

R语言之数值型描述分析

【摘要】 文章和代码已经归档至【Github仓库:https://github.com/timerring/dive-into-AI 】或者公众号【AIShareLab】回复 R语言 也可获取。在分析之前,先将数据集 birthwt 中的分类变量 low、race、smoke、ht 和 ui 转换成因子。library(MASS)data(birthwt)str(birthwt)options(war...
文章和代码已经归档至【Github仓库:https://github.com/timerring/dive-into-AI 】或者公众号【AIShareLab】回复 R语言 也可获取。
在分析之前,先将数据集 birthwt 中的分类变量 low、race、smoke、ht 和 ui 转换成因子。
library(MASS)
data(birthwt)
str(birthwt)
options(warn=-1)
library(dplyr)
birthwt <- birthwt %>%
mutate(low = factor(low, labels = c("no", "yes")),
race = factor(race, labels = c("white", "black", "other")),
smoke = factor(smoke, labels = c("no", "yes")),
ht = factor(ht, labels = c("no", "yes")),
ui = factor(ui, labels = c("no", "yes")))
str(birthwt)
获取数据框里每个变量的常用统计量是一种快速探索数据集的方法,这可以通过下面的一个命令实现。
summary(birthwt)
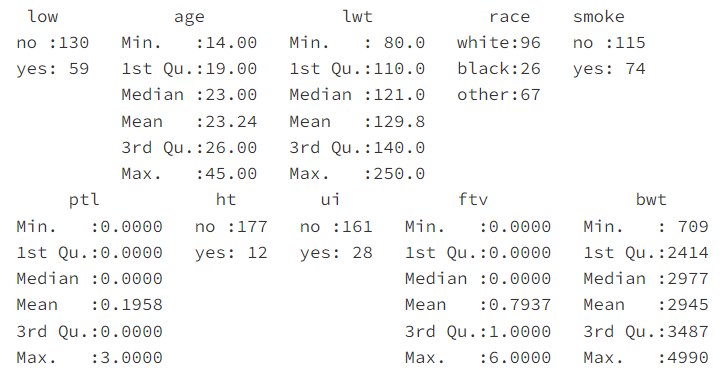
函数 summary( )可以对每个变量进行汇总统计。对于数值型变量,如 age、lwt、plt、ftv 和 bwt,函数 summary( )给出最小值、下四分位数、中位数、均值、上四分位数和最大值;对于分类变量,如 low、race、smoke、ht 和 ui,给出的则是频数统计表。
epiDisplay 包的函数 summ( )作用于数据框可以得到另一种格式的汇总输出,它将变量按行排列,把最小值和最大值放在最后两列以方便查看数据的全距。
library(epiDisplay)
summ(birthwt)
需要注意的是,对于因子型的变量,函数 summ( )把变量的各个水平当作数值计算统计量。
数值型变量的描述性统计分析
本节将讨论数值型变量的集中趋势、离散程度和分布形状等。这里我们关注 3 个连续型变量:年龄(age)、母亲怀孕前体重(lwt)和婴儿出生时体重(bwt)。
cont.vars <- dplyr::select(birthwt, age, lwt, bwt)
接下来,先计算这 3 个变量的描述性统计量,然后按照母亲吸烟情况(smoke)分组考查描述性统计量。这里 smoke 是一个二分类变量,我们在把它转换成因子时已经为其两个水平定义了标签:“no”和“yes”。
除了上面提到的函数 summary( ),R 中还有很多用于计算特定统计量的函数(见第二章)。例如,计算变量 age 的样本量、样本均值和样本标准差:
length(cont.vars$age)
mean(cont.vars$age)
sd(cont.vars$age)
我们还可以用函数 sapply( )同时计算数据框中多个变量的指定统计量。例如,计算数据框 cont.vars 中各个变量的样本标准差:
sapply(cont.vars, sd)
基本包中没有提供计算偏度和峰度的函数,我们可以根据公式自己计算,也可以调用其他包里的函数计算,例如 Hmisc 包、psych 包和 pstecs 包等。这些包提供了种类繁多的计算统计量的函数,这几个包在首次使用前需要先安装。下面以 psych 包为例进行说明。psych 包被广泛应用于计量心理学。
psych 包里的函数 describe( )可以计算变量忽略缺失值后的样本量、均值、标准差、中位数、截尾均值、绝对中位差、最小值、最大值、全距、偏度、峰度和均值的标准误等。
例如:
R.Version()
library(psych)
describe(cont.vars)
在很多时候我们还想计算某个分类变量各个类别下的统计量。在 R 中完成这个任务有多种方式,下面先从基本包的函数 aggregate( )和 tapply( )开始介绍。
aggregate(cont.vars, by = list(smoke = birthwt$smoke), mean)
aggregate(cont.vars, by = list(smoke = birthwt$smoke), sd)
函数 aggregate( )中的参数 by 必须设为 list。如果直接使用 list(birthwt$smoke),则上面分组列的名称将会是“Group.1”而不是“smoke”。我们还可以在 list 里面设置多个分类变量,例如:
aggregate(cont.vars,
by = list(smoke = birthwt$smoke, race = birthwt$race),
mean)
这里的分类变量有 2 个,其中 smoke 有 2 个类别,race 有 3 个类别,上面的命令按照这两个变量各类别的所有组合(共 6 组)计算均值。
当然,你也可以使用下面任一方式写:
aggregate(birthwt[,c("age","lwt","bwt")],
by = list(smoke = birthwt$smoke, race = birthwt$race),
mean)
aggregate(cbind(age, lwt, bwt)~smoke+race, birthwt, mean)
函数 tapply( )可以实现类似的功能,不同的是它的第一个参数必须是一个变量,第二个参数名是 INDEX 而不是 by。例如,计算变量 bwt 在母亲不同吸烟情况下的均值,可以输入:
tapply(birthwt$bwt, INDEX = birthwt$smoke, mean)
# no 3055.69565217391 yes 2771.91891891892
epiDisplay 包里的函数 summ( )也可以实现类似的功能,不同的是该函数里的统计量是固定的,而且函数的输出包含一个按照分类变量绘制的有序点图,如下图所示。
summ(birthwt$bwt, by = birthwt$smoke)
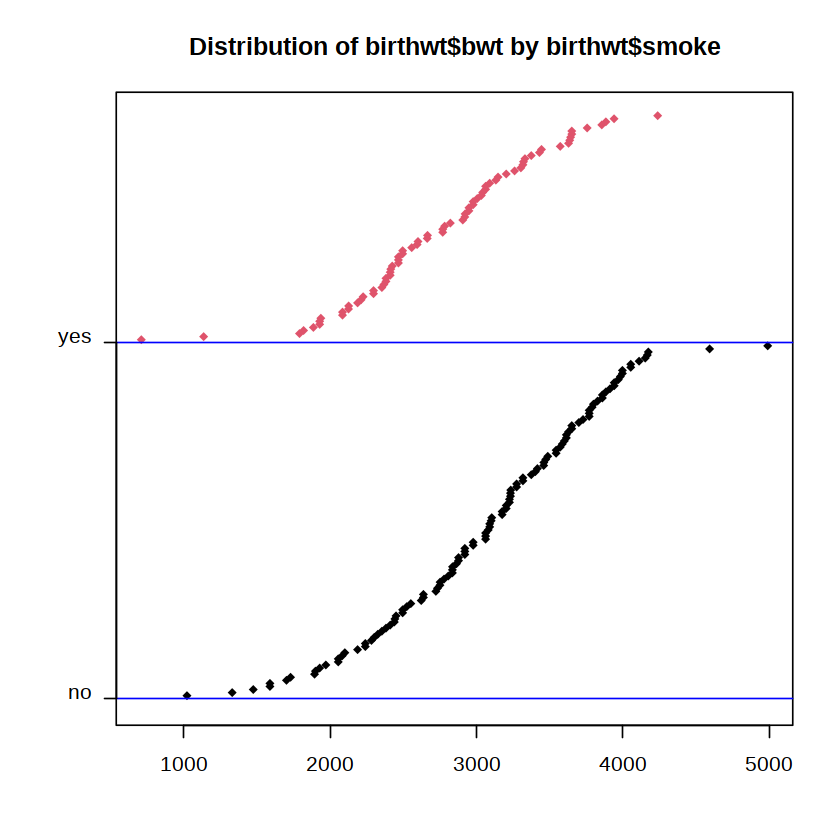
用函数 summ( )输出的有序点图探索数值型变量的分布尤其是数据的密集趋势和异常值非常方便。
psych 包里的函数 describeBy( )也可以分组计算与函数 describe( )相同的统计量,例如:
describeBy(cont.vars, birthwt$smoke)
函数 describeBy( )虽然很方便,但它不能指定任意函数,所以扩展性较差。实际上,在第 3 章介绍的 dplyr 包里的函数 group_by( )和 summarise( )就能非常灵活地计算分组统计量。例如:
library(dplyr)
birthwt %>%
group_by(smoke) %>%
summarise(Mean.bwt = mean(bwt), Sd.bwt = sd(bwt))
数据分析者可以选择自己最习惯的方式计算和展示描述性统计量。最后一种方式的思路最清晰,结果最简洁。
【版权声明】本文为华为云社区用户原创内容,未经允许不得转载,如需转载请自行联系原作者进行授权。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com

- 点赞
- 收藏
- 关注作者
作者其他文章










评论(0)