《深度学习笔记》三

LeCun提出的神经网络结构,所以命名LeNet.
而他也赢得了"卷积神经网络之父“的美誉。
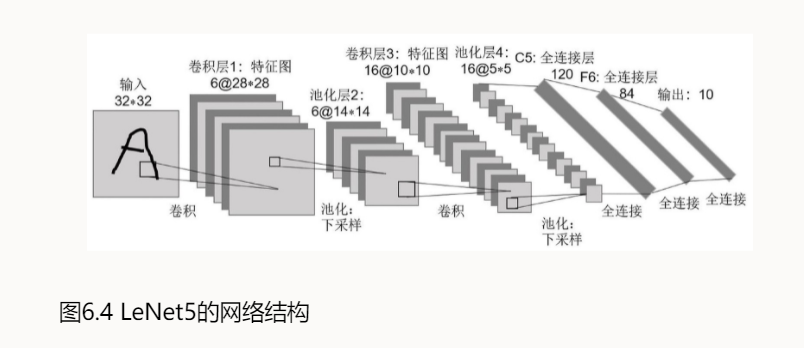
然而在LeNet提出后的十几年里,由于神经网络的可解释性较差和计算资源的限制等原因,神经网络一直处于发展的低谷阶段。
转折点
2012年
也是现代意义的深度学习的元年
Alex Krizhevsky提出的神经网络结构,所以叫AlexNet
爆点在于在当年的ILSVRC挑战赛中获得冠军(错误率16.4%),并且极大拉开了与第二名的距离(错误率26.2%)
而曾经表现最好的方法是基于手工设计的特征和浅分类器。这种极大的差距也就引起了对“新”方法的极大的兴趣。
而相比于LeNet,AlexNet有一些规模性的成长:更大的输入、更多的层、更多的参数(是原来的千万倍)
以及一些方面优化:激活函数、正则化、归一化等
人们越来越敢将神经网络的结构推向更深层。在2014年提出的vgg中,首次将神经网络结构拓展到16层和19层,也就是VGG16和vgg19。
VGG使用3*3的卷积滤波器,虽然网络加深,但结构不复杂,还很规整,非常利于编程实现。

VGG16在当年ILSVRC得了第2名,第1名是GoogLeNet
GoogLeNet使用3*3的卷积滤波器。它有一个独创的新颖的模块,叫Inception(盗梦空间…?)
实际上就是组合操作。比如由网络自行决定卷积、池化的组合。
深度卷积网络一开始面临的最主要问题是梯度消失和梯度爆炸。
梯度消失,就是在深层神经网络的训练过程中,计算得到的梯度越来越小,权值得不到更新的情形,这样算法也就失效了。
梯度爆炸,则是相反,在神经网络训练过程中梯度变得越来越大,权值得到疯狂更新的情形,这样算法得不到收敛,模型也就失效了。
通过设置线性整流函数(ReLU)和归一化激活函数层等手段可以很好地解决这些问题。
但当将网络层数加到更深时却发现训练的准确率在逐渐降低。
这种并不是由过拟合造成的神经网络训练数据识别准确率降低的现象称为退化(Degradation)。

- 点赞
- 收藏
- 关注作者
评论(0)