Flink完全分布式环境搭建及应用,Standalone(开发测试)

【摘要】 🍬博主介绍👨🎓 博主介绍:CSDN大数据领域新星创作者、阿里云专家博主✨主攻领域:【大数据】【java】【python】【面试分析】 一、架构图client客户端提交任务给 JobManagerJobManager 负责Flink集群计算资源管理, 并分发任务给TaskManager执行TaskManager定期向JobManager汇报状态Flink的TM就是运行在不同节点上JVM...
🍬博主介绍
👨🎓 博主介绍:CSDN大数据领域新星创作者、阿里云专家博主
✨主攻领域:【大数据】【java】【python】【面试分析】
一、架构图

- client客户端提交任务给 JobManager
- JobManager 负责Flink集群计算资源管理, 并分发任务给TaskManager执行
- TaskManager定期向JobManager汇报状态
- Flink的TM就是运行在不同节点上JVM进程(process), 这个进程会拥有一定量的资源. 比如内存、CPU、网络、磁盘等. flink将进程的内存进行了划分到多个slot中.
上图中有两个 TaskManager, 每个 TaskManager有2个 slot的, 每个slot占有1/2的内存.
二、 集群规划
| 服务器 | 角色 |
|---|---|
| node1 | Master, slave |
| node2 | slave |
| node3 | slave |
三、 集群搭建
1. 修改安装目录下conf文件夹内的flink-conf.yaml配置文件,指定JobManager
cd /export/server/flink/conf
vim flink-conf.yaml
# jobManager 的IP地址
jobmanager.rpc.address: node1
# JobManager 的端口号
jobmanager.rpc.port: 6123
# JobManager的总进程内存大小
jobmanager.memory.process.size: 1024m
# TaskManager的总进程内存大小
taskmanager.memory.process.size: 1024m
# 每个 TaskManager 提供的任务 slots 数量大小
taskmanager.numberOfTaskSlots: 2
#是否进行预分配内存,默认不进行预分配,这样在我们不使用flink集群时候不会占用集群资源
taskmanager.memory.preallocate: false
# 程序默认并行计算的个数
parallelism.default: 1
#JobManager的Web界面的端口(默认:8081)
rest.port: 8081
小结
taskmanager.numberOfTaskSlots:2
每一个taskmanager中的分配2个TaskSlot,3个taskmanager一共有6个TaskSlot
parallelism.default:1 运行程序默认的并行度为1,6个TaskSlot只用了1个,有5个空闲
==slot==是静态的概念,是指taskmanager具有的最大并发执行能力
==parallelism==是动态的概念,是指程序运行时实际使用的并发能力
2. 修改安装目录下conf文件夹内的workers配置文件,指定TaskManager
cd /export/server/flink/conf
vim workers
node1
node2
node3
3. 使用vi修改 /etc/profile 系统环境变量配置文件,添加HADOOP_CONF_DIR目录
vim /etc/profile
export HADOOP_CONF_DIR=/export/server/hadoop-3.3.0/etc/hadoop
注意: 必须验证 hadoop 路径是否正确
4. 分发/etc/profile到其他两个节点
scp -r /etc/profile node2:/etc
scp -r /etc/profile node3:/etc
5. 每个节点重新加载环境变量
source /etc/profile
6. 将配置好的Flink目录分发给其他的两台节点
scp -r flink-1.14.0/ node2:/export/server/
scp -r flink-1.14.0/ node3:/export/server/
在node2和node3上设置flink的快捷方式
ln -s /export/server/flink-1.14.0/ /export/server/flink
cd /export/server/ && ll | grep flink
四、 Flink初体验
1. 启动Flink集群
cd /export/server/flink
bin/start-cluster.sh
2. 通过jps查看进程信息

3. flink整合hadoop
flink与hadoop整合的时候需要上传整合的jar包:flink-shaded-hadoop-3-uber-3.1.1.7.2.9.0-173-9.0.jar、commons-cli-1.4.jar,到flink安装目录的lib目录下
注意: 集群中每个节点都需要拷贝
4. 启动HDFS集群
如果你还不会启动HDFS集群,请查看我另一篇文章:【Hadoop技术篇】hadoop的使用
5. 在HDFS中创建/test/input目录, 上传wordcount.txt文件到HDFS /test/input目录
先把 wordcount.txt 文件上传到 /root 目录下
[root@node1 ~] hdfs dfs -mkdir -p /test/input
[root@node1 ~] hdfs dfs -put wordcount.txt /test/input
[root@node1 ~] hdfs dfs -ls /test/input
Found 1 items
-rw-r--r-- 3 root supergroup 229 2022-01-01 15:55 /test/input/wordcount.txt
6. 递交作业
bin/flink run /export/server/flink/examples/batch/WordCount.jar \
--input hdfs://node1:8020/test/input/wordcount.txt \
--output hdfs://node1:8020/test/output/result.txt \
--parallelism 2
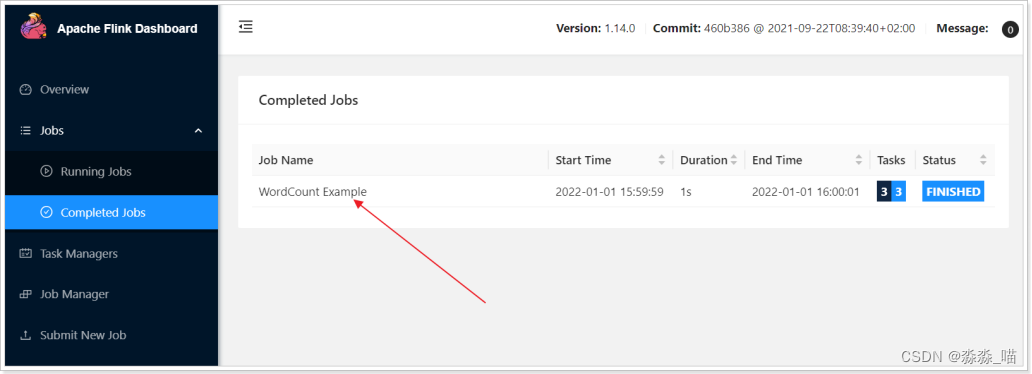
7. 浏览Flink Web UI界面
8. 命令合集
#启动/停止jobmanager
./bin/start-cluster.sh
./bin/stop-cluster.sh
#如果集群中的jobmanager进程挂了,执行下面命令启动
bin/jobmanager.sh start
bin/jobmanager.sh stop
#添加新的taskmanager节点或者重启taskmanager节点
bin/taskmanager.sh start
bin/taskmanager.sh stop

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)