深度学习基础:9.复现经典网络:LeNet5与AlexNet

【摘要】
LeNet5
1998年, LeNet5 被LeCun等人在论文《Gradient-Based Learning Applied to Document Recognition》中正式提出,它被认为是现...
LeNet5
1998年, LeNet5 被LeCun等人在论文《Gradient-Based Learning Applied to Document Recognition》中正式提出,它被认为是现代卷积神经网络的奠基者。
网络结构图:

import torch
from torch import nn
from torch.nn import functional as F
class Model(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 6, 5) # (H+2p-K)/S + 1
self.pool1 = nn.AvgPool2d(kernel_size=2, stride=2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.pool2 = nn.AvgPool2d(2)
self.fc1 = nn.Linear(5 * 5 * 16, 120)
self.fc2 = nn.Linear(120, 84)
def forward(self, x):
x = torch.tanh(self.conv1(x))
x = self.pool1(x)
x = torch.tanh(self.conv2(x))
x = self.pool2(x)
x = x.view(-1, 5 * 5 * 16)
x = torch.tanh(self.fc1(x))
output = F.softmax(self.fc2(x), dim=1) # (samples, features)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
使用模型可视化工具torchinfo可以模拟输入,查看模型信息。
from torchinfo import summary
net = Model()
summary(net, input_size=(10, 1, 32, 32))
- 1
- 2
- 3
- 4
输出结果如图:

AlexNet
AlexNet诞生于有“视觉界奥林匹克”之称的大规模视觉识别挑战比赛ILSVRC(ImageNet Large Scale
Visual Recognition Challenge)。AlexNet出现之前,最好成绩一直由手工提取特征+支持向量机的算法获得,最低错误率为25.8%。2012年,AlexNet进入ILSVRC竞赛,一下将错误率降低到了15.3%。
相比于LeNet5,AlexNet主要做出了如下改变:
- 卷积核更小、网络更深、通道数更多
- 使用了ReLU激活函数
- 使用了Dropout层来控制模型复杂度,控制过拟合
- 引入了大量传统或新兴的图像增强技术来扩大数据集,进一步缓解过拟合。
- 使用GPU对网络进行训练
AlexNet的网络结构如图所示:

class Model(nn.Module):
def __init__(self):
super().__init__()
# 为了处理尺寸较大的原始图片,先使用11x11的卷积核和较大的步长来快速降低特征图的尺寸
# 同时,使用比较多的通道数,来弥补降低尺寸造成的数据损失
self.conv1 = nn.Conv2d(3, 96, kernel_size=11, stride=4)
self.pool1 = nn.MaxPool2d(kernel_size=3, stride=2) # overlap pooling
# 已经将特征图尺寸缩小到27x27,计算量可控,可以开始进行特征提取了
# 卷积核、步长恢复到业界常用的大小,进一步扩大通道来提取数据
self.conv2 = nn.Conv2d(96, 256, kernel_size=5, padding=2)
self.pool2 = nn.MaxPool2d(kernel_size=3, stride=2)
# 疯狂提取特征,连续用多个卷积层
# kernel 5, padding 2, kernel 3, padding 1 可以维持住特征图的大小
self.conv3 = nn.Conv2d(256, 384, kernel_size=3, padding=1)
self.conv4 = nn.Conv2d(384, 384, kernel_size=3, padding=1)
self.conv5 = nn.Conv2d(384, 256, kernel_size=3, padding=1)
self.pool3 = nn.MaxPool2d(kernel_size=3, stride=2)
# 进入全连接层,进行信息汇总
self.fc1 = nn.Linear(6 * 6 * 256, 4096) # 上层所有特征图上的所有像素
self.fc2 = nn.Linear(4096, 4096)
self.fc3 = nn.Linear(4096, 1000)
def forward(self, x):
x = F.relu(self.conv1(x))
x = self.pool1(x)
x = F.relu(self.conv2(x))
x = self.pool2(x)
x = F.relu(self.conv3(x))
x = F.relu(self.conv4(x))
x = F.relu(self.conv5(x))
x = self.pool3(x)
x = x.view(-1, 6 * 6 * 256) # 将数据拉平
x = F.dropout(x, p=0.5)
x = F.relu(F.dropout(self.fc1(x), p=0.5))
x = F.relu(self.fc2(x))
output = F.softmax(self.fc3(x), dim=1)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
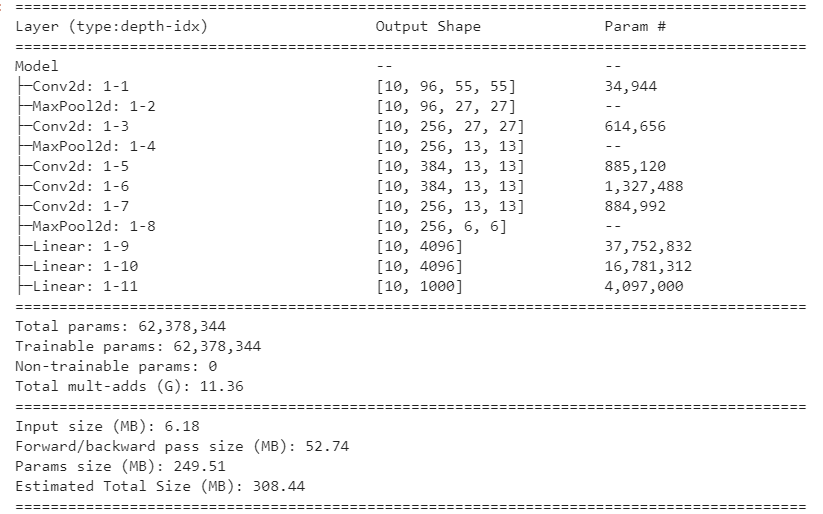
查看模型信息:
net = Model()
summary(net, input_size=(10, 3, 227, 227))
- 1
- 2
文章来源: zstar.blog.csdn.net,作者:zstar-_,版权归原作者所有,如需转载,请联系作者。
原文链接:zstar.blog.csdn.net/article/details/125782823

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)