带你走进知识图谱的世界

知识图谱的介绍
知识图谱最开始是Google为了优化搜索引擎提出来的,推出之后引起了业界轰动,随后其他搜索公司也纷纷推出了他们的知识图谱。知识图谱发展到今天,不仅是应用在搜索行业,已经是AI的基础功能了。那到底知识图谱是什么?有什么能力?怎么应用?这就是本文想要讨论的内容。
01 什么是知识图谱
1. 定义
官方定义:知识图谱是一种基于图的数据结构,由节点(point)和边(Edge)组成,每个节点表示一个“实体”,每条边为实体与实体之间的“关系”,知识图谱本质上是语义网络。
实体指的可以是现实世界中的事物,比如人、地名、公司、电话、动物等;关系则用来表达不同实体之间的某种联系。

由上图,可以看到实体有地名和人;大理属于云南、小明住在大理、小明和小秦是朋友,这些都是实体与实体之间的关系。
通俗定义:知识图谱就是把所有不同种类的信息连接在一起而得到的一个关系网络,因此知识图谱提供了从“关系”的角度去分析问题的能力。
2. 可视化表现
如果我们在百度搜索“周杰伦的老婆”的时候,搜索结果不是周杰伦,而是直接返回了昆凌的信息卡片,为什么呢?
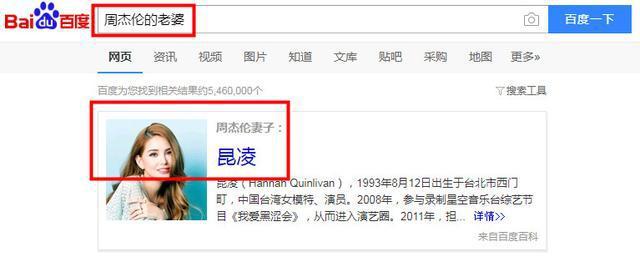
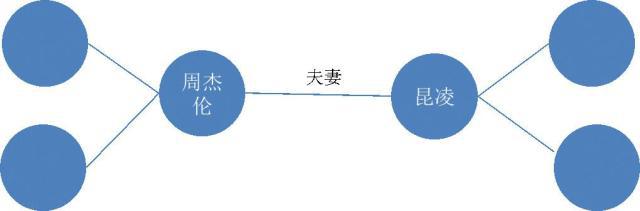
因为底层知识图谱已经有了周杰伦和昆凌是夫妻关系,所以可以理解到你要找的是昆凌,而不是周杰伦,这也说明了知识图谱有理解用户意图的能力。
02 知识图谱构建的关键技术
知识图谱构建的过程中,最主要的一个步骤就是把数据从不同的数据源中抽取出来,然后按一定的规则加入到知识图谱中,这个过程我们称为知识抽取。
数据源的分为两种:结构化的数据和非结构化的数据。
结构化的数据是比较好处理的,难点在于处理非结构化的数据。而处理非结构化数据通常需要使用自然语言处理技术:实体命名识别、关系抽取、实体统一、指代消解等。
我们先来看下把这段文字变成知识图谱的方式表达的结果:
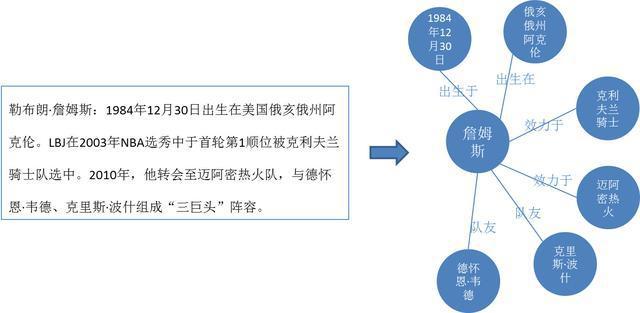
上图左边的文案就是一个非结构化的文本数据,就需要经过一系列的技术处理,才能转化为右边的知识图谱。具体是怎么实现的呢,接下来一一讨论。
1. 实体命名识别
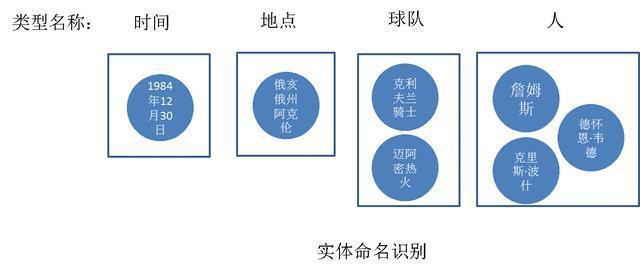
提取文本中的实体,并对每个实体进行分类或打标签,比如把文中“1984年12月30日”记为“时间”类型;“克利夫兰骑士”和“迈阿密热火”记为“球队”类型,这个过程就是实体命名。
2. 关系抽取
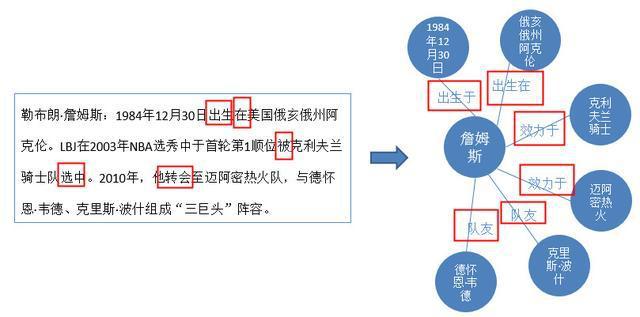
关系抽取是把实体之间的关系抽取出来的一项技术,其中主要是根据文本中的一些关键词,如“出生”、“在”、“转会”等,我们就可以判断詹姆斯与地点俄亥俄州、与迈阿密热火等实体之间的关系。
3. 实体统一

在文本中可能同一个实体会有不同的写法,比如说“LBJ”就是詹姆斯的缩写,因此“勒布朗詹姆斯”和“LBJ”指的就是同一个实体,实体统一就是处理这样问题的一项技术。
4. 指代消解

指代消解跟实体统一类似,都是处理同一个实体的问题。比如说文本中的“他”其实指的就是“勒布朗詹姆斯”。所以指代消解要做的事情就是,找出这些代词,都指的是哪个实体。
指代消解和实体统一是知识抽取中比较难的环节。
03 知识图谱的存储
知识图谱主要有两种存储方式:一种是基于RDF的存储;另一种是基于图数据库的存储。
1. RDF(Resource Description Framework)
RDF一个重要的设计原则是数据的易发布以及共享,另外,RDF以三元组的方式来存储数据而且不包含属性信息。
2. 图数据库
图数据库主要把重点放在了高效的图查询和搜索上,一般以属性图为基本的表示形式,所以实体和关系可以包含属性。
3. RDF和图数据库的主要特点区别
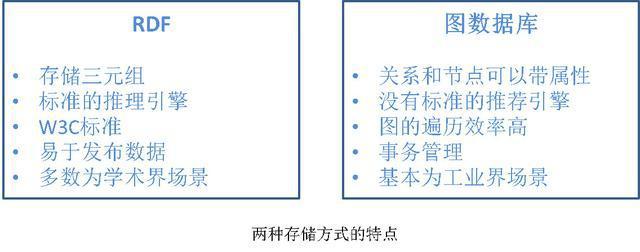
关于知识图片的存储方式的内容比较专业,且没有实际操作过比较难理解,所以我就不在此展开讨论了,大家简单知道知识图谱有这么一项内容就行,若有需要的可以自行研究下。
下面我们把重点放在知识图片在金融领域的一些应用。
04 知识图谱在金融领域的应用
知识图谱在各行各业中的应用是比较普及的,并且有很重要的地位。下面我们跟大家一起讨论的是知识图谱在金融领域的一些应用,希望能通过这些例子给大家一点启发。
1. 反欺诈
假设银行要借钱给一个人,那要怎么判断这个人是真实用户还是欺诈的呢?
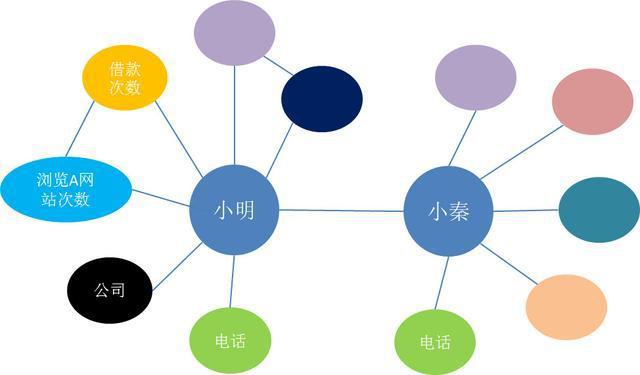
我们需要以人为核心,展开一系列的数据构建,比如说用户的基本信息、借款记录、工作信息、消费记录、行为记录、网站浏览记录等等。把这些信息整合到知识图谱中。从而整体进行预测和评分,用户欺诈行为的概率有多大。当然这个预测是需要通过机器学习,得到一个合理的模型,模型中可能会包括消费记录的权重、网站浏览记录的权重等等信息。
2. 不一致性验证
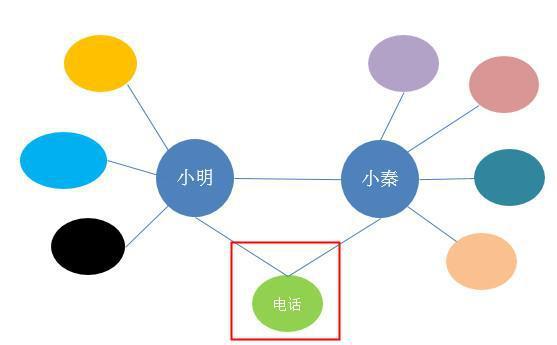
比如说不同的两个借款人,却填写了同一个电话号码,那说明这两个人中至少有一个是可疑的了,这时就需要重点关注了。
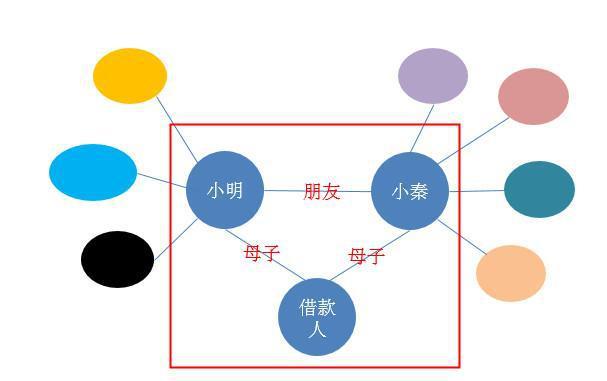
更复杂点的,可能需要知识图谱通过一些关系去推理了。比如说“借款人”跟小明和小秦都是母子关系,按推理的话小明跟小秦应该是兄弟关系,而在知识图谱上显示的是朋友关系,就有可能有异常了,因此也需要重点关注。
3. 客户失联管理
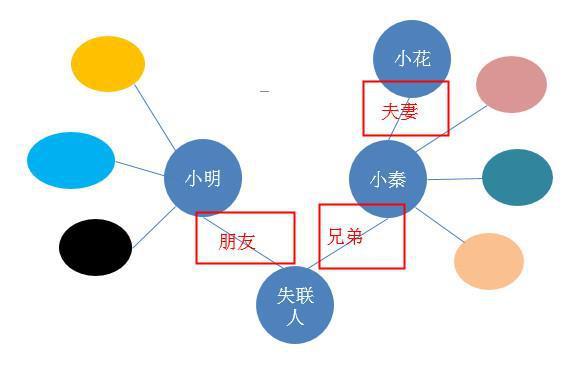
如果借款人失联了,通过知识图谱,是不是可以联系他的朋友,或兄弟,甚至是兄弟的妻子,去追踪失联人。
因此在失联的情况下,知识图谱可以挖掘更多失联人的联系人,从而提高催收效率。
4. 知识推理
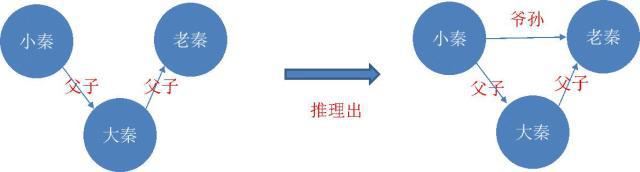
如上左图(注意这里的箭头方向),小秦是大秦的儿子,大秦是老秦的儿子,从这这样的关系,我们就可以推理出,小秦是老秦的孙子,这样就能使知识图谱更加完善了。
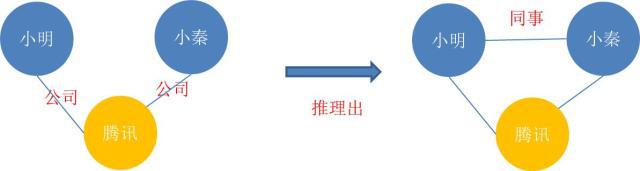
如上左图,小明在腾讯上班,小秦也在腾讯上班,从这样的关系,我们可以推理出,小明和小秦是同事关系。
推理能力其实就是机器模仿人的一种重要的能力,可以从已有的知识中发现一些隐藏的知识。当然这样的能力离不开深度学习,而随着深度学习的不断成熟,我相信知识图谱的能力也会越来越强大。
graph - embedding 图编码
图数据库 Neo4j
neo4j 下载: https://neo4j.com/download-center/
Neo4j Demo https://grapheco.org/InteractiveGraph/dist/examples/example1.html
为什么用 neo4j ?用的人最多, 模板好找, 报错能查,就这么简单
官网 : neo4j.com
Neo4j 教程 https://www.w3cschool.cn/neo4j/neo4j_need_for_graph_databses.html
JDK安装 :https://www.oracle.com/java/technologies/downloads/
不支持 低版本的jdk 必须是10以上
启动 neo4j.bat console
网页访问localhost:7474


- 点赞
- 收藏
- 关注作者
评论(0)