2万字50张图玩转Flink面试体系

大家好,我是老兵。
本系列为大数据技术栈面试体系系列,每期将分享一个技术组件的知识全体系,并结合面试的形式由浅入深讲解。
本期将介绍大数据实时计算利器Flink面试体系,全文内容已制作成PDF。
一 基础篇
1 简单介绍下Flink及使用场景
Apache Flink是开源的大数据实时计算框架,具有分布式、高性能、内存计算等特点。Flink因其独特的流批一体设计模式,被广泛应用于实时和离线数据应用场景。
Flink被称为第四代大数据计算引擎,在其前面存在Mapreduce、Storm、Spark等计算框架。在流处理领域中,Flink是目前最全面、最强大的实时计算引擎。
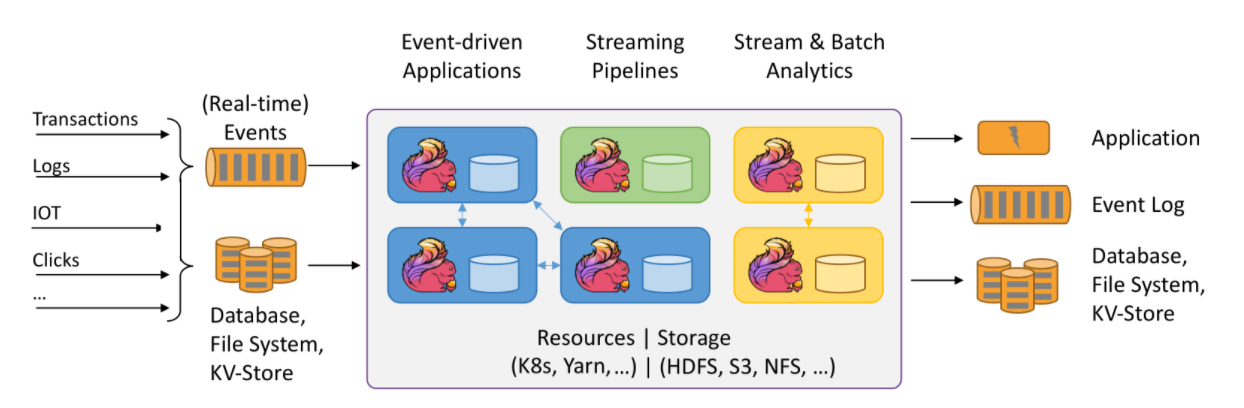
结合官网的示意图,我们来看下Flink的工作场景。
-
数据源:支持多种数据源接入。包含事务型数据库、日志、IOT设备、点击事件等数据。 -
处理层:基于Yarn|K8s调度引擎和HDFS|S3存储组件,提供完整的 事件驱动、时间语义、流&批一体的Flink计算服务。 -
应用层:输出端提供应用系统、事件日志、存储系统等数据对接。
2 Flink编程模型了解吗
1)Flink分层模型
Flink底层通过封装和抽象,提供四级分层编程模型,以此支撑业务开发实时和批处理程序。
结合示意图,我们由下而上进行介绍。
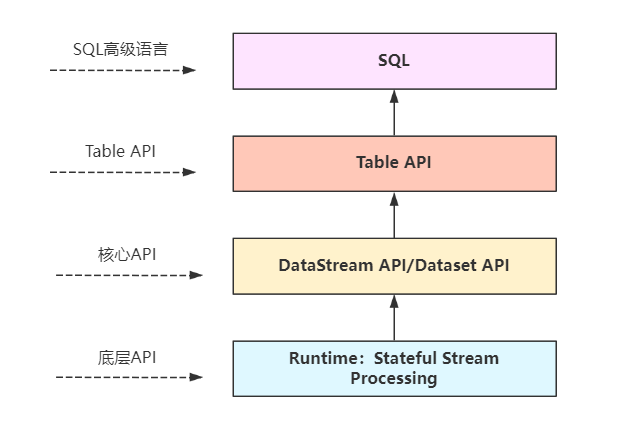
-
Runtime层:Flink程序的最底层入口。提供基础的核心接口完成流、状态、事件、时间等复杂操作,功能灵活但使用成本较高,一般面向源码研发人员。 -
DataStream/Dataset API层:这一层主要面向开发者。基于Runtime层抽象为两类API,其中DataStream API处理实时流程序;Dataset API处理批数据程序。 -
Table API:统一DataStream/DataSet API,抽象成带有Schema信息的表结构API。通过Table操作和注册表完成数据计算,支持与DataStream/Dataset相互转换。 -
SQL:面向数据分析和开发人员,抽象为SQL操作,降低开发门槛和平台化。
2)Flink计算模型
Flink的计算模型和Spark的模型有些类似。包含输入端(source)、转换(Transform)、输出端(sink)。
-
source端:Flink程序的输入端,支持多个数据源对接 -
Transformation:Flink程序的转换过程,实现DataStream/Dataset的计算和转换 -
sink端: Flink的输出端,支持内部和外部输出源
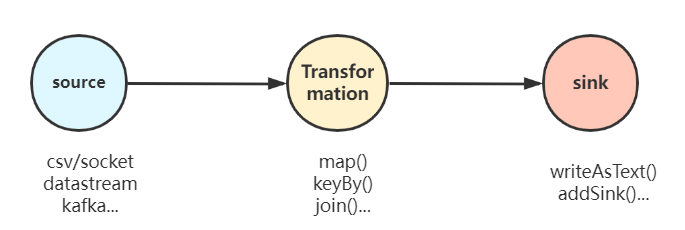
具体的Flink计算模型(算子)详情,可以参考我的文章:一网打尽Flink算子大全
3 聊聊Flink的工作原理
主要考察对Flink的内部运行机制的了解程度,需要重点注意Flink中的重要角色组件及其协作机制。
Flink底层执行分为客户端(Client)、Job管理器(JobManager)、任务执行器(TaskManager)三种角色组件。其中Client负责Job提交;JobManager负责协调Job执行和Task任务分配;TaskManager负责Task任务执行。
 Flink常见执行流程如下(调度器不同会有所区别):
Flink常见执行流程如下(调度器不同会有所区别):
-
1)用户提交流程序Application。 -
2)Flink 解析StreamGraph。Optimizer和Builder模块解析程序代码,生成初始StreamGraph并提交至Client。 -
3)Client 生成JobGraph。上述StreamGraph由一系列operator chain构成,在client中会被转换为JobGraph,即优化多个chain为一个节点,最终提交到JobManager。 -
4)JobManager 调度Job。JobManager和Client的ActorSystem保持通信,并生成ExecutionGraph(并行化JobGraph)。随后Schduler和Coordinator模块协调并调度Jobz执行。 -
5)TaskManager 部署Task。TaskManager和JobManager的ActorSystem保持通信,接受job调度计划并在内部划分TaskSlot部署执行Task任务。 -
6)Task 执行。Task执行期间,JobManager、TaskManager和Client之间保持通信,回传任务状态和心跳信息,监控任务执行。
4 公司怎么提交Flink实时任务的?谈谈流程
顾名思义,这里涉及Flink的部署模式内容。一般Flink部署模式除了Standalone之外,最常见的为Flink on Yarn和Flink on K8s模式,其中Flink on Yarn模式在企业中应用最广。
Flink on Yarn模式细分由可以分为Flink session、Flink per-job和Flink application模式,下面我们逐一说明。
1)Flink session模式
Flink Session模式会首先启动一个集群,按照配置约定,集群中包含一定数量的JobManager和TaskManager。后面所有提交的Flink Job均共享该集群内的JobManager和TaskManager,即所有的Flink Job竞争相同资源。
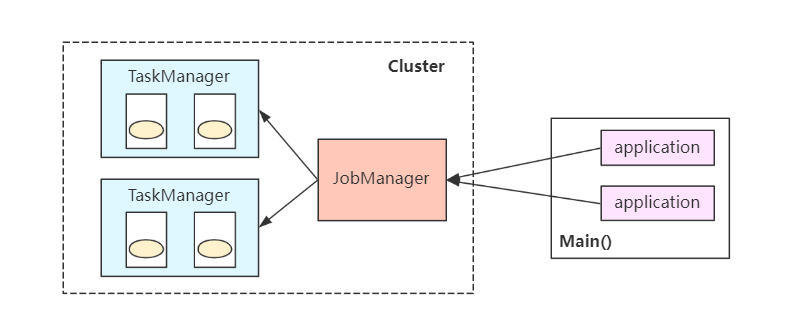
这样做的好处是节省作业提交资源开销(集群已存在),减少资源和线程切换工作。但是所有作业共享一个JobManager,导致JobManager压力激增,同时一旦某Job发生故障时会影响到其他作业(中断或重启)。一般仅适用于短周期、小容量作业。
看下Flink-session模式的作业提交流程:
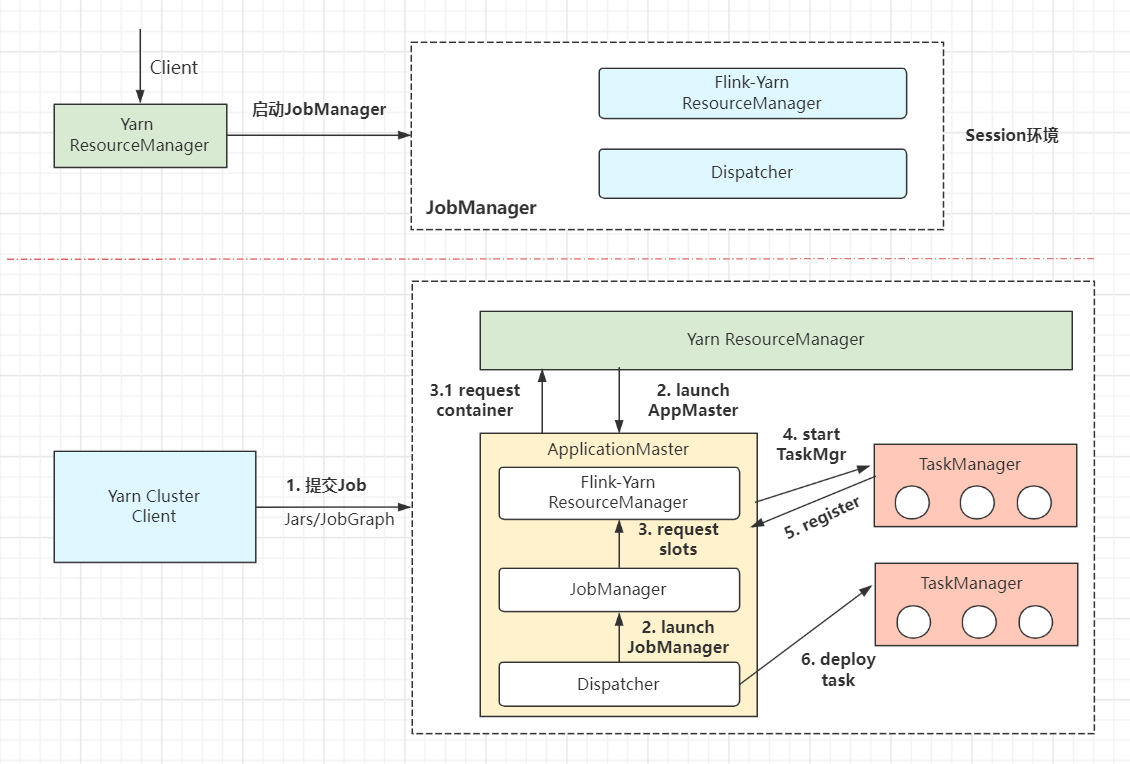
-
(1)整体流程分为两部分:yarn-session集群启动、Job提交。 -
(2) yarn-session集群启动。请求YarnRM启动JobManager,随后JobManager内部启动Dispatcher和Flink-yarnRM进程,等待后续Job提交。 -
(3)Client提交Job。Client连接 Dispatcher开始提交Job,包含jars和解析过的JobGraph拓扑数据结构。 -
(4)Dispatcher启动 JobMaster,JobMaster向Yarn RM请求slots资源。 -
(5) Flink-Yarn RM向Yarn RM请求Container资源,准备启动TaskManager。 -
(6)Yarn启动 TaskManager进程。TaskManager同时向Flink RM反向注册(自身可用的slots槽数) -
(7)TaskManager为新的作业提供slots,与JobMaster通信。 -
(8)JobMaster将执行的 任务分发给TaskManager,开始部署执行任务
2)Flink Per-job模式
Flink Per-job模式为每个提交的作业启动集群,各集群间相互独立,并在各自作业完成后销毁,最大限度保障资源隔离。每个Job均衡分发自身的JobManager,单独进行job的调度和执行。
虽然该模式提供了资源隔离,但是每个job均维护一个集群,启动、销毁以及资源请求消耗时间长,因此比较适用于长时间的任务执行(批处理任务)。
Per-job模式在Flink 1.15中弃用,目前推荐使用applicaiton模式。
 看下Flink Per-job模式的作业提交流程:
看下Flink Per-job模式的作业提交流程:
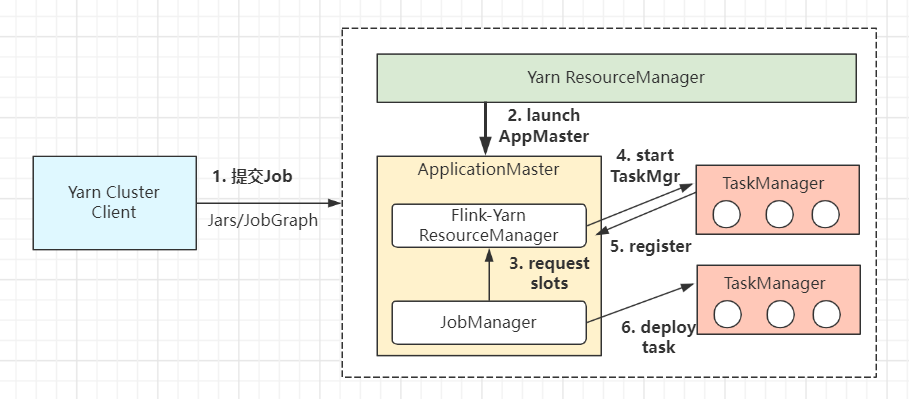
-
(1)首先Client提交作业到 YarnRM,包括jars和JobGraph等信息。 -
(2)YarnRM分配Container启动 AppMaster。AppMaster中启动JobManager和FlinkRM,并将作业提交给JobMaster。 -
(3)JobMaster向YarnRM请求资源( slots)。 -
(4)FlinkRM向 YarnRM请求container并启动TaskManager。 -
(6)TaskManager启动之后,向 FlinkRM注册自己的可用任务槽。 -
(7)TaskManager向FlinkRM反向 注册(自身可用的slots槽数) -
(8)TaskManager为新的作业提供 slots,与JobMaster通信。 -
(9)JobMaster将执行的 任务分发给TaskManager,开始部署执行任务
3)Flink application模式
Flink application模式综合Per-job和session的优点,为每个·Application·创建独立的集群(JobManager),允许每个Application中包含多个job作业提交(可开启异步提交),当application应用完成时集群关闭。
该模式和前面两种模式的最大区别是Main()方法此时在JobManager中执行,即在JobManager中完成文件下载、jobGraph解析、提交资源等事项。前面两种模式的main()方法在Client端执行,该模式将大大减少Client压力。
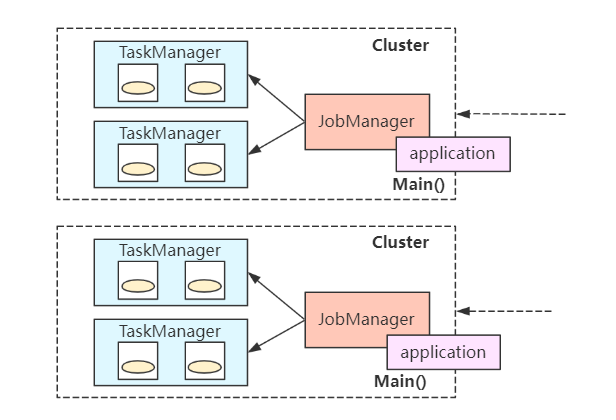
看下Flink application模式的作业提交流程:
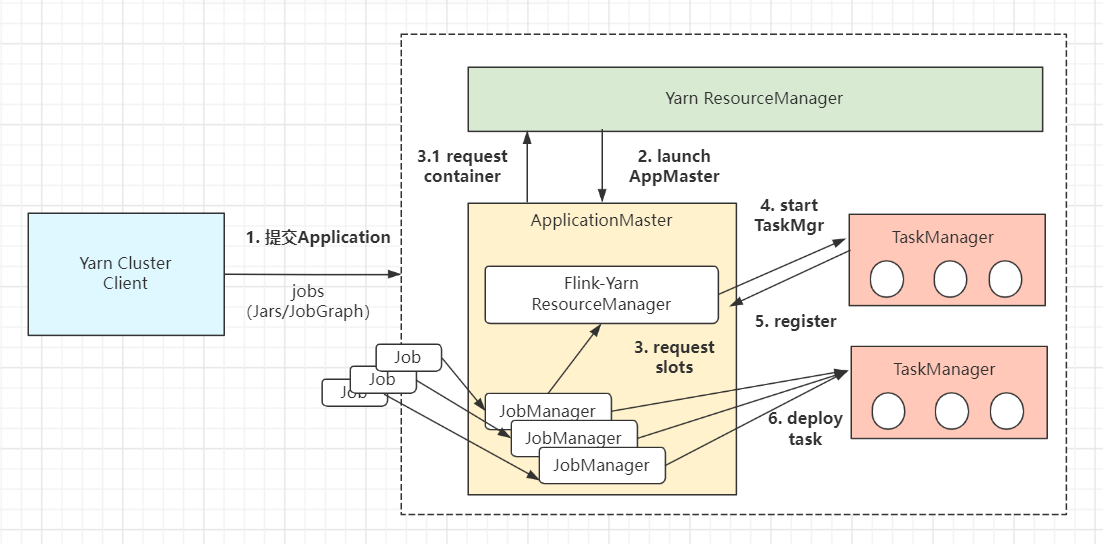
-
(1)流程与Per-job模式的提交流程非常相似。 -
(2)提交Application。此时首先是提交整个Application应用,应用中包含多个Job。 -
(3)每个Job启动各自的JobManager,可选择异步启动执行。 -
(4)其余步骤与Per-job模式类似,可参考上述步骤详解。
5 K8s了解吗?谈谈Flink on K8S的提交流程
由于目前云原生和K8s容器化的快速发展,很多Flink程序开始转向容器化部署。首先需要了解下K8s的相关知识,这是个加分项。
1)K8s容器编排技术
k8s全称kubernete,是一种强大的、可移植的高性能容器编排工具。这里的容器指的是Docker容器化技术,它通过将执行环境和配置打包成镜像服务,在任意环境下快速部署docker容器,提供基础的环境服务。解决之前部署服务速度慢、迁移难和高成本等问题。
由于Docker容器技术的普及,基于容器构建的云原生架构越来越多,同时也带来了很多容器运维管理问题。K8s提供了一套完整的容器编排解决方案,实现容器发现及调度、负载均衡、弹性扩容和数据卷挂载等服务。
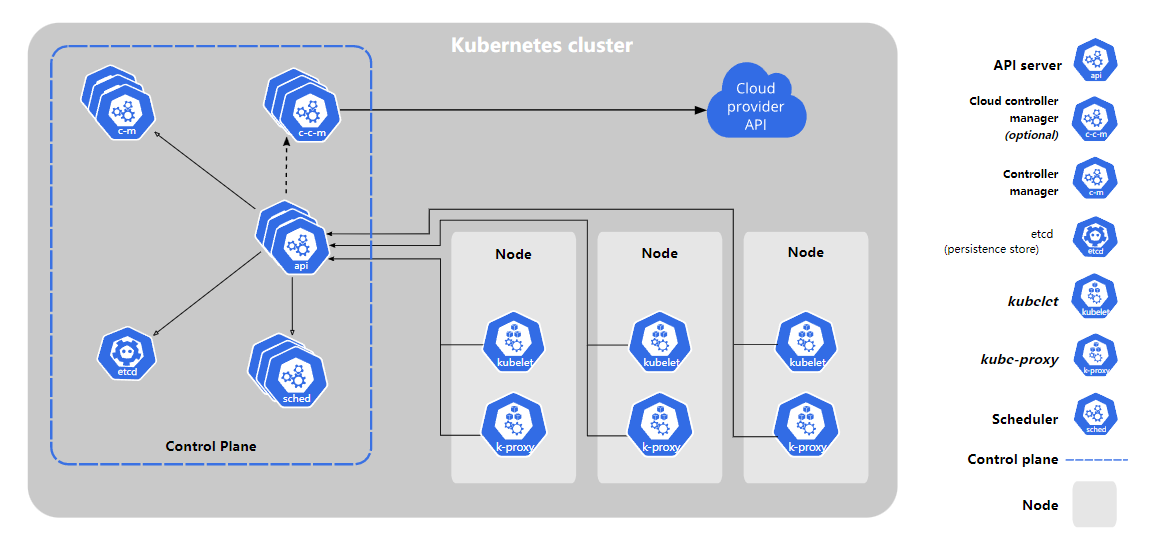
2)Flink on K8s部署模式
整体过程和Flink on Yarn的提交模式比较类似,主要是环境切换成K8s,此时的TaskManager和JobManager等组件变成了K8s Pod角色(镜像)。
首先提前定义各组件的服务配置文件并提交到K8s集群;K8s集群会自动根据配置启动相应的Pod服务,最后Flink程序开始运行。
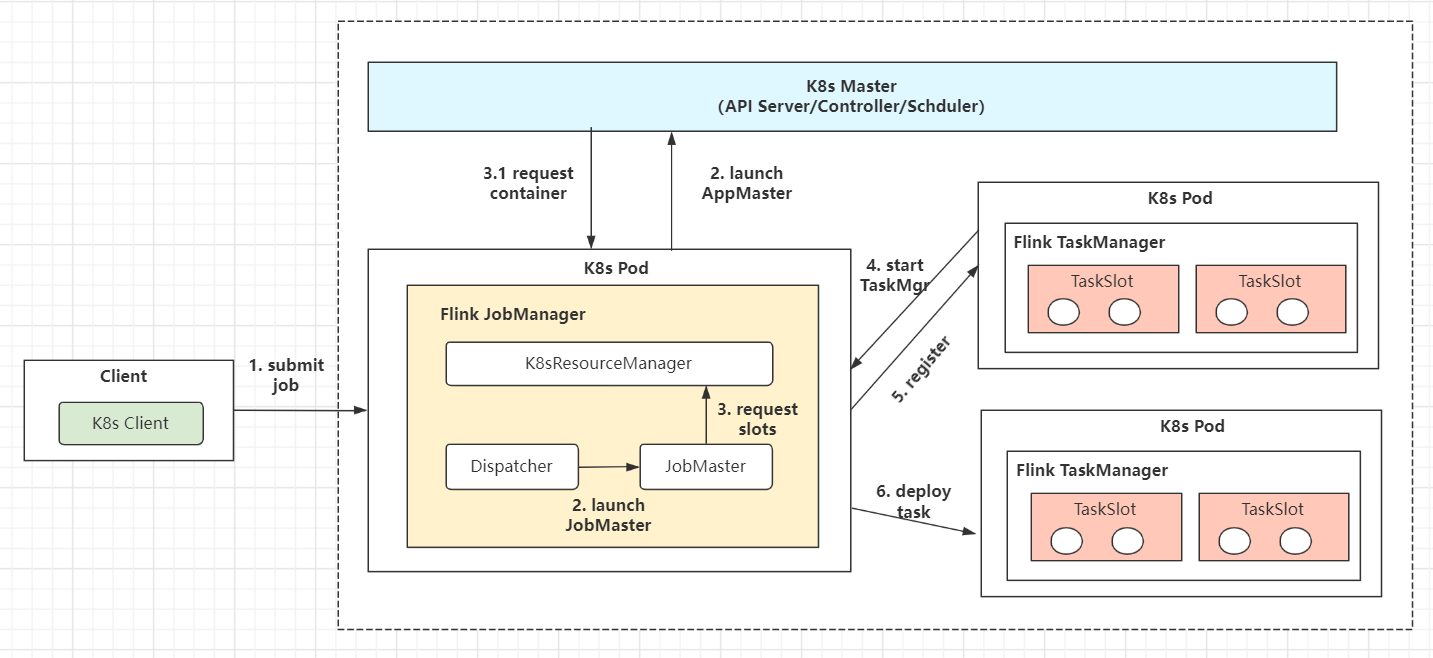 session模式示例
session模式示例
-
(1)K8s集群根据提交的配置文件启动 K8sMaster和TaskManager(K8s Pod对象) -
(2)依次启动Flink的 JobManager、JobMaster、Deploy和K8sRM进程(K8s Pod对象);过程中完成slots请求和ExecutionGraph的生成动作。 -
(3)TaskManager注册Slots、JobManager请求Slots并分配任务 -
(4)部署Task执行并反馈状态
6 Flink的执行图有哪几种?分别有什么作用
Flink中的执行图一般是可以分为四类,按照生成顺序分别为:StreamGraph-> JobGraph-> ExecutionGraph->物理执行图。
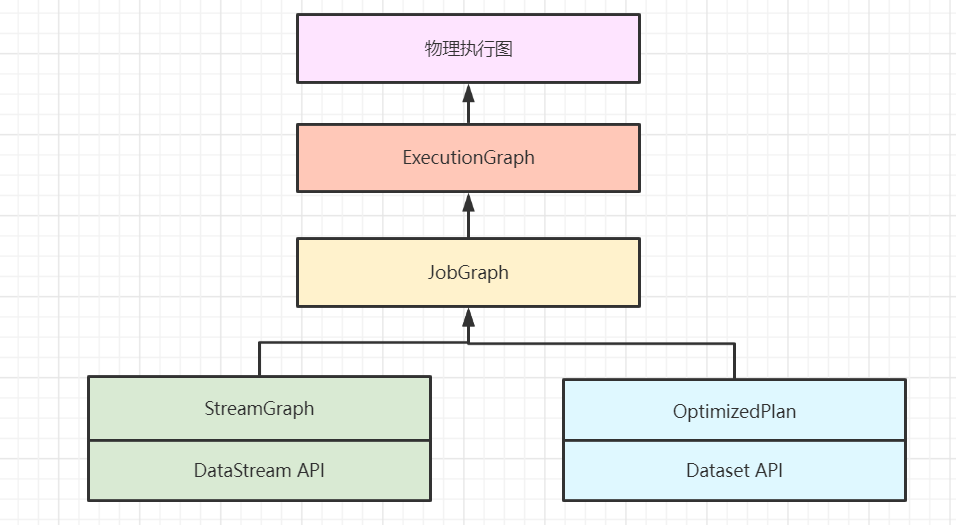
1)StreamGraph
顾名思义,这里代表的是我们编写的流程序图。通过Stream API生成,这是执行图的最原始拓扑数据结构。
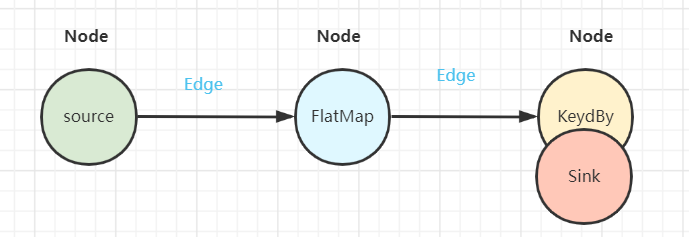
2)JobGraph
StreamGraph在Client中经过算子chain链合并等优化,转换为JobGraph拓扑图,随后被提交到JobManager中。
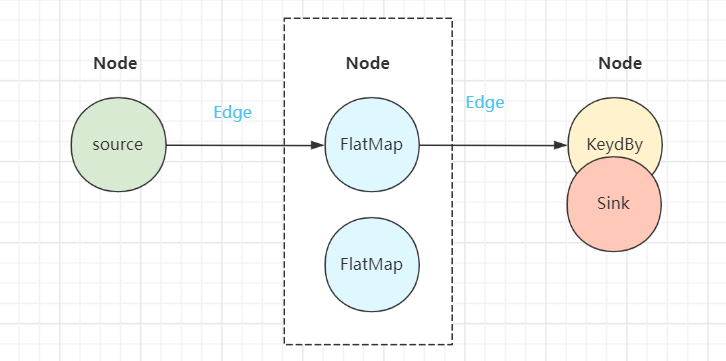
3)ExecutionGraph
JobManager中将JobGraph进一步转换为ExecutionGraph,此时ExecutuonGraph根据算子配置的并行度转变为并行化的Graph拓扑结构。
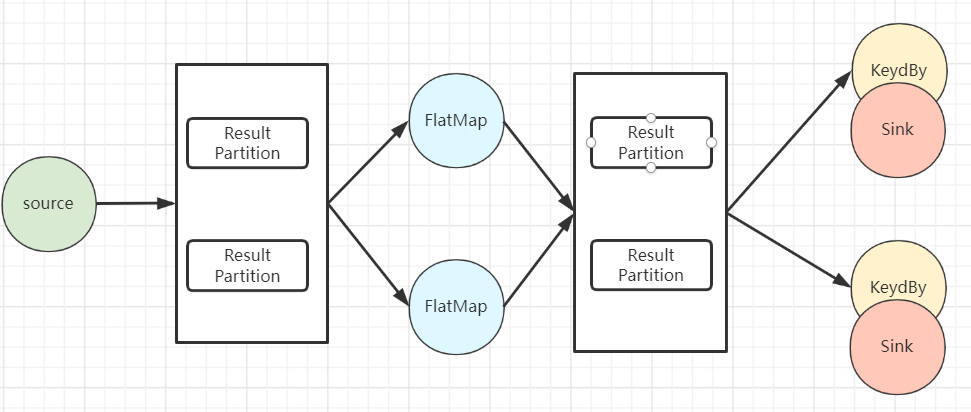
4)物理执行图
比较偏物理执行概念,即JobManager进行Job调度,TaskManager最终部署Task的图结构。
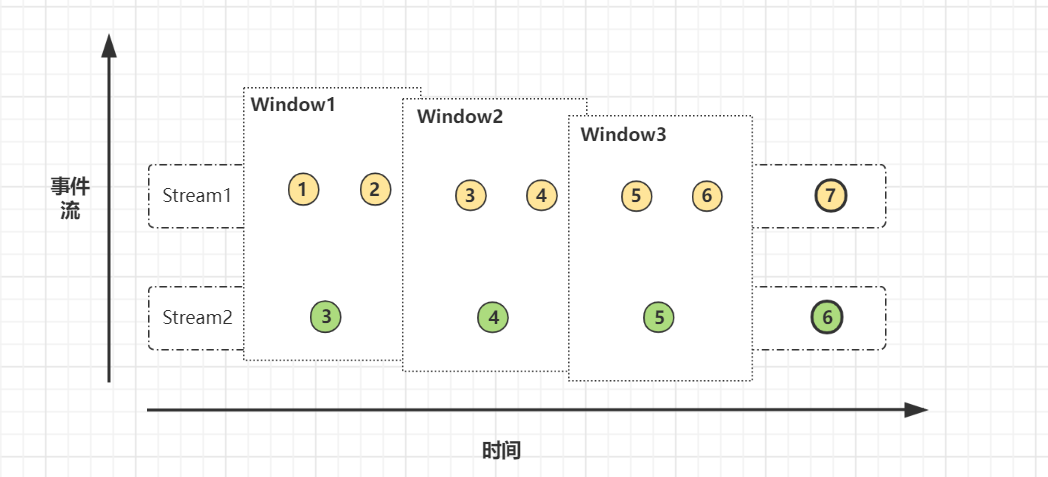
7 说说Flink的窗口机制
Flink一般根据固定时间或长度把数据流切分到不同的窗口,并提供相应的窗口Window算子,在窗口内进行聚合运算。
Flink的窗口一般分为三种类型:滚动窗口、滑动窗口、会话窗口和全局窗口等。
 滚动窗口
滚动窗口
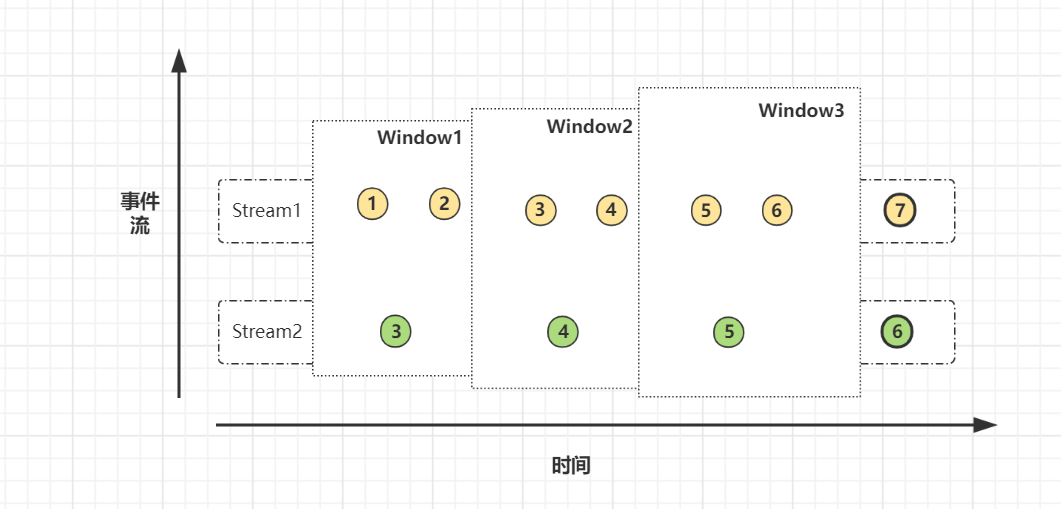 滑动窗口
滑动窗口
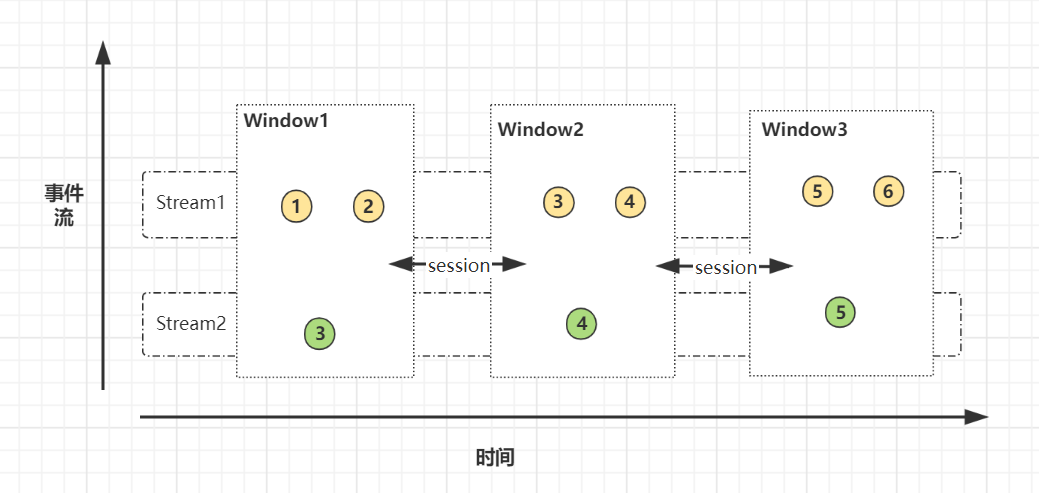 会话窗口
会话窗口
Flink中的窗口算子一般会配置Keyed类型数据集操作,并结合watermark和定时器,提供时间语义的统计,Windows算子的定义如下:
-
Windows Assigner:定义窗口的类型(数据流分配到多长时间间隔的哪种窗口),比如1min的滚动窗口。 -
Trigger:指派触发器,即窗口满足什么条件触发 -
Evictor:数据剔除(非必须) -
Lateness:是否处理延迟数据标志,可在watermark之后再次触发 -
OutputTag:侧输出流输出标签,和getOutputTag配合使用。 -
WindowFunction:windows内的处理逻辑(程序核心)
// 计算过去30s窗口的uv/pv
dataStream.keyBy(x => x.getString("position_id"))
.window(TumblingEventTimeWindows.of(Time.minutes(30)))
.aggregate(new PVResultFunc(), new UVResultFunc())
8 Flink的watermark水印了解吗
Flink中的waternark(水印)是处理延迟数据的优化机制。一般数据顺序进入系统,但是存在网络等外部因素导致数据乱序或者延迟达到,这部分数据即不能丢弃也不能无限等待,watermark的出现解决了这个两难问题。
watermark的定义是:比如在一个窗口内,当位于窗口最小watermark(水位线)的数据达到后,表明(约定)该窗口内的所有数据均已达到,此时不再等待数据,直接触发窗口计算。
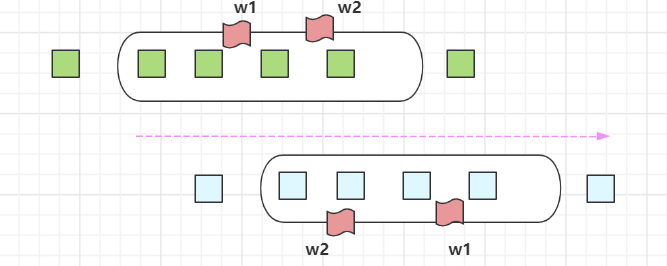
watermark:最新事件事件 - 固定时间间隔
1)watermark的作用
-
规定了数据延迟处理的最优判定,即watermark时间间隔 -
较为完善的处理了数据乱序的问题,从而输出预期结果 -
结合最大延迟时间和侧输出流等机制,彻底解决数据延迟
2)watermark的生成
Flink中的watermark生成形式分为两种,即PeriodicWatermarks(周期性的生成水印)、PunctuatedWatermarks(每条信息/数据量生成水印)。
-
AssignerWithPeriodicWatermarks
// 设置5s周期性生成watermark
env.getConfig.setAutoWatermarkInterval(5000)
// 周期性生成watermark
val periodicWatermarkStream = dataStream.assignTimestampsAndWatermarks(new XXPeriodicAssigner(10))
-
AssignerWithPunctuatedWatermarks
class xxx extends AssignerWithPunctuatedWatermarks[(String, Long, Int)] {
override def extractTimestamp(element: (String, Long, Int), previousElementTimestamp: Long): Long = {
element._2
}
override def checkAndGetNextWatermark(lastElement:(St ring, Long, Int), extractTimestamp: Long): Watermark = {
// 判断字段状态生成watermark
if (lastElement._1 != 0) new Watermark(extractTimesta mp) else null
}
}
9 Flink分布式快照原理是什么
分布式快照即所谓的一致性检查点(Checkpoints)。定义为某个时间点上所有任务状态的一份拷贝(快照),该时间点也是所有任务刚好处理完一个相同数据的时间。
Flink间隔时间自动执行
一致性检查点程序,异步插入barrier检查点分界线,内存状态存储为cp进程文件。
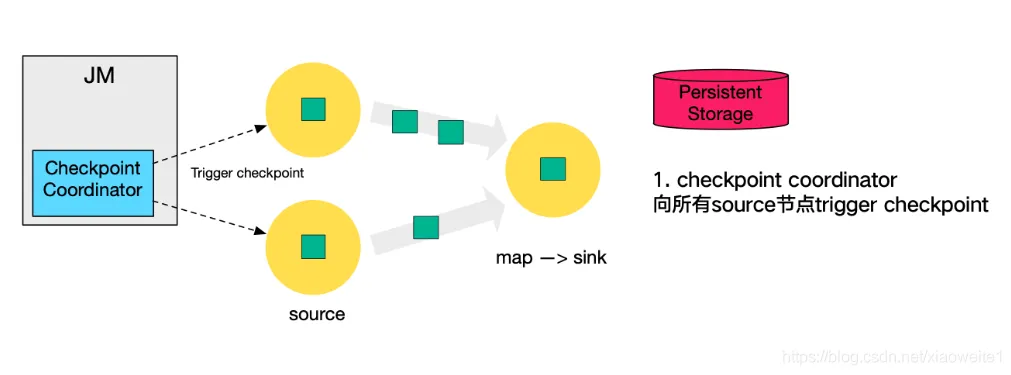
-
从 source(Input)端开始,JobManager会向每个source端发送检查点barrier消息并启动检查点checkpoints。在保证所有的source端数据处理完成后,Flink开始保存一致性检查点checkpoints,过程启用barrier检查点分界线。 -
接收数据和 barrier消息,两个过程异步进行。在所有的source数据都处理完成后,开始将自己的检查点checkpoints保存到状态后端StateBackend中,并通知JobManager将barrier分发到下游。 -
barrier向下游传递时会进行 barrier对齐确认。待barrier都到齐后才进行checkpoints检查点保存。 -
重复以上操作,直到整个流程完成。
10 说说Flink的状态机制
Flink重要的特性就是其支持有状态计算。什么是有状态计算呢?即将中间的计算结果进行保存,便于后面的数据回溯和计算。
这个很好理解,因为Flink一般使用场景大多数为窗口实时计算,计算的是即时数据,当存在一个计算历史数据累计的需求时显得捉襟见肘,因此需要有方法能够保持前面的数据状态。Flink的底层很多机制默认开启了状态管理,比如checkpoint过程、二阶段提交均存在状态保存的操作。
在实际操作中Flink状态分为Keyed State 与 Operator State。
1)Operator State
算子状态的作用范围限定为算子任务,同一并行任务的所有数据都可以访问到相同的状态。状态对于同一任务而言是共享的。
-
List State。列表状态算子,将状态存储为列表数据 -
Union List State。联合列表状态算子,与List State类似,但是当出现故障时可恢复。 -
Broadcast State。广播状态算子,即存在多个task任务共享状态。
private var listState : ListState[Person] = _
override def open(parameters: Configuration): Unit = {
val listStateDesc: ListStateDescriptor[Person] = new ListStateDescriptor[Person]("personState", classOf[Person])
listState = getRuntimeContext.getListState(listStateDesc)
}
2)Keyed State
顾名思义,此类型的State状态保存形式为K-V键值对,通过K值管理和维护状态数据。
Flink对每个key维护自身状态,相同Key的数据划分到同一任务中,由Key管理其对应的状态。
-
Value State。值状态算子,将状态存储为K-单个值 -
List State。和上面的List State类似,状态被存储为k-数组列表 -
Map State。映射状态算子,状态被存储为K-Map -
聚合State。状态存储为Aggregating聚合操作列表
MapState<Long,Long> userMapState;
userMapState = getRuntimeContext().getMapState(
new MapStateDescriptor<Long, Long>(
"Usercount",Long.class,Long.class));
11 说说Flink的内存管理是如何做的
在介绍内存管理之前,先介绍一下JVM中的堆内存和堆外内存。
通常来说。JVM堆空间概念,简单描述就是在程序中,关于对象实例|数组的创建、使用和释放的内存,都会在JVM中的一块被称作为"JVM堆"内存区域内进行管理分配。
Flink程序在创建对象后,JVM会在堆内内存中
分配一定大小的空间,创建Class对象并返回对象引用,Flink保存对象引用,同时记录占用的内存信息。
而堆外内存如果你有过Java相关编程经历的话,相信对堆外内存的使用并不陌生。其底层调用基于C的JDK Unsafe类方法,通过指针直接进行内存的操作,包括内存空间的申请、使用、删除释放等。
介绍完了堆内内存和堆外内存的概念,下面我们来看下Flink的内存管理。
1)JobManager内存管理
 JobManager进程总内存包括JVM堆内内存、JVM堆外内存以及JVM MetaData内存,其中涉及的内存配置参数为:
JobManager进程总内存包括JVM堆内内存、JVM堆外内存以及JVM MetaData内存,其中涉及的内存配置参数为:
# JobManager总进程内存
jobmanager.memory.process.size:
# 作业管理器的 JVM 堆内存大小
jobmanager.memory.heap.size:
#作业管理器的堆外内存大小。此选项涵盖所有堆外内存使用。
jobmanager.memory.off-heap.size:
2)TaskManager内存管理
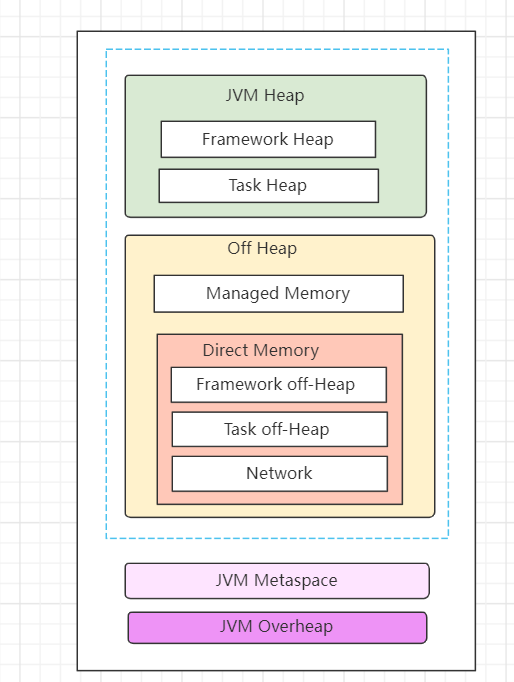
TaskManager内存同样包含JVM堆内内存、JVM堆外内存以及JVM MetaData内存三大块。其中JVM堆内内存又包含Framework Heap和Task Heap,即框架堆内存和任务Task堆内存。
JVM堆外内存包含Memory memory托管内存,主要用于保存排序、结果缓存、状态后端数据等。另一块为Direct Memory直接内存,包含如下:
-
Framework Off-Heap Memory:Flink框架的堆外内存,即Flink中TaskManager的自身内存,和slot无关。 -
Task Off-Heap:Task的堆外内存 -
Network Memory:网络内存
其中涉及的内存配置参数为:
// tm的框架堆内内存
taskmanager.memory.framework.heap.size=
// tm的任务堆内内存
taskmanager.memory.task.heap.size
// Flink管理的原生托管内存
taskmanager.memory.managed.size=
taskmanager.memory.managed.fraction=
// Flink 框架堆外内存
taskmanager.memory.framework.off-heap.size=
// Task 堆外内存
taskmanager.memory.task.off-heap.size=
// 网络数据交换所使用的堆外内存大小
taskmanager.memory.network.min: 64mb
taskmanager.memory.network.max: 1gb
taskmanager.memory.network.fraction: 0.1
12 Flink和Spark Streaming有什么区别
1)设计理念
-
Spark是批处理框架,其中的SparkStreaming在Spark的基础上实现的微批处理工作,支持秒级别延迟。 -
Flink是彻底的流处理框架,可以处理有界流和无流数据,达到流批一体,延迟低,真正做到来一条数据立马处理。 -
spark本身是无状态的,基于RDD计算。Flink基于事件驱动,既能进行有状态计算,也可以进行无状态计算。
2)流批一体
-
Spark通过逼近最小微批的方式达到近实时的效果,本质上还是批处理。 -
Flink本身内部就是处理无界的实时流,通过时间间隔限制,将无界流转换为有界流,实现流批一体。
3)应用场景
-
Spark擅长处理数据量非常大而且逻辑复杂的批数据处理、基于历史数据的交互式查询等 -
Flink擅长处理低延迟实时数据处理场景,比如实时日志报表分析等。 -
Spark社区更为活跃,且生态比较丰富,特别是机器学习方面;Flink正在逐渐完善社区和生态影响力。
4)相同点
-
均提供统一的批处理和流处理API,支持高级编程语言和SQL -
都基于内存计算,速度快 -
都支持Exactly-once一致性 -
都有完善的故障恢复机制
二 进阶篇
13 Flink/Spark/Hive SQL的执行原理
这里我把三个组件SQL执行原理放到了一起,通过对比加深一下印象。
1)Hive SQL的执行原理
Hive SQL是Hive提供的SQL查询引擎,底层由MapReduce实现。Hive根据输入的SQL语句执行词法分析、语法树构建、编译、逻辑计划、优化逻辑计划以及物理计划等过程,转化为Map Task和Reduce Task最终交由Mapreduce引擎执行。
-
执行引擎。具有mapreduce的一切特性,适合大批量数据离线处理,相较于Spark而言,速度较慢且IO操作频繁 -
有完整的 hql语法,支持基本sql语法、函数和udf -
对表数据存储格式有要求,不同存储、压缩格式性能不同
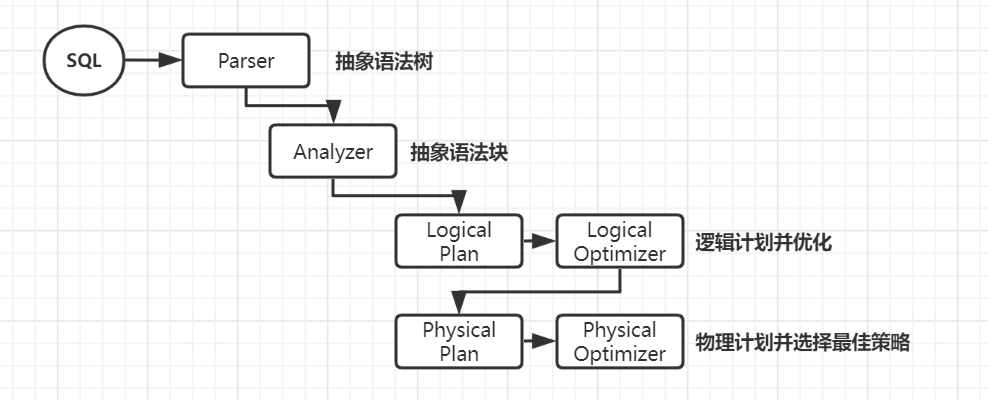
2)Spark SQL的执行原理
Spark SQL底层基于Spark引擎,使用Antlr解析语法,编译生成逻辑计划和物理计划,过程和Hive SQL执行过程类似,只不过Spark SQL产生的物理计划为Spark程序。
-
输入编写的Spark SQL -
SqlParser分析器。进行语法检查、词义分析,生成未绑定的Logical Plan逻辑计划(未绑定查询数据的元数据信息,比如查询什么文件,查询那些列等) -
Analyzer解析器。查询元数据信息并绑定,生成完整的逻辑计划。此时可以知道具体的数据位置和对象,Logical Plan 形如from table -> filter column -> select 形式的树结构 -
Optimizer优化器。选择最好的一个Logical Plan,并优化其中的不合理的地方。常见的例如谓词下推、剪枝、合并等优化操作 -
Planner使用Planing Strategies将逻辑计划转化为物理计划,并根据最佳策略选择出的物理计划作为最终的执行计划 -
调用Spark Plan Execution执行引擎执行Spark RDD任务
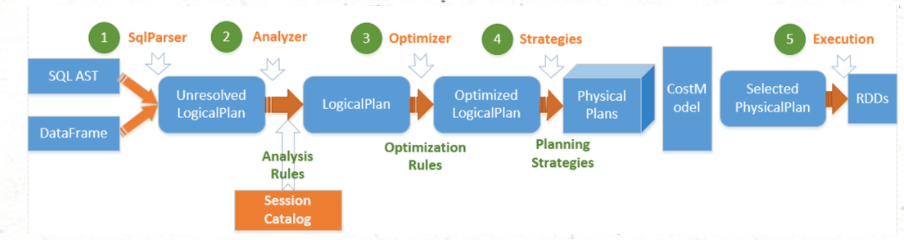
3)Flink SQL的执行原理
Flink SQL的执行原理和Hive以及Spark SQL的执行原理大同小异,均存在解析、校验、编译生成语法树、优化生成逻辑计划等步骤。

-
Parser: SQL解析。底层通过JavaCC解析SQ语法,并将SQL解析为未经校验的AST语法树。 -
Validate: SQL校验。这里会校验SQL的合法性,比如Schema、字段、数据类型等是否合法(SQL匹配程度),过程需要与sql存储的元数据结合查验。 -
Optimize: SQL优化。Flink内部使用多种优化器,将前面步骤的语法树进一步优化,针对RelNode和生成的逻辑计划,随后生成物理执行计划。 -
Produce: SQL生成。将物理执行计划生成在特定平台的可执行程序。 -
Execute: SQL执行。执行SQL得到结果。
14 Flink的背压遇到过吗?怎么解决的
Flink背压是生产应用中常见的情况,当程序存在数据倾斜、内存不足状况经常会发生背压,我将从如下几个方面去分析。
1)Flink背压表现
-
1)运行开始时正常,后面出现大量Task任务 等待 -
2)少量Task任务开始报 checkpoint超时问题 -
3)大量Kafka数据堆积,无法消费 -
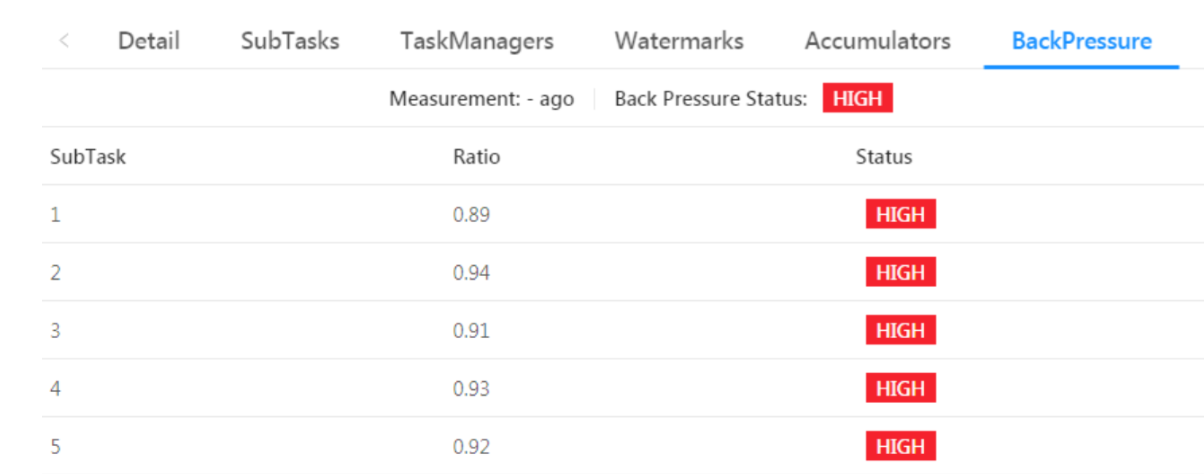
4)Flink UI的BackPressure页面出现红色 High标识
2) 反压一般有哪些情况
 一般可以细分两种情况:
一般可以细分两种情况:
-
当前Task任务处理速度慢,比如task任务中调用算法处理等复杂逻辑,导致上游申请不到足够内存。 -
下游Task任务处理速度慢,比如多次collect()输出到下游,导致当前节点无法申请足够的内存。
3) 频繁反压的影响是什么
频繁反压会导致流处理作业数据延迟增加,同时还会影响到Checkpoint。
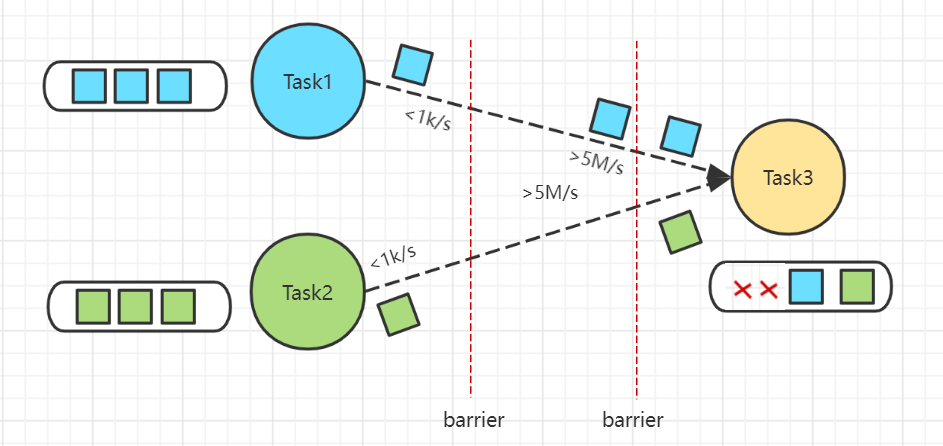
Checkpoint时需要进行Barrier对齐,此时若某个Task出现反压,Barrier流动速度会下降,导致Checkpoint变慢甚至超时,任务整体也变慢。
长期或频繁出现反压才需要处理,如果由于
网络波动或者GC出现的偶尔反压可以不必处理。
4)Flink的反压机制
背压时一般下游速度慢于上游速度,数据久积成疾,需要做限流。但是无法提前预估下游实际速度,且存在网络波动情况。
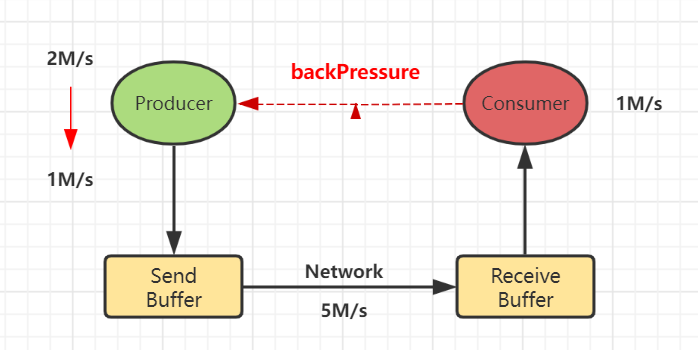
需要保持上下游动态反馈,如果下游速度慢,则上游限速;否则上游提速。实现动态自动反压的效果。
下面看下Flink内部是怎么实现反压机制的。
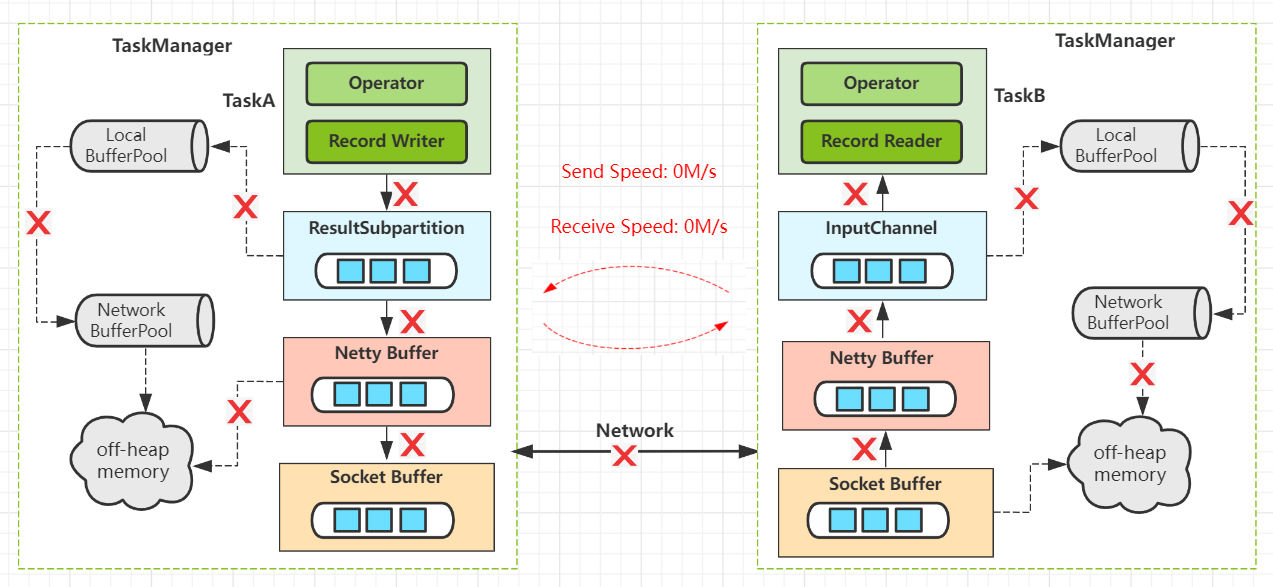
-
1)每个 TaskManager维护共享Network BufferPool(Task共享内存池),初始化时向Off-heap Memory中申请内存。 -
2)每个Task创建自身的 Local BufferPool(Task本地内存池),并和Network BufferPool交换内存。 -
3)上游 Record Writer向 Local BufferPool申请buffer(内存)写数据。如果Local BufferPool没有足够内存则向Network BufferPool申请,使用完之后将申请的内存返回Pool。 -
4) Netty Buffer拷贝buffer并经过Socket Buffer发送到网络,后续下游端按照相似机制处理。 -
5)当下游申请buffer失败时,表示当前节点 内存不够,则逐层发送反压信号给上游,上游慢慢停止数据发送,直到下游再次恢复。
5)反压如何处理
-
查看Flink UI界面,定位哪些Task出现反压问题 -
查看代码和数据,检查是否出现数据倾斜 -
如果发生数据倾斜,进行预聚合key或拆分数据 -
加大执行内存,调整并发度和分区数 -
其他方式。。。
由于篇幅有限,更多Flink反压内容请查看我的相关文章:万字趣解Flink背压
15 Flink的exactly-once怎么保持
精准一次消费需要整个系统各环节均保持强一致性,包括可靠的数据源端(数据可重复读取、不丢失) 、可靠的消费端(Flink)、可靠的输出端(幂等性、事务)。
Flink保持精准一次消费主要依靠checkpoint一致性快照和二阶段提交机制。
1)数据源端
Flink内置FlinkKafkaConsumer类,不依赖于 kafka 内置的消费组offset管理,在内部自行记录并维护 kafka consumer 的offset。
(1)管理offset(手动提交)并保存到checkpoint中
(2)FlinkKafkaConsumer API内部集成Flink的Checkpoint机制,自动实现精确一次的处理语义。
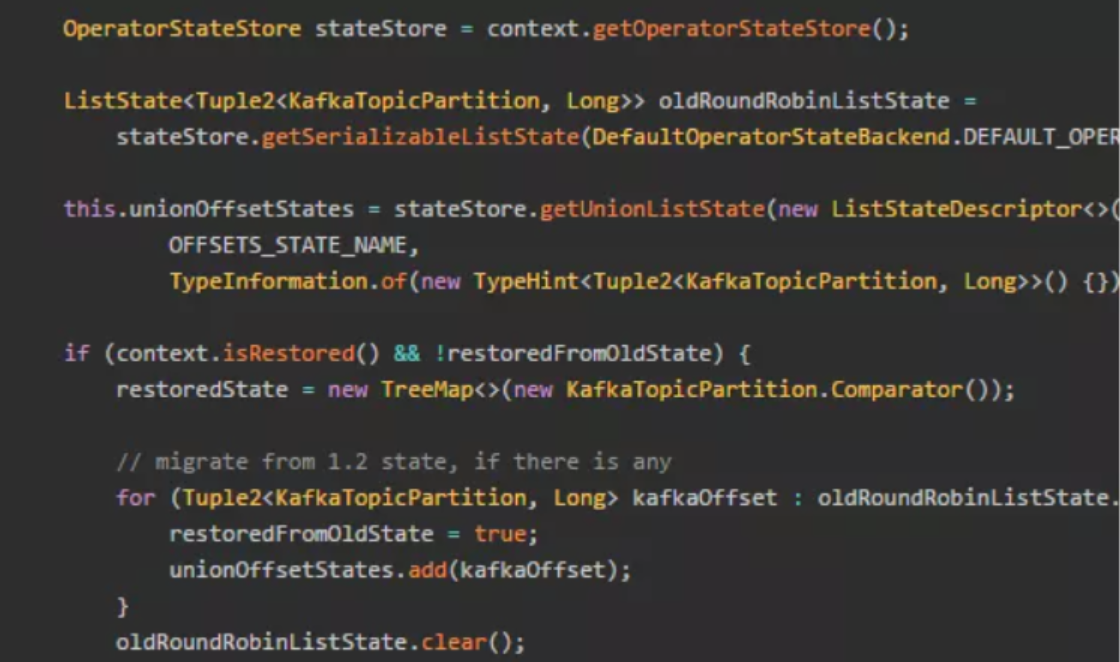
从源码中看到stateBackend中把offset state恢复到restoredState,然后从fetcher拉取最新的offset数据,随后将offset存入到stateBackend中;最后更新xcheckpoint。
2)Flink消费端
Flink内部采用一致性快照机制来保障Exactly-Once的一致性语义。
通过间隔时间自动执行一致性检查点(Checkpoints)程序,b并异步插入barrier检查点分界线。整个流程所有的operator均会进行barrier对齐->数据完成确认->checkpoints状态保存,从而保证数据被精确一次处理。
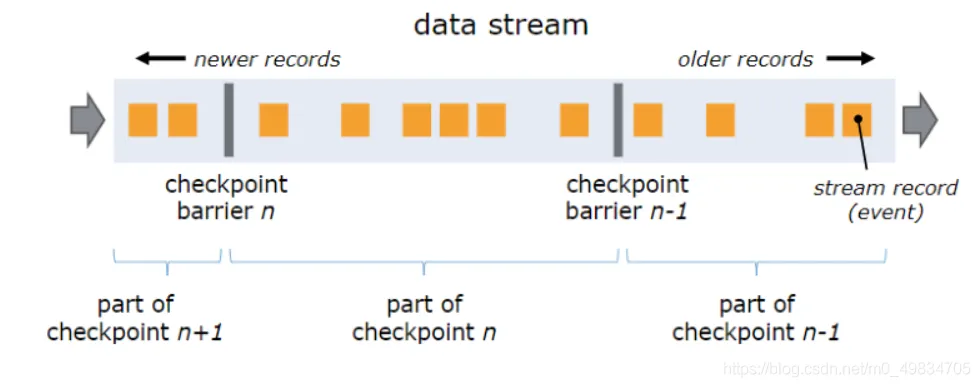
3)输出端
Flink内置二阶段事务提交机制和目标源支持幂等写入。
幂等写入就是多次写入会产生相同的结果,结果具有不可变性。在Flink中saveAsTextFile算子就是一种比较典型的幂等写入。
二阶段提交则对于每个checkpoint创建事务,先预提交数据到sink中,然后等所有的checkpoint全部完成后再真正提交请求到sink, 并把状态改为已确认,从而保证数据仅被处理一次。
为checkpoint创建事务,等到所有的checkpoint全部真正的完成后,才把计算结果写入到sink中。
16 Flink怎么处理迟到数据
-
Flink内置watermark机制,可在一定程度上允许数据延迟 -
程序可在watermark的基础上再配置最大延迟时间 -
开启侧输出流,将延迟的数据输出到侧输出流 -
程序内部控制,延迟过高的数据单独进行后续处理
17 谈谈Flink的双流JOIN
Flink双流JOIN主要分为两大类。一类是基于原生State的Connect算子操作,另一类是基于窗口的JOIN操作。其中基于窗口的JOIN可细分为window join和interval join两种。
实现原理:底层原理依赖Flink的
State状态存储,通过将数据存储到State中进行关联join, 最终输出结果。
1)基于Window Join的双流JOIN实现机制
通俗理解,将两条实时流中元素分配到同一个时间窗口中完成Join。两条实时流数据缓存在Window State中,当窗口触发计算时执行join操作。
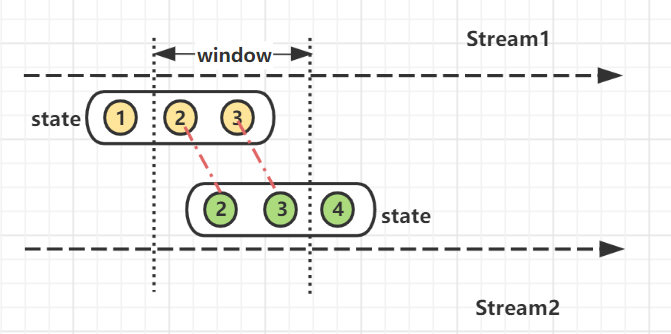
-
join算子操作
两条流数据按照关联主键在(滚动、滑动、会话)窗口内进行inner join, 底层基于State存储,并支持处理时间和事件时间两种时间特征,看下源码:
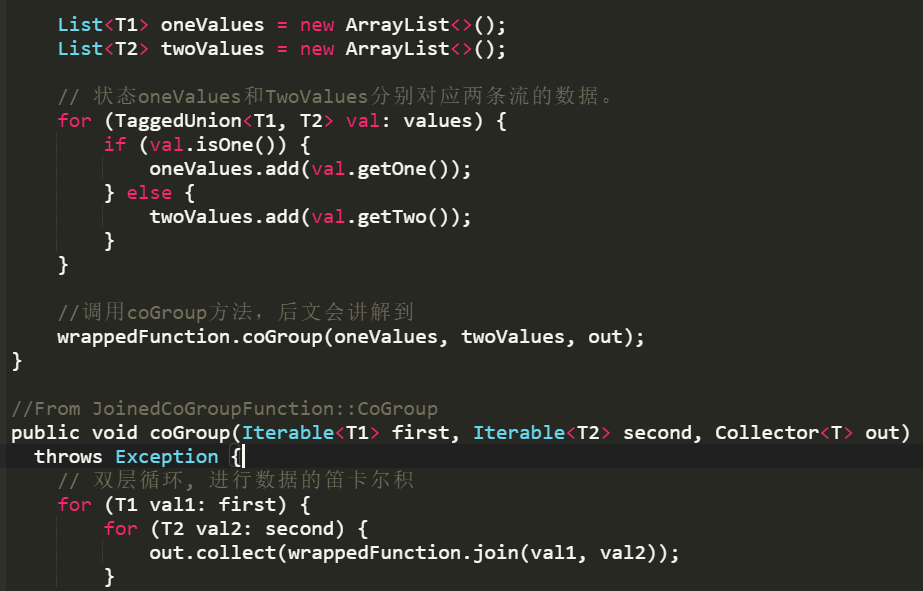
windows窗口、state存储和双层for循环执行join()实现双流JOIN操作,但是此时仅支持inner join类型。
-
coGroup算子操作
coGroup算子也是基于window窗口机制,不过coGroup算子比Join算子更加灵活,可以按照用户指定的逻辑匹配左流或右流数据并输出,达到left join和right join的目的。
orderDetailStream
.coGroup(orderStream)
.where(r -> r.getOrderId())
.equalTo(r -> r.getOrderId())
.window(TumblingProcessingTimeWindows.of(Time.seconds(60)))
.apply(new CoGroupFunction<OrderDetail, Order, Tuple2<String, Long>>() {
@Override
public void coGroup(Iterable<OrderDetail> orderDetailRecords, Iterable<Order> orderRecords, Collector<Tuple2<String, Long>> collector) {
for (OrderDetail orderDetaill : orderDetailRecords) {
boolean flag = false;
for (Order orderRecord : orderRecords) {
// 右流中有对应的记录
collector.collect(new Tuple2<>(orderDetailRecords.getGoods_name(), orderDetailRecords.getGoods_price()));
flag = true;
}
if (!flag) {
// 右流中没有对应的记录
collector.collect(new Tuple2<>(orderDetailRecords.getGoods_name(), null));
}
}
}
})
.print();
2)基于Interval Join的双流JOIN实现机制
Interval Join根据右流相对左流偏移的时间区间(interval)作为关联窗口,在偏移区间窗口中完成join操作。
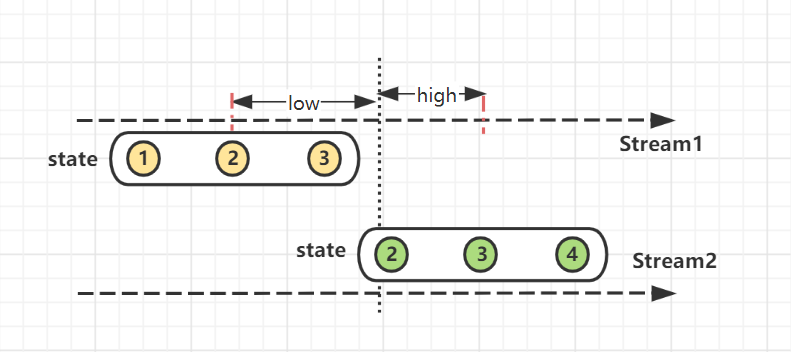
满足数据流stream2在数据流stream1的 interval(low, high)偏移区间内关联join。interval越大,关联上的数据就越多,超出interval的数据不再关联。
实现原理:interval join也是利用Flink的state存储数据,不过此时存在state失效机制
ttl,触发数据清理操作。
val env = ...
// kafka 订单流
val orderStream = ...
// kafka 订单明细流
val orderDetailStream = ...
orderStream.keyBy(_.1)
// 调用intervalJoin关联
.intervalJoin(orderDetailStream._2)
// 设定时间上限和下限
.between(Time.milliseconds(-30), Time.milliseconds(30))
.process(new ProcessWindowFunction())
class ProcessWindowFunction extends ProcessJoinFunction...{
override def processElement(...) {
collector.collect((r1, r2) => r1 + " : " + r2)
}
}
订单流在流入程序后,等候(low,high)时间间隔内的订单明细流数据进行join, 否则继续处理下一个流。interval join目前也仅支持inner join。
3)基于Connect的双流JOIN实现机制
对两个DataStream执行connect操作,将其转化为ConnectedStreams, 生成的Streams可以调用不同方法在两个实时流上执行,且双流之间可以共享状态。
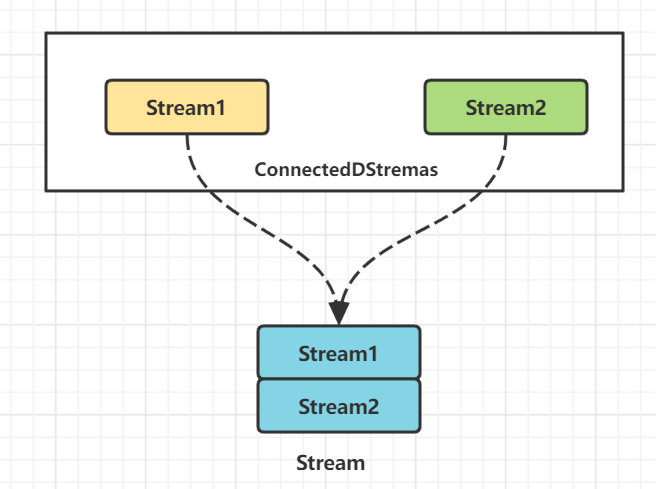
两个数据流被connect之后,只是被放在了同一个流中,内部依然保持各自的数据和形式,两个流相互独立。
[DataStream1, DataStream2] -> ConnectedStreams[1,2]
我们可以在Connect算子底层的ConnectedStreams中编写代码,自行实现双流JOIN的逻辑处理。
-
1)调用connect算子,根据orderid进行分组,并使用process算子分别对两条流进行处理。
orderStream.connect(orderDetailStream)
.keyBy("orderId", "orderId")
.process(new orderProcessFunc());
-
2)process方法内部进行状态编程, 初始化订单、订单明细和定时器的ValueState状态。
private ValueState<OrderEvent> orderState;
private ValueState<TxEvent> orderDetailState;
private ValueState<Long> timeState;
// 初始化状态Value
orderState = getRuntimeContext().getState(
new ValueStateDescriptor<Order>
("order-state",Order.class));
····
-
3)为每个进入的数据流保存state状态并创建定时器。在时间窗口内另一个流达到时进行join并输出,完成后删除定时器。
@Override
public void processElement1(Order value, Context ctx, Collector<Tuple2<Order, OrderDetail>> out){
if (orderDetailState.value() == null){
//明细数据未到,先把订单数据放入状态
orderState.update(value);
//建立定时器,60秒后触发
Long ts = (value.getEventTime()+10)*1000L;
ctx.timerService().registerEventTimeTimer(
ts);
timeState.update(ts);
}else{
//明细数据已到,直接输出到主流
out.collect(new Tuple2<>(value,orderDetailS
tate.value()));
//删除定时器
ctx.timerService().deleteEventTimeTimer
(timeState.value());
//清空状态,注意清空的是支付状态
orderDetailState.clear();
timeState.clear();
}
}
...
@Override
public void processElement2(){
...
}
-
4)未及时达到的数据流触发定时器输出到侧输出流,左流先到而右流未到,则输出左流,反之输出右连流。
@Override
public void onTimer(long timestamp, OnTimerContext ctx, Collector<Tuple2<Order, OrderDetail>> out) {
// 实现左连接
if (orderState.value() != null){
ctx.output(new OutputTag<String>("left-jo
in") {},
orderState.value().getTxId());
// 实现右连接
}else{
ctx.output(new OutputTag<String>("left-jo
in") {},
orderDetailState.value().getTxId());
}
orderState.clear();
orderDetailState.clear();
timeState.clear();
}
4)Flink双流JOIN问题处理总结
-
1)为什么我的双流join时间到了却不触发,一直没有输出
检查一下
watermark的设置是否合理,数据时间是否远远大于watermark和窗口时间,导致窗口数据经常为空
-
2)state数据保存多久,会内存爆炸吗
state自带有
ttl机制,可以设置ttl过期策略,触发Flink清理过期state数据。建议程序中的state数据结构用完后手动clear掉。
-
3)我的双流join倾斜怎么办
join倾斜三板斧: 过滤异常key、拆分表减少数据、打散key分布。当然可以的话我建议加内存!加内存!加内存!!
-
4)想实现多流join怎么办
目前无法一次实现,可以考虑先union然后再二次处理;或者先进行connnect操作再进行join操作,仅建议~
-
5)join过程延迟、没关联上的数据会丢失吗
这个一般来说不会,join过程可以使用侧输出流存储延迟流;如果出现节点网络等异常,Flink checkpoint也可以保证数据不丢失。
由于篇幅有限,更多Flink双流JOIN内容请查看我的相关文章:万字直通Flink双流JOIN面试
18 Flink数据倾斜遇到过吗?怎么处理的
数据倾斜一般都是数据Key分配不均,比如某一类型key数量过多,导致shuffle过程分到某节点数据量过大,内存无法支撑。
1)数据倾斜可能的情况
那我们怎么发现数据倾斜了呢?一般是监控某任务Job执行情况,可以去Yarn UI或者Flink UI观察,一般会出现如下状况:
-
发现某subTask执行时间过慢 -
传输数据量和其他task相差过大 -
BackPressure页面出现反压问题(红色High标识)
结合以上的排查定位到具体的task中执行的算子,一般常见于Keyed类型算子:比如groupBy()、rebance()等产生shuffle过程的操作。
2)数据倾斜的处理方法
-
数据拆分。如果能定位的数据倾斜的key,总结其规律特征。比如发现包含某字符,则可以在代码中把该部分数据key拆分出来,单独处理后拼接。 -
key二次聚合。两次聚合,第一次将key加前缀聚合,分散单点压力;随后去除前缀后再次聚合,得到最终结果。 -
调整参数。加大TaskManager内存、keyby均衡等参数,一般效果不是很好。 -
自定义分区或聚合逻辑。继承分区划分、聚合计算接口,根据数据特征和自定义逻辑,调整数据分区并均匀打散数据key。
19 Flink数据重复怎么办
一般来说Flink可以开启exactly-once机制,可保证精准一次消费。但是如果存在数据处理过程异常导致数据重复,可以借助一些工具或者程序来处理。
建议数据量不大的话可以使用flink自身的state或者借助bitmap结构;稍微大点可以用布隆过滤器或hyperlog工具;其次使用外部介质(redis或hbase)设计好key就行自动去重,只不过会增加处理过程。
总结一下Flink的去重方式:
-
内存去重。采用 Hashset等数据结构,读取数据中类似主键等唯一性标识字段,在内存中存储并进行去重判断。 -
使用 Redis Key去重。借助Redis的Hset等特殊数据类型,自动完成Key去重。 -
DataFrame/SQL场景,使用 group by、over()、window开窗等SQL函数去重 -
利用groupByKey等聚合算子去重
20 聊聊公司的Flink实时数仓架构,为什么这么设计
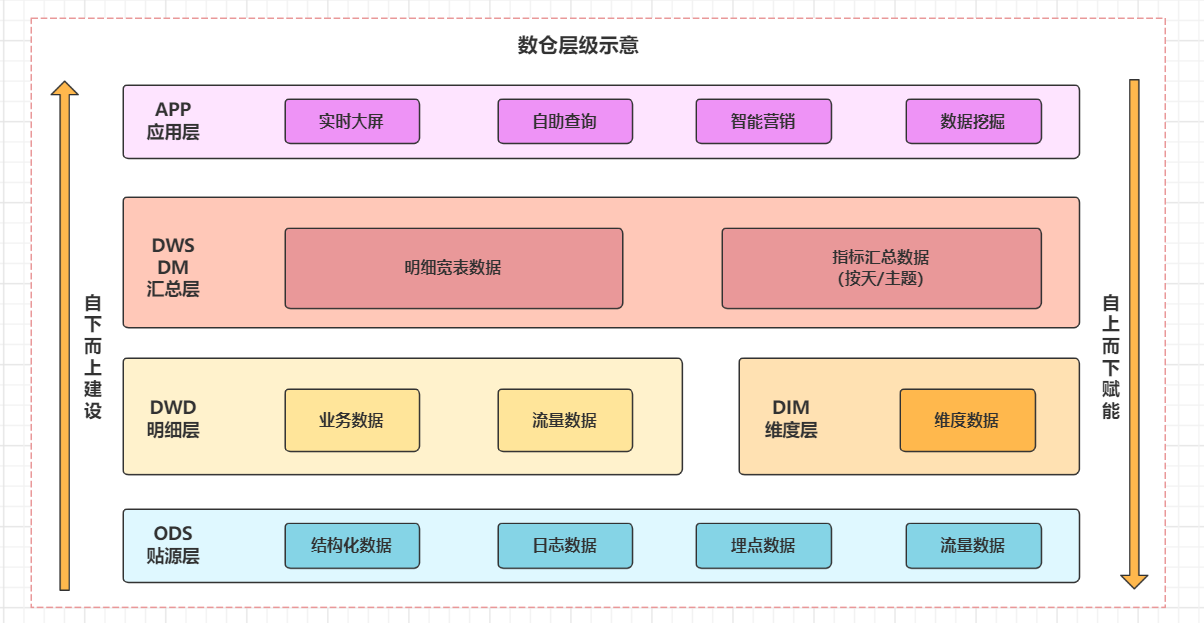
实时数仓数据规整为层级存储,每层独立加工。整体遵循由下向上建设思想,最大化数据赋能。
1)数仓分层设计
-
数据源: 分为 日志数据和业务数据两大类,包括结构化和非结构化数据。 -
数仓类型:根据及时性分为 离线数仓和实时数仓 -
技术栈: -
采集(Sqoop、Flume、CDC) -
存储(Hive、Hbase、Mysql、Kafka、数据湖) -
加工(Hive、Spark、Flink) -
OLAP查询(Kylin、Clickhous、ES、Dorisdb)等。
-
2)数仓架构设计
整体采用Lambda架构。保留实时、离线两条处理流程,即最终会同时构建实时数仓和离线数仓。
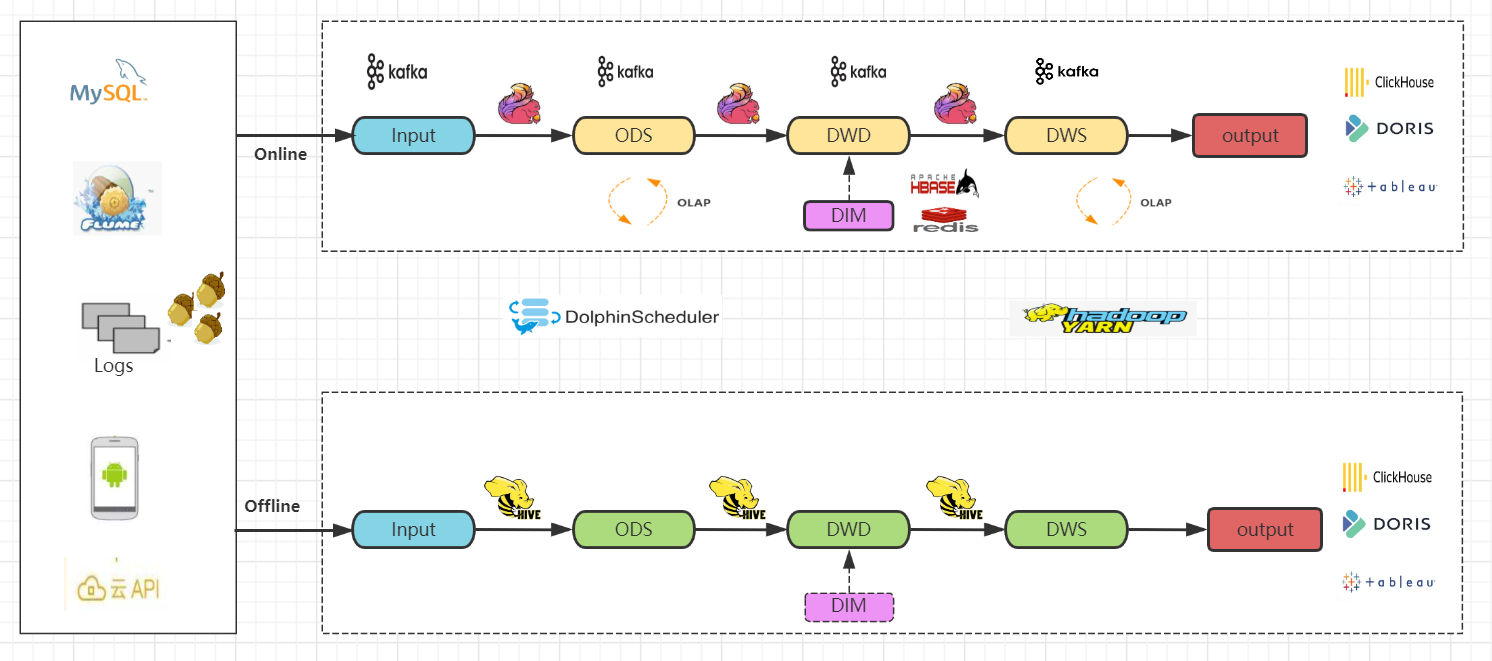
1. 技术实现
-
使用Flink和Kafka、Hive为主要技术栈 -
实时技术流程。通过实时采集程序同步数据到Kafka消息队列 -
Flink实时读取Kafka数据,回写到 kafka ods贴源层topic -
Flink实时读取Kafka的ods层数据,进行实时清洗和加工,结果写入到 kafka dwd明细层topic -
同样的步骤,Flink读取dwd层数据写入到 kafka dws汇总层topic -
离线技术流程和前面章节一致 -
实时olap引擎查询分析、报表展示
2. 优缺点
-
两套技术流程,全面保障实时性和历史数据完整性 -
同时维护两套技术架构,维护成本高,技术难度大 -
相同数据源处理两次且存储两次,产生大量数据冗余和操作重复 -
容易产生数据不一致问题
3)数据流程设计
整体从上而下,数据经过采集 -> 数仓明细加工、汇总 -> 应用步骤,提供实时数仓服务。
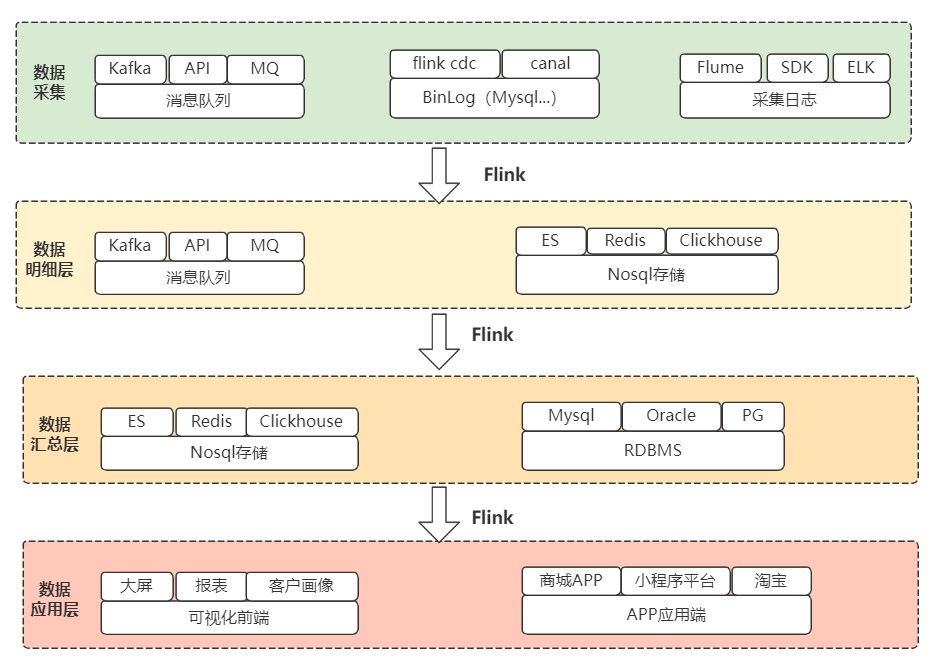
这里列举用户分析的数据流程和技术路线:
采集用户行为数据,统计用户曝光点击信息,构建用户画像。
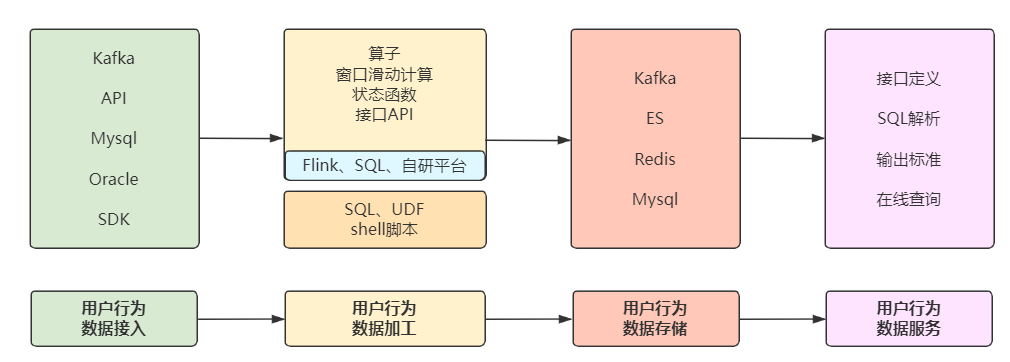 电商实时数仓用户分析数据流程》》更多好文,请关注gzh:大数据兵工厂
电商实时数仓用户分析数据流程》》更多好文,请关注gzh:大数据兵工厂

- 点赞
- 收藏
- 关注作者
评论(0)