想了解流计算?你必须得看一眼,实现Flink on Yarn的三种部署方式,并运行wordcount计算任务

1. 第一种方式:YARN session
1.1 说明
1.1.1 yarn-session.sh(开辟资源)+flink run(提交任务)
这种模式下会启动yarn session,并且会启动Flink的两个必要服务:JobManager和Task-managers,然后你可以向集群提交作业。同一个Session中可以提交多个Flink作业。需要注意的是,这种模式下Hadoop的版本至少是2.2,而且必须安装了HDFS(因为启动YARN session的时候会向HDFS上提交相关的jar文件和配置文件)
1.1.2 通过./bin/yarn-session.sh脚本启动YARN Session
脚本可以携带的参数:
-n(–container):TaskManager的数量。(1.10 已经废弃)
-s(–slots): 每个TaskManager的slot数量,默认一个slot一个core,默认每个taskmanager的slot的个数为1,有时可以多一些taskmanager,做冗余。
-jm:JobManager的内存(单位MB)。
-q:显示可用的YARN资源(内存,内核);
-tm:每个TaskManager容器的内存(默认值:MB)
-nm:yarn 的appName(现在yarn的ui上的名字)。
-d:后台执行
注意:
如果不想让Flink YARN客户端始终运行,那么也可以启动分离的 YARN会话。该参数被称为-d或--detached。
==确定TaskManager数==:
Flink on YARN时,TaskManager的数量就是:max(parallelism) / yarnslots(向上取整)。例如,一个最大并行度为10,每个TaskManager有两个任务槽的作业,就会启动5个TaskManager。
1.2 启动
1.2.1 yarn-session.sh(开辟资源)
cd /export/server/flink/
bin/yarn-session.sh -tm 1024 -s 4 -d
参数说明
-n 表示申请2个容器,这里指的就是多少个taskmanager
-tm 表示每个TaskManager的内存大小
-s 表示每个TaskManager的slots数量
-d 表示以后台程序方式运行
解释
上面的命令的意思是,每个 TaskManager 拥有4个 Task Slot(-s 4),并且被创建的每个 TaskManager 所在的YARN Container 申请 1024M 的内存,同时额外申请一个Container用以运行ApplicationMaster以及Job Manager。
1.2.2 执行wordcount(提交任务)
bin/flink run -p 8 examples/batch/WordCount.jar
解释
-p 为8,并行度为 8 , 上面在开辟资源时,指定的
-s 为4 每个TaskManager 有4个slot, 几个并行就需要几个slot, 所以我们这次的案例会用到 2个TaskManager 。
1.2.3 启动成功之后,控制台显示
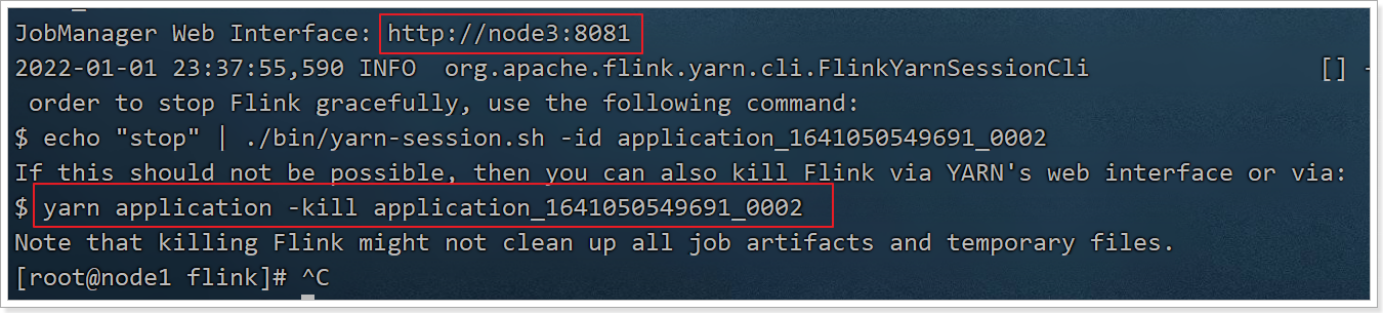
JobManager Web Interface:后面的信息就是你可以访问到flink界面的信息。
==此为flink的web界面==
1.2.4 去yarn页面
ip:8088可以查看当前提交的flink session
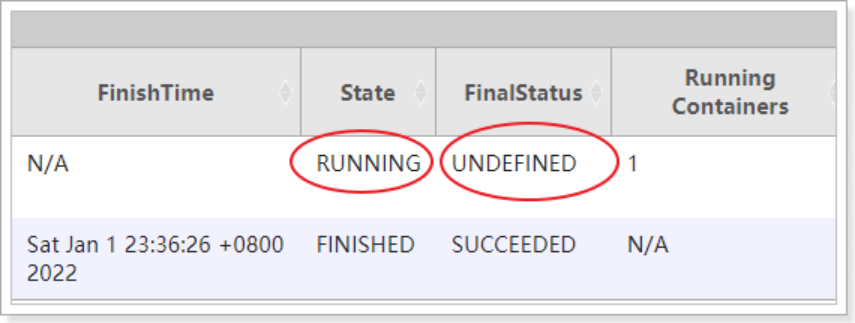
虽然程序运行完了,但是转态依然是==running== ,最终状态是==undefined==,意味着资源依然被占用,程序没有终止。
1.2.5 停止当前任务
yarn application -kill application_1641050549691_0002
1.5.7.2.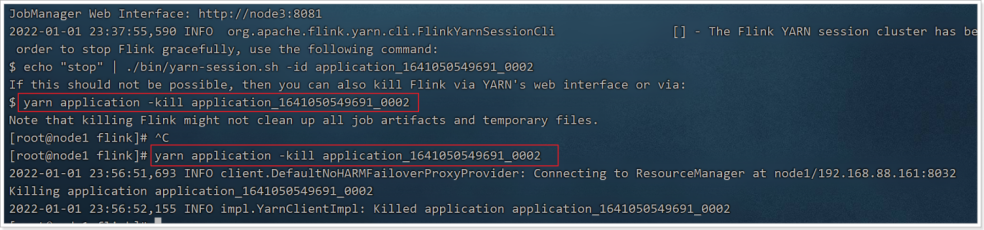
2. 第二种方式:Per-Job
2.1 在YARN上运行一个Flink作业
这里我们还是使用./bin/flink,但是==不需要==事先启动YARN session:
直接提交job
cd /export/server/flink/
bin/flink run -m yarn-cluster -yjm 1024 -ytm 1024 examples/batch/WordCount.jar
参数说明
-m jobmanager的地址
-yjm 1024 指定jobmanager的内存信息
-ytm 1024 指定taskmanager的内存信息
其他参数
常用参数:
–p 程序默认并行度
下面的参数仅可用于 -m yarn-cluster 模式
–yjm JobManager可用内存,单位兆
–ynm YARN程序的名称
–yq 查询YARN可用的资源
–yqu 指定YARN队列是哪一个
–ys 每个TM会有多少个Slot
–ytm 每个TM所在的Container可申请多少内存,单位兆
–yD 动态指定Flink参数
-yd 分离模式(后台运行,不指定-yd, 终端会卡在提交的页面上)
2.2 去yarn页面
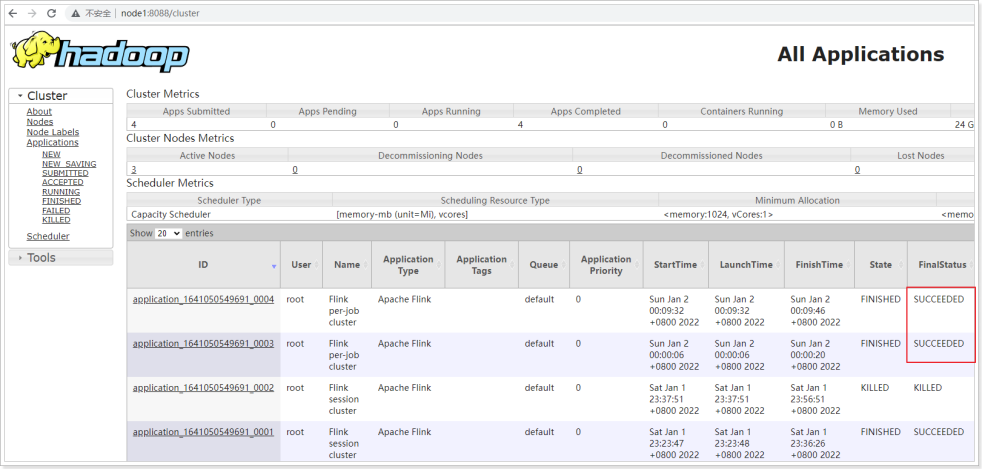
2.3 停止 yarn-cluster
yarn application -kill application的ID
2.4 注意
在创建集群的时候,集群的配置参数就写好了,但是往往因为业务需要,要更改一些配置参数,这个时候可以不必因为一个实例的提交而修改conf/flink-conf.yaml;
可以通过:-yD <arg> Dynamic properties
来覆盖原有的配置信息:比如:
bin/flink run -m yarn-cluster -yD fs.overwrite-files=true examples/batch/WordCount.jar
-yD fs.overwrite-files=true -yD taskmanager.network.numberOfBuffers=16368
3. 第三种方式:Application Mode
application 模式使用 bin/flink run-application 提交作业;
通过 -t 指定部署环境,目前 application 模式支持部署在 yarn 上(-t yarn-application) 和 k8s 上(-t kubernetes-application);
并支持通过 -D 参数指定通用的 运行配置,比如 jobmanager/taskmanager 内存、checkpoint 时间间隔等。
通过 bin/flink run-application -h 可以看到 -D/-t 的详细说明:(-e 已经被废弃,可以忽略)
- 下面列举几个使用 Application 模式提交作业到 yarn 上运行的命令:
3.1 第一种方式
- 带有 JM 和 TM 内存设置的命令提交:
/bin/flink run-application -t yarn-application \
-Djobmanager.memory.process.size=1024m \
-Dtaskmanager.memory.process.size=1024m \
-Dyarn.application.name="MyFlinkWordCount" \
./examples/batch/WordCount.jar --output hdfs://node1:8020/wordcount/output_51
3.2 第二种方式
- 在上面例子 的基础上自己设置 TaskManager slots 个数为3,以及指定并发数为3:
./bin/flink run-application -t yarn-application -p 3 \
-Djobmanager.memory.process.size=1024m \
-Dtaskmanager.memory.process.size=1024m \
-Dyarn.application.name="MyFlinkWordCount" \
-Dtaskmanager.numberOfTaskSlots=3 \
./examples/batch/WordCount.jar --output hdfs://node1:8020/wordcount/output_52
当然,指定并发还可以使用 -Dparallelism.default=3,而且社区目前倾向使用 -D+通用配置代替客户端命令参数(比如 -p)。所以这样写更符合规范:
./bin/flink run-application -t yarn-application \
-Dparallelism.default=3 \
-Djobmanager.memory.process.size=1024m \
-Dtaskmanager.memory.process.size=1024m \
-Dyarn.application.name="MyFlinkWordCount" \
-Dtaskmanager.numberOfTaskSlots=3 \
./examples/batch/WordCount.jar --output hdfs://node1:8020/wordcount/output_53
3.3 第三种方式
- 和 yarn.provided.lib.dirs 参数一起使用,可以充分发挥 application 部署模式的优势:我们看 官方配置文档 对这个配置的解释:
yarn.provided.lib.dirs: A semicolon-separated list of provided lib directories. They should be pre-uploaded and world-readable. Flink will use them to exclude the local Flink jars(e.g. flink-dist, lib/, plugins/)uploading to accelerate the job submission process. Also YARN will cache them on the nodes so that they doesn’t need to be downloaded every time for each application. An example could be hdfs://$namenode_address/path/of/flink/lib
意思是我们可以预先上传 flink 客户端依赖包 (flink-dist/lib/plugin) 到远端存储(一般是 hdfs,或者共享存储),然后通过 yarn.provided.lib.dirs 参数指定这个路径,flink 检测到这个配置时,就会从该地址拉取 flink 运行需要的依赖包,省去了依赖包上传的过程,yarn-cluster/per-job 模式也支持该配置。在之前的版本中,使用 yarn-cluster/per-job 模式,每个作业都会单独上传 flink 依赖包(一般会有 180MB左右)导致 hdfs 资源浪费,而且程序异常退出时,上传的 flink 依赖包往往得不到自动清理。通过指定 yarn.provided.lib.dirs,所有作业都会使用一份远端 flink 依赖包,并且每个 yarn nodemanager 都会缓存一份,提交速度也会大大提升,对于跨机房提交作业会有很大的优化。
使用示例如下:
my-application.jar 是用户 jar 包
上传 Flink 相关 plugins 到hdfs
cd /export/server/flink/plugins
hdfs dfs -mkdir -p /flink/plugins
hdfs dfs -put \
external-resource-gpu/flink-external-resource-gpu-1.14.0.jar \
metrics-datadog/flink-metrics-datadog-1.14.0.jar \
metrics-graphite/flink-metrics-graphite-1.14.0.jar \
metrics-influx/flink-metrics-influxdb-1.14.0.jar \
metrics-jmx/flink-metrics-jmx-1.14.0.jar \
metrics-prometheus/flink-metrics-prometheus-1.14.0.jar \
metrics-slf4j/flink-metrics-slf4j-1.14.0.jar \
metrics-statsd/flink-metrics-statsd-1.14.0.jar \
/flink/plugins
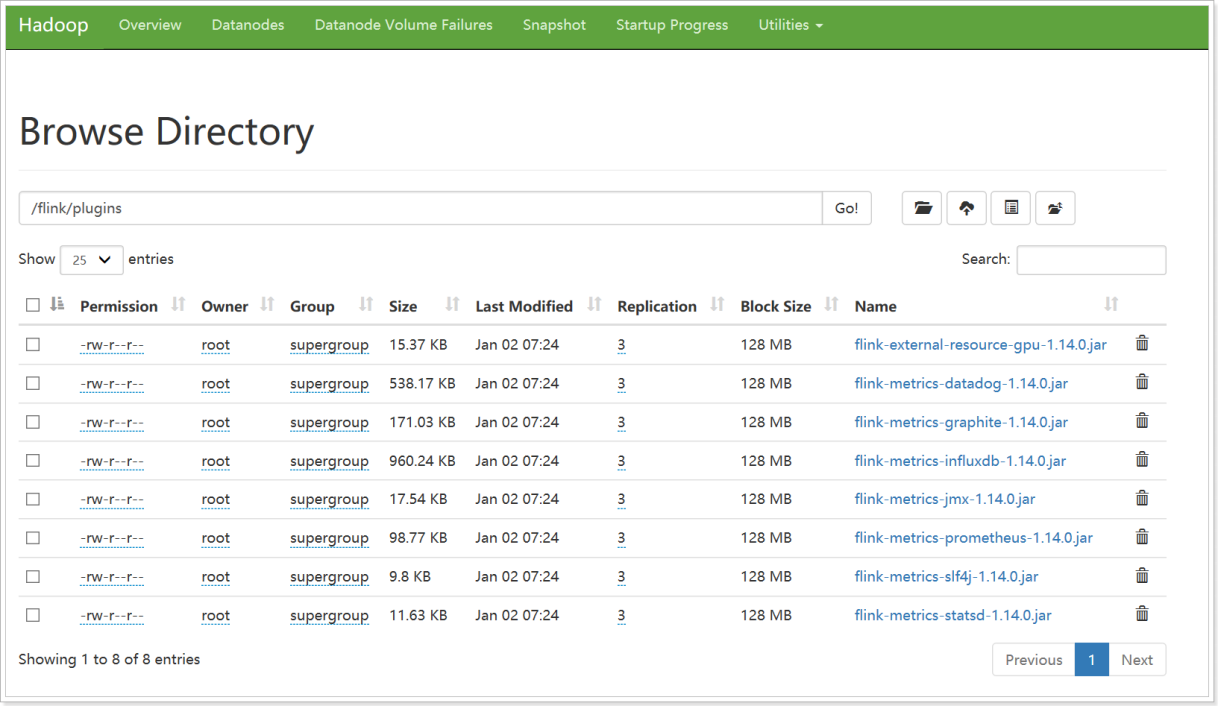
根据自己业务需求上传相关的 jar
cd /export/server/flink/lib
hdfs dfs -mkdir /flink/lib
hdfs dfs -put flink-csv-1.14.0.jar \
flink-dist_2.12-1.14.0.jar \
flink-json-1.14.0.jar \
flink-shaded-hadoop-3-uber-3.1.1.7.2.9.0-173-9.0.jar \
commons-cli-1.4.jar \
flink-shaded-zookeeper-3.4.14.jar \
flink-table_2.12-1.14.0.jar \
log4j-1.2-api-2.14.1.jar \
log4j-api-2.14.1.jar \
log4j-core-2.14.1.jar \
log4j-slf4j-impl-2.14.1.jar \
/flink/lib
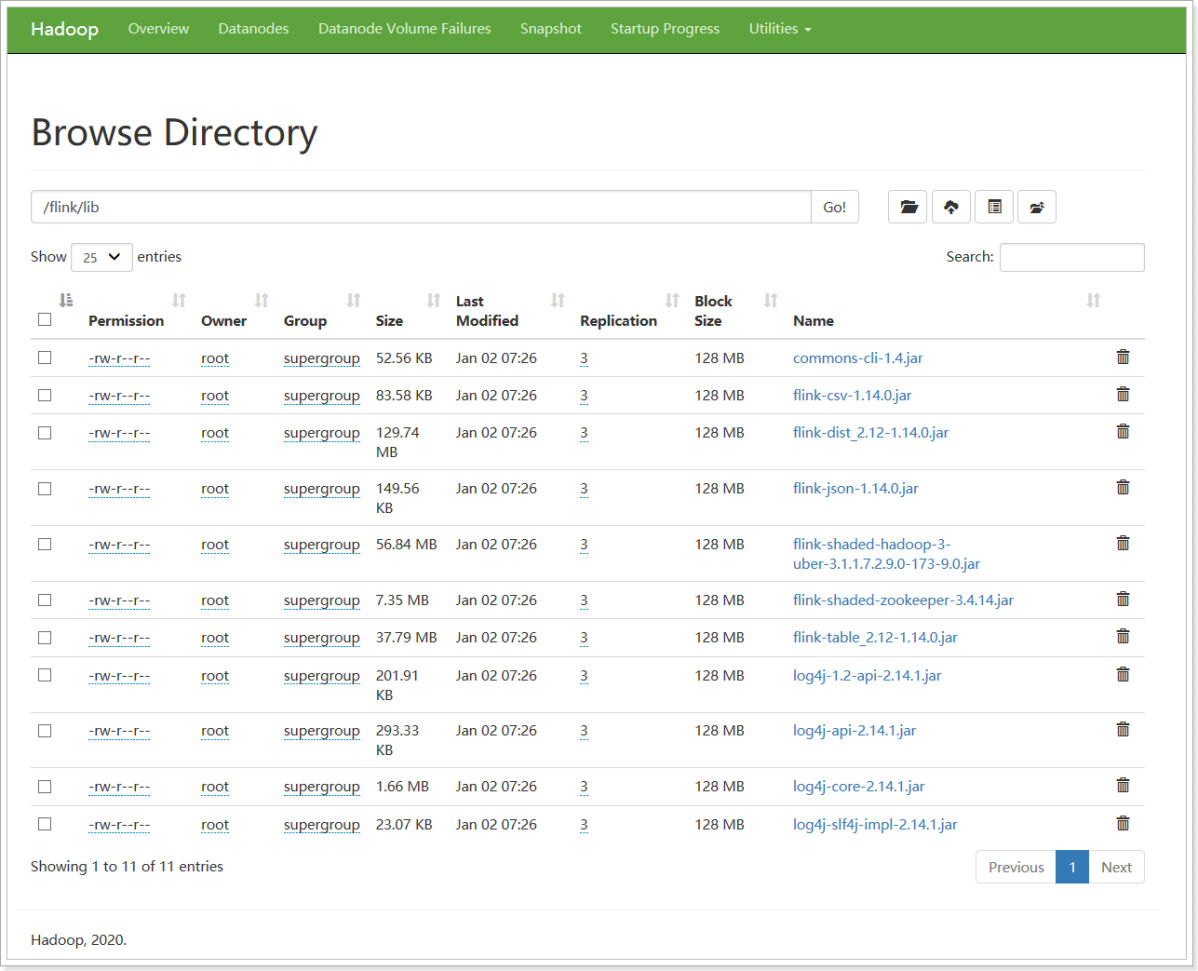
上传用户 jar 到 hdfs
cd /export/server/flink
hdfs dfs -mkdir /flink/user-libs
hdfs dfs -put ./examples/batch/WordCount.jar /flink/user-libs
# 提交任务
bin/flink run-application -t yarn-application \
-Djobmanager.memory.process.size=1024m \
-Dtaskmanager.memory.process.size=1024m \
-Dtaskmanager.numberOfTaskSlots=2 \
-Dparallelism.default=2 \
-Dyarn.provided.lib.dirs="hdfs://node1:8020/flink/lib;hdfs://node1:8020/flink/plugins" \
-Dyarn.application.name="batchWordCount" \
hdfs://node1:8020/flink/user-libs/WordCount.jar --output hdfs://node1:8020/wordcount/output_54
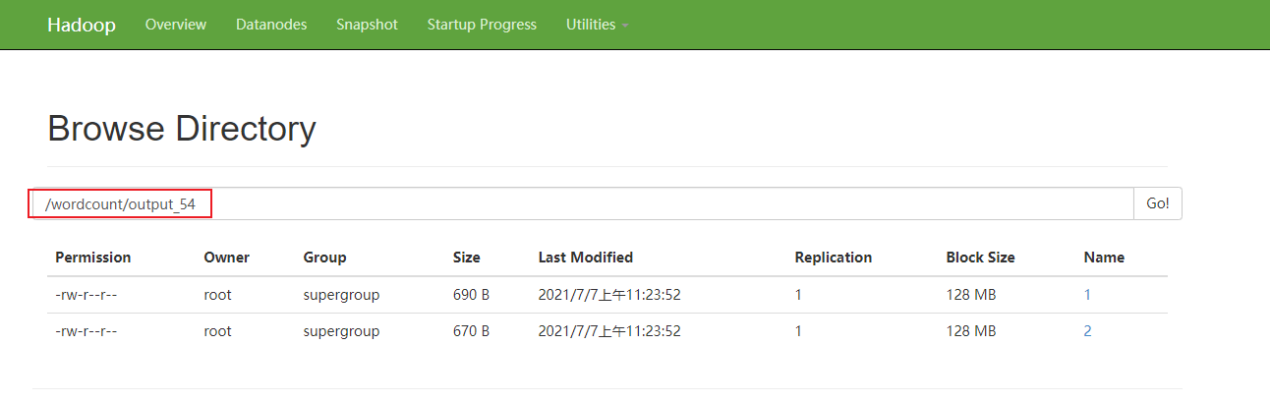
4. 注意
如果使用的是flink on yarn方式,想切换回standalone模式的话,需要删除文件:【/tmp/.yarn-properties-root】
因为默认查找当前yarn集群中已有的yarn-session信息中的jobmanager
如果是分离模式运行的YARN JOB后,其运行完成会自动删除这个文件
但是会话模式的话,如果是kill掉任务,其不会执行自动删除这个文件的步骤,所以需要我们手动删除这个文件。

- 点赞
- 收藏
- 关注作者
评论(0)