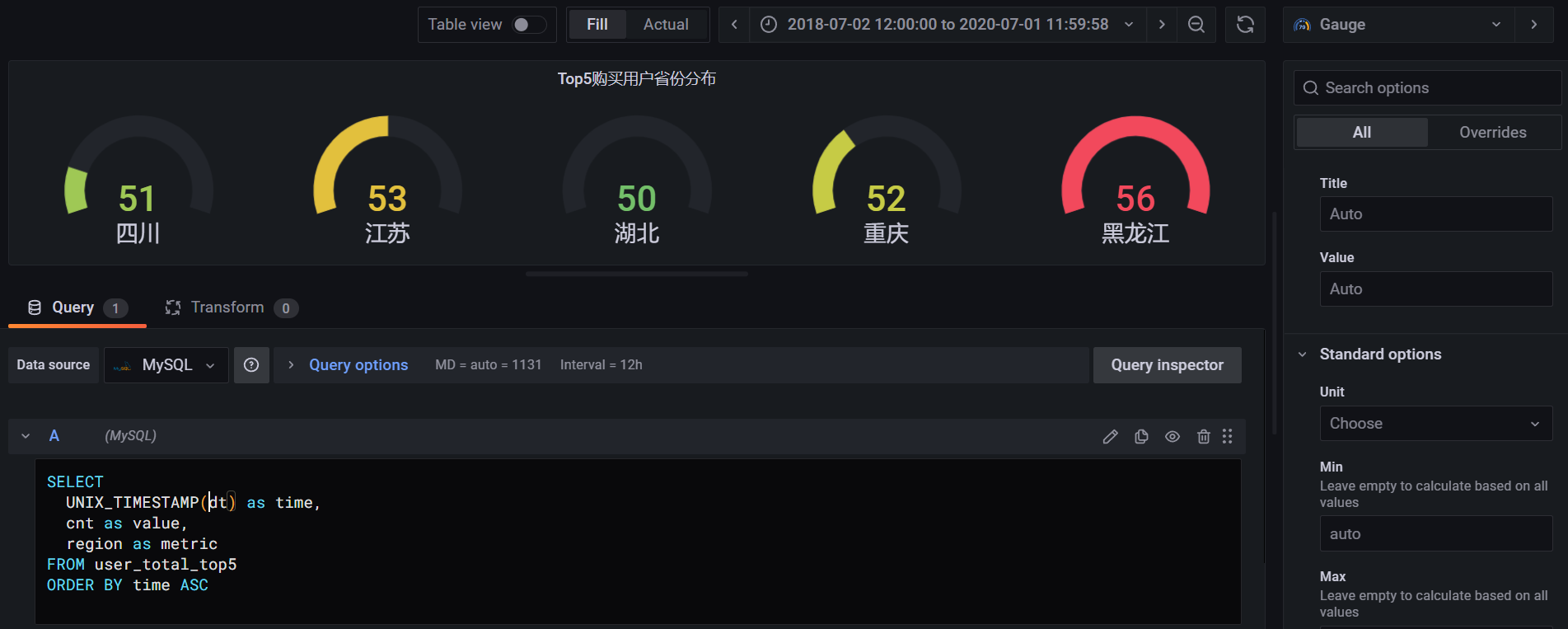
如图所示省份状态分布情况中,我选择了仪表盘图形,并且进行了简单的页面SQL编辑获取数据(需要提前配置Mysql数据源)。在编辑页面中支持对图表的属性进行微调,提供丰富多样的图表库。
在经过了合适的图表选择和属性配置,并且设置取数时间范围和刷新频率以,最终得到完整的项目成果: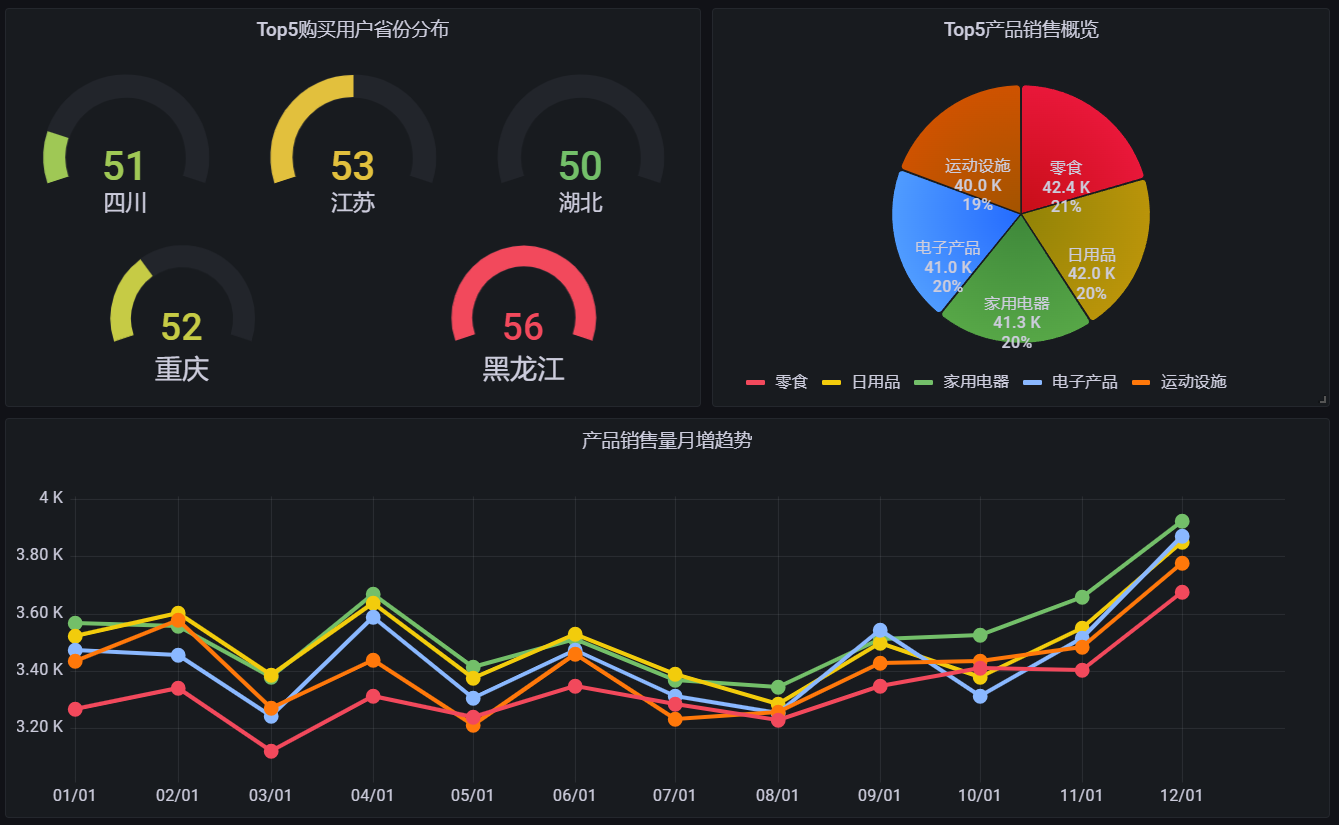
4 写在最后
本项目是基于Spark和Grafana技术栈实现的电商零售可视化大屏系统,因时间问题可能并没有做的很完善,仅作为一个可视化项目的入门尝试,希望能给朋友们提供一个研究方向参考。
其中Grafana目前支持很多数据源。除了常见的关系数据库,还支持Nosql数据库、Prometheus、Redis等,且社区规模也在不断壮大,结合其他组件可以做出很酷炫的监控大屏。感兴趣的小伙伴可以去看看,我也放上他的官网链接:https://grafana.com/docs/。

- 点赞
- 收藏
- 关注作者
评论(0)