深度学习经典网络模型汇总——LeNet、AlexNet、ZFNet、VGGNet、GoogleNet、ResNet

先来看一下我们要讲述哪些经典的网络模型,如下:
- LeNet :最早用于手写数字识别的CNN网络
- AlexNet :2012年ILSVRC比赛冠军,比LeNet层数更深,这是一个历史性突破。
- ZFNet :2013年ILSVRC比赛效果较好,和AlexNet类似。
- VGGNet :2014年ILSVRC比赛分类亚军、定位冠军
- GoogleNet :2014年ILSVRC分类比赛冠军
- ResNet :2015年ILSVRC比赛冠军,碾压之前的各种网络
LeNet
1989年,Yang LeCun等人提出了LeNet网络,这是最早的卷积神经网络,极大的推动了深度学习的发展,Yang LeCun也被称为卷积网络之父。确实,这样的大牛也该被每个科研人所记住,这里可以来看一下Yang的照片,一看就很有学问有木有👨🏼🎓👨🏼🎓👨🏼🎓👨🏼🎓👨🏼🎓
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vo1xlyGd-1643041241873)(C:\Users\WSJ\AppData\Roaming\Typora\typora-user-images\image-20220120155345041.png)]](https://img-blog.csdnimg.cn/9acfcf9321204c33b6371ebe218bd68d.png#pic_center)
好了,下面就来看看这个大能所设计的网络结构,如下图:

现在看来,这个网络是非常简单的,一共有五层(仅包含有参数的层,无参数的池化层不算在网络模型之中,之后所说的层都不包括池化层):
- 输入尺寸:32*32
- 卷积层:2个
- 池化层:2个
- 全连接层:2个
- 输出层:1个,大小为10*1
现通过下图逐一讲讲这些层:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LpRyctVz-1643117960562)(C:\Users\WSJ\AppData\Roaming\Typora\typora-user-images\image-20220120160829680.png)]](https://img-blog.csdnimg.cn/162cd73d204d4198951ede586ad1d2f1.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA56eD5aS05bCP6IuP,size_20,color_FFFFFF,t_70,g_se,x_16#pic_center)
- 输入层:LeNet的输入是32*32*1大小的灰度图(只要一个颜色通道)。
- CONV1(第一个卷积层):对大小为32*32*1的灰度图进行卷积,卷积核大小为5*5,步长s为1,卷积核个数为6,进行卷积操作后得到大小为28*28*6特征图(卷积后特征图大小不会计算的自行百度)。
- 第一个池化层:LeNet采用的是平均池化的方法,上层卷积得到的特征图尺寸为28*28*6,对此大小特征图进行池化操作。池化核大小为2*2,步长s=2,进行第一次池化后特征图大小为14*14*6(池化后特征图大小不会同样自行百度,卷积和池化得到特征图的公式基本是一致的)。
- CONV2(第二个卷积层):对池化得到的14*14*6大小的特征图进行第二次卷积,卷积核大小为5*5,步长s为1,卷积核个数为16,进行卷积后得到大小为10*10*16的特征图。
- 第二个池化层:池化核大小为2*2,步长s=2,进行第二次池化后特征图大小为5*5*16。
- 第一个全连接层:上一步得到的特征图尺寸是5*5*16,经过这层后输出大小为120*1。这一步其实有一定的迷惑性,开始接触神经网络时可能不是很理解,怎么一个三维的向量一下子就变成了一个一维的?我想看网络模型这部分的人也该对这里是比较清楚的了,但考虑到内容的完整和严谨,这里也简单说一下:其实在得到5*5*16的特征图后,还要进行一个flatten(展平)操作,即是将5*5*16的特征图展开成一个(5x5x16)*1=400*1大小的向量,然后再进入到全连接层。讲到这里应该就很清晰了,在第一个全连接层我们输入的是400个神经元,输出是120个神经元。
- 第二个全连接层:和上一层类似,输入的是120个神经元,输出的是84个神经元。
- 输出层:从得到84个神经元后,其实再经过一个全连接就得到输出,大小为10*1。
AlexNet
我们直接来看AlexNet的网络架构,如下图所示:可以看出AlexNet和LeNet的整体结构还是非常类似的,都是一系列的卷积池化操作最后接上全连接层。同样的,我们将对每层都进行详细的讲解,即是怎么通过卷积核和池化核得到相应的特征图大小的。该网络一共有8层(不包括池化),如下:
- 输入尺寸:227*227*3
- 卷积层:5个
- 池化层:3个
- 全连接层:2个
- 输出层:1个,大小为1000*1

- 输入层:AlexNet的输入是227*227*3大小的彩色图片(有三个颜色通道)
- 第一个卷积层:对大小为227*227*3的彩色图片进行卷积,卷积核大小为11*11,步长s为4,padding=0,卷积核个数为96,进行卷积后得到大小为55*55*96的特征图。
- 第一个池化层:**AlexNet采用的是最大池化的方法。上层卷积得到55*55*96的特征图,对此特征图进行最大池化操作。池化核大小为3*3,步长s为2,padding=0,经池化后特征图大小为27*27*96。
- 第二个卷积层:输入维度为27*27*96,卷积核大小为5*5,步长s为1,padding=2,卷积核个数为256,进行卷积后得到大小为27*27*256的特征图。
【注1:这里可能有人不明白了,为什么这里的步长s=1,padding=0 ?这里就设计到卷积的三种模式了,不知道的请点击传送门了解。总之,我们可以设置特定的s和padding来达到卷积前后特征图前两个维度大小不变的效果】
【注2:看到上图此步卷积时写有same,则表示卷积的方式是same mode,也即卷积前后特征图大小相同】 - 第二个池化层:输入维度为27*27*256,池化核大小为3*3,步长s为2,padding=0,经池化后特征图大小为13*13*256。
- 第三个卷积层:输入维度为13*13*256,卷积核大小为3*3,步长s为1,padding=1,卷积核个数为384,进行卷积后得到大小为13*13*384的特征图。
- 第四个卷积层:输入维度为13*13*384,卷积核大小为3*3,步长s为1,padding=1,卷积核个数为384,进行卷积后得到大小为13*13*384的特征图。
- 第五个卷积层:输入维度为13*13*384,卷积核大小为3*3,步长s为1,padding=1,卷积核个数为256,进行卷积后得到大小为13*13*256的特征图。
- 第三个池化层:输入维度为13*13*256,池化核大小为3*3,步长s为2,padding=0,经池化后特征图大小为6*6*256。
- 第一个全连接层:输入的是6*6*256=9216个神经元,输出的是4096个神经元。
- 第一个全连接层:输入的是4096个神经元,输出的是4096个神经元。
- 输出层:得到4096个神经元后,其实再经过一个全连接就得到输出,大小为1000*1。
上述已经把AlexNet各层结构给描述清楚了,但模型的一些细节没有描述,如加入了relu激活函数,加入了局部应答标准化(LRN,后再VGG中证明这步是无效的),同时也加入了Dropout层,具体的网络结构如下图。【注:下图描述的是再两台GPU上运行的结构图,是在当时算力不够的情况下减小训练时间所采用的技巧,现已不需要。】

下面总结一下AlexNet的一些创新点:
- 使用ReLU作为CNN的激活函数,并验证其效果在较深的网络超过了Sigmoid,成功解决了Sigmoid在网络较深时的梯度弥散问题,此外,加快了训练速度,因为训练网络使用梯度下降法,非饱和的非线性函数训练速度快于饱和的非线性函数。虽然ReLU激活函数在很久之前就被提出了,但是直到AlexNet的出现才将其发扬光大。
- 训练时使用Dropout随机忽略—部分神经元,以避免模型过拟合。Dropout虽有单独的论文论述,但是AlexNet将其实用化,通过实践证实了它的效果。在AlexNet中主要是最后几个全连接层使用了Dropout。
- 在CNN中使用重叠的最大池化。此前CNN中普遍使用平均池化,AlexNet全部使用最大池化,避免平均池化的模糊化效果。并且AlexNet中提出让步长比池化核的尺寸小,这样池化层的输出之间会有重叠和覆盖,提升了特征的丰富性。
- 提出了LRN层,对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。【此方法在之后的VGG中被认为是无效的】
- 使用CUDA加速深度卷积网络的训练,利用GPU强大的并行计算能力,处理神经网络训练时大量的矩阵运算。AlexNet使用了两块GTX580GPU进行训练,单个GTX580只有3GB显存,这限制了可训练的网络的最大规模。因此作者将AlexNet分布在两个GPU上,在每个GPU的显存中储存一半的神经元的参数。【现在随着算力的增强,也不太需要使用双GPU加速】
- 数据增强,随机地从256*256的原始图像中截取224*224大小的区域(以及水平翻转的镜像),相当于增加了(256*224)2*2=2048倍的数据量。如果没有数据增强,仅靠原始的数据量,参数众多的CNN会陷入过拟合中,使用了数据增强后可以大大减轻过拟合,提升泛化能力。进行预测时,则是取图片的四个角加中间共5个位置,并进行左右翻转,一共获得10张图片,对他们进行预测并对10次结果求均值。
ZFNet
ZFNet的网络结构和AlexNet的结构基本是一致的,主要的改变就是在AlexNet的第一层将卷积核的大小由11*11变成了7*7,并且将步长s由4变成了2。既然ZFNet相比于AlexNet只改变了这么点,那为什么要讲这个结构呢。这是我觉得ZFNet更宝贵的是提出了一种逆变换的思想来可视化了神经网络,将卷积核变小也是因为可视化而产生的结论,即小卷积核使网络效果更好。

VGGNet
VGGNet是牛津大学计算机视觉组(Visual Geometry Group)和Google DeepMind公司的研究员一起研发的深度卷积神经网络。VGGNet的论文中对很多的网络结构做对比(主要表现在网络的层数不同),具体如下图所示:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-V3tkXHxv-1643041241884)(https://neurohive.io/wp-content/uploads/2018/11/Capture-564x570.jpg)]](https://img-blog.csdnimg.cn/18c9050972ee4e9b8db79c0577c8321d.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA56eD5aS05bCP6IuP,size_19,color_FFFFFF,t_70,g_se,x_16#pic_center)
其中VGG-16和VGG-19较为出色(16、19指网络层数),下面以VGG-16为例,对VGG网络进行详细的介绍。首先我们可以先来看一下VGG-16的整体结构,如下图:可以看出VGG-16和AlexNet也有类似之处(网络层数变深),都是一系列卷积操作之后接上池化,最后在连接一些全连接层。

下面将用下图来逐一介绍每层之间的转化,一共16层,分别如下:
输入尺寸:224*224*3
卷积层:13个
池化层:5个
全连接层:3个 (这里已经包括了输出层,最后一个全连接层也可以说是输出层,最后的SotMax层只是做个分类)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-py1kqSVE-1643041241886)(https://media5.datahacker.rs/2019/02/vgg.png)]](https://img-blog.csdnimg.cn/46a4142400fe4412b0bde44747247951.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA56eD5aS05bCP6IuP,size_20,color_FFFFFF,t_70,g_se,x_16#pic_center)
- 输入层:VGG-16的输入是224*224*3大小的彩色图片。
- 第一个卷积层:对大小为224*224*3的图片进行卷积,卷积核大小为3*3,步长s=1,padding=1,卷积核个数为64,经卷积后得到大小为224*224*64的特征图。
- 第二个卷积层:对大小为224*224*64的图片进行卷积,卷积核大小为3*3,步长s=1,padding=1,卷积核个数为64,经卷积后得到大小为224*224*64的特征图。【注意:上图中第一次、第二次卷积是放在一起的,因为第二次卷积相对于第一次卷积特征图的维度没有变化】
- 第一个池化层:输入维度为224*224*64,池化核大小为2*2,步长s=2,padding=0,经池化核得到大小为112*112*64的特征图。
- 第三个、第四个卷积层:输入维度为112*112*64的图片进行卷积,卷积核大小为3*3,步长s=1,padding=1,卷积核个数为128,经卷积后得到大小为112*112*128的特征图。【注意:和第一个、第二个卷积一样,第四个卷积后没有改变第三次卷积后特征图的维度,这里放在了一起进行书写】
- 第二个池化层:输入维度为112*112*128,池化核大小为2*2,步长s=2,padding=0,经池化核得到大小为56*56*128的特征图。
- 第五个、第六个、第七个卷积层:输入维度为56*56*128的图片进行卷积,卷积核大小为3*3,步长s=1,padding=1,卷积核个数为256,经卷积后得到大小为56*56*256的特征图。【同样的,第六次、第七次卷积没有改变第五次卷积后的特征图的大小,故将其放在了一起】
- 第三个池化层:输入维度为56*56*256,池化核大小为2*2,步长s=2,padding=0,经池化核得到大小为28*28*256的特征图。
- 第八个、第九个、第十个卷积层:输入维度为28*28*256的图片进行卷积,卷积核大小为3*3,步长s=1,padding=1,卷积核个数为512,经卷积后得到大小为28*28*512的特征图。
- 第四个池化层:输入维度为28*28*512,池化核大小为2*2,步长s=2,padding=0,经池化核得到大小为14*14*512的特征图。
- 第十一个、第十二个、第十三个卷积层:输入维度为14*14*512的图片进行卷积,卷积核大小为3*3,步长s=1,padding=1,卷积核个数为512,经卷积后得到大小为14*14*512的特征图。
- 第五个池化层输入维度为14*14*512,池化核大小为2*2,步长s=2,padding=0,经池化核得到大小为7*7*512的特征图。
- 第一个全连接层:输入的是7*7*512=25088个神经元、输入的是4096个神经元【可以看出这里的参数众多为:25088*4096=102760448个,一亿多,VGG的绝大多数参数都在这里】
- 第二个全连接层:输入的是4096个神经元,输出的是4096个神经元。
- 第三个全连接层:输入的是4096个神经元,输出的是1000个神经元。
VGG相较与AlexNet的改进如下:
- 主要的区别,更深,把网络层数加到了16-19层(不包括池化和softmax层),而AlexNet是8层结构。
- 将卷积层提升到卷积块的概念。卷积块有2~3个卷积层构成,使网络有更大感受野的同时能降低网络参数,同时多次使用ReLu激活函数有更多的线性变换,学习能力更强。
- 前面的Conv占用大量的memory,后面的FC占用大量的参数,最多的集中在第一个全连接层,使得最终参数多达138M个。
- 取消LRN,因为实际发现使用LRN,反而降低功效。
GoogleNet
GoogleNet是2014年ILSVRC分类比赛冠军 ,在介绍完整的GoogleNet的网络结构之前,我们先来介绍其子结构——Inception,GoogleNet就是由这样的一个个Inception组成的。Inception结构如下:
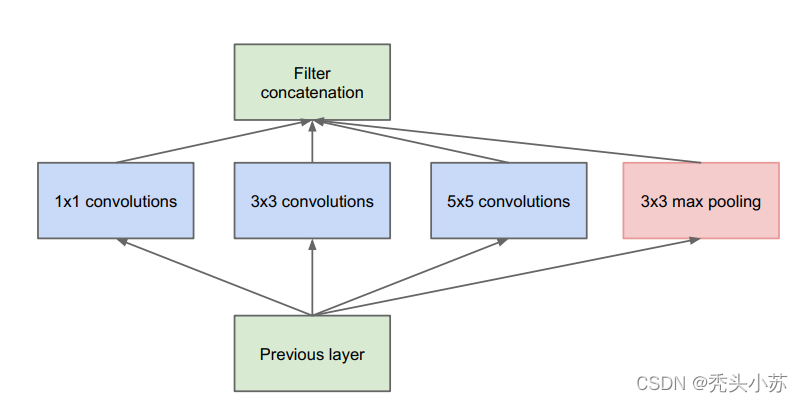
可以看出,Inception结构将原始的图像进行了三种不同大小的卷积操作及一次池化操作,然后将四次操作得到的特征图结合在一些得到一个大的特征图。这样的拼接操作可以融合不同尺度的特征,最后的特征图包含不同感受野的信息。【注意:这里的卷积池化操作得到的一个特征图的大小必须是一样的,这样才可以将它们拼接在一起,这就要求需要设置不同的步长s和padding,y以达到输入输出前后特征图大小一致的效果(这里再插一句,往往用3*3的卷积核进行卷积,则采用s=1,padding=0可使输入输出前后特征图大小不变;对应5*5的卷积核,则需要设置s=1,padding=2)】
在GoogleNet的论文中对上图的Inception结构进行了改善,即在3x3和5x5的过滤器前面,maxpooling后分别加上了1x1的卷积核,因为这样可以大大减少参数量。结构如下图所示:
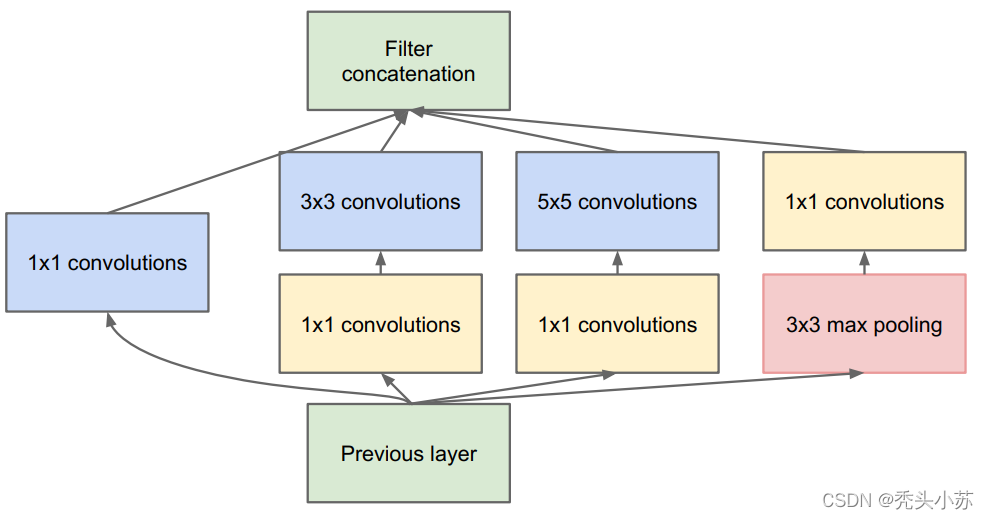
对于为什么加上1x1的卷积之后,参数量变少了,我们给出以下解释【拿之前的5*5的卷积和后面的加上1*1的卷积举例】
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-reZbkdGa-1643041241891)(C:\Users\WSJ\AppData\Roaming\Typora\typora-user-images\image-20220123212206825.png)]](https://img-blog.csdnimg.cn/a65eea2f07e84393b1f184afbe6d599e.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA56eD5aS05bCP6IuP,size_20,color_FFFFFF,t_70,g_se,x_16#pic_center)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5ZyJfUuF-1643041241893)(C:\Users\WSJ\AppData\Roaming\Typora\typora-user-images\image-20220123212253693.png)]](https://img-blog.csdnimg.cn/43a4c69ac3754abcb2836ec28c5d8f4d.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA56eD5aS05bCP6IuP,size_20,color_FFFFFF,t_70,g_se,x_16#pic_center)
通过上图可以很明显的发现:当加入1x1的卷积后参数大大减少了。
在解释了Inception模块后,GoogleNet的结构就很清晰了,主要由9个Inception模块,如下图所示:【需要注意的是在网络中4a和4d模块增加了2个额外的softmax层,但是这部分在网络测试过程中是不需要的】
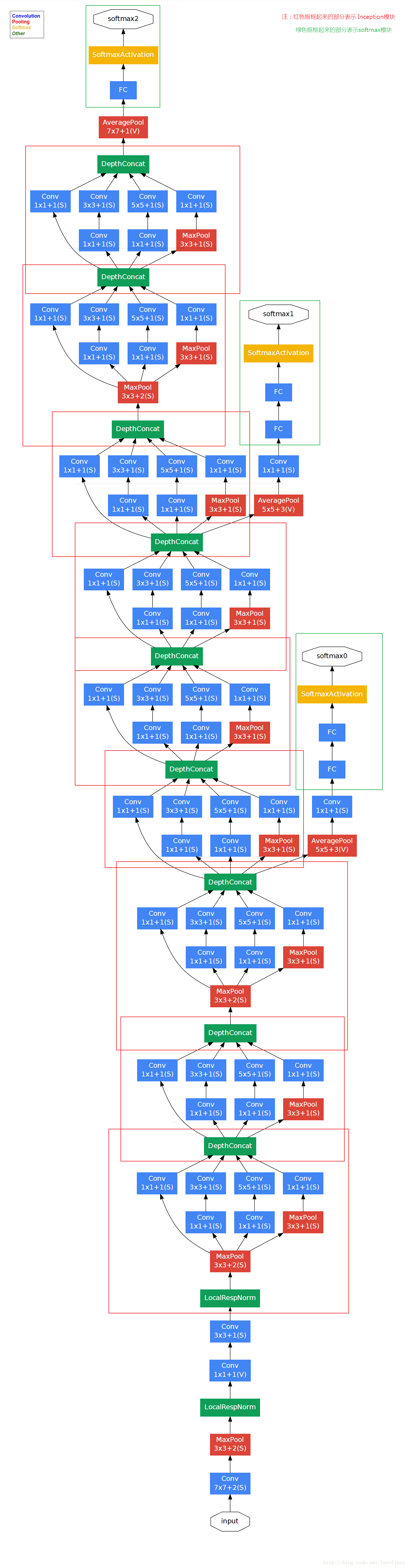
这部分就不解释每一步的特征图变化了(实在太多了😭😭😭)我相信前面的大家会了的话,这里是很容易推导的!!!方便大家推导,再附上论文中自带的每次输入输出变化的情况图表,如下图所示:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eml6YH4f-1643041241896)(C:\Users\WSJ\AppData\Roaming\Typora\typora-user-images\image-20220123213542874.png)]](https://img-blog.csdnimg.cn/4ae7eaf418624c2389bbf7ee3edfda36.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA56eD5aS05bCP6IuP,size_20,color_FFFFFF,t_70,g_se,x_16#pic_center)
这个图开始看可能不是很懂,这里给出论文中的解释就会明白了,如下图所示:【注意:上表中param表示需要参数的量,但我计算的结果(也找了一些资料验证)表明上表结果是不正确的,大家也可以算算看!!!】
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-g8sksQmj-1643041241897)(C:\Users\WSJ\AppData\Roaming\Typora\typora-user-images\image-20220123214206917.png)]](https://img-blog.csdnimg.cn/ad0c743c1d38450dbdac097a7227b432.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA56eD5aS05bCP6IuP,size_20,color_FFFFFF,t_70,g_se,x_16#pic_center)
ResNet
ResNet是2015年ILSVRC比赛冠军,在分类识别定位等各个赛道碾压之前的各种网络。重点是他的作者是中国人,何恺明大神!!!
我们先来谈谈之前深度学习网络中普遍存在的问题——随着网络层数的加深,网络训练结果并不能得到提升,反而会发生下降的问题,这种现象被称之为网络退化问题。具体可以参照下图,可以发现不管是在训练集还是在测试集,传统的网络层数增加后,错误率反而变大了。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2ULScGA9-1643041241899)(C:\Users\WSJ\AppData\Roaming\Typora\typora-user-images\image-20220124234411326.png)]](https://img-blog.csdnimg.cn/ccb0dce4358b4c8c93918ee451948ee7.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA56eD5aS05bCP6IuP,size_20,color_FFFFFF,t_70,g_se,x_16#pic_center)
当发生网络退化问题后,人们一度认为深度学习就到这里为止了,直到ResNet的出现才解决了这一问题。ResNet的核心就是残差模块,下面主要来讲讲残差模块的设计。
在原论文中,残差路径可以大致分成2种,一种有bottleneck结构,即下图右中的1×11×1 卷积层,用于先降维再升维,主要出于降低计算复杂度的现实考虑,称之为“bottleneck block”,另一种没有bottleneck结构,如下图左所示,称之为“basic block”。basic block由2个3×33×3卷积层构成。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JoJopJBN-1643041241900)(C:\Users\WSJ\AppData\Roaming\Typora\typora-user-images\image-20220124235604681.png)]](https://img-blog.csdnimg.cn/f7454984d0eb4e03bb71502e2223cdde.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA56eD5aS05bCP6IuP,size_20,color_FFFFFF,t_70,g_se,x_16#pic_center)
其实ResNet最主要的就是上图的残差模块,上图会涉及到一个什么残差映射函数,F(x),H(x),我想看过ResNet的都知道有这么一回事,但是为什么是这样设计的可能都不是很清楚,我也没有弄明白这一块,网上也感觉说不清这回事,让我想到程序员就是炼丹师这句话,的确啊,有的神经网络里面的东西很奇妙,你不知道为什么!!!这里我就放上一个链接吧,看能不能看明白。ResNet详解——通俗易懂版。
至于ResNet全部的结构如下:【以34层的作为代表】

其实搞明白我前文所说的那几种网络结构,知道了ResNet的残差模块,上图结构是很容易看懂的,都是一些残差模块的整合!!!
🥺🥺🥺好吧,感觉每次写到最后都会有一点偷懒,也许是最后的内容就自以为大家有了前面的基础了,就写的少了【好吧,是借口】太晚了,晚安🛌🏼🛌🏼🛌🏼
咻咻咻咻~~duang~~点个赞呗

- 点赞
- 收藏
- 关注作者
评论(0)