一文理清数仓治理和成本管理的那些事

今天和大家聊聊数据治理的那些事儿。
随着公司业务的发展,数据平台发展到一定规模,伴随而来的是数据资产越来越庞大,业务对数据分析的需求越来越丰富。
而传统的数据开发模式,由于缺乏系统的管理和规范,将越来越无法满足业务日益增长的数据分析需求,数据运维也会变得十分痛苦。
面对纷繁复杂的数据,我们该如何治理?从何下手?我将带你从零开始了解如何构建数据治理体系。本文整体内容包括:
1 我们有什么数据
1.1 元数据是什么
我们要使用数据,首选需要理解数据。
当你看到一个数字5000万,如果不告诉它的业务含义、统计口径是什么、数据来源是什么、计算逻辑是怎样的,那这个数字将毫无意义,你也根本无法有效的使用它。
而这里说的业务含义、统计口径、数据来源、计算逻辑等就是元数据,它是对数据属性的描述。
1.2 为什么要元数据
随着数据业务的发展,我们会有越来越多的表、字段、计算任务、数据模型。
面对上千张表、上万个字段,任何人都无法做到对所有的数据心中有数,信手拈来。如果没有 元数据的管理,越来越多的数据给我们带来的不是资产,而是负担。
找数据越来越难,团队不同成员之间数据共享和沟通成本越来越高,数据开发和分析师的记忆负担也越来越重。
1.3 有哪些元数据
业界划分元数据大致可以分为三类:数据字典、数据血缘和数据特征。
1.3.1 数据字典
数据字典,顾名思义,就跟我们学习语文英语用的字典一样,存储了每个数据对象的基本信息和释义。
以数据表为例,数据字典应该包括表名、注解、包含字段、字段含义、字段类型、来源任务等。

数据字典可以帮助我们快速检索查看某个数据的含义和其他属性。
对于数据开发和应用中的数据共享、高效使用和知识传承的作用就更加不言而喻了。
1.3.2 数据血缘
数据血缘是描述数据之间上下有关系的元数据。就跟人与人之间的血缘关系一样,数据血缘主要记录每个数据对象的来源和去向。
根据血缘可以排查上游数据和相关计算任务,从而快速定位和解决数据问题的根源。
当某个数据表有结构变更或者计算逻辑变更的时候,我们也可以快速罗列其所有的下游数据和相关计算任务,并完成相应更改适配。
除此之外,数据血缘在数据模型评估、数据质量监控、数据成本价值分析中有广泛的用途。
1.3.3 数据特征
一些读者可能是第一次听到这个词,数据特征相比于数据血缘和数据字段的确更少露面,但是在数据治理中也同样十分重要。
数据特征是数据对象的一些动态和标签属性。相比于数据字典包含的数据本身静态的、客观的基础属性,数据特征则是一般是数据动态或者主观的特征。

数据特征极大的方便了我们对数据进行分类管理、成本控制和价值评估等。
1.4 元数据采集
在数据开发业务中,往往会有各种类型的数据源,比如MySQL、ClickHouse、Hive等。
因此,我们的元数据采集必须支持多种类型的数据源采集。
1.4.1 数据字典采集
数据字典采集一般采用数据源适配+定时拉取同步的模式。
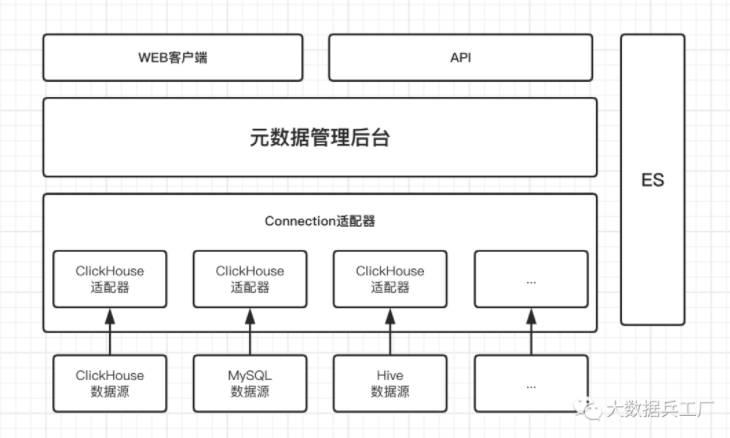
系统通过实现不同数据源的适配器连接不同类型的数据源,并向上抽象为统一的接口供管理后台调用。
上层则可以基于统一的接口来实现对元数据的拉取、更新、存储和检索等。
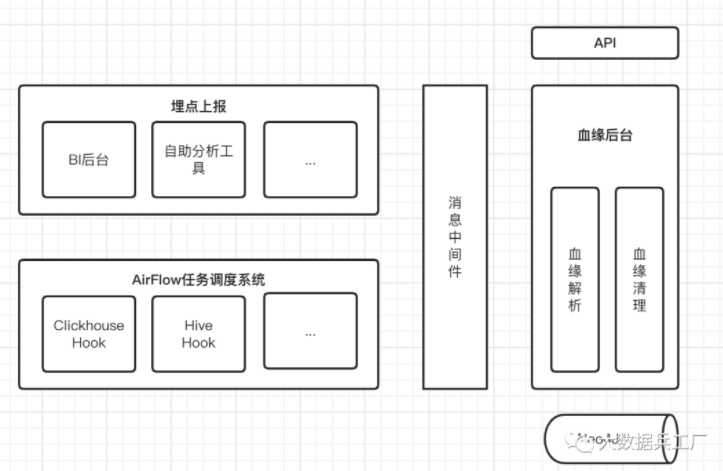
1.4.2 数据血缘采集
获取并解析计算任务的SQL语句来获取任务的输入表和输出表,以及对于字段的关系。
相比于事后分析各个计算任务的日志,这种方式既可以保证血缘采集的及时性又可以保证血缘关系的准确性。
对于SQL语句的实时获取,可分为两种场景来处理。
1)BI 后台、自助分析工具实时查询
通过在后台代码对存储组件接口调用埋点上报的方式将执行成功的 SQL 语句写到消息中间件中。
2)定时执行的批处理任务
以Airflow 工作流引擎为例:通过Hook机制实现了对各类计算任务的 SQL 语句获取与上报,这些 SQL 语句同样会写到消息中间件中。
消息中间件的另一端则是数据血缘后台服务。对中间件的消息进行解析之后,通过Neo4j(一种图数据库引擎)来存储血缘关系。
整体架构可以参照下图:
1.4.3 数据特征采集
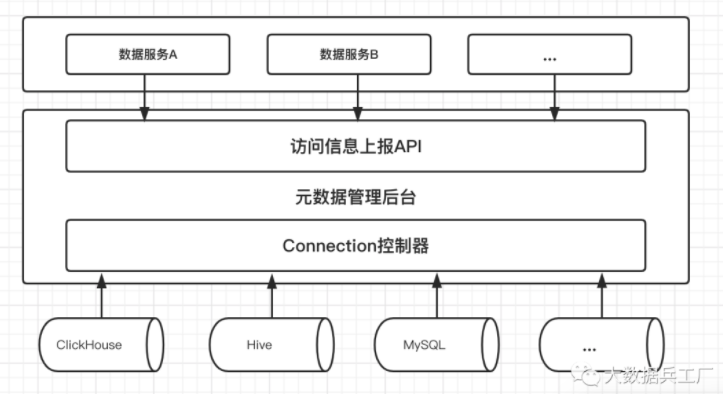
数据特征采集相对简单,通过调用各类数据存储组件的 API 来获取诸如存储大小、分区信息、访问热度等信息。
另一方面则是在各类数据服务的对外 API 处埋点,上报各个数据的访问行为,最后进行汇总分析获得数据的访问特征等。
2 数据质量
有了以上的基础设施,我们便可以建设自己的数据质量体系了。
2.1 问题分析
在传统的烟囱式开发模式下,缺乏有效的数据质量监控,当业务的某个报表数据不对,或者数据产出延迟,往往不能被及时发现。
由于数据和开发人员的割裂,当数据使用方发现问题并反馈时,数据团队才被动地开始查找定位问题,而这还只是刚刚开始。
好不容易找到问题报表对应的数据开发或分析师,让他定位问题。他基于自己的记忆,好不容易找到自己的任务,发现数据计算逻辑没问题。
然后层层定位,发现是某个上游数据发现变更没有通知下游,数据出现了问题久矣。没办法,我们只能对下游计算逻辑进行相应修改,然后回溯重跑以前的数据。
这些问题可以归结为以下几点:
-
数据问题发现慢
-
问题根源定位慢
-
修复数据成本高
2.2 问题根源
要解决数据质量的问题,我们首先找到问题的根源。 在实际的业务场景中,数据出问题的原因是多种多样的,总结起来主要有一下几类:
-
数据源的意外变更
-
数据计算逻辑错误
-
计算资源不足
-
计算基础设施不稳定
2.3 解决思路
面对这些问题,我们如何能快速定位,并低成本的修复数据呢?
我觉得可以从以下几个方面对数据进行监控:
-
产出时效性监控
-
分区数据完整性检测
-
数据合法性校验
-
字段唯一性校验
-
数据的量化评价
产出时效性监控即数据表当天的分区数据进行监控,设置指定的时间阈值,未在规定时间内产出当天分区则发出告警通知。
分区数据完整性检测是对当天的分区数据进行总数统计,并与历史数据进行同比和环比计算,据此推测当天产出数据在大体上是否完整。
数据合法性校验就是根据指定规则校验数据的合法性,比如枚举值类型的字段校验是否有效、字符串类型字段是否满足正则表达式规则等。
字段唯一性校验则是对应该在分区内唯一的字段进行校验,看是否存在异常重复值,并统计重复比例和数量。
最后是数据的量化评价,根据业务需求判断这些统计值偏离正常范围的程度,并计算出数据质量的量化指标,最终综合度量数据模型的质量。
2.4 解决办法
对于单个表的数据质量检测,可以制定一套检测流程,如下图所示。
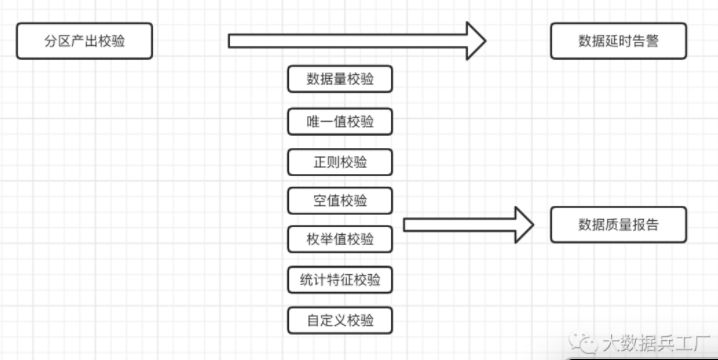
通过对上图的各种指标的检测,最后产出数据质量报告供该数据的订阅者查阅。有了单表监控之后我们就可以对数据仓库的每张表都设置特定的监控策略,表的关注者就能及时收到相关的告警信息。
然而,在实际工作中,单单只是对每个表的监控和检测还会产生很多问题。比如当一个上游表出错或者延迟的时候往往会导致其下游的所有表都接连出错或者延迟。
这时候我们就会收到大量的重复告警,常常反而把重要的告警或者问题源头给掩盖了。
因此,我们还需基于数据血缘设置具有依赖关系的数据质量检测任务集。
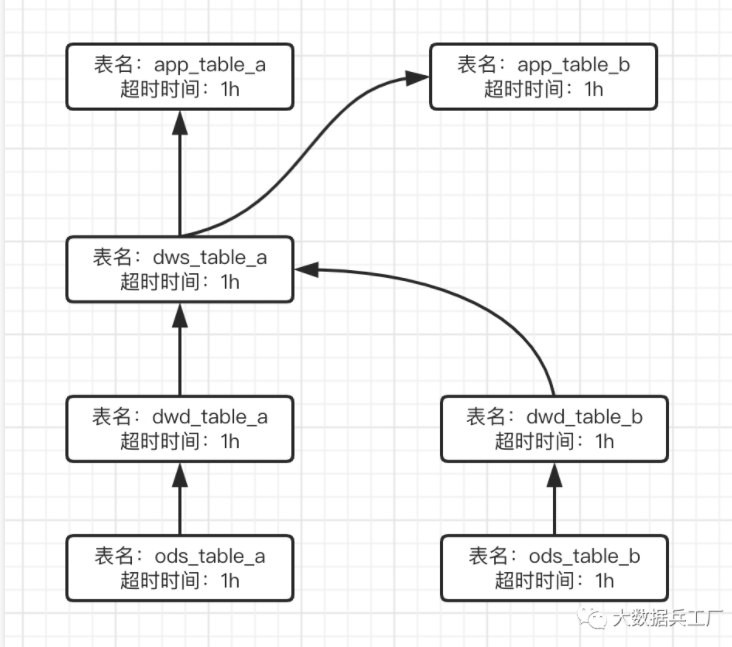
数据表的 质量检测任务需等待其所有直接上游表的检测任务执行完毕且必要的检测条件通过之后才运行。这样既能及时发现出问题的数据表,又能避免同一个问题导致大量重复无用的告警轰炸。
最后系统根据设置的告警通知规则将告警信息和数据质量报告通过邮件、企业微信等方式发送给数据质量的订阅者。这样我们的解决办法才告一段落。
3 成本管理
3.1 问题分析
随着数据资产得以不断积累,成本陷阱的隐患也在不断积累。数据和计算任务的不断增多,以下问题也逐渐显现出来:
-
设备成本急剧上升
-
维护成本越来越大
-
数据之间的关系变得复杂
-
数据模型的复用性降低
造成些成本陷阱的原因其实也不复杂,主要有以下几类:
-
数据上线容易下线难
-
数据价值与资源消耗不匹配
-
缺少对数据成本的量化管理
没有成本管理,几乎没有人去关注数据剩余的生命周期,即使知道有些数据表已经很少有人使用也不知道是否该下线,更不敢随意下线。
如果任由数据这样的野蛮增长,带给我们的数据成本将日趋高昂。
3.2 成本与价值量化
表的价值一般体现在用户对报表的访问热度以及所支持的业务,我们可以利用这种计算方式直接评估应用层报表的实用价值。
那对于数据仓库中数量更多的中间表和底层表我们该如何计算它们的价值呢?这里我们可以基于数据血缘,将应用层报表的直接价值逐层传递到上游表上叠加计算。
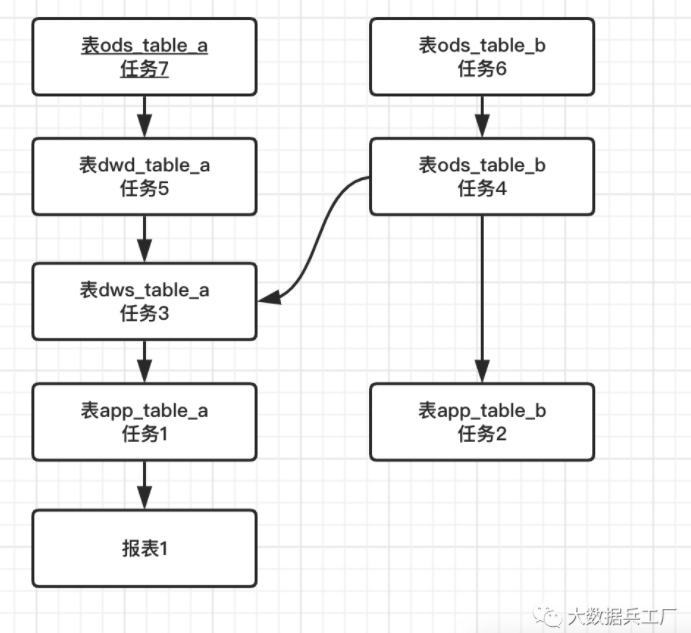
以上图为例,终端报表的价值可以直接由其访问记录的加权值计算得出。
为了说明具体的计算方法,我们不妨在划分表的价值给上游表时简单地使用均等划分,那么具体的计算公式如下:

成本则主要由产出该表的计算任务所消耗的计算资源成本和该表数据的存储成本组成。
表的价值计算类似,表的成本计算也是根据数据血缘来进行叠加计算的。不过表的成本的计算顺序与价值计算正好相反,具体计算公式如下:

3.3 成本优化
有了表的价值与成本的量化指标之后,我们就可以计算出每个数据表的投入产出比了。即时对数据仓库的数据进行详细的评估,及时发现成本问题。比如:
-
僵尸报表和任务;
-
低价值高成本的数据表;
-
计算高峰期高消耗的任务。
当我们发现有产出价值几乎为零的数据表时,我们就应该重点关注该数据表和相应的计算任务是否又继续存在的必要。
在谨慎评估的前提下,我们要对无用的报表的任务依照自下而上的原则逐步下线这些僵尸报表和任务。
对于低价值高成本的数据表,我们也要组织人力对相关的数据和业务进行重新评估,看看是否有数据整合和优化的空间。
4 总结
数据治理是数据平台建设到一定规模不可回避的话题。
希望本文能给数据治理经验尚浅的读者一些启发,也好在大数据平台建设的路途少走弯路。

- 点赞
- 收藏
- 关注作者
评论(0)