Hadoop之初识MapReduce

1.MapReduce计算模型介绍
1.1.理解MapReduce思想
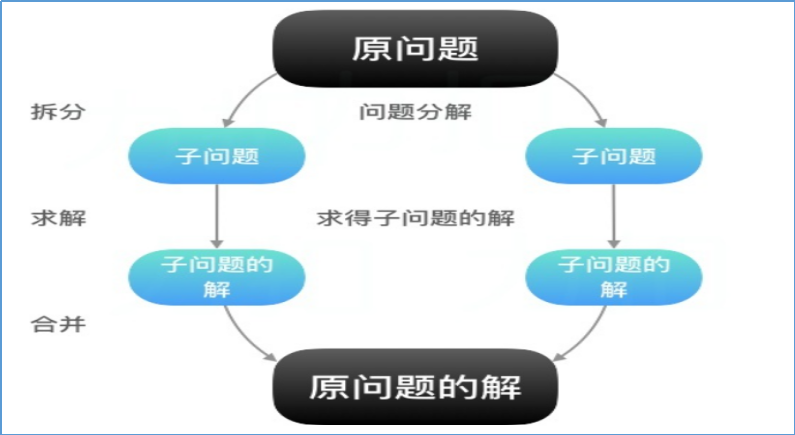
MapReduce的思想核心是“分而治之”。
所谓“分而治之”就是把一个复杂的问题按一定的“分解”方法分为规模较小的若干部分,然后逐个解决,分别找出各部分的解,再把把各部分的解组成整个问题的解。
这种朴素的思想来源于人们生活与工作的经验,也完全适合于技术领域。诸如软件的体系结构设计、模块化设计都是分而治之的具体表现。即使是发布过论文实现分布式计算的谷歌也只是实现了这种思想,而不是自己原创。
概况起来,MapReduce所包含的思想分为两步:

==Map负责“分”==,即把复杂的任务分解为若干个“简单的任务”来并行处理。可以进行拆分的前提是这些小任务可以并行计算,彼此间几乎没有依赖关系。
==Reduce负责“合”==,即对map阶段的结果进行全局汇总。
这两个阶段合起来正是MapReduce思想的体现。
还有一个比较形象的语言解释MapReduce:要数停车场中的所有停放车的总数量。
你数第一列,我数第二列…这就是Map阶段,人越多,能够同时数车的人就越多,速度就越快。
数完之后,聚到一起把所有人的统计数加在一起。这就是Reduce合并汇总阶段。

1.2.Hadoop MapReduce设计构思
MapReduce是一个分布式运算程序的编程框架,核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的==分布式运算程序==,并发运行在Hadoop集群上。
既然是做计算的框架,那么表现形式就是有个输入(input),MapReduce操作这个输入(input),通过本身定义好的计算模型,得到一个输出(output)。
对许多开发者来说,自己完完全全实现一个并行计算程序难度太大,而MapReduce就是一种简化并行计算的编程模型,降低了开发并行应用的入门门槛。
Hadoop MapReduce构思体现在如下的三个方面:
-
如何对付大数据处理:分而治之
对相互间不具有计算依赖关系的大数据,实现并行最自然的办法就是采取分而治之的策略。并行计算的第一个重要问题是如何划分计算任务或者计算数据以便对划分的子任务或数据块同时进行计算。不可分拆的计算任务或相互间有依赖关系的数据无法进行并行计算! -
构建抽象模型:Map和Reduce
MapReduce借鉴了函数式语言中的思想,用Map和Reduce两个函数提供了高层的并行编程抽象模型。
Map: 对一组数据元素进行某种重复式的处理;
Reduce: 对Map的中间结果进行某种进一步的结果整理。
MapReduce中定义了如下的Map和Reduce两个抽象的编程接口,由用户去编程实现:
map: (k1; v1) → [(k2; v2)]
reduce: (k2; [v2]) → [(k3; v3)]
Map和Reduce为程序员提供了一个清晰的操作接口抽象描述。通过以上两个编程接口,大家可以看出MapReduce处理的数据类型是<key,value>键值对。 -
统一构架,隐藏系统层细节
如何提供统一的计算框架,如果没有统一封装底层细节,那么程序员则需要考虑诸如数据存储、划分、分发、结果收集、错误恢复等诸多细节;为此,MapReduce设计并提供了统一的计算框架,为程序员隐藏了绝大多数系统层面的处理细节。
MapReduce最大的亮点在于通过抽象模型和计算框架把需要做什么(what need to do)与具体怎么做(how to do)分开了,为程序员提供一个抽象和高层的编程接口和框架。程序员仅需要关心其应用层的具体计算问题,仅需编写少量的处理应用本身计算问题的程序代码。
如何具体完成这个并行计算任务所相关的诸多系统层细节被隐藏起来,交给计算框架去处理:从分布代码的执行,到大到数千小到单个节点集群的自动调度使用。
2.官方MapReduce示例
在Hadoop的安装包中,官方提供了MapReduce程序的示例examples,以便快速上手体验MapReduce。
该示例是使用java语言编写的,被打包成为了一个jar文件。
/export/server/hadoop-3.3.0/share/hadoop/mapreduce
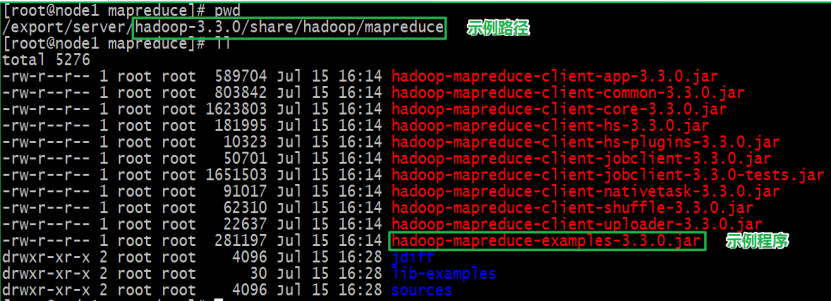
运行该jar包程序,可以传入不同的参数实现不同的处理功能。
hadoop jar hadoop-mapreduce-examples-3.3.0.jar args…
2.1.示例1:评估圆周率π(PI)
圆周率π大家都不陌生,如何去估算π的值呢?
==Monte Carlo==方法到基本思想:
当所求解问题是某种随机事件出现的概率,或者是某个随机变量的期望值时,通过某种“实验”的方法,以这种事件出现的频率估计这一随机事件的概率,或者得到这个随机变量的某些数字特征,并将其作为问题的解。
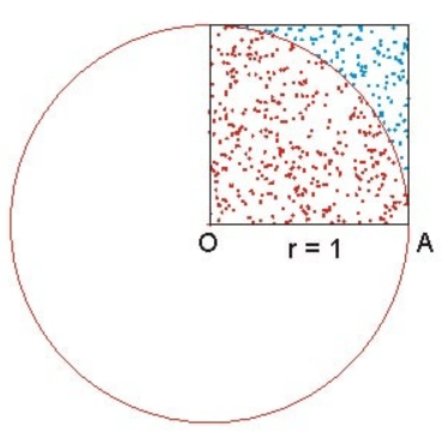
假设正方形边长为1,圆半径也为1,那么1/4圆的面积为:
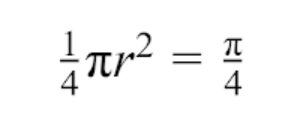
在正方形内随机撒点,分布于1/4圆内的数量假设为a ,分布于圆外的数量为b,N则是所产生的总数:N=a+b。
那么数量a与N的比值应与1/4圆面积及正方形面积成正比,于是:
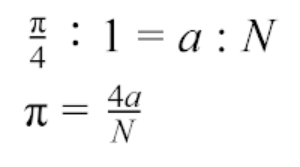
下面来运行MapReduce程序评估一下圆周率的值,执行中可以去YARN页面上观察程序的执行的情况。
[root@node1 mapreduce]# pwd
/export/server/hadoop-3.3.0/share/hadoop/mapreduce
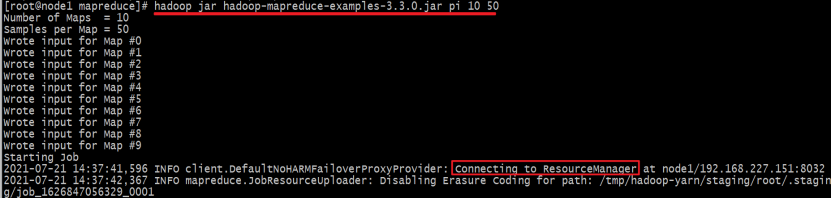
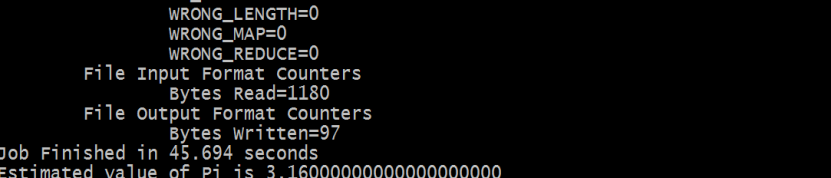
[root@node1 mapreduce]# hadoop jar hadoop-mapreduce-examples-3.3.0.jar pi 10 50
第一个参数pi:表示MapReduce程序执行圆周率计算;
第二个参数:用于指定map阶段运行的任务次数,并发度,这是是10;
第三个参数:用于指定每个map任务取样的个数,这里是50。


2.2.示例2:单词词频统计WordCount
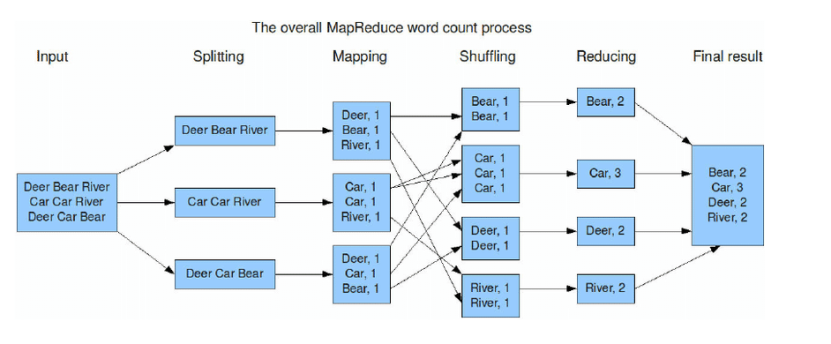
WordCount算是大数据统计分析领域的经典需求了,相当于编程语言的HelloWorld。其背后的应用场景十分丰富,比如统计页面点击数,搜索词排行榜等跟count相关的需求。
其最基本的应用雏形就是统计文本数据中,相同单词出现的总次数。用SQL的角度来理解的话,相当于根据单词进行group by分组,相同的单词分为一组,然后每个组内进行count聚合统计。
对于MapReduce乃至于大数据计算引擎来说,业务需求本身是简单的,重点是当数据量大了之后,如何使用分而治之的思想来处理海量数据进行单词统计。
上传文本文件到HDFS文件系统的/input目录下,如果没有这个目录,使用shell创建:
hadoop fs -mkdir /input
hadoop fs -put 1.txt /input
准备好之后,执行官方MapReduce实例,对上述文件进行单词次数统计:
[root@node1 mapreduce]# pwd
/export/server/hadoop-3.3.0/share/hadoop/mapreduce
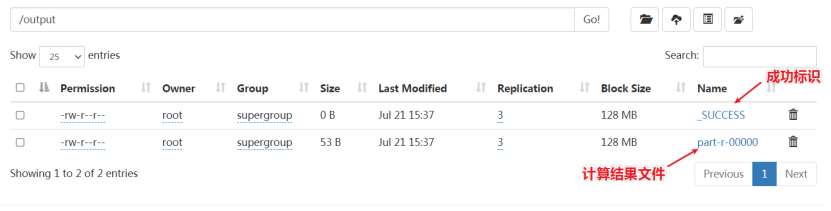
[root@node1 mapreduce]# hadoop jar hadoop-mapreduce-examples-3.3.0.jar wordcount /input /output
第一个参数:wordcount表示执行单词统计
第二个参数:指定输入文件的路径
第三个参数:指定输出结果的路径(该路径不能已存在)
3.MapReduce Python接口接入
3.1.前言
虽然Hadoop是用Java编写的一个框架, 但是并不意味着他只能使用Java语言来操作, 在Hadoop-0.14.1版本后, Hadoop支持了==Python和C++==语言, 在Hadoop的文档中也表示可以使用Python进行开发。
Hadoop Streaming文档连接:Hadoop Streaming
在Hadoop的文档中提到了Hadoop Streaming, 我们可以使用流的方式来操作它.语法是:
[root@node1 lib]# pwd
/export/server/hadoop-3.3.0/share/hadoop/tools/lib
[root@node1 lib]# hadoop jar hadoop-streaming-3.3.0.jar
-input InputDirs \
-output OutputDir \
-mapper xxx \
-reducer xxx
在Python中的sys包中存在, stdin和stdout,输入输出流, 我们可以利用这个方式来进行MapReduce的编写.
3.2.代码实现
==mapper.py==
import sys
for line in sys.stdin:
# 捕获输入流
line = line.strip()
# 根据分隔符切割单词
words = line.split()
# 遍历单词列表 每个标记1
for word in words:
print("%s\t%s" % (word, 1))
==reducer.py==
-*- coding:utf-8 -*-
@Time : 2022/10/30 20:00
@Author: chad__chang
@File : reducer.py
import sys
保存单词次数的字典 key:单词 value:总次数
word_dict = {}
for line in sys.stdin:
line = line.strip()
word, count = line.split('\t')
# count类型转换
try:
count = int(count)
except ValueError:
continue
# 如果单词位于字典中 +1,如果不存在 保存并设初始值1
if word in word_dict:
word_dict[word] += 1
else:
word_dict.setdefault(word, 1)
#结果遍历输出
for k, v in word_dict.items():
print('%s\t%s' % (k, v))
3.3.程序执行
方式1:本地测试Python脚本逻辑是否正确。
方式2:使用hadoop streaming提交Python脚本集群运行。
注意:不管哪种方式执行,都需要提前在Centos系统上安装好Python3.
本地测试
#上传待处理文件 和Python脚本到Linux上
[root@node2 ~]# pwd
/root
[root@node2 ~]# ll
-rw-r--r-- 1 root root 105 May 18 15:12 1.txt
-rwxr--r-- 1 root root 340 Jul 21 16:16 mapper.py
-rwxr--r-- 1 root root 647 Jul 21 16:18 reducer.py
#使用shell管道符运行脚本测试
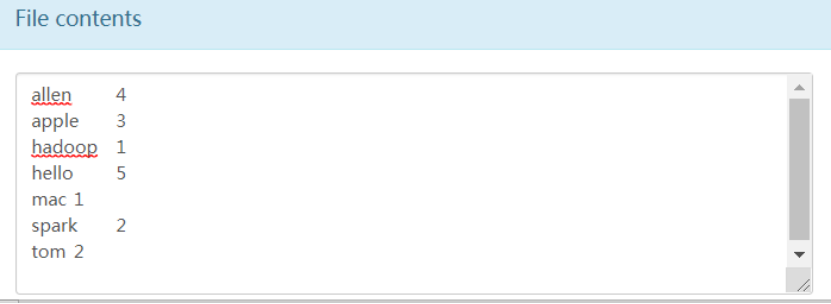
[root@node2 ~]# cat 1.txt | python mapper.py |sort|python reducer.py
allen 4
apple 3
hadoop 1
hello 5
mac 1
spark 2
tom 2
hadoop streaming提交
#上传处理的文件到hdfs、上传Python脚本到linux
#提交程序执行
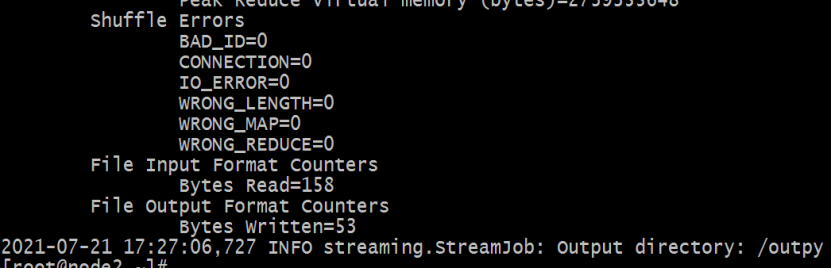
hadoop jar /export/server/hadoop-3.3.0/share/hadoop/tools/lib/hadoop-streaming-3.3.0.jar \
-D mapred.reduce.tasks=1 \
-mapper "python mapper.py" \
-reducer "python reducer.py" \
-file mapper.py -file reducer.py \
-input /input/* \
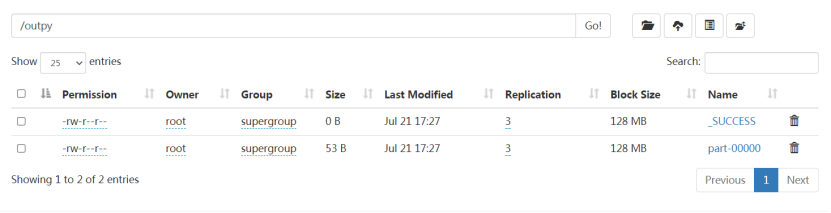
-output /outpy
执行结果:

- 点赞
- 收藏
- 关注作者
评论(0)