干货收藏!基于Spark Graphframes的社交关系图谱项目实战

大家好,我是老兵。
本文是基于Spark Graphframes的社交关系图谱实战演练。
我将结合自身开发和项目经验,分别讲述社交关系图谱原理、图计算原理、Spark Graphframes图计算编程、关联推荐实战等内容,帮助大家快速了解Spark Graphframes图计算的使用。
有兴趣交流沟通的朋友,欢迎添加我个人微信: youlong525。
1 什么是社交关系图谱
社交关系图谱的粗浅理解,即表达社交网络中的人与群体的关系。
我是谁? 我周围人是谁?我们有什么关系?
1)业务通俗理解
比如张三是个资深网络爱好者,也是个圈内达人。我们先来看看他的圈子:家庭圈、同事圈、朋友圈、区域圈、兴趣圈等。。
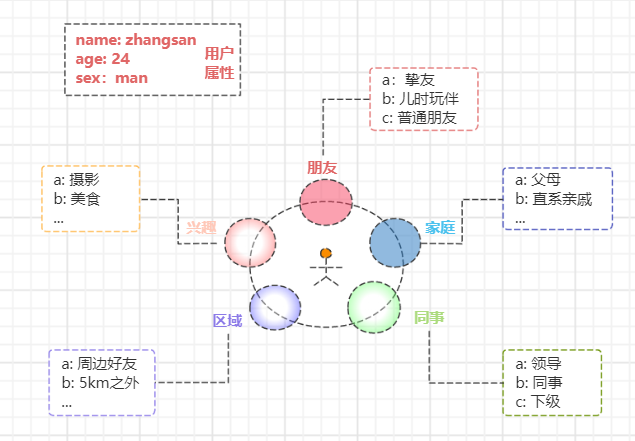
这些圈子中的角色对象。有的和张三关系紧密,如亲朋好友;有的毫不相识,即潜在对象;有的相隔万里却因相同的一个兴趣结识。。。
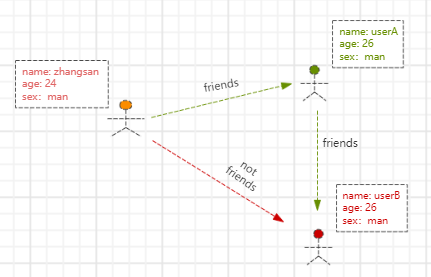
总体而言,这就是张三的社交关系图谱(简略版)。
个体属性 + 群体关系 => 关系图谱
2)数据层面理解
在理解社交关系图谱的业务含义后,我们去看看数据层面的含义。
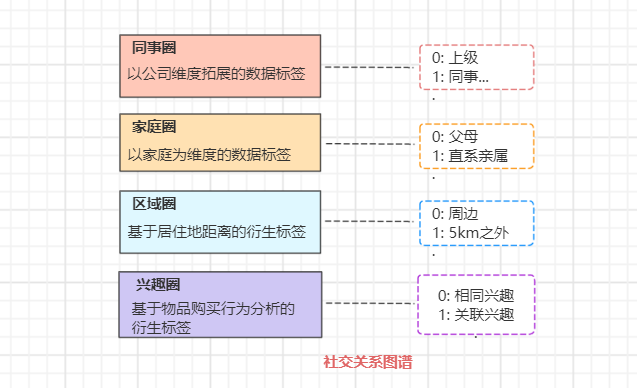
群体关系和个体属性,从数据角度可抽象成包含多维度的数据标签。
类似: 张三(name/age/sex)、朋友(friend/non-friend..)、同事(superior、colleague...)、区域(nearby、non-nearby)等。
最终提炼成丰富的标签化的用户社交数据。
| 关系 | 标签值 |
|---|---|
| 朋友 | 0(friend)、1(non-friend) ... |
| 同事 | 0(superior)、1(colleague) ... |
| 亲戚 | 0(parent)、1(non-parent) ... |
| 区域 | 0(nearby)、1(non-nearby)... |
大多数公司的社交关系图谱建设,一般会基于企业内人与人的关系数据梳理,通过对数据的类型、可信强度,不同来源的分析,构建统一的丰富的社交数据体系,形成关系知识图谱。
2 社交关系图谱与图计算
2.1 图计算模型
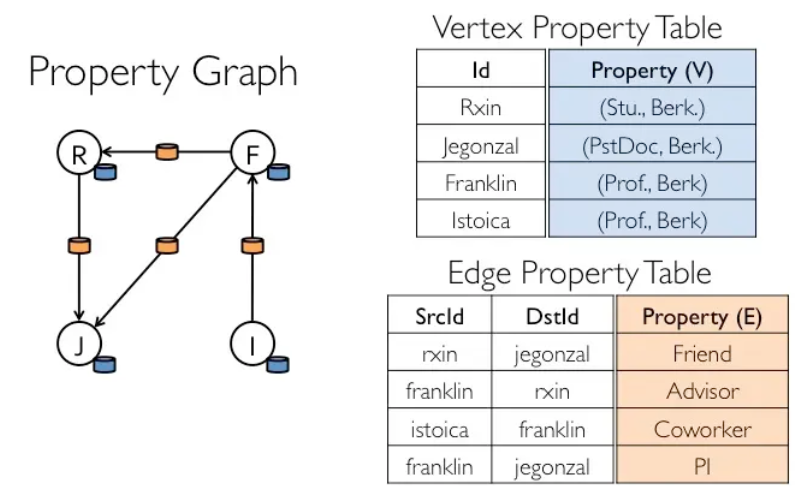
上面我们将关系图谱经过数字化和标签化处理,抽象成带有标签的个体属性和关系数据。
再来看看此时的张三,包含属性特征和一组组的关系特征。
-
属性特征: zhangsan<name、age、sex> -
关系特征:zhangsan ->(friends)-> userA
既然有了数据概念模型,程序中如何去实现呢?仔细看下,属性特征和关系特征数据在结构上符合图结构。
图由一个顶点集合和一条边(或者弧)集合组成,且每一条边都依附于顶点集合的两个顶点。
——来自百度百科

因此关系图谱数据在程序中可被抽象成"点——线"拓扑集合。基于此类数据结构的计算被称作图计算。

2.2 图计算组件
关系图谱数据转换为图数据结构后,一般会使用图计算组件进行开发。
如下列举了生产中常见的图计算引擎特性,供大家参考。
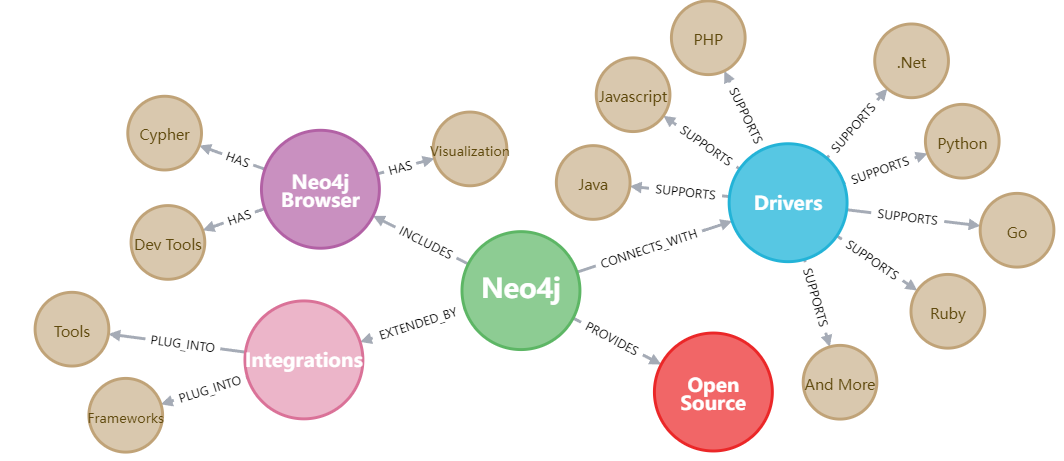
1)Neo4J
-
有很好的可视化界面,支持交互式查询 -
小批量操作时查询效率高,对用户比较友好,适用于OLTP查询 -
不支持数据分片,存储数据有限,数据的导入与更新操作耗时
2)Spark GraphX
-
spark的优点既是SparkGraphX的优点,支持海量数据 -
重点在图计算,而非图存储和查询领域,适合OLAP领域 -
为Scala提供接口,运算基于RDD -
支持常见的图算法
3)Spark GraphFrame
-
运算基于Spark GraphFrame -
为Python、Java和Scala提供了统一的接口,能够使用GraphX的全部算法 -
加入新的图算法(motif finding/BFS) -
图的存储和读取;GraphFrames与DataFrame的数据源完全兼容,支持以Parquet、Json以及Csv等格式完成图的存储与读取。

4)GraphFrames vs GraphX
由于环境和项目技术选型所限,本文选择Spark Graphframes。大家也可以选择Spark Graphx,且GraphFrames和GraphX可相互转化。
// GraphFrames转换为GraphX
val g: Graph[Row, Row] = gf.toGraphX()
// GraphX转换为GraphFrames
val gf: GraphFrame = GraphFrame.fromGraphX(g)
这里我也列出了Spark GraphX和Spark Graphframes的区别。
| GraphFrames | GraphX | |
|---|---|---|
| 数据模型 | DataFrames | RDDs |
| 开发语言 | Scala/Java/Python | Scala |
| 使用场景 | 数据查询、图计算 | 图计算 |
| 顶点ID | Any Type | Long |
| 点边属性 | DataFrame columns | Any Type(VD, ED) |
| 返回类型 | GraphFrame、DataFrame | Graph[VD, ED] 、RDD[Long, VD] |
3 Spark GraphFrames图计算实战
编程环境: Jupter
编程语言: Python
技术组件: Spark Graphframes
实现难度: 中等(可替换为Spark GraphX)
3.1 Spark graphframes基本语法
GraphX中常用算法在GraphFrame的调用方法:
1) 创建图对象(示例)
// 定义顶点
vertices = spark.createDataFrame(
[("a", "Alice", 34), ("b", "Bob", 36)], \
["id", "name", "age"])
// 定义边
edges = spark.createDataFrame(
[("a", "b", "friend")] , ["src", "dst", "relationship"])
// 创建图对象
graph = GraphFrame(vertices,edges)
2)获取边、角、出入度(示例)
// 计算顶点/边
graph.vertices.show()
graph.edges.show()
// 计算顶点度、出入度
graph.degrees.show()
graph.inDegrees.show()
graph.outDegrees.show()
3)依据点、边、出入度的子图筛选
graph.vertices().filter("age > 30").show()
graph.edges.filter("type == friends").show()
graph.inDegrees.filter("inDegree >= 2").show()
4)模式发现(示例)
// 获取a->b的关系
motifs = graph.find("(a)-[e]->(b)")
motifs.show()
5)基本算法(示例)
// PageRank算法
graph.pageRank().maxIter() \
.resetProbability().run() \
.vertices().show()
// 广度优先算法
paths = graph.bfs("name='Alice'", "age > 34")
paths.show()
// 最短路径
graph.shortestPaths(landmarks=lm).show()
// 标签传播算法
graph.labelPropagation().show()
3.2 Spark Graphframes 实战—基于社交关系推荐好友
回到本文的核心,我们将关系图谱数据处理成图结构,且选择Spark Graphframes作为技术组件,下面开始实战演练。
场景分析: 社交网络中,平台会推荐你关注人的喜爱物品,同时也会推荐关注人好友列表给你。
类似于物以类聚、人以群分的道理,有相同爱好、相同圈子的人可能是你感兴趣的人。
这里举个例子:假如userA是zhangsan的朋友,userB是userA的朋友且不是zhangsan的朋友;userB和zhangsan有相同兴趣,则将userB推荐给zhangsan。
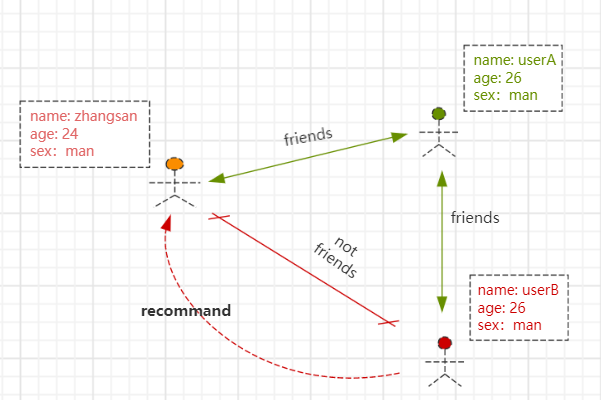
逻辑分析: A->B and B -> C and A >< C,即A与B双向关系、B与C双向关系,但是A->C没有关系,输出(A,C)
1)配置环境
-
环境中安装graphframes-xx.jar包,并指向安装位置 -
代码中引入graphframes依赖
from pyspark.sql import SparkSession
from pyspark import SparkContext
from graphframes import *
from pyspark.sql.functions import *
// 定义SparkContext
conf = SparkConf().set("", "")
// 添加graphframes-xx.jar依赖包
spark = SparkSession \
.builder \
.config(conf=conf) \
.config("spark.jar", "./graphframes-0.9.1-spark2.7-s_2.11.jar") \
.getOrCreate()
sc = spark.sparkContext
2)定义图对象
-
friends表示朋友关系;follow表示跟随关系<可看作有相同爱好> -
Alice和Charies是朋友关系;Esther和Charies没关系 -
Esther是Alice的跟随者,最终推荐Charies给Esther
// Vertics
v = spark.createDataFrame([
("a", "Alice", 34),
("b", "Bob", 36),
("c", "Charlie", 37),
("d", "David", 29),
("e", "Esther", 32),
("f", "Fanny", 38),
("g", "Gabby", 60)
], ["id", "name", "age"])
// Edges
e = spark.createDataFrame([
("a", "b", "follow"),
("a", "c", "friend"),
("a", "g", "friend"),
("b", "c", "friend"),
("c", "a", "friend"),
("c", "b", "friend"),
("c", "d", "follow"),
("c", "g", "friend"),
("d", "a", "follow"),
("d", "g", "friend"),
("e", "a", "follow"),
("e", "d", "follow"),
("f", "b", "follow"),
("f", "c", "follow"),
("f", "d", "follow"),
("g", "a", "friend"),
("g", "c", "friend"),
("g", "d", "friend")
], ["src", "dst", "relationship"])
// Create a GraphFrame
g = GraphFrame(v, e)
3)计算推荐好友
-
方法1:使用模式匹配 -
方法2:使用模式匹配后,取差集
// 计算关联好友
relationG = g.find("(a)-[ab]->(b)") \
.dropDuplicates() \
.selectExpr("a.name as user", "b.name as recommended_user")
// 计算推荐好友
// recommend = g.find("(a)-[ab]->(b);(b)-[bc]->(c); !(a)-[ac]->(c);")
recommend = g.find("(a)-[ab]->(b);(b)-[bc]->(c)") \
.filter("a.id != c.id") \
.filter("ab.relationship = 'follow' \
and bc.relationship = 'friend'") \
.dropDuplicates() \
.selectExpr("a.name as user", "c.name as recommended_user") \
.subtract(relationG)
4)结果输出
-
结果输出(user, recomanduser列表) -
后续可继续分析
result = recommend.rdd.map(
lambda x: (x["user"], x["recommended_user"]
)).sortBy(lambda x: x[0]).collect()
print(result)
 推荐好友列表
推荐好友列表
5)补充:获取社交好友圈数量
获取社交图谱关系链中 "[relationship=='friends']>=2" 的数量
chain = g.find("(a)-[ab]->(b);(b)-[bc]->(c);(c)-[cd]->(d)")
// 定义更新状态条件,关系为friends则+1
sumChain = lambda cnt, relation: when(
relationship == 'friends', cnt + 1) \
.otherwise(cnt)
// 应用到chain,计算好友数量
condition = reduce(lambda cnt, sumChain(
cnt, col(e).relationship), \
["ab", "bc", "cd"], \
lit(0))
// 计算好友圈数
chainWithFriends = chain.where(condition >= 2)
chainWithFriends.show()
4 写在最后
社交关系图谱由家庭、同事、区域、兴趣等组成社交标签体系,可以为企业基于社交维度的用户分析挖掘提供数据基础。
同时基于多维度数据的特性,支持家庭关系、兴趣偏好等相关业务场景,可助力企业从客户维度、产品维度等提供拓客的数据支持。
基于Spark Graphframes图计算技术,可快速实现企业级社交关系图谱项目的实施落地。本文内容仅供参考,关于项目的技术细节和问题后续再继续补充。

- 点赞
- 收藏
- 关注作者
评论(0)