[Python从零到壹] 十三.机器学习之聚类算法四万字总结(K-Means、BIRCH、MeanShift)丨【百变AI秀】

欢迎大家来到“Python从零到壹”,在这里我将分享约200篇Python系列文章,带大家一起去学习和玩耍,看看Python这个有趣的世界。所有文章都将结合案例、代码和作者的经验讲解,真心想把自己近十年的编程经验分享给大家,希望对您有所帮助,文章中不足之处也请海涵。Python系列整体框架包括基础语法10篇、网络爬虫30篇、可视化分析10篇、机器学习20篇、大数据分析20篇、图像识别30篇、人工智能40篇、Python安全20篇、其他技巧10篇。您的关注、点赞和转发就是对秀璋最大的支持,知识无价人有情,希望我们都能在人生路上开心快乐、共同成长。
前一篇文章讲述了回归模型的原理知识,包括线性回归、多项式回归和逻辑回归,并详细介绍Python Sklearn机器学习库的线性回归和逻辑回归算法及案例。本文介绍聚类算法的原理知识级案例,包括K-Means聚类、BIRCH算法、PCA降维聚类、均值漂移聚类、文本聚类等。基础文章,希望对您有所帮助。
文章目录
下载地址:
前文赏析:
第一部分 基础语法
第二部分 网络爬虫
第三部分 数据分析+机器学习
- [Python从零到壹] 十三.机器学习之聚类分析万字总结全网首发(K-Means、BIRCH、层次聚类、树状聚类)
在过去,科学家会根据物种的形状习性规律等特征将其划分为不同类型的门类,比如将人种划分为黄种人、白种人和黑种人,这就是简单的人工聚类方法。聚类是将数据集中某些方面相似的数据成员划分在一起,给定简单的规则,对数据集进行分堆,是一种无监督学习。聚类集合中,处于相同聚类中的数据彼此是相似的,处于不同聚类中的元素彼此是不同的。本章主要介绍聚类概念和常用聚类算法,然后详细讲述Scikit-Learn机器学习包中聚类算法的用法,并通过K-Means聚类、Birch层次聚类及PAC降维三个实例加深读者印象。
俗话说“物以类聚,人以群分”,聚类(Clustering)就是根据“物以类聚”的原理而得。从广义上说,聚类是将数据集中在某些方面相似的数据成员放在一起,聚类中处于相同类簇中的数据元素彼此相似,处于不同类簇中的元素彼此分离。
由于在聚类中那些表示数据类别的分组信息或类标是没有的,即这些数据是没有标签的,所有聚类又被称为无监督学习(Unsupervised Learning)。
聚类是将本身没有类别的样本聚集成不同类型的组,每一组数据对象的集合都叫做簇。聚类的目的是让属于同一个类簇的样本之间彼此相似,而不同类簇的样本应该分离。图1表示聚类的算法模型图。
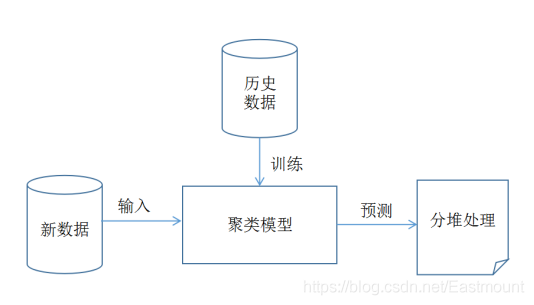
聚类模型的基本步骤包括:
- 训练。通过历史数据训练得到一个聚类模型,该模型用于后面的预测分析。需要注意的是,有的聚类算法需要预先设定类簇数,如KMeans聚类算法。
- 预测。输入新的数据集,用训练得到的聚类模型对新数据集进行预测,即分堆处理,并给每行预测数据计算一个类标值。
- 可视化操作及算法评价。得到预测结果之后,可以通过可视化分析反应聚类算法的好坏,如果聚类结果中相同簇的样本之间距离越近,不同簇的样本之间距离越远,其聚类效果越好。同时采用相关的评价标准对聚类算法进行评估。
常用聚类模型包括:
- K-Means聚类
- 层次聚类
- DBSCAN
- Affinity Propagatio
- MeanShift
聚类算法在Scikit-Learn机器学习包中,主要调用sklearn.cluster子类实现,下面对常见的聚类算法进行简单描述,后面主要介绍K-Means算法和Birch算法实例。
(1) K-Means
K-Means聚类算法最早起源于信号处理,是一种最经典的聚类分析方法。它是一种自下而上的聚类方法,采用划分法实现,其优点是简单、速度快;缺点是必须提供聚类的数目,并且聚类结果与初始中心的选择有关,若不知道样本集要聚成多少个类别,则无法使用K-Means算法。Sklearn包中调用方法如下:
from sklearn.cluster import KMeans
clf = KMeans(n_clusters=2)
clf.fit(X,y)
(2) Mini Batch K-Means
Mini Batch K-means是KMeans的一种变换,目的为了减少计算时间。其实现类是MiniBatchKMeans。Sklearn包中调用方法如下:
from sklearn.cluster import MiniBatchKMeans
X= [[1],[2],[3],[4],[3],[2]]
mbk = MiniBatchKMeans(init='k-means++', n_clusters=3, n_init=10)
clf = mbk.fit(X)
print(clf.labels_)
#输出:[0 2 1 1 1 2]
(3) Birch
Birch是平衡迭代归约及聚类算法,全称为Balanced Iterative Reducing and Clustering using Hierarchies,是一种常用的层次聚类算法。该算法通过聚类特征(Clustering Feature,CF)和聚类特征树(Clustering Feature Tree,CFT)两个概念描述聚类。聚类特征树用来概括聚类的有用信息,由于其占用空间小并且可以存放在内存中,从而提高了算法的聚类速度,产生了较高的聚类质量,Birch算法适用于大型数据集。
Sklearn包中调用方法如下:
from sklearn.cluster import Birch
X = [[1],[2],[3],[4],[3],[2]]
clf = Birch(n_clusters=2)
clf.fit(X)
y_pred = clf.fit_predict(X)
print(clf)
print(y_pred)
#输出:[1 1 0 0 0 1]
上述代码调用Birch算法聚成两类,并对X数据进行训练,共6个点(1、2、3、4、3、2),然后预测其聚类后的类标,输出为0或1两类结果,其中点1、2、2输出类标为1,点3、4、3输出类标为0。这是一个较好的聚类结果,因为值较大的点(3、4)聚集为一类,值较小的点(1、2)聚集为另一类。这里只是进行了简单描述,后面将讲述具体的算法及实例。
(4) Mean Shift
Mean Shift是均值偏移或均值漂移聚类算法,最早是1975年Fukunaga等人在一篇关于概率密度梯度函数的估计论文中提出。它是一种无参估计算法,沿着概率梯度的上升方向寻找分布的峰值。Mean Shift算法先算出当前点的偏移均值,移动该点到其偏移均值,然后以此为新的起始点,继续移动,直到满足一定的条件结束。
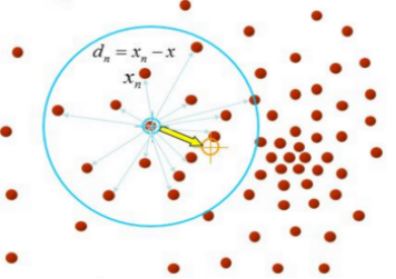
(5) DBSCAN
DBSCAN是一个典型的基于密度的聚类算法,它与划分聚类方法、层次聚类方法不同,它将簇定义为密度相连的点的最大集合,能够把具有足够高密度的区域划分为簇,并可在噪声的空间数据库中发现任意形状的聚类。与K-Means方法相比,DBSCAN不需要事先知道要形成的簇类的数目,它可以发现任意形状的簇类,同时该算法能够识别出噪声点,对于数据集中样本的顺序不敏感。但也存在一定缺点:DBSCAN聚类算法不能很好反映高维数据。
聚类根据文档的相似性把一个文档集合中的文档分成若干类,但是究竟分成多少类,这个要取决于文档集合里文档自身的性质。图3是Scikit-Learn官网中DBSCAN聚类示例结果,该聚类算法应该把文档集合分成3类,而不是2类或4类,这就涉及到了聚类算法评价。
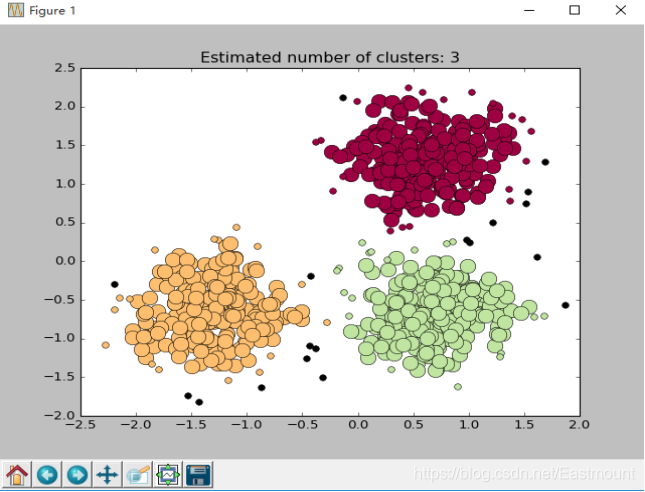
聚类算法的评价应该考虑:聚类之间是否较好地相互分离、同一类簇中的点是否都靠近的中心点、聚类算法是否正确识别数据的类簇或标记。聚类算法的常见评价指标包括纯度(Purity)、F值(F-measure)、熵值(Entropy)和RI,其中F值最为常用。
(1) F值(F-measure)
F值(F-measure或F-score)的计算包括两个指标:精确率(Precision)和召回率(Recall)。精确率定义为检索出相关文档数与检索出的文档总数的比率,衡量的是检索系统的查准率;召回率定义为检索出的相关文档数和文档库中所有相关文档数的比率,衡量的是检索系统的查全率。公式如下:
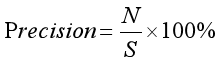

其中,参数N表示实验结果中正确识别出的聚类类簇数,S表示实验结果中实际识别出的聚类类簇数,T表示数据集中所有真实存在的聚类相关类簇数。
精确率和召回率两个评估指标在特定的情况下是相互制约的,因而很难使用单一的评价指标来衡量实验的效果。F-值是准确率和召回率的调和平均值,它可作为衡量实验结果的最终评价指标,F值更接近两个数中较小的那个。F值指的计算公式如下公式所示:
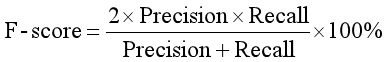
(2) 纯度(Purity)
Purity方法是极为简单的一种聚类评价方法,它表示正确聚类的文档数占总文档数的比例。公式如下:
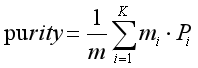
其中,参数m表示整个聚类划分涉及的成员个数;聚类i的纯度定义为Pi;K表示聚类的类簇数目。举个示例,假设聚类成3堆,其中x表示一类数据集,o表示一类数据集,◇表示一类数据集,如图4所示。
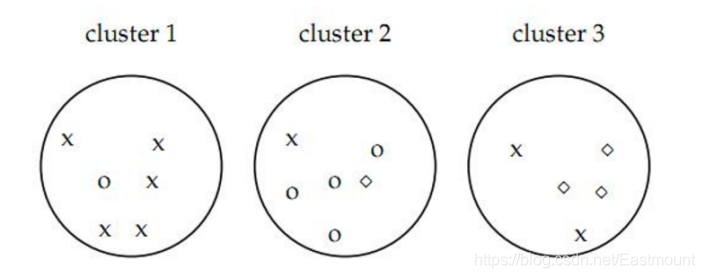
纯度为正确聚类的文档数占总文档数的比例,即:purity=(5+4+3)/17=0.71。其中第一堆聚集正确5个x,第二堆正确聚集4个o,第三队正确聚集3个◇。Purity方法优点在于计算过程简便,值在0~1之间,完全错误的聚类方法值为0,完全正确的聚类方法值为1;其缺点是无法对聚类方法给出正确的评价,尤其是每个文档单独聚集成一类的情况。
(3) 兰德指数(RI)
兰德指数(Rand Index,简称RI)是一种用排列组合原理来对聚类进行评价的手段,公式如下:
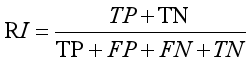
其中参数TP表示被聚在一类的两个文档被正确分类,TN表示不应该被聚在一类的两个文档被正确分开,FP表示不应该放在一类的文档被错误的放在了一类,FN表示不应该分开的文档被错误的分开。
RI越大表示聚类效果准确性越高,同时每个类内的纯度越高,更多评价方法请读者结合实际数据集进行分析。
K-Means聚类是最常用的聚类算法,最初起源于信号处理,其目标是将数据点划分为K个类簇,找到每个簇的中心并使其度量最小化。该算法的最大优点是简单、便于理解,运算速度较快,缺点是只能应用于连续型数据,并且要在聚类前指定聚集的类簇数。
(1) K-Means聚类算法流程
下面作者采用通俗易懂的方法描述K-Means聚类算法的分析流程,步骤如下:
- 第一步,确定K值,即将数据集聚集成K个类簇或小组。
- 第二步,从数据集中随机选择K个数据点作为质心(Centroid)或数据中心。
- 第三步,分别计算每个点到每个质心之间的距离,并将每个点划分到离最近质心的小组,跟定了那个质心。
- 第四步,当每个质心都聚集了一些点后,重新定义算法选出新的质心。
- 第五步,比较新的质心和老的质心,如果新质心和老质心之间的距离小于某一个阈值,则表示重新计算的质心位置变化不大,收敛稳定,则认为聚类已经达到了期望的结果,算法终止。
- 第六步,如果新的质心和老的质心变化很大,即距离大于阈值,则继续迭代执行第三步到第五步,直到算法终止。
图5是对身高和体重进行聚类的算法,将数据集的人群聚集成三类。
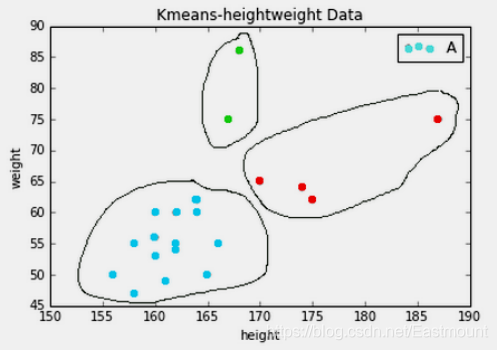
下面通过一个例子讲解K-Means聚类算法,从而加深读者的印象。假设存在如下表1所示六个点,需要将其聚类成两堆。流程如下:
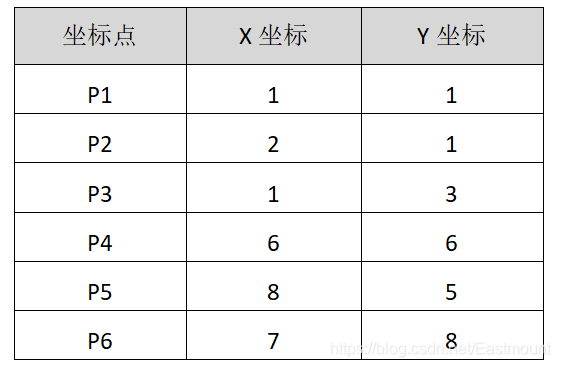
坐标点 X坐标 Y坐标
P1 1 1
P2 2 1
P3 1 3
P4 6 6
P5 8 5
P6 7 8
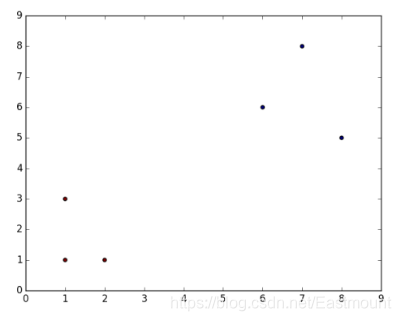
在坐标轴中绘制这6个点的分布如图6所示。
第一步:随机选取质心。假设选择P1和P2点,它们则为聚类的中心。
第二步:计算其他所有点到质心的距离。
计算过程采用勾股定理,如P3点到P1的距离为:

P3点到P2距离为:
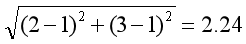
P3离P1更近,则选择跟P1聚集成一堆。同理P4、P5、P6算法如下:
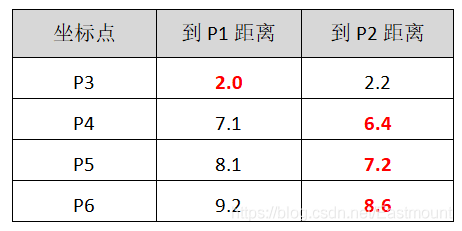
此时聚类分堆情况如下:
- 第一组:P1、P3
- 第二组:P2、P4、P5、P6
第三步:组内从新选择质心。
这里涉及到距离的计算方法,通过不同的距离计算方法可以对K-Means聚类算法进行优化。这里计算组内每个点X坐标的平均值和Y坐标的平均值,构成新的质心,它可能是一个虚拟的点。
- 第一组新质心:
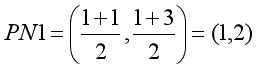
- 第二组新质心:
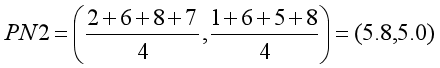
第四步:再次计算各点到新质心的距离。此时可以看到P1、P2、P3离PN1质心较近,P4、P5、P6离PN2质心较近。
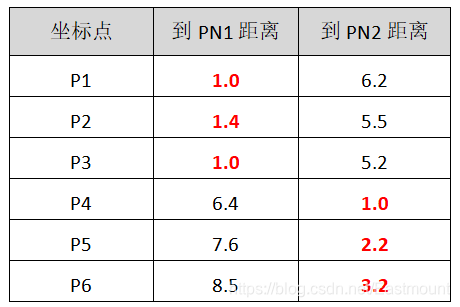
则聚类分堆情况如下,注意由于新的质心PN1和PN2是虚拟的两个点,则不需要对PN1和PN2进行分组。。
- 第一组:P1、P2、P3
- 第二组:P4、P5、P6
第五步:同理,按照第三步计算新的质心。
- 第一组新质心:
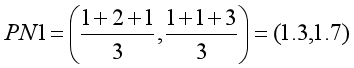
- 第二组新质心:
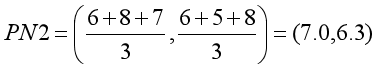
第六步:计算点到新的质心距离。
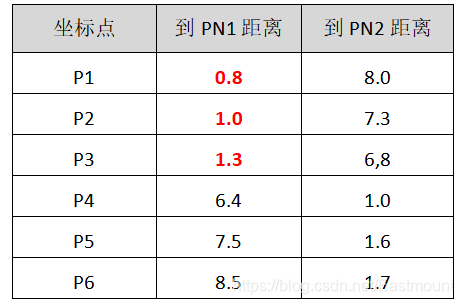
这时可以看到P1、P2、P3离PN1更近,P4、P5、P6离PN2更近,所以第二聚类分堆的结果是:
- 第一组:P1、P2、P3
- 第二组:P4、P5、P6
结论:此时发现,第四步和第六步分组情况都是一样的,说明聚类已经稳定收敛,聚类结束,其聚类结果P1、P2、P3一组,P4、P5、P6是另一组,这和我们最初预想的结果完全一致,说明聚类效果良好。这就是KMeans聚类示例的完整过程。
在Sklearn机器学习包中,调用cluster聚类子库的Kmeans()函数即可进行Kmeans聚类运算,该算法要求输入聚类类簇数。KMeans聚类构造方法如下:
sklearn.cluster.KMeans(n_clusters=8
, init='k-means++'
, n_init=10
, max_iter=300
, tol=0.0001
, precompute_distances=True
, verbose=0
, random_state=None
, copy_x=True
, n_jobs=1)
其中,参数解释如下:
- n_clusters:表示K值,聚类类簇数
- max_iter:表示最大迭代次数,可省略
- n_init:表示用不同初始化质心运算的次数,由于K-Means结果是受初始值影响的局部最优的迭代算法,因此需要多运行几次算法以选择一个较好的聚类效果,默认是10,一般不需要更改,如果你的K值较大,则可以适当增大这个值
- Init:是初始值选择的方式,可以为完全随机选择’random’,优化过的’k-means++‘或者自己指定初始化的K个质心,建议使用默认的’k-means++’
下面举个简单的实例,分析前面的例子中的6个点,设置聚类类簇数为2(n_clusters=2),调用KMeans(n_clusters=2)函数聚类,通过clf.fit()函数装载数据训练模型。代码如下:
from sklearn.cluster import KMeans
X = [[1,1],[2,1],[1,3],[6,6],[8,5],[7,8]]
y = [0,0,0,1,1,1]
clf = KMeans(n_clusters=2)
clf.fit(X,y)
print(clf)
print(clf.labels_)
输出结果如下:
>>>
KMeans(copy_x=True, init='k-means++', max_iter=300, n_clusters=2, n_init=10,
n_jobs=1, precompute_distances='auto', random_state=None, tol=0.0001,
verbose=0)
[0 0 0 1 1 1]
>>>
clf.labels_表示输出K-means聚类后的类标。由于聚类类簇设置为2,故类标为0或1,其中X[1,1]、X[2,1]、X[1,3]聚类后属于0类,X[6,6]、X[8,5]、X[7,8]聚类后属于1类。
调用Matplotlib扩展包的scatter()函数可以绘制散点图,代码的具体含义将在接下来的K-Means分析篮球数据中详细介绍。代码如下:
# -*- coding: utf-8 -*-
# By:Eastmount CSDN 2021-07-03
from sklearn.cluster import KMeans
X = [[1,1],[2,1],[1,3],[6,6],[8,5],[7,8]]
y = [0,0,0,1,1,1]
clf = KMeans(n_clusters=2)
clf.fit(X,y)
print(clf)
print(clf.labels_)
import matplotlib.pyplot as plt
a = [n[0] for n in X]
b = [n[1] for n in X]
plt.scatter(a, b, c=clf.labels_)
plt.show()
输出结果如图7所示,其中右上角红色三个点聚集在一起,左下角蓝色三个点聚集在一起,聚类效果明显。
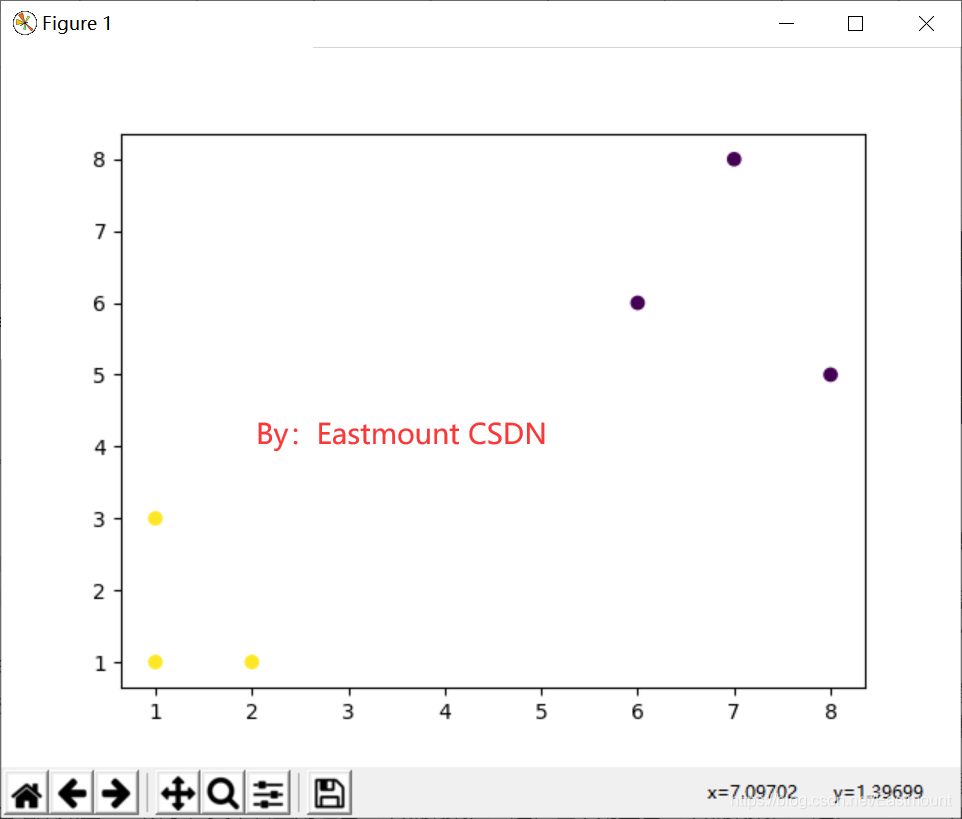
读者为了区分,建议将不同类簇的点绘制成不同类型的散点图,便于对比观察。
(1) 篮球数据集
数据集使用的是篮球运动员数据:KEEL-dateset Basketball dataset,下载地址为:
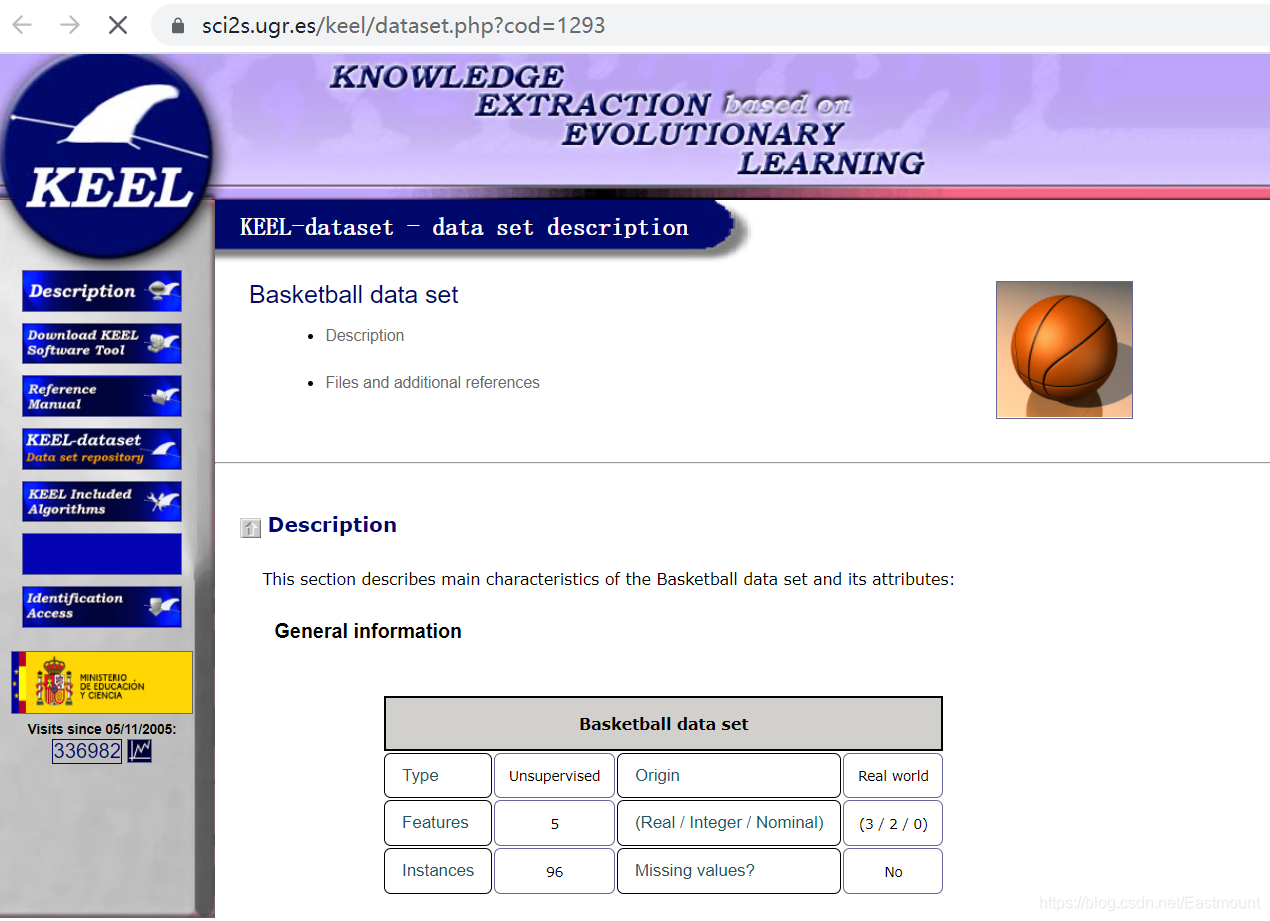
该数据集主要包括5个特征,共96行数据,特征包括运动员身高(height)、每分钟助攻数(assists_per_minute)、运动员出场时间(time_played)、运动员年龄(age)和每分钟得分数(points_per_minute)。其特征和值域如图8所示,比如每分钟得分数为0.45,一场正常的NBA比赛共48分钟,则场均能得21.6分。

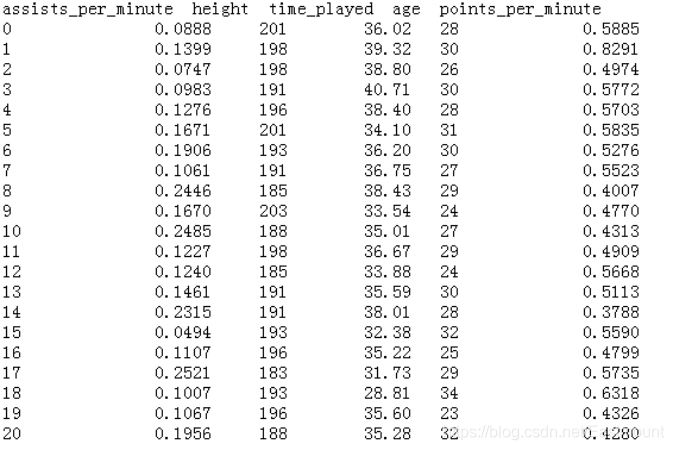
下载篮球数据集,前20行数据如图9所示。
(2) K-Means聚类
现在需要通过篮球运动员的数据,判断该运动员在比赛中属于什么位置。如果某个运动员得分能力比较强,他可能是得分后卫;如果篮板能力比较强,他可能是中锋。
下面获取助攻数和得分数两列数据的20行,相当于20*2矩阵。主要调用Sklearn机器学习包的KMeans()函数进行聚类,调用Matplotlib扩展包绘制图形。完整代码如下:
# -*- coding: utf-8 -*-
# By:Eastmount CSDN 2021-07-03
from sklearn.cluster import KMeans
X = [[0.0888, 0.5885],
[0.1399, 0.8291],
[0.0747, 0.4974],
[0.0983, 0.5772],
[0.1276, 0.5703],
[0.1671, 0.5835],
[0.1906, 0.5276],
[0.1061, 0.5523],
[0.2446, 0.4007],
[0.1670, 0.4770],
[0.2485, 0.4313],
[0.1227, 0.4909],
[0.1240, 0.5668],
[0.1461, 0.5113],
[0.2315, 0.3788],
[0.0494, 0.5590],
[0.1107, 0.4799],
[0.2521, 0.5735],
[0.1007, 0.6318],
[0.1067, 0.4326],
[0.1956, 0.4280]
]
print(X)
# Kmeans聚类
clf = KMeans(n_clusters=3)
y_pred = clf.fit_predict(X)
print(clf)
print(y_pred)
# 可视化操作
import numpy as np
import matplotlib.pyplot as plt
x = [n[0] for n in X]
y = [n[1] for n in X]
plt.scatter(x, y, c=y_pred, marker='x')
plt.title("Kmeans-Basketball Data")
plt.xlabel("assists_per_minute")
plt.ylabel("points_per_minute")
plt.legend(["Rank"])
plt.show()
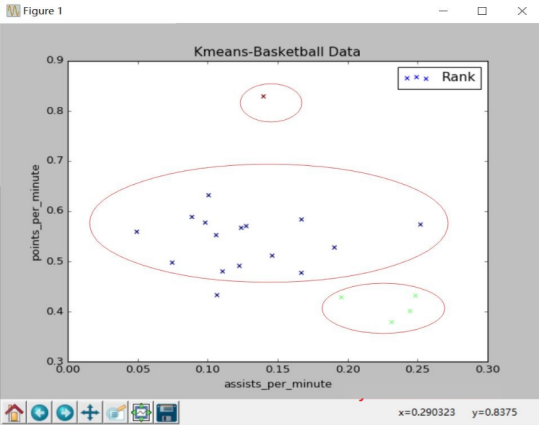
运行结果如下图10所示,从图中可以看到聚集成三类,顶部红色点所代表的球员比较厉害,得分和助攻都比较高,可能类似于NBA中乔丹、科比等得分巨星;中间蓝色点代表普通球员那一类;右下角绿色表示助攻高得分低的一类球员,可能是控位。代码中y_pred表示输出的聚类类标,类簇数设置为3,则类标位0、1、2,它与20个球员数据一一对应。
(3) 代码详解
推荐读者结合作者分享的文件用法进行读取及聚类。
-
from sklearn.cluster import KMeans
表示在sklearn包中导入KMeans聚类模型,调用 sklearn.cluster.KMeans 这个类。 -
X = [[164,62],[156,50],…]
X是数据集,包括2列20行,对应20个球员的助攻数和得分数。 -
clf = KMeans(n_clusters=3)
表示调用KMeans()函数聚类分析,并将数据集聚集成类簇数为3后的模型赋值给clf。 -
y_pred =clf.fit_predict(X)
调用clf.fit_predict(X)函数对X数据集(20行数据)进行聚类分析,并将预测结果赋值给y_pred变量,每个y_pred对应X的一行数据,聚成3类,类标分别为0、1、2。 -
print(y_pred)
输出预测结果:[0 2 0 0 0 0 0 0 1 0 1 0 0 0 1 0 0 0 0 0 1]。 -
import matplotlib.pyplot as plt
导入matplotlib.pyplot扩展包来进行可视化绘图,as表示重命名为plt,便于后续调用。 -
x = [n[0] for n in X]
y = [n[1] for n in X]
分别获取获取第1列和第2列值,并赋值给x和y变量。通过for循环获取,n[0]表示X第一列,n[1]表示X第2列。 -
plt.scatter(x, y, c=y_pred, marker=‘o’)
调用scatter()函数绘制散点图,横轴为x,获取的第1列数据;纵轴为y,获取的第2列数据;c=y_pred为预测的聚类结果类标;marker='o’说明用点表示图形。 -
plt.title(“Kmeans-Basketball Data”)
表示绘制图形的标题为“Kmeans-Basketball Data”。 -
plt.xlabel(“assists_per_minute”)
-
plt.ylabel(“points_per_minute”)
表示输出图形x轴的标题和y轴的标题。 -
plt.legend([“Rank”])
设置右上角图例。 -
plt.show()
最后调用show()函数将绘制的图形显示出来。
上面的代码存在一个问题是需要优化的,可能细心的读者已经发现了。那就是前面的代码定义了X数组(共20行、每行2个特征),再对其进行数据分析,而实际数据集通常存储在TXT、CSV、XLS等格式文件中,并采用读取文件的方式进行数据分析的。那么,如何实现读取文件中数据再进行聚类分析的代码呢?
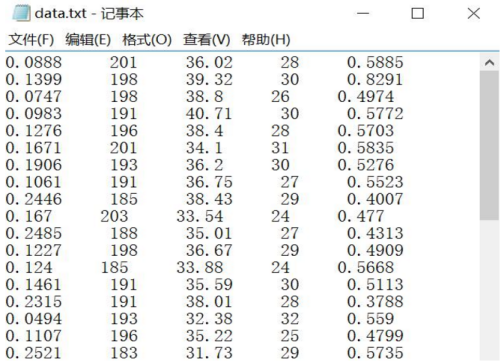
接下来,作者将完整的96行篮球数据存储至TXT文件进行读取操作,再调用K-Means算法聚类分析,并将聚集的三类数据绘制成想要的颜色和形状。假设下载的篮球数据集存在在本地data.txt文件中,如下所示。
首先,需要将data.txt数据读取,然后赋值到data变量数组中,代码如下。
# -*- coding: utf-8 -*-
import os
data = []
for line in open("data.txt", "r").readlines():
line = line.rstrip() #删除换行
result = ' '.join(line.split()) #删除多余空格,保存一个空格连接
#获取每行的五个值,如'0 0.0888 201 36.02 28 0.5885',并将字符串转换为小数
s = [float(x) for x in result.strip().split(' ')]
#输出结果:['0', '0.0888', '201', '36.02', '28', '0.5885']
print(s)
#数据存储至data
data.append(s)
#输出完整数据集
print(data)
print(type(data))
现在输出的结果如下:
['0 0.0888 201 36.02 28 0.5885',
'1 0.1399 198 39.32 30 0.8291',
'2 0.0747 198 38.80 26 0.4974',
'3 0.0983 191 40.71 30 0.5772',
'4 0.1276 196 38.40 28 0.5703',
....
]
然后需要获取数据集中的任意两列数据进行数据分析,赋值给二维矩阵X,对应可视化图形的X轴和Y轴,这里调用dict将两列数据绑定,再将dict类型转换位list。
#获取任意列数据
print('第一列 第五列数据')
L2 = [n[0] for n in data] #第一列表示球员每分钟助攻数:assists_per_minute
L5 = [n[4] for n in data] #第五列表示球员每分钟得分数:points_per_minute
T = dict(zip(L2,L5)) #两列数据生成二维数据
type(T)
#下述代码将dict类型转换为list
X = list(map(lambda x,y: (x,y), T.keys(),T.values()))
print(type(X))
print(X)
输出结果如下图所示:
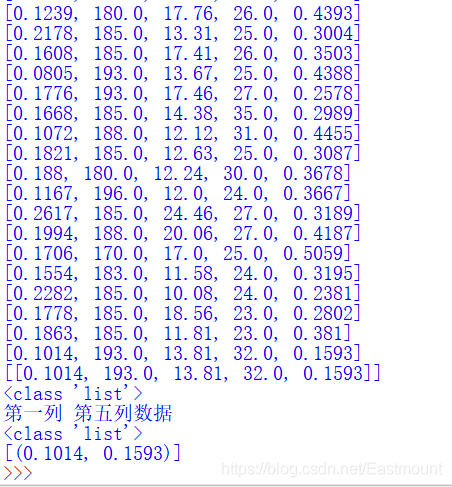
接下来就是调用KMeans(n_clusters=3)函数聚类,聚集的类簇数为3。输出聚类预测结果,共96行数据,每个y_pred对应X一行数据或一个球员,聚成3类,其类标为0、1、2。其中,clf.fit_predict(X) 表示载入数据集X训练预测,并且将聚类的结果赋值给y_pred。
from sklearn.cluster import KMeans
clf = KMeans(n_clusters=3)
y_pred = clf.fit_predict(X)
print(clf)
print(y_pred)
最后是可视化分析代码,并生成三堆指定的图形和颜色散点图。
完整代码如下:
# -*- coding: utf-8 -*-
# By:Eastmount CSDN 2021-07-03
#------------------------------------------------------------------------
#第一步 读取数据
import os
data = []
for line in open("data.txt", "r").readlines():
line = line.rstrip()
result = ' '.join(line.split())
#将字符串转换为小数
s = [float(x) for x in result.strip().split(' ')]
print(s)
data.append(s)
print(data)
print(type(data))
#------------------------------------------------------------------------
#第二步 获取两列数据
print('第一列 第五列数据')
L2 = [n[0] for n in data] #第一列表示球员每分钟助攻数:assists_per_minute
L5 = [n[4] for n in data] #第五列表示球员每分钟得分数:points_per_minute
T = dict(zip(L2,L5)) #两列数据生成二维数据
type(T)
print(L2)
#下述代码将dict类型转换为list
X = list(map(lambda x,y: (x,y), T.keys(),T.values()))
print(type(X))
print(X)
#------------------------------------------------------------------------
#第三步 聚类分析
from sklearn.cluster import KMeans
clf = KMeans(n_clusters=3)
y_pred = clf.fit_predict(X)
print(clf)
print(y_pred)
#------------------------------------------------------------------------
#第四步 绘制图形
import numpy as np
import matplotlib.pyplot as plt
#获取第一列和第二列数据,使用for循环获取,n[0]表示X第一列
x = [n[0] for n in X]
y = [n[1] for n in X]
#坐标
x1, y1 = [], []
x2, y2 = [], []
x3, y3 = [], []
#分布获取类标为0、1、2的数据并赋值给(x1,y1) (x2,y2) (x3,y3)
i = 0
while i < len(X):
if y_pred[i]==0:
x1.append(X[i][0])
y1.append(X[i][1])
elif y_pred[i]==1:
x2.append(X[i][0])
y2.append(X[i][1])
elif y_pred[i]==2:
x3.append(X[i][0])
y3.append(X[i][1])
i = i + 1
#三种颜色 红 绿 蓝,marker='x'表示类型,o表示圆点、*表示星型、x表示点
plot1, = plt.plot(x1, y1, 'or', marker="x")
plot2, = plt.plot(x2, y2, 'og', marker="o")
plot3, = plt.plot(x3, y3, 'ob', marker="*")
plt.title("Kmeans-Basketball Data") #绘制标题
plt.xlabel("assists_per_minute") #绘制x轴
plt.ylabel("points_per_minute") #绘制y轴
plt.legend((plot1, plot2, plot3), ('A', 'B', 'C'), fontsize=10) #设置右上角图例
plt.show()
输出结果如下图所示:
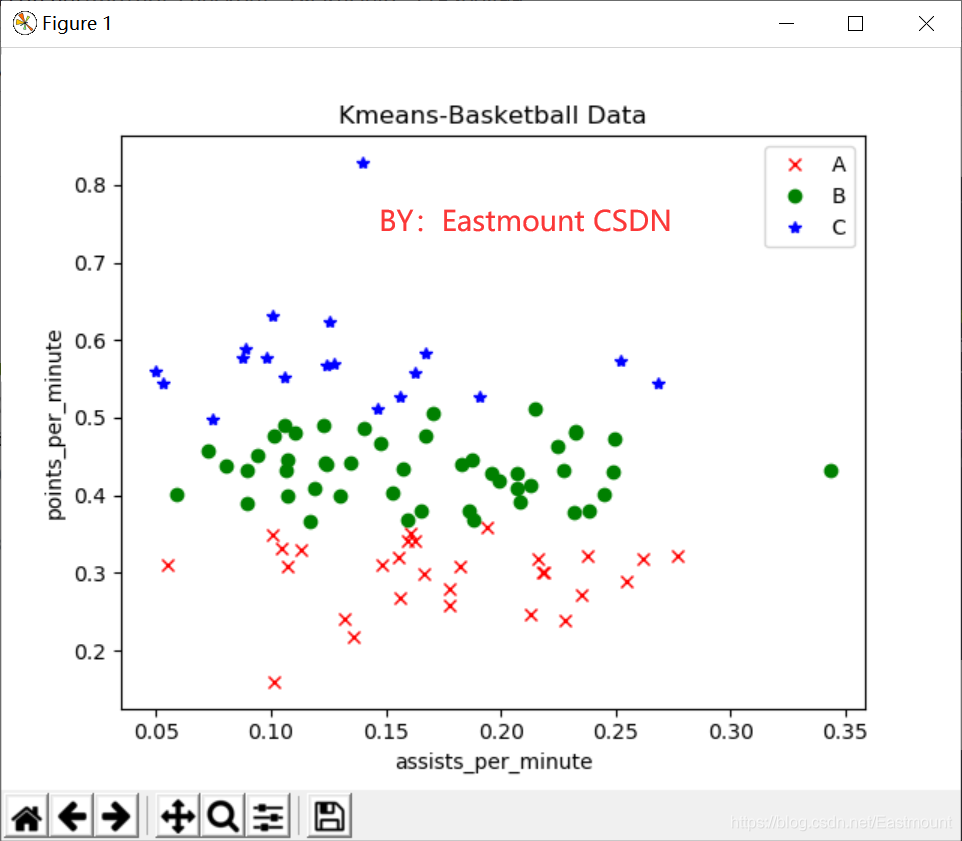
KMeans聚类时,寻找类簇中心或质心的过程尤为重要,那么聚类后的质心是否可以显示出来呢?答案是可以的,下面这段代码就是显示前面对篮球运动员聚类分析的类簇中心并绘制相关图形。完整代码如下。
# -*- coding: utf-8 -*-
# By:Eastmount CSDN 2021-07-03
#------------------------------------------------------------------------
#第一步 读取数据
import os
data = []
for line in open("data.txt", "r").readlines():
line = line.rstrip()
result = ' '.join(line.split())
#将字符串转换为小数
s = [float(x) for x in result.strip().split(' ')]
print(s)
data.append(s)
print(data)
print(type(data))
#------------------------------------------------------------------------
#第二步 获取两列数据
print('第一列 第五列数据')
L2 = [n[0] for n in data] #第一列表示球员每分钟助攻数:assists_per_minute
L5 = [n[4] for n in data] #第五列表示球员每分钟得分数:points_per_minute
T = dict(zip(L2,L5)) #两列数据生成二维数据
type(T)
print(L2)
#下述代码将dict类型转换为list
X = list(map(lambda x,y: (x,y), T.keys(),T.values()))
print(type(X))
print(X)
#------------------------------------------------------------------------
#第三步 聚类分析
from sklearn.cluster import KMeans
clf = KMeans(n_clusters=3)
y_pred = clf.fit_predict(X)
print(clf)
print(y_pred)
#------------------------------------------------------------------------
#第四步 绘制图形
import numpy as np
import matplotlib.pyplot as plt
#获取第一列和第二列数据,使用for循环获取,n[0]表示X第一列
x = [n[0] for n in X]
y = [n[1] for n in X]
#坐标
x1, y1 = [], []
x2, y2 = [], []
x3, y3 = [], []
#分布获取类标为0、1、2的数据并赋值给(x1,y1) (x2,y2) (x3,y3)
i = 0
while i < len(X):
if y_pred[i]==0:
x1.append(X[i][0])
y1.append(X[i][1])
elif y_pred[i]==1:
x2.append(X[i][0])
y2.append(X[i][1])
elif y_pred[i]==2:
x3.append(X[i][0])
y3.append(X[i][1])
i = i + 1
#三种颜色 红 绿 蓝,marker='x'表示类型,o表示圆点、*表示星型、x表示点
plot1, = plt.plot(x1, y1, 'or', marker="x")
plot2, = plt.plot(x2, y2, 'og', marker="o")
plot3, = plt.plot(x3, y3, 'ob', marker="*")
plt.title("Kmeans-Basketball Data") #绘制标题
plt.xlabel("assists_per_minute") #绘制x轴
plt.ylabel("points_per_minute") #绘制y轴
plt.legend((plot1, plot2, plot3), ('A', 'B', 'C'), fontsize=10) #设置右上角图例
#------------------------------------------------------------------------
#第五步 设置类簇中心
centers = clf.cluster_centers_
print(centers)
plt.plot(centers[:,0],centers[:,1],'r*',markersize=20) #显示三个中心点
plt.show()
输出如下图所示,可以看到三个红色的五角星为类簇中心。
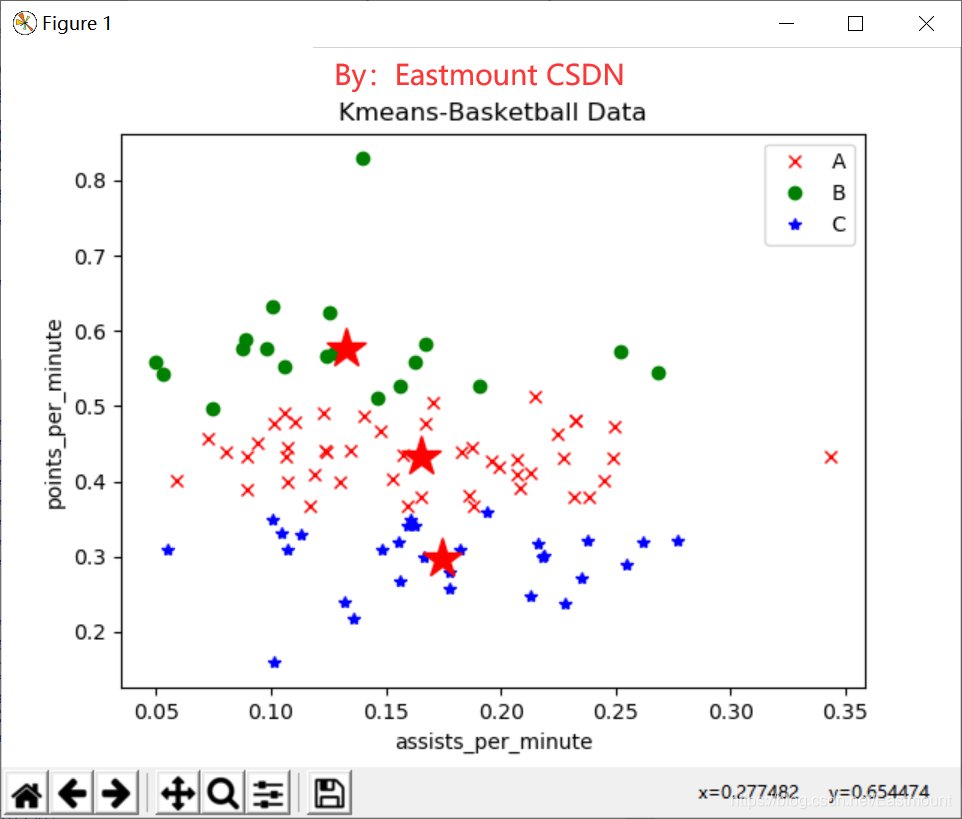
其中类簇中心的坐标为:
[[ 0.1741069 0.29691724]
[ 0.13618696 0.56265652]
[ 0.16596136 0.42713636]]
Birch聚类算法称为平衡迭代归约及聚类算法,它是一种常用的层次聚类算法。该算法通过聚类特征(Clustering Feature,CF)和聚类特征树(Clustering Feature Tree,CFT)两个概念描述聚类。聚类特征树用来概括聚类的有用信息,由于其占用空间小并且可以存放在内存中,从而提高了算法的聚类速度,产生了较高的聚类质量,并适用于大型数据集。层次聚类算法是讲数据样本组成一颗聚类树,根据层次分解是以自顶向下(分裂)还是自底向上(合并)方式进一步合并或分裂。
Birch聚类算法的聚类特征(CF)通过三元组结构描述了聚类类簇的基本信息,其中三元组结构公式如下:
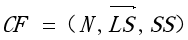
其中,N表示聚类数据点的个数,每个点用一个d维向量表示;表示N个聚类数据点的线性和;SS表示N个聚类数据点的平方和。聚类特征通过线性和表示聚类的质心,通过平方和表示聚类的直径大小。
Birch算法主要包括以下三个阶段:
- 设定初始阈值z并扫描整个数据集D,再根据该阈值建立一棵聚类特征树T。
- 通过提升阈值z重建该聚类特征树T,从而得到一棵压缩的CF树。
- 利用全局性聚类算法对CF树进行聚类,改进聚类质量以得到更好的聚类结果。
Birch聚类算法具有处理的数据规模大、算法效率高、更容易计算类簇的直径和类簇之间的距离等优点。
在Sklearn机器学习包中,调用cluster聚类子库的Birch()函数即可进行Birch聚类运算,该算法要求输入聚类类簇数。Birch类构造方法如下:
sklearn.cluster.Birch(branching_factor=50
, compute_labels=True
, copy=True
, n_clusters=3
, threshold=0.5)
其中,最重要的参数n_clusters=3表示该聚类类簇数为3,即聚集成3堆。下面举个简单的实例,使用前面的例子中的6个点进行,设置聚类类簇数为2(n_clusters=2),调用Birch()函数聚类,通过clf.fit()装载数据训练模型。代码如下:
from sklearn.cluster import Birch
X = [[1,1],[2,1],[1,3],[6,6],[8,5],[7,8]]
y = [0,0,0,1,1,1]
clf = Birch(n_clusters=2)
clf.fit(X,y)
print(clf.labels_)
输出结果如下:
>>>
[0 0 0 1 1 1]
>>>
clf.labels_表示输出聚类后的类标。由于聚类类簇设置为2,故类标为0或1,其中X[1,1]、X[2,1]、X[1,3]聚类后属于0类,X[6,6]、X[8,5]、X[7,8]聚类后属于1类。
(1) 数据集
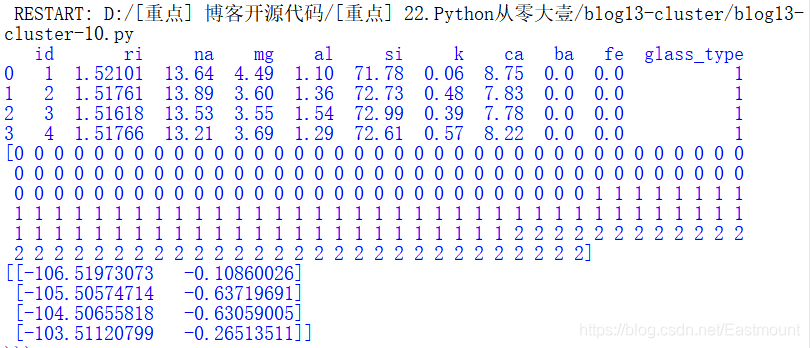
数据来源为UCI的玻璃数据集(Glass Identification Database)。该数据集包括7种类型的玻璃,各个特征是定义它们的氧化物含量(即钠,铁,钾等)。数据集中化学符号包括:Na-钠、Mg-镁、Al-铝、Si-硅、K-钾、Ca-钙、Ba-钡、Fe-铁。数据集为glass.csv文件,前10行数据(包括列名第一行)如下图14所示。
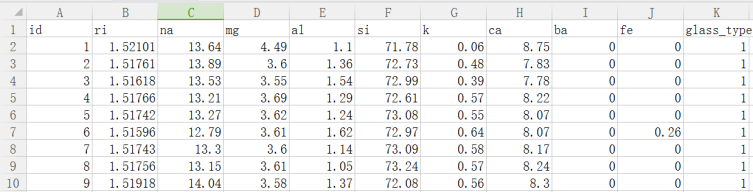
数据集共包含9个特征变量,分别为ri、na、mg、al、si、k、ca、ba、fe,1个类别变量glass_type,共有214个样本。其中类别变量glass_type包括7个值,分别是:1 表示浮动处理的窗口类型、2表示非浮动处理的窗口类型、3表示浮动处理的加工窗口类型、4表示非浮动处理的加工窗口类型(该类型在该数据集中不存在)、5表示集装箱类型、6表示餐具类型、7表示头灯类型。
数据集地址:
(2) 算法实现
首先调用Pandas库读取glass.csv文件中的数据,并绘制简单的散点图,代码如下:
import pandas as pd
import matplotlib.pyplot as plt
glass = pd.read_csv("glass.csv")
plt.scatter(glass.al, glass.ri, c=glass.glass_type)
plt.xlabel('al')
plt.ylabel('ri')
plt.show()
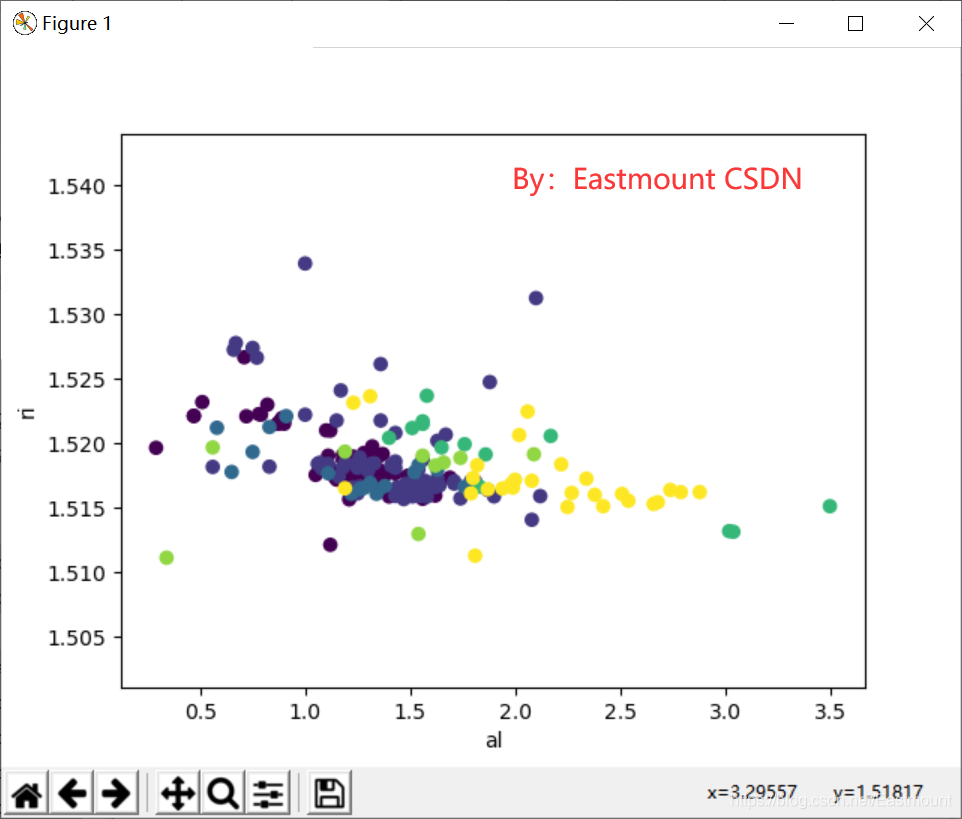
首先调用Pandas的read_csv()函数读取文件,然后调用Matplotlib.pyplot包中的scatter()函数绘制散点图。scatter(glass.al, glass.ri, c=glass.glass_type)中铝元素作为x轴,折射率作为y轴进行散点图绘制,不同类别glass_type绘制为不同颜色的点(共7个类别)。输出如图15所示,可以看到各种颜色的点。
下面是调用Birch()函数进行聚类处理,主要步骤包括:
- 调用Pandas扩展包的read_csv导入玻璃数据集,注意获取两列数据,需要转换为二维数组X。
- 从sklearn.cluster包中导入Birch()聚类函数,并设置聚类类簇数。
- 调用clf.fit(X, y)函数训练模型。
- 用训练得到的模型进行预测分析,调用predict()函数预测数据集。
- 分别获取三类数据集对应类的点。
- 调用plot()函数绘制散点图,不同类别的数据集设置为不同样式。
完整代码如下:
# -*- coding: utf-8 -*-
# By:Eastmount CSDN 2021-07-03
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.cluster import Birch
#数据获取
glass=pd.read_csv("glass.csv")
X1 = glass.al
X2 = glass.ri
T = dict(zip(X1,X2)) #生成二维数组
X = list(map(lambda x,y: (x,y), T.keys(),T.values())) #dict类型转换为list
y = glass.glass_type
#聚类
clf = Birch(n_clusters=3)
clf.fit(X, y)
y_pred = clf.predict(X)
print(y_pred)
#分别获取不同类别数据点
x1, y1 = [], []
x2, y2 = [], []
x3, y3 = [], []
i = 0
while i < len(X):
if y_pred[i]==0:
x1.append(X[i][0])
y1.append(X[i][1])
elif y_pred[i]==1:
x2.append(X[i][0])
y2.append(X[i][1])
elif y_pred[i]==2:
x3.append(X[i][0])
y3.append(X[i][1])
i = i + 1
#三种颜色 红 绿 蓝,marker='x'表示类型,o表示圆点 *表示星型 x表示点
plot1, = plt.plot(x1, y1, 'or', marker="x")
plot2, = plt.plot(x2, y2, 'og', marker="o")
plot3, = plt.plot(x3, y3, 'ob', marker="*")
plt.xlabel('al')
plt.ylabel('ri')
plt.show()
输出如下图所示:
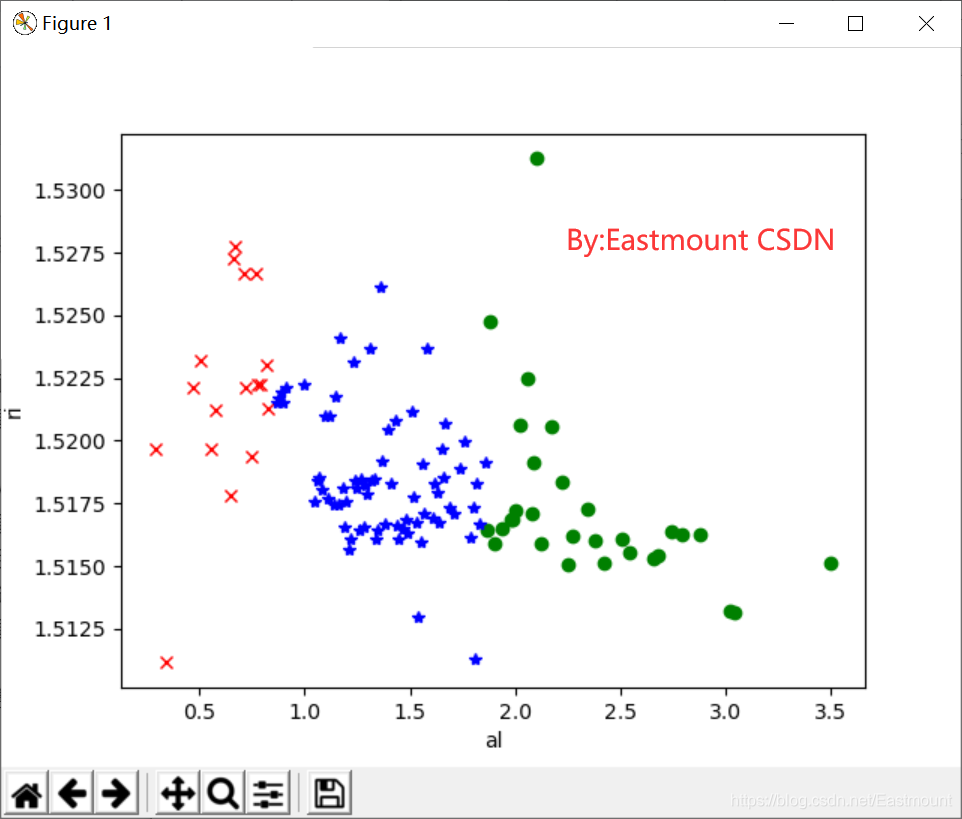
从图中可以看到,右下角红色x形点聚集在一起,其al含量较高、ri含量较低;中间绿色o点聚集在一起,其al、ri含量均匀;右部蓝色*星形点聚集在一起,其al含量较低、ri含量较高。该Birch算法很好的将数据集划分为三部分。
但不知道读者有没有注意到,在代码中获取了两列数据进行聚类,而数据集中包含多个特征,如ri、na、mg、al、si、k、ca、ba、fe等,真正的聚类分析中,是可以对多个特征进行分析的,这就涉及到了降维技术。
任何回归、聚类和分类算法的复杂度都依赖于输入的数量,为了减少存储量和计算时间,我们需要降低问题的维度,丢弃不相关的特征。同时,当数据可以用较少的维度表示而不丢失信息时,我们可以对数据绘图,可视化分析它的结构和离群点,数据降维由此产生。
数据降维(Dimensionality Reduction)是指采用一个低纬度的特征来表示高纬度特征,其本质是构造一个映射函数f:X->Y,其中X是原始数据点,用n维向量表示;Y是数据点映射后的r维向量,并且n>r。通过这种映射方法,可以将高维空间中的数据点降低。
特征降维一般有两类方法:特征选择(Feature Selection)和特征提取(Feature Extraction)。
-
特征选择
特征选择是指从高纬度特征中选择其中的一个子集来作为新的特征。最佳子集表示以最少的维贡献最大的正确率,丢弃不重要的维,使用合适的误差函数产生,特征选择的方法包括在向前选择(Forword Selection)和在向后选择(Backward Selection)。 -
特征提取
特征提取是指将高纬度的特征经过某个函数映射至低纬度作为新的特征。常用的特征抽取方法包括PCA(主成分分析)和LDA(线性判别分析)。图17表示采用PCA方法将三维图形尾花数据降维成两维2D图形。
主成分分析(Principal Component Analysis,简称PCA)是一种常用的线性降维数据分析方法,它是在能尽可能保留具有代表性的原特征数据点的情况下,将原特征进行线性变换,从而映射至低纬度空间中。
PCA降维方法通过正交变换将一组可能存在相关性的变量转换为一组线性不相关的变量,转换后的这组变量叫做主成分,它可以用于提取数据中的主要特征分量,常用于高维数据的降维。该方法的重点在于:能否在各个变量之间相关关系的基础上,用较少的新变量代替原来较多的变量,并且这些较少的新变量尽可能多地反映原来较多的变量所提供信息,又能保证新指标之间信息不重叠。
图18是将二维样本的散点图(红色三角形点)降低成一维直线(黄色圆点)表示。最理想的情况是这个一维新向量所包含的原始数据信息最多,即降维后的直线能尽可能多覆盖二维图形中的点,或者所有点到这条直线的距离和最短,这类似于椭圆长轴,该方向上的离散程度最大、方差最大,所包含的信息最多;而椭圆短轴方向上的数据变化很少,对数据的解释能力较弱。
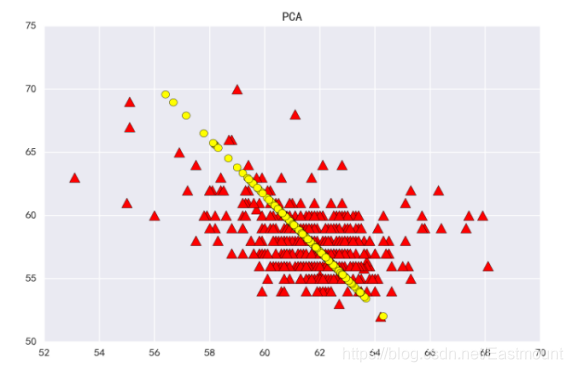
由于作者数学能力有限,该方法的推算过程及原理推荐读者下来自行研究学习,也请读者海涵。
下面介绍Sklearn机器学习包中PCA降维方法的应用。
- 导入扩展包
from sklearn.decomposition import PCA - 调用降维函数
pca = PCA(n_components=2)
其中参数n_components=2表示降低为2维,下述代码是调用PCA降维方法进行降维操作,将一条直线(二维矩阵)X变量降低为一个点并输出。
import numpy as np
from sklearn.decomposition import PCA
X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])
pca = PCA(n_components=2)
print(pca)
pca.fit(X)
print(pca.explained_variance_ratio_)
输出如下所示,包括PCA算法原型及降维成2维的结果。

其结果表示通过PCA降维方法将六个点或一条直线降低成为一个点,并尽可能表征这六个点的特征。输出点为:[0.99244289 0.00755711]。
- 降维操作
pca = PCA(n_components=2)
newData = pca.fit_transform(x)
调用PCA()函数降维,降低成2维数组,并将降维后的数据集赋值给newData变量。下面举一个例子,载入波士顿(Boston)房价数据集,将数据集中的13个特征降低为2个特征。核心代码如下所示:
# -*- coding: utf-8 -*-
# By:Eastmount CSDN 2021-07-03
#载入数据集
from sklearn.datasets import load_boston
d = load_boston()
x = d.data
y = d.target
print(x[:2])
print('形状:', x.shape)
#降维
import numpy as np
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
newData = pca.fit_transform(x)
print('降维后数据:')
print(newData[:4])
print('形状:', newData.shape)
其中,波士顿房价数据集共506行,13个特征,经过PCA算法降维后,降低为两个特征,并调用newData[:4]输出前4行数据,输出结果如下所示。
[[ 6.32000000e-03 1.80000000e+01 2.31000000e+00 0.00000000e+00
5.38000000e-01 6.57500000e+00 6.52000000e+01 4.09000000e+00
1.00000000e+00 2.96000000e+02 1.53000000e+01 3.96900000e+02
4.98000000e+00]
[ 2.73100000e-02 0.00000000e+00 7.07000000e+00 0.00000000e+00
4.69000000e-01 6.42100000e+00 7.89000000e+01 4.96710000e+00
2.00000000e+00 2.42000000e+02 1.78000000e+01 3.96900000e+02
9.14000000e+00]]
形状: (506L, 13L)
降维后数据:
[[-119.81821283 5.56072403]
[-168.88993091 -10.11419701]
[-169.31150637 -14.07855395]
[-190.2305986 -18.29993274]]
形状: (506L, 2L)
前面讲述的Birch聚类算法分析氧化物的数据只抽取了数据集的第一列和第二列数据,接下来讲述对整个数据集的所有特征进行聚类的代码,调用PCA将数据集降低为两维数据,再进行可视化操作,完整代码如下。
# -*- coding: utf-8 -*-
# By:Eastmount CSDN 2021-07-03
#第一步 数据获取
import pandas as pd
glass = pd.read_csv("glass.csv")
print(glass[:4])
#第二步 聚类
from sklearn.cluster import Birch
clf = Birch(n_clusters=3)
clf.fit(glass)
pre = clf.predict(glass)
print(pre)
#第三步 降维
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
newData = pca.fit_transform(glass)
print(newData[:4])
x1 = [n[0] for n in newData]
x2 = [n[1] for n in newData]
#第四步 绘图
import matplotlib.pyplot as plt
plt.xlabel("x feature")
plt.ylabel("y feature")
plt.scatter(x1, x2, c=pre, marker='x')
plt.show()
输出如图19所示。核心代码前面已经详细叙述了,其中[n[0] for n in newData]代码表示获取降维后的第一列数据,[n[1] for n in newData]获取降维后的第二列数据,并分别赋值给x1和x2变量,为最后的绘图做准备。
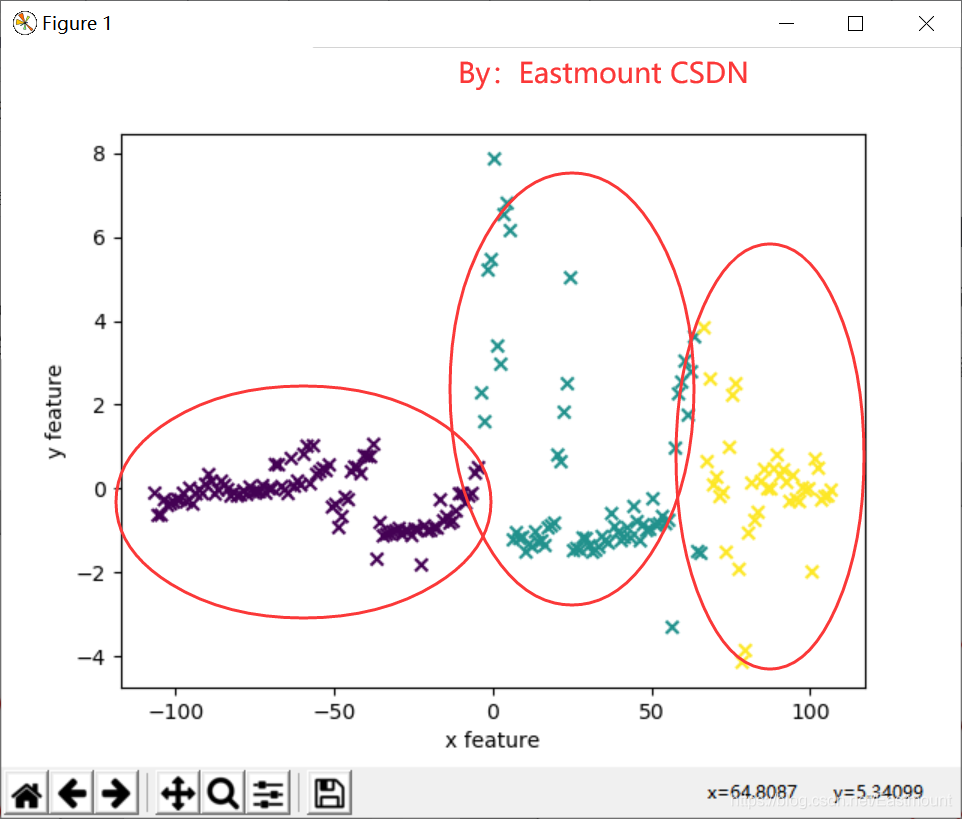
同时,上述代码输出的前4行数据集结果如下:
最后简单讲述设置不同类簇数的聚类对比代码,完整代码如下:
# -*- coding: utf-8 -*-
# By:Eastmount CSDN 2021-07-03
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from sklearn.cluster import Birch
#获取数据集及降维
glass = pd.read_csv("glass.csv")
pca = PCA(n_components=2)
newData = pca.fit_transform(glass)
print(newData[:4])
L1 = [n[0] for n in newData]
L2 = [n[1] for n in newData]
plt.rc('font', family='SimHei', size=8) #设置字体
plt.rcParams['axes.unicode_minus'] = False #负号
#聚类 类簇数=2
clf = Birch(n_clusters=2)
clf.fit(glass)
pre = clf.predict(glass)
p1 = plt.subplot(221)
plt.title(u"Birch聚类 n=2")
plt.scatter(L1,L2,c=pre,marker="s")
plt.sca(p1)
#聚类 类簇数=3
clf = Birch(n_clusters=3)
clf.fit(glass)
pre = clf.predict(glass)
p2 = plt.subplot(222)
plt.title(u"Birch聚类 n=3")
plt.scatter(L1,L2,c=pre,marker="o")
plt.sca(p2)
#聚类 类簇数=4
clf = Birch(n_clusters=4)
clf.fit(glass)
pre = clf.predict(glass)
p3 = plt.subplot(223)
plt.title(u"Birch聚类 n=4")
plt.scatter(L1,L2,c=pre,marker="o")
plt.sca(p3)
#聚类 类簇数=5
clf = Birch(n_clusters=5)
clf.fit(glass)
pre = clf.predict(glass)
p4 = plt.subplot(224)
plt.title(u"Birch聚类 n=5")
plt.scatter(L1,L2,c=pre,marker="s")
plt.sca(p4)
plt.savefig('18.20.png', dpi=300)
plt.show()
输出如图20所示,可以分别看到类簇数为2、3、4、5的聚类对比情况。需要注意的是不同类簇数据点的颜色是不同的,建议读者下来自己去实现该部分代码,从实际数据分析中体会。

前面我看到是针对TXT和CSV文件中的数据,接着我们来看看聚类算法如何应用到图像分割领域。
均值漂移(Mean Shfit)算法是一种通用的聚类算法,最早是1975年Fukunaga等人在一篇关于概率密度梯度函数的估计论文中提出。它是一种无参估计算法,沿着概率梯度的上升方向寻找分布的峰值。Mean Shift算法先算出当前点的偏移均值,移动该点到其偏移均值,然后以此为新的起始点,继续移动,直到满足一定的条件结束。
图像分割中可以利用均值漂移算法的特性,实现彩色图像分割。在OpenCV中提供的函数为pyrMeanShiftFiltering(),该函数严格来说并不是图像分割,而是图像在色彩层面的平滑滤波,它可以中和色彩分布相近的颜色,平滑色彩细节,侵蚀掉面积较小的颜色区域,所以在OpenCV中它的后缀是滤波“Filter”,而不是分割“segment”。该函数原型如下所示:
- dst = pyrMeanShiftFiltering(src, sp, sr[, dst[, maxLevel[, termcrit]]])
– src表示输入图像,8位三通道的彩色图像
– dst表示输出图像,需同输入图像具有相同的大小和类型
– sp表示定义漂移物理空间半径的大小
– sr表示定义漂移色彩空间半径的大小
– maxLevel表示定义金字塔的最大层数
– termcrit表示定义的漂移迭代终止条件,可以设置为迭代次数满足终止,迭代目标与中心点偏差满足终止,或者两者的结合
均值漂移pyrMeanShiftFiltering()函数的执行过程是如下:
-
(1) 构建迭代空间。
以输入图像上任一点P0为圆心,建立以sp为物理空间半径,sr为色彩空间半径的球形空间,物理空间上坐标为x和y,色彩空间上坐标为RGB或HSV,构成一个空间球体。其中x和y表示图像的长和宽,色彩空间R、G、B在0至255之间。 -
(2) 求迭代空间的向量并移动迭代空间球体重新计算向量,直至收敛。
在上一步构建的球形空间中,求出所有点相对于中心点的色彩向量之和,移动迭代空间的中心点到该向量的终点,并再次计算该球形空间中所有点的向量之和,如此迭代,直到在最后一个空间球体中所求得向量和的终点就是该空间球体的中心点Pn,迭代结束。 -
(3) 更新输出图像dst上对应的初始原点P0的色彩值为本轮迭代的终点Pn的色彩值,完成一个点的色彩均值漂移。
-
(4) 对输入图像src上其他点,依次执行上述三个步骤,直至遍历完所有点后,整个均值偏移色彩滤波完成。
下面的代码是图像均值漂移的实现过程:
# -*- coding: utf-8 -*-
# By:Eastmount CSDN 2021-07-03
import cv2
import numpy as np
import matplotlib.pyplot as plt
#读取原始图像灰度颜色
img = cv2.imread('scenery.png')
spatialRad = 100 #空间窗口大小
colorRad = 100 #色彩窗口大小
maxPyrLevel = 2 #金字塔层数
#图像均值漂移分割
dst = cv2.pyrMeanShiftFiltering( img, spatialRad, colorRad, maxPyrLevel)
#显示图像
cv2.imshow('src', img)
cv2.imshow('dst', dst)
cv2.waitKey()
cv2.destroyAllWindows()
当漂移物理空间半径设置为50,漂移色彩空间半径设置为50,金字塔层数 为2,输出的效果图如图21所示。
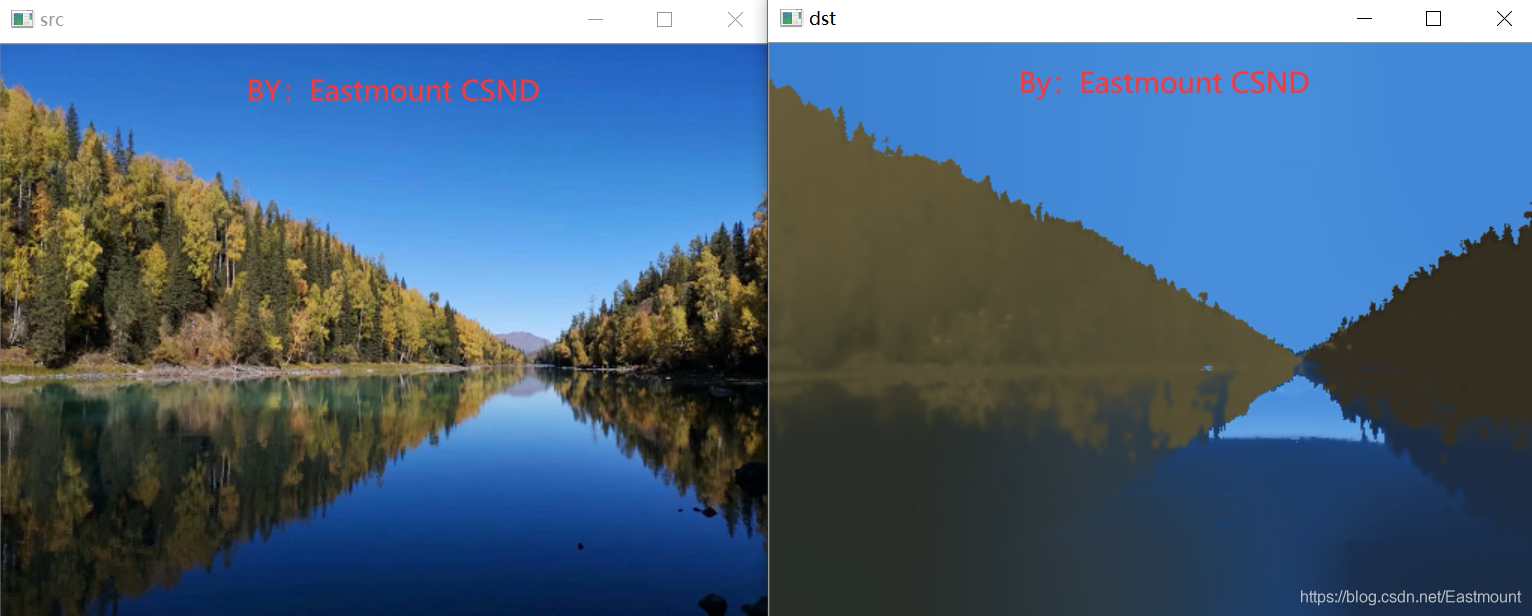
当漂移物理空间半径设置为20,漂移色彩空间半径设置为20,金字塔层数为2,输出的效果图如图22所示。对比可以发现,半径为20时,图像色彩细节大部分存在,半径为50时,森林和水面的色彩细节基本都已经丢失。
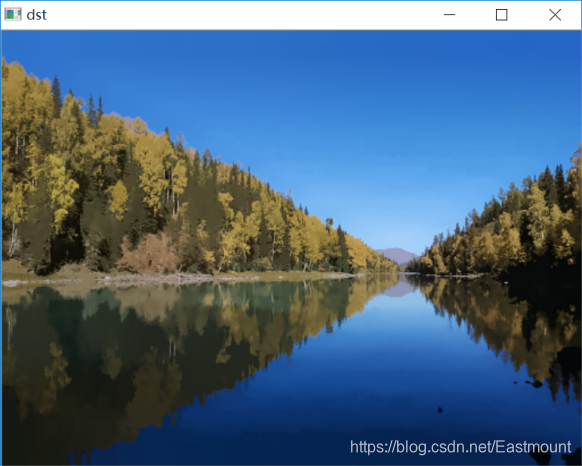
写到这里,均值偏移算法对彩色图像的分割平滑操作就完成了,为了达到更好地分割目的,借助漫水填充函数进行下一步处理。完整代码如下所示:
# -*- coding: utf-8 -*-
# By:Eastmount CSDN 2021-07-03
import cv2
import numpy as np
import matplotlib.pyplot as plt
#读取原始图像灰度颜色
img = cv2.imread('scenery.png')
#获取图像行和列
rows, cols = img.shape[:2]
#mask必须行和列都加2且必须为uint8单通道阵列
mask = np.zeros([rows+2, cols+2], np.uint8)
spatialRad = 100 #空间窗口大小
colorRad = 100 #色彩窗口大小
maxPyrLevel = 2 #金字塔层数
#图像均值漂移分割
dst = cv2.pyrMeanShiftFiltering( img, spatialRad, colorRad, maxPyrLevel)
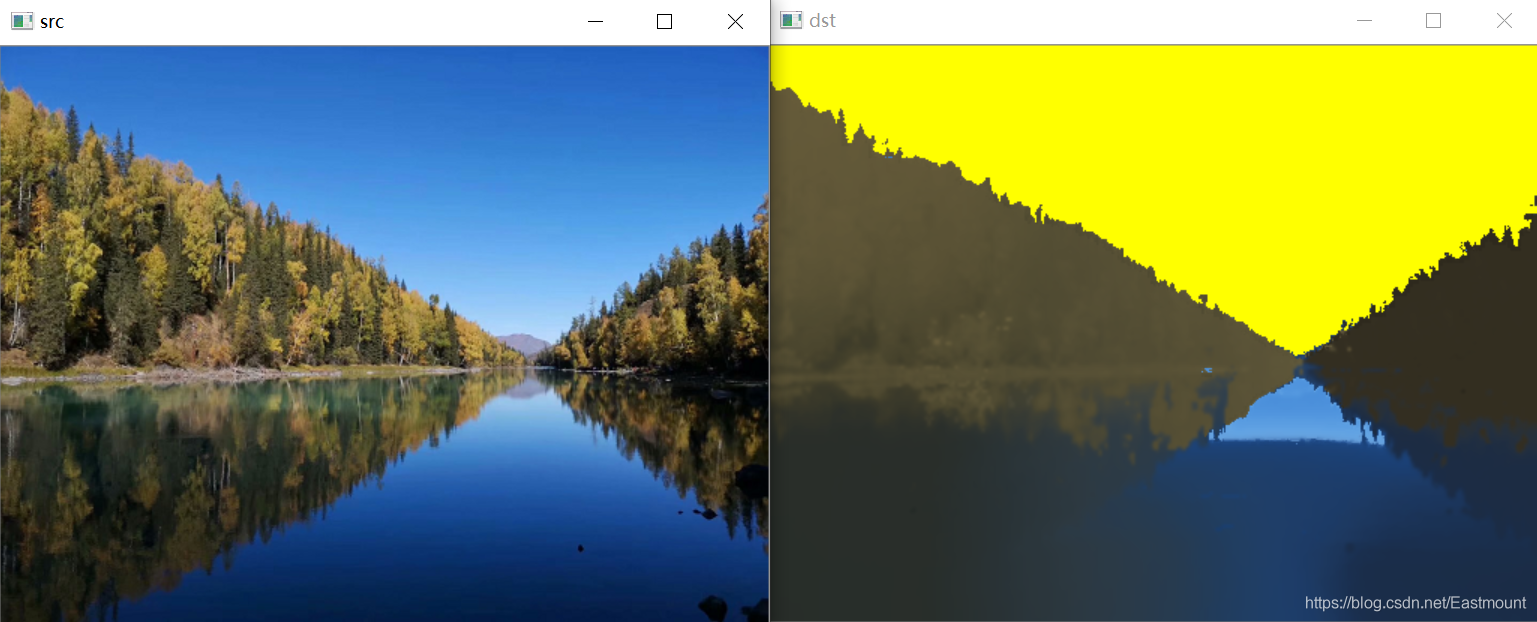
#图像漫水填充处理
cv2.floodFill(dst, mask, (30, 30), (0, 255, 255),
(100, 100, 100), (50, 50, 50),
cv2.FLOODFILL_FIXED_RANGE)
#显示图像
cv2.imshow('src', img)
cv2.imshow('dst', dst)
cv2.waitKey()
cv2.destroyAllWindows()
输出的效果图如图23所示,它将天空染成黄色。
同样,K-Means算法也能实现图像分割。在图像处理中,通过K-Means聚类算法可以实现图像分割、图像聚类、图像识别等操作,本小节主要用来进行图像颜色分割。假设存在一张100×100像素的灰度图像,它由10000个RGB灰度级组成,我们通过K-Means可以将这些像素点聚类成K个簇,然后使用每个簇内的质心点来替换簇内所有的像素点,这样就能实现在不改变分辨率的情况下量化压缩图像颜色,实现图像颜色层级分割。
在OpenCV中,Kmeans()函数原型如下所示:
- retval, bestLabels, centers = kmeans(data, K, bestLabels, criteria, attempts, flags[, centers])
– data表示聚类数据,最好是np.flloat32类型的N维点集
– K表示聚类类簇数
– bestLabels表示输出的整数数组,用于存储每个样本的聚类标签索引
– criteria表示算法终止条件,即最大迭代次数或所需精度。在某些迭代中,一旦每个簇中心的移动小于criteria.epsilon,算法就会停止
– attempts表示重复试验kmeans算法的次数,算法返回产生最佳紧凑性的标签
– flags表示初始中心的选择,两种方法是cv2.KMEANS_PP_CENTERS ;和cv2.KMEANS_RANDOM_CENTERS
– centers表示集群中心的输出矩阵,每个集群中心为一行数据
下面使用该方法对灰度图像颜色进行分割处理,需要注意,在进行K-Means聚类操作之前,需要将RGB像素点转换为一维的数组,再将各形式的颜色聚集在一起,形成最终的颜色分割。
# -*- coding: utf-8 -*-
# By:Eastmount CSDN 2021-07-03
import cv2
import numpy as np
import matplotlib.pyplot as plt
#读取原始图像灰度颜色
img = cv2.imread('scenery.png', 0)
print(img.shape)
#获取图像高度、宽度和深度
rows, cols = img.shape[:]
#图像二维像素转换为一维
data = img.reshape((rows * cols, 1))
data = np.float32(data)
#定义中心 (type,max_iter,epsilon)
criteria = (cv2.TERM_CRITERIA_EPS +
cv2.TERM_CRITERIA_MAX_ITER, 10, 1.0)
#设置标签
flags = cv2.KMEANS_RANDOM_CENTERS
#K-Means聚类 聚集成4类
compactness, labels, centers = cv2.kmeans(data, 4, None, criteria, 10, flags)
#生成最终图像
dst = labels.reshape((img.shape[0], img.shape[1]))
#用来正常显示中文标签
plt.rcParams['font.sans-serif']=['SimHei']
#显示图像
titles = [u'原始图像', u'聚类图像']
images = [img, dst]
for i in range(2):
plt.subplot(1,2,i+1), plt.imshow(images[i], 'gray'),
plt.title(titles[i])
plt.xticks([]),plt.yticks([])
plt.show()
输出结果如图24所示,左边为灰度图像,右边为K-Means聚类后的图像,它将灰度级聚集成四个层级,相似的颜色或区域聚集在一起。

下面代码是对彩色图像进行颜色分割处理,它将彩色图像聚集成2类、4类和64类。
# -*- coding: utf-8 -*-
# By:Eastmount CSDN 2021-07-03
import cv2
import numpy as np
import matplotlib.pyplot as plt
#读取原始图像
img = cv2.imread('scenery.png')
print(img.shape)
#图像二维像素转换为一维
data = img.reshape((-1,3))
data = np.float32(data)
#定义中心 (type,max_iter,epsilon)
criteria = (cv2.TERM_CRITERIA_EPS +
cv2.TERM_CRITERIA_MAX_ITER, 10, 1.0)
#设置标签
flags = cv2.KMEANS_RANDOM_CENTERS
#K-Means聚类 聚集成2类
compactness, labels2, centers2 = cv2.kmeans(data, 2, None, criteria, 10, flags)
#K-Means聚类 聚集成4类
compactness, labels4, centers4 = cv2.kmeans(data, 4, None, criteria, 10, flags)
#K-Means聚类 聚集成8类
compactness, labels8, centers8 = cv2.kmeans(data, 8, None, criteria, 10, flags)
#K-Means聚类 聚集成16类
compactness, labels16, centers16 = cv2.kmeans(data, 16, None, criteria, 10, flags)
#K-Means聚类 聚集成64类
compactness, labels64, centers64 = cv2.kmeans(data, 64, None, criteria, 10, flags)
#图像转换回uint8二维类型
centers2 = np.uint8(centers2)
res = centers2[labels2.flatten()]
dst2 = res.reshape((img.shape))
centers4 = np.uint8(centers4)
res = centers4[labels4.flatten()]
dst4 = res.reshape((img.shape))
centers8 = np.uint8(centers8)
res = centers8[labels8.flatten()]
dst8 = res.reshape((img.shape))
centers16 = np.uint8(centers16)
res = centers16[labels16.flatten()]
dst16 = res.reshape((img.shape))
centers64 = np.uint8(centers64)
res = centers64[labels64.flatten()]
dst64 = res.reshape((img.shape))
#图像转换为RGB显示
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
dst2 = cv2.cvtColor(dst2, cv2.COLOR_BGR2RGB)
dst4 = cv2.cvtColor(dst4, cv2.COLOR_BGR2RGB)
dst8 = cv2.cvtColor(dst8, cv2.COLOR_BGR2RGB)
dst16 = cv2.cvtColor(dst16, cv2.COLOR_BGR2RGB)
dst64 = cv2.cvtColor(dst64, cv2.COLOR_BGR2RGB)
#用来正常显示中文标签
plt.rcParams['font.sans-serif']=['SimHei']
#显示图像
titles = [u'原始图像', u'聚类图像 K=2', u'聚类图像 K=4',
u'聚类图像 K=8', u'聚类图像 K=16', u'聚类图像 K=64']
images = [img, dst2, dst4, dst8, dst16, dst64]
for i in range(6):
plt.subplot(2,3,i+1), plt.imshow(images[i], 'gray'),
plt.title(titles[i])
plt.xticks([]),plt.yticks([])
plt.show()
输出结果如图10所示,它对比了原始图像和各K-Means聚类处理后的图像。当K=2时,聚集成2种颜色;当K=4时,聚集成4种颜色;当K=8时,聚集成8种颜色;当K=16时,聚集成16种颜色;当K=64时,聚集成64种颜色。

更多图像处理知识推荐作者的专栏:
最后我们简单补充文本聚类相关知识,这里以树状图为例,后面的文本挖掘系列也会进行详细介绍。层次聚类绘制的树状图,也是文本挖掘领域常用的技术,它会将各个领域相关的主题以树状的形式进行显示。数据集为作者在CSDN近十年分享的所有博客标题,如下图所示。
最终输出结果如下图所示,可以看到这个内容分为不同的主题,包括网络安全、人工智能、图像处理、算法等。
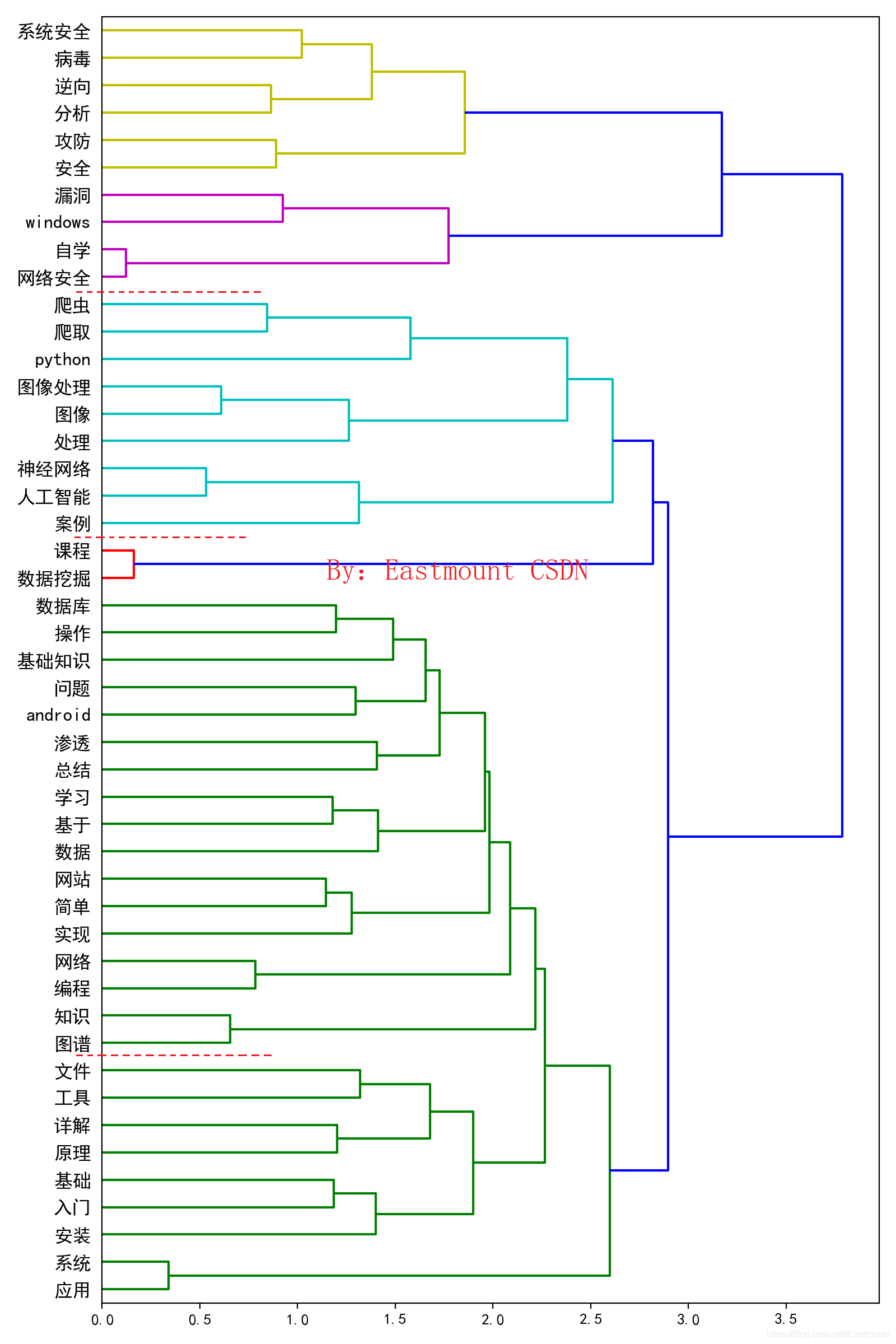
注意,这里作者可以通过设置过滤来显示树状图显示的主题词数量,并进行相关的对比实验,找到最优结果。
# -*- coding: utf-8 -*-
# By:Eastmount CSDN 2021-07-03
import os
import codecs
from sklearn.feature_extraction.text import CountVectorizer, TfidfTransformer
from sklearn.manifold import TSNE
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import jieba
from sklearn import metrics
from sklearn.metrics import silhouette_score
from array import array
from numpy import *
from pylab import mpl
from sklearn.metrics.pairwise import cosine_similarity
import matplotlib.pyplot as plt
import matplotlib as mpl
from scipy.cluster.hierarchy import ward, dendrogram
#---------------------------------------加载语料-------------------------------------
text = open('data-fenci.txt').read()
print(text)
list1=text.split("\n")
print(list1)
print(list1[0])
print(list1[1])
mytext_list=list1
#控制显示数量
count_vec = CountVectorizer(min_df=20, max_df=1000) #最大值忽略
xx1 = count_vec.fit_transform(list1).toarray()
word=count_vec.get_feature_names()
print("word feature length: {}".format(len(word)))
print(word)
print(xx1)
print(type(xx1))
print(xx1.shape)
print(xx1[0])
#---------------------------------------层次聚类-------------------------------------
titles = word
#dist = cosine_similarity(xx1)
mpl.rcParams['font.sans-serif'] = ['SimHei']
df = pd.DataFrame(xx1)
print(df.corr())
print(df.corr('spearman'))
print(df.corr('kendall'))
dist = df.corr()
print (dist)
print(type(dist))
print(dist.shape)
#define the linkage_matrix using ward clustering pre-computed distances
linkage_matrix = ward(dist)
fig, ax = plt.subplots(figsize=(8, 12)) # set size
ax = dendrogram(linkage_matrix, orientation="right",
p=20, labels=titles, leaf_font_size=12
) #leaf_rotation=90., leaf_font_size=12.
#show plot with tight layout
plt.tight_layout()
#save figure as ward_clusters
plt.savefig('KH.png', dpi=200)
plt.show()
写到这里,这篇文章就结束了,您是否对聚类有更好的认识呢?
聚类是把一堆数据归为若干类,同一类数据具有某些相似性,并且这些类别是通过数据自发的聚集出来的,而不是事先给定的,也不需要标记结果,机器学习里面称之为无监督学习,常见的聚类方法包括KMeans、Birch、谱聚类、图聚类等。聚类被广泛应用于不同场景中,社交网络通过聚类来发现人群,关注人群的喜好;网页通过聚类来查找相似文本内容;图像通过聚类来进行分割和检索相似图片;电商通过用户聚类来分析购物的人群、商品推荐以及计算购物最佳时间等。
- 一.聚类
1.算法模型
2.常见聚类算法
3.性能评估 - 二.K-Means
1.算法描述
2.K-Means聚类示例
3.Sklearn中K-Means用法介绍
4.K-Means分析篮球数据
5.K-Means聚类优化
6.设置类簇中心 - 三.Birch
1.算法描述
2.Birch分析氧化物数据 - 四.结合降维处理的聚类分析
1.PCA降维
2.Sklearn PCA降维
3.PCA降维实例 - 五.基于均值漂移的图像聚类
1.MeanShift图像聚类
2.K-Means图像聚类 - 六.基于文本的树状关键词聚类
- 七.总结
最后希望读者能复现每一行代码,只有实践才能进步。同时更多聚类算法和原理知识,希望读者下来自行深入学习研究,也推荐大家结合Sklearn官网和开源网站学习更多的机器学习知识。
该系列所有代码下载地址:
感谢在求学路上的同行者,不负遇见,勿忘初心。这周的留言感慨~
感恩能与大家在华为云遇见!
希望能与大家一起在华为云社区共同成长,原文地址:https://blog.csdn.net/Eastmount/article/details/118518130
【百变AI秀】有奖征文火热进行中:https://bbs.huaweicloud.com/blogs/29670
(By:娜璋之家 Eastmount 2021-08-27 夜于贵阳)
参考文献:
- [1] 杨秀璋. 专栏:知识图谱、web数据挖掘及NLP - CSDN博客[EB/OL]. (2016-09-19)[2017-11-07]. http://blog.csdn.net/column/details/eastmount-kgdmnlp.html.
- [2] 张良均,王路,谭立云,苏剑林. Python数据分析与挖掘实战[M]. 北京:机械工业出版社,2016.
- [3] (美)Wes McKinney著. 唐学韬等译. 利用Python进行数据分析[M]. 北京:机械工业出版社,2013.
- [4] Jiawei Han,Micheline Kamber著. 范明,孟小峰译. 数据挖掘概念与技术. 北京:机械工业出版社,2007.
- [5] 杨秀璋. [Python数据挖掘课程] 二.Kmeans聚类数据分析及Anaconda介绍[EB/OL]. (2016-10-10)[2017-11-17]. http://blog.csdn.net/eastmount/article/details/52777308.
- [6] 杨秀璋. [Python数据挖掘课程] 三.Kmeans聚类代码实现、作业及优化[EB/OL]. (2016-10-12)[2017-11-17]. http://blog.csdn.net/eastmount/article/details/52793549.
- [7] 杨秀璋. [Python数据挖掘课程] 七.PCA降维操作及subplot子图绘制[EB/OL]. (2016-11-26)[2017-11-17]. http://blog.csdn.net/eastmount/article/details/53285192
- [8] scikit-learn官网. scikit-learn clusterin [EB/OL]. (2017)[2017-11-17]. http://scikit-learn.org/stable/modules/clustering.html#clustering.
- [9] KEEL数据集. KEEL-dateset Basketball dataset[EB/OL]. (2017)[2017-11-17]. http://sci2s.ugr.es/keel/dataset.php?cod=1293.
- [10] UCI官网. 玻璃数据集(Glass Identification Database)[EB\OL]. (2017)[2017-11-17]. http://archive.ics.uci.edu/ml/machine-learning-databases/glass/.

- 点赞
- 收藏
- 关注作者
评论(0)