Langchain and RAG Best Practices

This is a quick-start essay for LangChain and RAG which mainly refers to the Langchain chat with your data course which are taught by Harrison Chase and Andrew Ng.
You can check the entire code in the rag101 repository. This article is also posted on my blog, feel free to check it.
LangChain and RAG best practices
Introduction
LangChain
LangChain is an Open-source developer framework for building LLM applications.
It components are as below:
Prompt
- Prompt Templates: used for generating model input.
- Output Parsers: implementations for processing generated results.
- Example Selectors: selecting appropriate input examples.
Models
- LLMs
- Chat Models
- Text Embedding Models
Indexes
- Document Loaders
- Text Splitters
- Vector Stores
- Retrievers
Chains
- Can be used as a building block for other chains.
- Provides over 20 types of application-specific chains.
Agents
- Supports 5 types of agents to help language models use external tools.
- Agent Toolkits: provides over 10 implementations, agents execute tasks through specific tools.
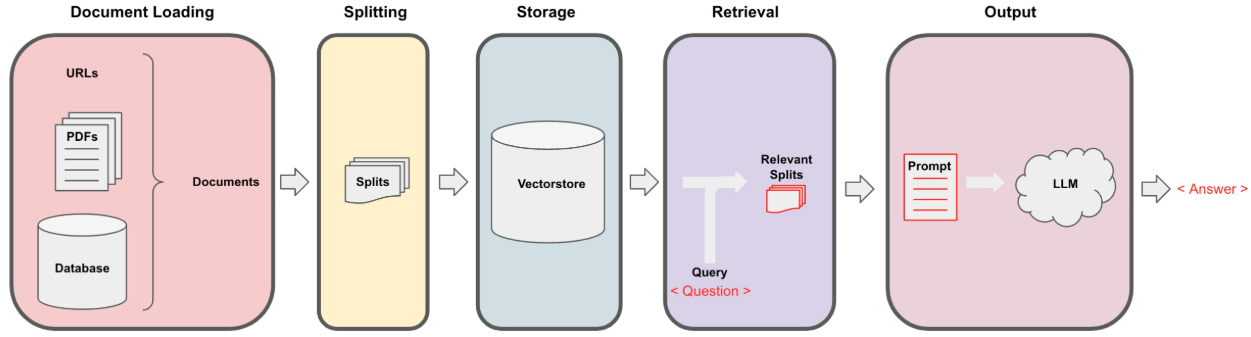
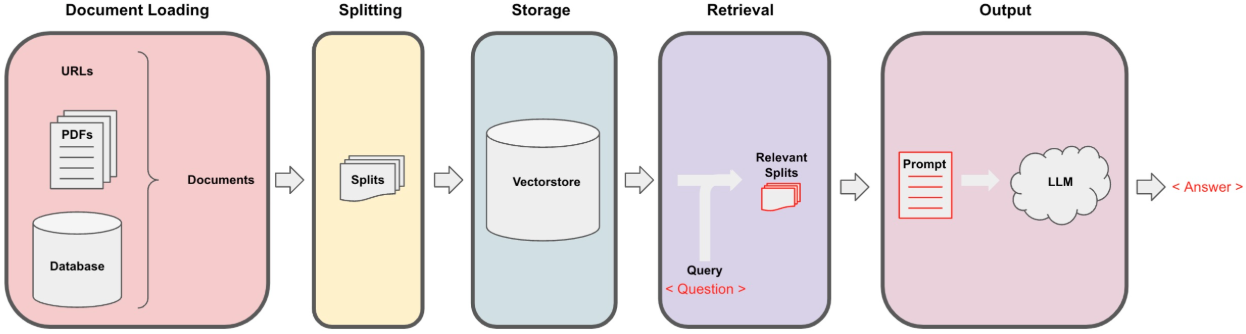
RAG process
The whole RAG process lays on the Vector Store Loading and Retrieval-Augmented Generation.
Vector Store Loading
Load the data from different sources, split and convert them into vector embeddings.
Retrieval-Augmented Generation
- After the user’s input Query, the system will retrieve the most relevant document fragments (Relevant Splits) from the vector store.
- The retrieved relevant fragments will be combined into a Prompt, which will be passed along with the context to the large language model (LLM).
- Finally, the language model will generate an answer based on the retrieved fragments and return it to the user.

Loaders
You can use loaders to deal with different kind and format of data.
Some are public and some are proprietary. Some are structured and some are not.
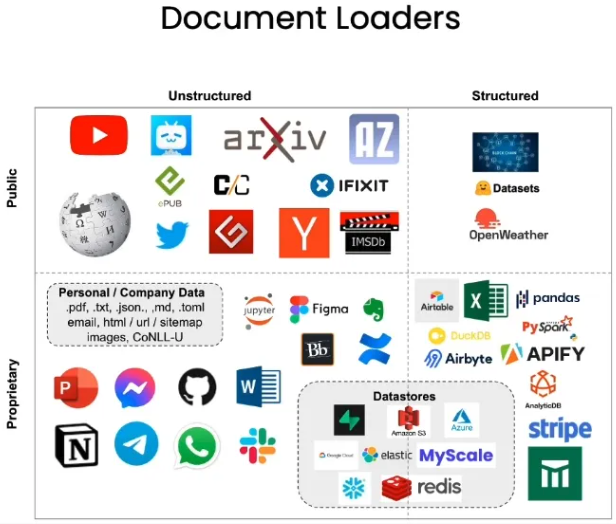
Some useful lib:
- pdf: pypdf
- youtube audio: yt_dlp pydub
- web page: beautifulsoup4
For more loaders, you can check the official docs.
You can check the entire code here.
Now, we can practice:
First, install the lib:
pip install langchain-community
pip install pypdf
You can check the demo in the
from langchain.document_loaders import PyPDFLoader
# In fact, the langchain calls the pypdf lib to load the pdf file
loader = PyPDFLoader("ProbRandProc_Notes2004_JWBerkeley.pdf")
pages = loader.load()
print(type(pages))
# <class 'list'>
print(len(pages))
# Print the total num of pages
# Using the first page as an example
page = pages[0]
print(type(page))
# <class 'langchain_core.documents.base.Document'>
# What is inside the page:
# 1. page_content
# 2. meta_data: the description of the page
print(page.page_content[0:500])
print(page.metadata)
Web Base Loader
Also we install the lib first:
pip install beautifulsoup4
The WebBaseLoader is based on the beautifulsoup4 lib.
from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader("https://zh.d2l.ai/")
pages = loader.load()
print(pages[0].page_content[:500])
# You can also use json as the post processing
# import json
# convert_to_json = json.loads(pages[0].page_content)
Splitters
Splitting Documents into smaller chunks. Retaining the meaningful relationships.
Why split?
- The limitation of GPU: the GPT model with more than 1B parameters. The forward propagation cannot process such a large parameters. So the split is necessary.
- More efficient computation.
- Some fixed size of sequence.
- Better generalization.
However, the split points may lose some information. So we split should consider the semantic.
Type of splitters
- CharacterTextSplitter
- MarkdownHeaderTextSplitter
- TokenTextsplitter
- SentenceTransformersTokenTextSplitter
- RecursiveCharacterTextSplitter: Recursively tries to split by different characters to find one that works.
- Language: for CPP, Python, Ruby, Markdown etc
- NLTKTextSplitter: sentences using NLTK(Natural Language Tool Kit)
- SpacyTextSplitter: sentences using Spacy
For more, check the docs.
Example CharacterTextSplitter and RecursiveCharacterTextSplitter
You can check the entire code here.
from langchain.text_splitter import RecursiveCharacterTextSplitter, CharacterTextSplitter
example_text = """When writing documents, writers will use document structure to group content. \
This can convey to the reader, which idea's are related. For example, closely related ideas \
are in sentances. Similar ideas are in paragraphs. Paragraphs form a document. \n\n \
Paragraphs are often delimited with a carriage return or two carriage returns. \
Carriage returns are the "backslash n" you see embedded in this string. \
Sentences have a period at the end, but also, have a space.\
and words are separated by space."""
c_splitter = CharacterTextSplitter(
chunk_size=450, # the size of the chunk
chunk_overlap=0, # the overlap of the chunk, which can be shared with the previous chunk
separator = ' '
)
r_splitter = RecursiveCharacterTextSplitter(
chunk_size=450,
chunk_overlap=0,
separators=["\n\n", "\n", " ", ""] # priority of the separators
)
print(c_splitter.split_text(example_text))
# split at 450 characters
print(r_splitter.split_text(example_text))
# split at first \n\n
Vectorstores and Embeddings
Review the RAG process:
Benefits:
- Improve the accuracy of the query. When query the similar chunks, the accuracy will be higher.
- Improve the efficiency of the query. Minimize the computation when query the similar chunks.
- Improve the coverage of the query. The chunks can cover every point of the document.
- Facilitate the Embeddings.
Embeddings
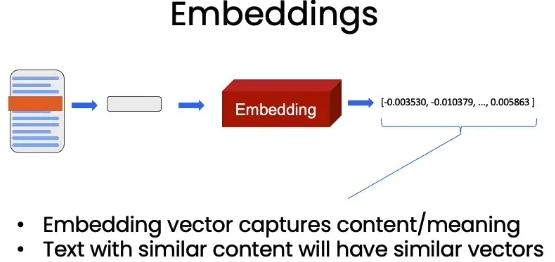
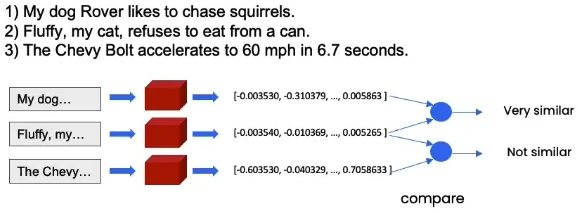
If two sentences have similar meanings, then they will be closer in the high-dimensional semantic space.
Vector Stores
Store every chunk in a vector store. When customer query, the query will be embedded and then find the most similar vectors which means the index of these chunks, and then return the chunks.
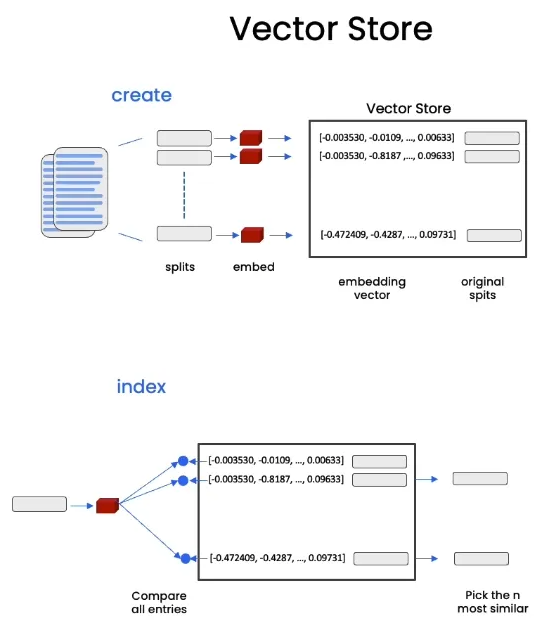
Practice
Embeddings
You can check the entire code here.
First, install the lib:
The chromadb is a lightweight vector database.
pip install chromadb
What we need is a good embedding model, you can select what you like. Refer to the docs.
Here I use the ZhipuAIEmbeddings. So you should install the lib:
pip install zhipuai
Here is the test code:
from langchain_community.embeddings import ZhipuAIEmbeddings
embed = ZhipuAIEmbeddings(
model="embedding-3",
api_key="Entry your own api key"
)
input_texts = ["This is a test query1.", "This is a test query2."]
print(embed.embed_documents(input_texts))
Vector Stores
You can check the entire code here.
pip install langchain-chroma
Then we can use the Chroma to store the embeddings.
from langchain_chroma import Chroma
from langchain_community.document_loaders import WebBaseLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.embeddings import ZhipuAIEmbeddings
# load the web page
loader = WebBaseLoader("https://en.d2l.ai/")
docs = loader.load()
# split the text into chunks
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 1500,
chunk_overlap = 150
)
splits = text_splitter.split_documents(docs)
# print(len(splits))
# set the embeddings models
embeddings = ZhipuAIEmbeddings(
model="embedding-3",
api_key="your own api key"
)
# set the persist directory
persist_directory = r'.'
# create the vector database
vectordb = Chroma.from_documents(
documents=splits,
embedding=embeddings,
persist_directory=persist_directory
)
# print(vectordb._collection.count())
# query the vector database
question = "Recurrent"
docs = vectordb.similarity_search(question, k=3)
# print(len(docs))
print(docs[0].page_content)
Then you can find the chorma.sqlite3 file in the specific directory.
Retrieval
This part is the core part of the RAG.
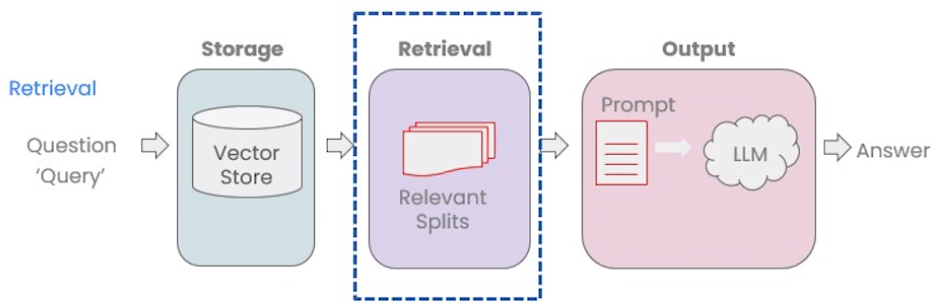
Last part we have already used the similarity_search method. On top of that, we also have other methods.
- Basic semantic similarity
- Maximum Marginal Relevance(MMR)
- Metadata
- LLM Aided Retrieval
Similarity Search
Similarity Search calculates the similarity between the query vector and all document vectors in the database to find the most relevant document.
The similarity measurement methods include cosine similarity and Euclidean distance, which can effectively measure the closeness of two vectors in a high-dimensional space.
However, relying solely on similarity search may result in insufficient diversity, as it only focuses on the match between the query and the content, ignoring the differences between different pieces of information. In some applications, especially when it is necessary to cover multiple different aspects of information, the extended method of Maximum Marginal Relevance (MMR) can better balance relevance and diversity.
Practice
The practice part is on the pervious part.
Maximum Marginal Relevance (MMR)
Retrieving only the most relevant documents may overlook the diversity of information. For example, if only the most similar response is selected, the results may be very similar or even contain duplicate content. The core idea of MMR is to balance relevance and diversity, that is, to select the information most relevant to the query while ensuring that the information is diverse in content. By reducing the repetition of information between different pieces, MMR can provide a more comprehensive and diverse set of results.
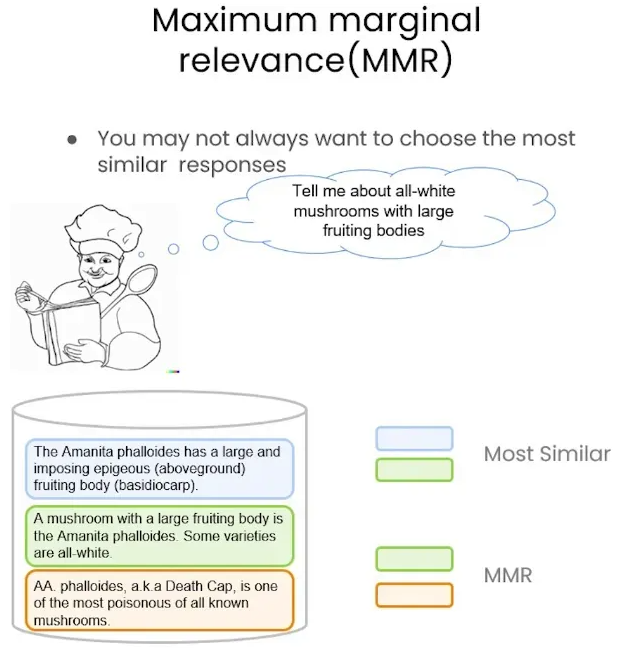
The process of MMR is as follows:
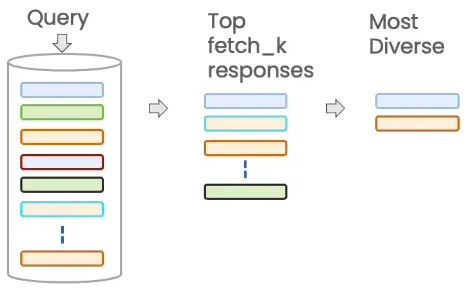
- Query the Vector Store: First convert the query into vectors using the embedding model.
- Choose the
fetch_kmost similar responses. Find the topkmost similar vectors from the vector store. - Within those responses choose the
kmost diverse. By calculating the similarity between each response, MMR will prefer results that are more different from each other, thus increasing the coverage of information. This process ensures that the returned results are not only “most similar”, but also “complementary”.
The key parameter is the lambda which is the weight of the relevance and diversity.
- When lambda is close to 1, MMR will be more like the similarity search.
- When lambda is close to 0, MMR will be more like the random search.
Practice
We can adjust the code in Vector stores part to use the MMR method. The full code is in the retrieval/mmr.py file.
# query the vector database with MMR
question = "How the neural network works?"
# fetch the 8 most similar documents, and then choose the 2 most relevant documents
docs_mmr = vectordb.max_marginal_relevance_search(question, fetch_k=8, k=2)
print(docs_mmr[0].page_content[:100])
print(docs_mmr[1].page_content[:100])
Metadata
When our query is under some specific conditions, we can use the metadata to filter the results.
For example, the information such as page numbers, authors, timestamps, etc. These information can be used as filtering conditions during retrieval, thus improving the accuracy of the query.
Practice
You can check the entire code here.
Add new documents from another website, and then filter the results from the specific website.
from langchain_chroma import Chroma
from langchain_community.document_loaders import WebBaseLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.embeddings import ZhipuAIEmbeddings
# load the web page
loader = WebBaseLoader("https://en.d2l.ai/")
docs = loader.load()
# split the text into chunks
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 1500,
chunk_overlap = 150
)
splits = text_splitter.split_documents(docs)
# print(len(splits))
# set the embeddings models
embeddings = ZhipuAIEmbeddings(
model="embedding-3",
api_key="your_api_key"
)
# set the persist directory
persist_directory = r'.'
# create the vector database
vectordb = Chroma.from_documents(
documents=splits,
embedding=embeddings,
persist_directory=persist_directory
)
# print(vectordb._collection.count())
# add new documents from another website
new_loader = WebBaseLoader("https://www.deeplearning.ai/")
new_docs = new_loader.load()
# split the text into chunks
new_splits = text_splitter.split_documents(new_docs)
# add to the existing vector database
vectordb.add_documents(new_splits)
# Get all documents
all_docs = vectordb.similarity_search("What is the difference between a neural network and a deep learning model?", k=20)
# Print the metadata of the documents
for i, doc in enumerate(all_docs):
print(f"Document {i+1} metadata: {doc.metadata}")
# Document 1 metadata: {'language': 'en', 'source': 'https://en.d2l.ai/', 'title': 'Dive into Deep Learning — Dive into Deep Learning 1.0.3 documentation'}
# Document 2 metadata: {'language': 'en', 'source': 'https://en.d2l.ai/', 'title': 'Dive into Deep Learning — Dive into Deep Learning 1.0.3 documentation'}
# Document 3 metadata: {'language': 'en', 'source': 'https://en.d2l.ai/', 'title': 'Dive into Deep Learning — Dive into Deep Learning 1.0.3 documentation'}
# Document 4 metadata: {'description': 'DeepLearning.AI | Andrew Ng | Join over 7 million people learning how to use and build AI through our online courses. Earn certifications, level up your skills, and stay ahead of the industry.', 'language': 'en', 'source': 'https://www.deeplearning.ai/', 'title': 'DeepLearning.AI: Start or Advance Your Career in AI'}
question = "how the neural network works?"
# filter the documents from the specific website
docs_meta = vectordb.similarity_search(question, k=1, filter={"source": "https://www.deeplearning.ai/"})
print(docs_meta[0].page_content[:100])
LLM Aided Retrieval
It uses language models to automatically parse sentence semantics, extract filtering information.
SelfQueryRetriever
LangChain provides the SelfQueryRetriever module, which can analyze the semantics of the question sentence from the language model, and extract the search term and filter conditions.
- The search term of the vector search
- The filter conditions of the document metadata
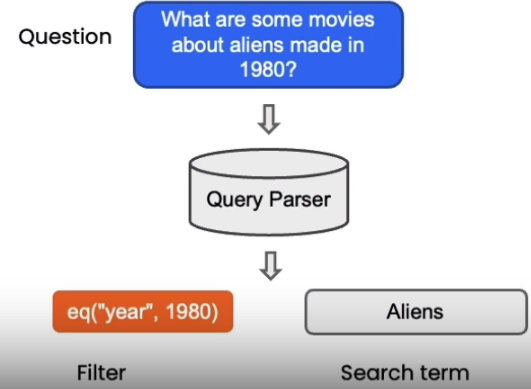
For example, for the question “Besides Wikipedia, which health websites are there?”, SelfQueryRetriever can infer that “Wikipedia” represents the filter condition, that is, to exclude the documents from Wikipedia.
Practice
from langchain.llms import OpenAI
from langchain.retrievers.self_query.base import SelfQueryRetriever
from langchain.chains.query_constructor.base import AttributeInfo
llm = OpenAI(temperature=0)
metadata_field_info = [
AttributeInfo(
name="source", # source is to tell the LLM the data is from which document
description="The lecture the chunk is from, should be one of `docs/loaders.pdf`, `docs/text_splitters.pdf`, or `docs/vectorstores.pdf`",
type="string",
),
AttributeInfo(
name="page", # page is to tell the LLM the data is from which page
description="The page from the lecture",
type="integer",
),
]
document_content_description = "the lectures of retrieval augmentation generation"
retriever = SelfQueryRetriever.from_llm(
llm,
vectordb,
document_content_description,
metadata_field_info,
verbose=True
)
question = "What is the main topic of second lecture?"
Compression
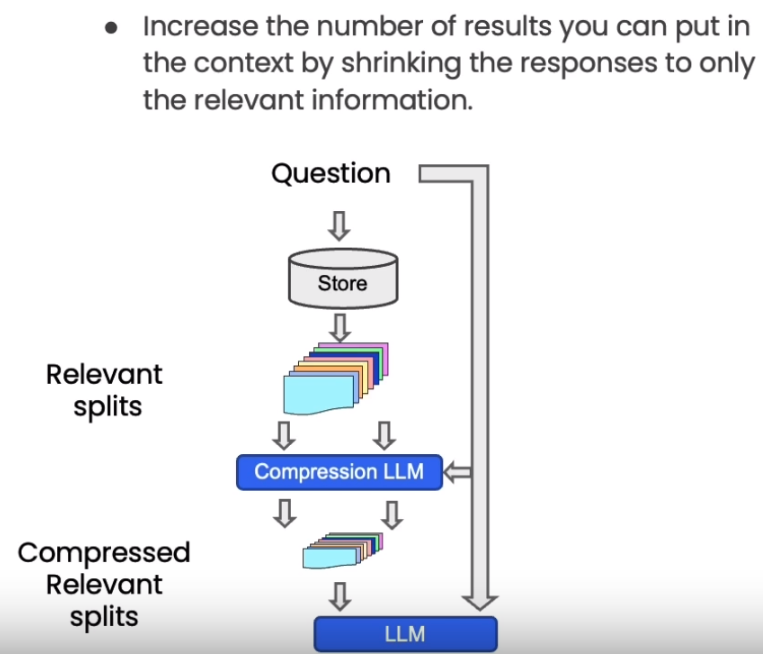
When using vector retrieval to get relevant documents, directly returning the entire document fragment may lead to resource waste, as the actual relevant part is only a small part of the document. To improve this, LangChain provides a “compression” retrieval mechanism.
Its working principle is to first use standard vector retrieval to obtain candidate documents, and then use a language model to compress these documents based on the semantic meaning of the query sentence, only retaining the relevant part of the document.
For example, for the query “the nutritional value of mushrooms”, the retrieval may return a long document about mushrooms. After compression, only the sentences related to “nutritional value” are extracted from the document.
Practice
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor
def pretty_print_docs(docs):
print(f"\n{'-' * 100}\n".join([f"Document {i+1}:\n\n" + d.page_content for i, d in enumerate(docs)]))
llm = OpenAI(temperature=0)
# initialize the compressor
compressor = LLMChainExtractor.from_llm(llm)
# initialize the compression retriever
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor, # llm chain extractor
base_retriever=vectordb.as_retriever() # vector database retriever
)
# compress the source documents
question = "What is the main topic of second lecture?"
compressed_docs = compression_retriever.get_relevant_documents(question)
pretty_print_docs(compressed_docs)
Question Answering
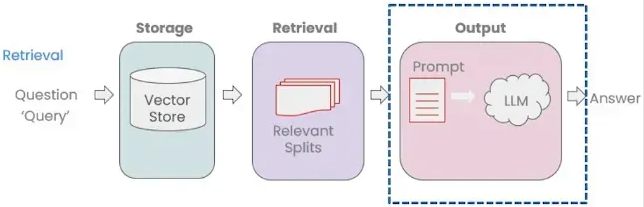
- Multiple relevant documents have been retrieved from the vector store
- Potentially compress the relevant splits to fit into the LLM context. The system will generate the necessary background information (System Prompt) and keep the user’s question (Human Question), and then integrate all the information into a complete context input.
- Send the information along with our question to an LLM to select and format an answer
RetrievalQA Chain
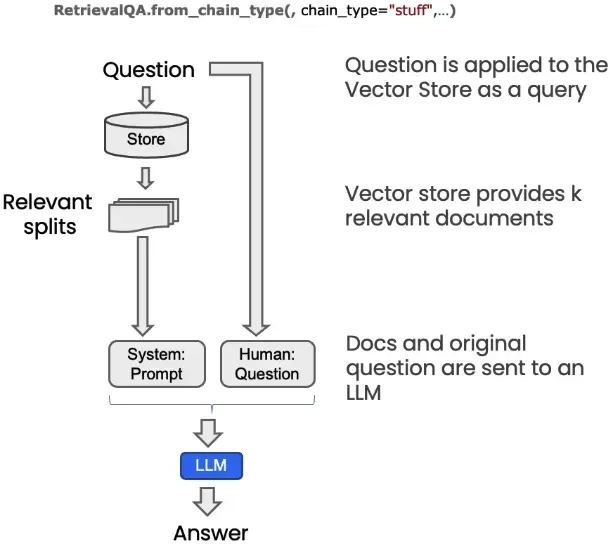
We need to use Langchain to combine the prompts into the desired format and pass them to the large language model to generate the desired reply. This solution is better than the traditional method of inputting the question into the large language model because:
- Enhance the accuracy of the answer: By combining the retrieval results with the generation ability of the large language model, the relevance and accuracy of the answer are greatly improved.
- Support real-time update of the knowledge base: The retrieval process depends on the data in the vector store, which can be updated in real time according to needs, ensuring that the answer reflects the latest knowledge.
- Reduce the memory burden of the model: By using the information in the knowledge base as the input context, the dependence on the model’s internal parameters for storing knowledge is reduced.
In addition to the RetrievalQA Chain, there are other methods, such as Map_reduce, Refine and Map_rerank.
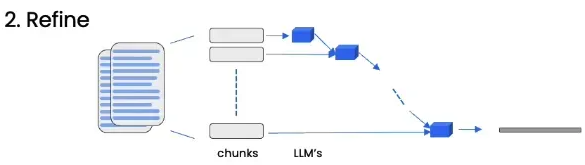
Map_reduce
Map_reduce method divides the documents into multiple chunks, and then passes each chunk to the language model (LLM) to generate an independent answer. After that, all the generated answers will be merged into the final answer, and the merging process (reduce) may include summarizing, voting, etc.
This method is suitable for the large amount of documents parallel processing, also with quick response.
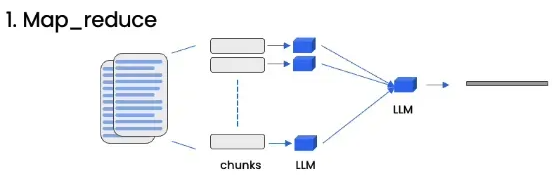
Refine
Refine method generates an initial answer from the first document chunk, and then processes each subsequent document one by one. Each block will supplement or correct the existing answer, and finally obtain an optimized and improved answer after all chunks are processed.
This method is suitable for the most quality answer.
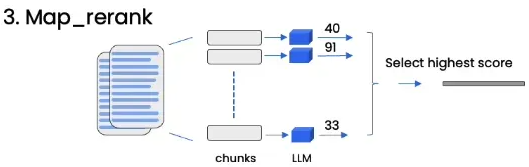
Map_rerank
Map_rerank divides the documents into multiple chunks, and then generates an independent answer for each chunk. The scoring is based on the relevance and quality of the answer. Finally, the answer with the highest score will be selected as the final output.
This method is suitable for the most match answer rather than combine with all the information.
Practice
You can check the entire code here.
First, install the lib:
pip install pyjwt
You can use the demo to check the model performance.
from langchain_community.chat_models import ChatZhipuAI
from langchain_core.messages import AIMessage, HumanMessage, SystemMessage
chat = ChatZhipuAI(
model="glm-4-flash",
temperature=0.5, # the temperature of the model
api_key="your_api_key"
)
messages = [
AIMessage(content="Hi."), # AI generated message
SystemMessage(content="Your role is a poet."), # the role of the model
HumanMessage(content="Write a short poem about AI in four lines."), # the message from the user
]
# get the answer from the model
response = chat.invoke(messages)
print(response.content)
Then we can use the RetrievalQA chain to get the answer from the model.
from langchain_community.chat_models import ChatZhipuAI
from langchain_core.messages import AIMessage, HumanMessage, SystemMessage
from langchain_community.embeddings import ZhipuAIEmbeddings
from langchain_chroma import Chroma
from langchain_community.document_loaders import WebBaseLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate # You can also import the PromptTemplate
loader = WebBaseLoader("https://en.d2l.ai/")
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 1500,
chunk_overlap = 150
)
splits = text_splitter.split_documents(docs)
persist_directory = '.'
# initialize the embeddings
embeddings = ZhipuAIEmbeddings(
model="embedding-3",
api_key="your_api_key"
)
# initialize the vector database
vectordb = Chroma.from_documents(
documents=splits,
embedding=embeddings,
persist_directory=persist_directory
)
chat = ChatZhipuAI(
model="glm-4-flash",
temperature=0.5,
api_key = "your_api_key"
)
# Now you can ask the question about the web to the model
question = "What is this book about?"
# You can also create a prompt template
template = """
Please answer the question based on the following context.
If you don't know the answer, just say you don't know, don't try to make up an answer.
Answer in at most three sentences. Please answer as concisely as possible. Finally, always say "Thank you for asking!"
Context: {context}
Question: {question}
Helpful answer:
"""
QA_CHAIN_PROMPT = PromptTemplate.from_template(template)
qa_chain = RetrievalQA.from_chain_type(
chat,
retriever=vectordb.as_retriever(),
return_source_documents=True, # Return the source documents(optional)
chain_type_kwargs={"prompt": QA_CHAIN_PROMPT} # Add the prompt template to the chain
)
result = qa_chain({"query": question})
print(result["result"])
print(result["source_documents"][0]) # If you set return_source_documents to True, you can get the source documents
Conversational Retrieval Chain
The whole process of RAG is as follows:
Conversational Retrieval Chain is a technical architecture that combines dialogue history and intelligent retrieval capabilities.
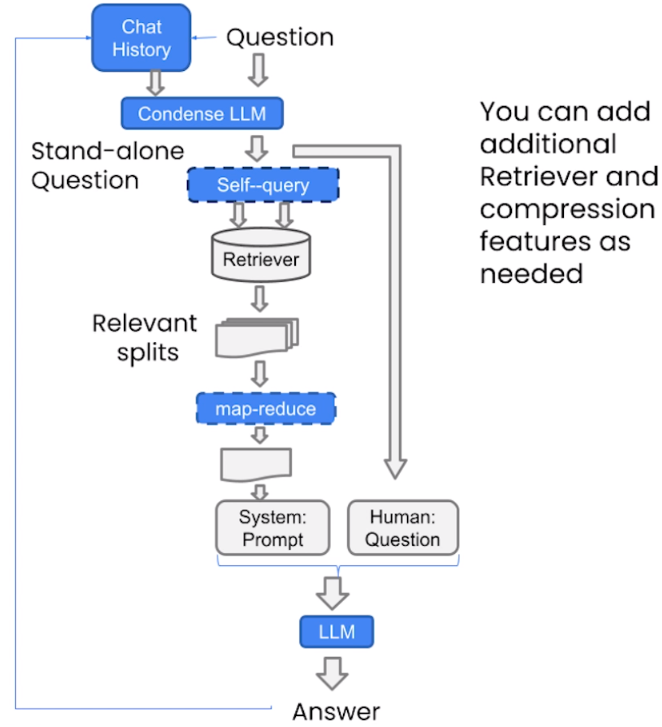
- Chat History: The system will record the user’s dialogue context as an important input for subsequent question processing.
- Question: The user’s question is sent to the retrieval module.
- Retriever: The system retrieves the content related to the question from the vector database through the retriever.
- System & Human: The system integrates the user’s question and the extracted relevant information into the Prompt, providing structured input to the language model.
- LLM: The language model generates the answer based on the context, and then returns the answer to the user.
Memory
ConversationBufferMemory is a memory module in the LangChain framework, which is used to manage the dialogue history. Its main function is to store the dialogue content between users and AI in the form of a buffer, and then return these records when needed, so that the model can generate responses in a consistent context.
The demo of it is as follows:
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory(
memory_key="chat_history", # This key can be referenced in other modules (such as chains or tools).
return_messages=True # whether to return the messages in list, otherwise return the messages in block.
)
Besides, we also need the corresponding RA module. Then we can test the memory.
from langchain.chains import ConversationalRetrievalChain
retriever=vectordb.as_retriever()
qa = ConversationalRetrievalChain.from_llm(
chat,
retriever=retriever,
memory=memory
)
question = "What is the main topic of this book?"
result = qa.invoke({"question": question})
print(result['answer'])
question = "What is my last question?"
result = qa.invoke({"question": question})
print(result['answer'])
Practice
You can check the entire code here.
The best practice is as follows:
from langchain_community.chat_models import ChatZhipuAI
from langchain_core.messages import AIMessage, HumanMessage, SystemMessage
from langchain_community.embeddings import ZhipuAIEmbeddings
from langchain_chroma import Chroma
from langchain_community.document_loaders import WebBaseLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.memory import ConversationBufferMemory
from langchain.chains import ConversationalRetrievalChain
loader = WebBaseLoader("https://en.d2l.ai/")
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 1500,
chunk_overlap = 150
)
splits = text_splitter.split_documents(docs)
persist_directory = '.'
# initialize the embeddings
embeddings = ZhipuAIEmbeddings(
model="embedding-3",
api_key="your_api_key"
)
# initialize the vector database
vectordb = Chroma.from_documents(
documents=splits,
embedding=embeddings,
persist_directory=persist_directory
)
chat = ChatZhipuAI(
model="glm-4-flash",
temperature=0.5,
api_key = "your_api_key"
)
# initialize the memory
memory = ConversationBufferMemory(
memory_key="chat_history",
return_messages=True
)
# create the ConversationalRetrievalChain
retriever = vectordb.as_retriever()
qa = ConversationalRetrievalChain.from_llm(
chat,
retriever=retriever,
memory=memory
)
# First question
question = "What is the main topic of this book?"
result = qa.invoke({"question": question})
print(result['answer'])
# Second question
question = "Can you tell me more about it?"
result = qa.invoke({"question": question})
print(result['answer'])

- 点赞
- 收藏
- 关注作者
评论(0)