Flink 实例:Flink 流处理程序编程模型

在深入了解 Flink 实时数据处理程序的开发之前,先通过一个简单示例来了解使用 Flink 的 DataStream API 构建有状态流应用程序的过程。
01、流数据类型
Flink 以一种独特的方式处理数据类型和序列化,它包含自己的类型描述符、泛型类型提取和类型序列化框架。基于 Java 和 Scala 语言,Flink 实现了一套自己的一套类型系统,它支持很多种类的类型,包括
(1) 基本类型。
(2) 数组类型。
(3) 复合类型。
(4) 辅助类型。
(5) 通用类型。
详细的 Flink 类型系统如图 1 所示。
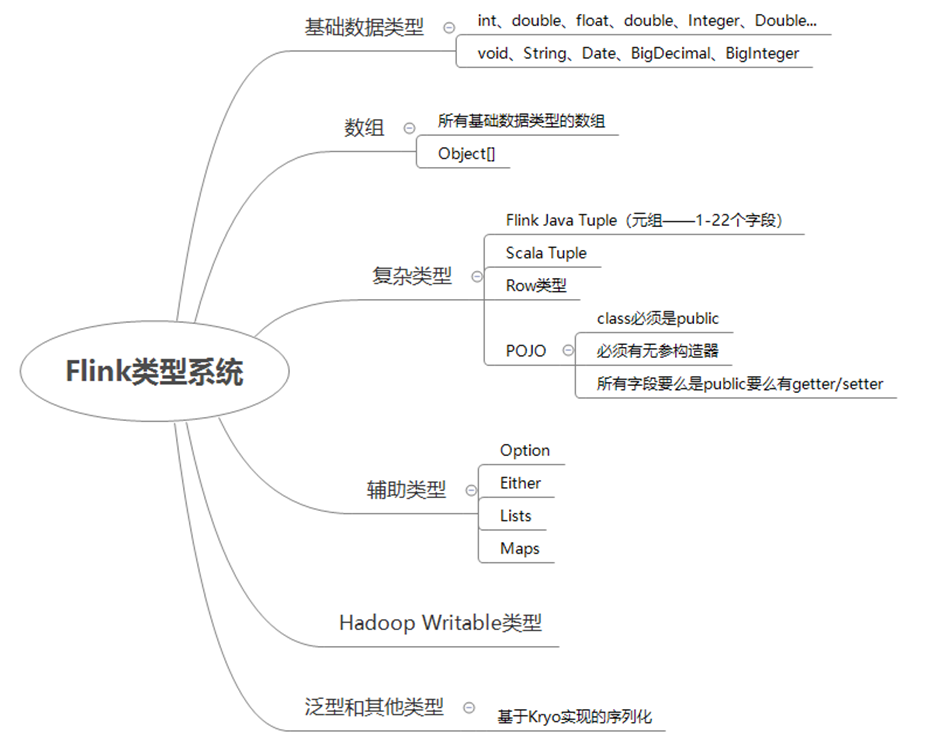
■ 图 1 Flink 类型系统
Flink 针对 Java 和 Scala 的 DataStream API 要求流数据的内容必须是可序列化的。Flink 内置了以下类型数据的序列化器:
(1) 基本数据类型:String、Long、Integer、Boolean、Array。
(2) 复合数据类型:Tuple、POJO、Scala case class。
对于其他类型,Flink 会返回 Kryo。也可以在 Flink 中使用其他序列化器。Avro 尤其得到了很好的支持。
1.java DataStream API 使用的流数据类型
对于 Java API,Flink 定义了自己的 Tuple1 到 Tuple25 类型来表示元组类型,代码如下:
Tuple2<String, Integer> person = new Tuple2<>("王老五", 35);
//索引基于0
String name = person.f0;
Integer age = person.f1;在 Java 中,POJO(plain old Java Object)是这样的 Java 类:
(1) 有一个无参的默认构造器。
(2) 所有的字段要么是 public 的,要么有一个默认的 getter 和 setter。
例如,定义一个名为 Person 的 POJO 类,代码如下:
2.Scala DataStream API 使用的流数据类型
对于元组,使用 Scala 自己的 Tuple 类型就好,代码如下:
对于对象类型,使用 case class(相当于 Java 中的 JavaBean),代码如下:
3.Flink 类型系统
对于创建的任意一个 POJO 类型,看起来它是一个普通的 Java Bean,在 Java 中,可以使用 Class 来描述该类型,但其实在 Flink 引擎中,它被描述为 PojoTypeInfo,而 PojoTypeInfo 是 TypeInformation 的子类。
TypeInformation 是 Flink 类型系统的核心类。Flink 使用 TypeInformation 来描述所有 Flink 支持的数据类型,就像 Java 中的 Class 类型一样。每种 Flink 支持的数据类型都对应的是 TypeInformation 的子类。例如 POJO 类型对应的是 PojoTypeInfo、基础数据类型数组对应的是 BasicArrayTypeInfo、Map 类型对应的是 MapTypeInfo、值类型对应的是 ValueTypeInfo。
除了对类型的描述,TypeInformation 还提供了序列化的支持。在 TypeInformation 中有一种方法:createSerializer 方法,它用来创建序列化器,序列化器中定义了一系列的方法,其中,通过 serialize 和 deserialize 方法,可以将指定类型进行序列化,并且 Flink 的这些序列化器会以稠密的方式来将对象写入内存中。Flink 中也提供了非常丰富的序列化器。在我们基于 Flink 类型系统支持的数据类型进行编程时,Flink 在运行时会推断出数据类型的信息,我们在基于 Flink 编程时,几乎是不需要关心类型和序列化的。
4.类型与 Lambda 表达式支持
在编译时,编译器能够从 Java 源代码中读取完整的类型信息,并强制执行类型的约束,但生成 class 字节码时,会将参数化类型信息删除。这就是类型擦除。类型擦除可以确保不会为泛型创建新的 Java 类,泛型是不会产生额外的开销的。也就是说,泛型只是在编译器编译时能够理解该类型,但编译后执行时,泛型是会被擦除掉的。
为了全球说明,请看下面的代码:
以上是一段 Java 的泛型方法,但在编译后,编译器会将未绑定类型的 T 擦除掉,替换为 Object。也就是编译之后的代码如下:
泛型只是能够防止在运行时出现类型错误,但运行时会出现以下异常,而且 Flink 以非常友好的方式提示:
就是因为 Java 编译器类型擦除的原因,所以 Flink 根本无法推断出来算子(例如 flatMap)要输出的类型是什么,所以在 Flink 中使用 Lambda 表达式时,为了防止因类型擦除而出现运行时错误,需要指定 TypeInformation 或者 TypeHint。
创建 TypeInformation,代码如下:
创建 TypeHint,代码如下:
02、流应用程序实现
Flink 程序的基本构建块是 stream 和 transformation(流和转换)。从概念上讲,stream 是数据记录的流(可能永远不会结束),transformation 是一个运算,它接受一个或多个流作为输入,经过处理/计算后生成一个或多个输出流。
下面实现一个完整的、可工作的 Flink 流应用程序示例。
【示例 1】将有关人员的记录流作为输入,并从中筛选出未成年人信息。
Scala 代码如下:
(1) 在 IntelliJ IDEA 中创建一个 Flink 项目,使用 flink-quickstart-scala 项目模板
(2) 设置依赖。在 pom.xml 文件中添加如下依赖内容:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.12</artifactId>
<version>1.13.2</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.12</artifactId>
<version>1.13.2</version>
<scope>provided</scope>
</dependency>(3) 创建主程序 StreamingJobDemo1,编辑流处理代码如下:
执行以上代码,输出结果如下:
Java 代码如下:
(1) 在 IntelliJ IDEA 中创建一个 Flink 项目,使用 flink-quickstart-Java 项目模板
(2) 设置依赖。在 pom.xml 文件中添加如下依赖内容:
(3) 创建一个 POJO 类,用来表示流中的数据,代码如下:
(4) 打开项目中的 StreamingJob 对象文件,编辑流处理代码如下:
(5) 执行以上程序,输出结果如下。
注意/
Flink 将批处理程序作为流程序的一种特殊情况执行,其中流是有界的(有限数量的元素)。DataSet 在内部被视为数据流,因此,上述概念同样适用于批处理程序,也适用于流程序,只有少数例外:
(1) 批处理程序的容错不使用检查点。错误恢复是通过完全重放流实现的,这使恢复的成本更高,但是因为它避免了检查点,所以使常规处理更轻量。
(2) DataSet API 中的有状态运算使用简化的 in-memory/out-of-核数据结构,而不是 key-value 索引。
(3) DataSet API 引入了特殊的同步(基于 superstep)迭代,这只可能在有界流上实现。
03、流应用程序剖析
所有的 Flink 应用程序都以特定的步骤来工作,这些工作步骤如图 2 所示。

■ 图 2 Flink 应用程序工作步骤
也就是说,每个 Flink 程序都由相同的基本部分组成:
(1) 获取一个执行环境。
(2) 加载/创建初始数据。
(3) 指定对该数据的转换。
(4) 指定计算结果放在哪里。
(5) 触发程序执行。
1.获取一个执行环境
Flink 应用程序从其 main()方法中生成一个或多个 Flink 作业(job)。这些作业可以在本地 JVM(LocalEnvironment)中执行,也可以在具有多台机器的集群的远程设置中执行(RemoteEnvironment)。对于每个程序,ExecutionEnvironment 提供了控制作业执行(例如设置并行性或容错/检查点参数)和与外部环境交互(数据访问)的方法。
每个 Flink 应用程序都需要一个执行环境(本例中为 env)。流应用程序需要的执行环境使用的是 StreamExecutionEnvironment。为了开始编写 Flink 程序,用户首先需要获得一个现有的执行环境,如果没有,就需要先创建一个。根据目的不同,Flink 支持以下几种方式:
(1) 获得一个已经存在的 Flink 环境。
(2) 创建本地环境。
(3) 创建远程环境。
Flink 流程序的入口点是 StreamExecutionEnvironment 类的一个实例,它定义了程序执行的上下文。StreamExecutionEnvironment 是所有 Flink 程序的基础。可以通过一些静态方法获得一个 StreamExecutionEnvironment 的实例,代码如下:
要获得执行环境,通常只需调用 getExecutionEnvironment()方法。这将根据上下文选择正确的执行环境。如果正在 IDE 中的本地环境上执行,则它将启动一个本地执行环境。如果是从程序中创建了一个 JAR 文件,并通过命令行调用它,则 Flink 集群管理器将执行 main()方法,getExecutionEnvironment()将返回用于在集群上以分布式方式执行程序的执行环境。
在上面的示例程序中,使用以下语句来获得流程序的执行环境。
Scala 代码如下:
Java 代码如下:
StreamExecutionEnvironment 包含 ExecutionConfig,可使用它为运行时设置特定于作业的配置值。例如,如果要设置自动水印发送间隔,可以像下面这样在代码进行配置。
Scala 代码如下:
Java 代码如下:
2.加载/创建初始数据
执行环境可以从多种数据源读取数据,包括文本文件、CSV 文件、Socket 套接字数据等,也可以使用自定义的数据输入格式。例如,要将文本文件读取为行序列,代码如下:
数据被逐行读取内存后,Flink 会将它们组织到 DataStream 中,这是 Flink 中用来表示流数据的特殊类。
在示例程序【示例 1】中,使用 fromElements()方法读取集合数据,并将读取的数据存储为 DataStream 类型。
Scala 代码如下:
Java 代码如下:
3.对数据进行转换
每个 Flink 程序都对分布式数据集合执行转换。Flink 的 DataStream API 提供了多种数据转换功能,包括过滤、映射、连接、分组和聚合。例如,下面是一个 map 转换应用,通过将原始集合中的每个字符串转换为整数来创建一个新的 DataStream,代码如下:
在示例程序【示例 1】中使用了 filter 过滤转换,将原始数据集转换为只包含成年人信息的新 DataStream 流,代码如下:
Scala 代码如下:
Java 代码如下:
这里不必了解每个转换的具体含义,后面我们会详细介绍它们。需要强调的是,Flink 中的转换是惰性的,在调用 sink 操作之前不会真正执行。
4.指定计算结果放在哪里
一旦有了包含最终结果的 DataStream,就可以通过创建接收器(sink)将其写入外部系统。例如,将计算结果打印输出到屏幕上。
Scala 代码如下:
Java 代码如下:
Flink 中的接收器(sink)操作触发流的执行,以生成程序所需的结果,例如将结果保存到文件系统或将其打印到标准输出。上面的示例使用 adults.print()将结果打印到任务管理器日志中(在 IDE 中运行时,任务管理器日志将显示在 IDE 的控制台中)。这将对流的每个元素调用其 toString()方法。
5.触发流程序执行
一旦写好了程序处理逻辑,就需要通过调用 StreamExecutionEnvironment 上的 execute()来触发程序执行。所有的 Flink 程序都是延迟执行的:当程序的主方法执行时,数据加载和转换不会直接发生,而是创建每个运算并添加到程序的执行计划中。当执行环境上的 execute()调用显式触发执行时,这些操作才实际上被执行。程序是在本地执行还是提交到集群中执行取决于 ExecutionEnvironment 的类型。
延迟计算可以让用户构建复杂的程序,然后 Flink 将其作为一个整体计划的单元执行。在示例程序【示例 1】中,使用如下代码来触发流处理程序的执行。
Scala 代码如下:
Java 代码如下:
在应用程序中执行的 DataStream API 调用将构建一个附加到 StreamExecutionEnvironment 的作业图(Job Graph)。调用 env.execute()时,此图被打包并发送到 Flink Master,该 Master 并行化作业并将其片段分发给 TaskManagers 以供执行。作业的每个并行片段将在一个 task slot(任务槽)中执行,如图 3 所示。

■图 3 Flink 流应用程序执行原理
这个分布式运行时要求 Flink 应用程序是可序列化的。它还要求集群中的每个节点都可以使用所有依赖项。
StreamExecutionEnvironment 上的 execute()方法将等待作业完成,然后返回一个 JobExecutionResult,其中包含执行时间和累加器结果。注意,如果不调用 execute(),应用程序将不会运行。
如果不想等待作业完成,可以通过调用 StreamExecutionEnvironment 上的 executeAysnc()来触发异步作业执行。它将返回一个 JobClient,可以使用它与刚才提交的作业进行通信。例如,下面的示例代码演示了如何通过 executeAsync()实现 execute()的语义。
Scala 代码如下:
Java 代码如下:

- 点赞
- 收藏
- 关注作者
评论(0)