RDKit | 化合物描述符向量化及部分结构检索

【摘要】 numpy的vectorization
arrays很重要因为它提供了可以批处理数据而不需要写任何for循环,叫做vectorization;
化合物描述符向量化及相似性检索
导入库
import pandas as pdfrom numpy import vectorize as vecfrom rdkit import Chemfrom rdkit...
numpy的vectorization
arrays很重要因为它提供了可以批处理数据而不需要写任何for循环,叫做vectorization;
化合物描述符向量化及相似性检索
导入库
-
import pandas as pd
-
from numpy import vectorize as vec
-
from rdkit import Chem
-
from rdkit.Chem.Draw import IPythonConsole
-
from rdkit.Chem import Descriptors,PandasTools
-
from rdkit.Chem.AllChem import Compute2DCoords
载入数据并查看
-
mols = PandasTools.LoadSDF("cdk2.sdf",smilesName='SMILES',molColName='Molecule',includeFingerprints=True)
-
mols.head()
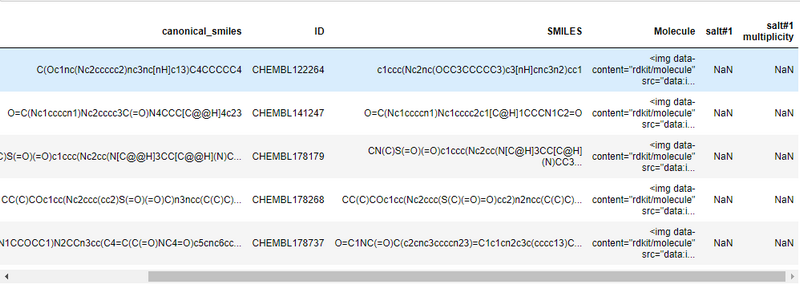
可
文章来源: drugai.blog.csdn.net,作者:DrugAI,版权归原作者所有,如需转载,请联系作者。
原文链接:drugai.blog.csdn.net/article/details/103859434

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)