【特征提取】基于matlab共振峰估计【含Matlab源码 550期】

一、获取代码方式
获取代码方式1:
通过订阅紫极神光博客付费专栏,凭支付凭证,私信博主,可获得此代码。
获取代码方式2:
完整代码已上传我的资源:【特征提取】基于matlab共振峰估计【含Matlab源码 550期】
备注:
订阅紫极神光博客付费专栏,可免费获得1份代码(有效期为订阅日起,三天内有效);
二、共振峰估计简介
声道可以看成是一根具有非均匀截面的声管,在发音时起共鸣器的作用。当准周期脉冲激励进入声道时会引起共振特性,产生一组共振频率,称为共振峰频率或简称共振峰。共振峰参数包括共振峰频率和频带宽度,它是区别不同韵母的重要参数。共振峰信息包含在语音频谱包络中,因此共振峰参数提取的关键是估计自然语音频谱包络,并认为谱包络中的最大值就是共振峰。
与基音提取类似,精确的共振峰估值也是很困难的。存在的问题包括以下几方面:
1)虚假峰值。在正常情况下,频谱包络中的最大值完全是由共振峰引起的,但也会出现虚假峰值。一般,在利用非线性预测分析方法的频谱包络估值器中,出现虚假峰值情况较
多,而在采用线性预测方法时,出现虚假峰值情况较少。
2)共振峰合并。相邻共振峰的频率可能会靠得太近难以分辨,而寻找一种理想的能对共振峰合并进行识别的共振峰提取算法有不少实际困难。
3)高音调语音。传统的频谱包络估值方法是利用由谐波峰值提供的样点,而高音调语音(如女声和童声)的谐波间隔比较宽,因而为频谱包络估值所提供的样点比较少。利用线性预测进行频谱包络估值也会出现这个问题,在高音调语音中,线性预测包络峰值趋向于离开真实位置而朝着最接近的谐波峰值移动。
1 带通滤波器组法
这种方法类似于语谱仪,但由于使用了计算机,使滤波器特性的选取更具灵活性,实现
框图示于图5-31中。这是共振峰提取的最早形式,与线性预测法相比,滤波器组法性能较
差。但通过滤波器组的设计可以使估计的共振峰頻率同人耳的灵敏度相匹配,其匹配的程度比线性预测法要好。
滤波器的中心频率有两种分布方法:一种是等间距地分布在分析频段上,即所有带通滤波器的带宽相同,从而保证了各通道的群延时相同;另一种是非均匀地分布,例如为了获得类似于人耳的频率分辨特性,在低频端间距小,高频端间距大,带宽也随之增加,这时滤波器的阶数必须设计成与带宽成正比,使得它们输出的群延时相同,不会产生波形失真。
为了使频率分辨率提高,滤波器的阶数应取足够大的值,使得带通滤波器具有良好的截
止特性,但同时也意味着每个滤波器均有较长的冲激响应。由于语音信号具有时变特性,显然较长的冲激响应会模拟这种特性,所以频率分辨率与时间分辨率总是相互矛盾的。带通滤波器组的方法可以实现较高的时间分辨率,故常用它来分析共振峰的走向。
图5-16为利用滤波器组进行共振峰估值的一种系统结构示意图。滤波器的中心频率为
150Hz~7kHz, 分析带宽为100Hz~1kHz, 频率按对数规律递增。滤波器输出经全波整流而用于提供频谱包络估值。辨识逻辑用于对适当频率范围内的峰值进行辨识而获得前三个共振峰。频谱峰值被依次指定,每一峰值都被约束在其已知的频率范围之内并且高于前面共振峰的频率。

2 倒谱法
虽然可以直接对语音信号求离散傅里叶变换(DFT) , 然后用DFT谱来提取语音信号的共振峰参数。但是, DFT的谱要受基频谐波的影响, 最大值只能出现在谐波频率上, 因而共振峰测定误差较大。为了消除基频谐波的影响,可以采用同态解卷技术。经过同态滤波后得到的谱较平滑,此时简单地检测峰值就可以直接提取共振峰参数,因此该方法更为有效和精确。因为倒谱运用对数运算和二次变换可将基音谐波和声道的频谱包络分离开来,因此用低时窗l(n)可从语音信号倒谱c(n)中截取出h(n),能更精确地反映声道响应。由h(n)经
DFT得到的H(k) , 就是声道的离散谱曲线。用H(k) 代替直接DFT的频谱, 可以去除激励引起的谐波波动,从而更精确地得到共振峰参数。
图5-17为倒谱法求取语音频谱包络的原理图。实验表明,倒谱法因为其频谱曲线的波动比较小,所以估计的共振峰参数较精确,但其运算量太大。

3 线性预测法
从线性预测导出的声道滤波器是频谱包络估计器的最新形式,线性预测提供了一个优良
的声道模型(条件是语音不含噪声)。尽管线性预测法的频率灵敏度和人耳不相匹配,但它
仍是最高效的方法之一。用线性预测可对语音信号进行解卷,即把激励分量归人预测残差
中,得到声道响应的全极模型H(:)的分量,从而得到这个分量的a,参数。尽管其精度由于存在一定的逼近误差而有所降低,但去除了激励分量的影响。此时求出声道响应分量的谱峰,就可以求出共振峰。常用的方法有两种:求根法和内插法。
(1)求根法是用标准的求取复根的方法计算全极模型分母多项式A(z)的根,其优点在于通过对预测多项式系数的分解可以精确地决定共振蜂的中心频率和带宽。找出多项式复根的过程通常采用牛顿一拉夫逊算法。算法步骤为首先猜测一个根值并就此猜测值计算多项式及其导数的值,然后利用结果再找出一个改进的猜测值。当前后两个猜测值之差小于某门限时结束猜测过程。由上述过程可知,重复运算找出复根的计算量相当可观。但是,假设每一帧的最初猜测值与前一帧的根的位置重合,那么根的帧到帧的移动足够小,经过较少的重复运算后,可使新的根的值汇聚在一起。初始化时,第一顿的猜测值可以在单位圆上等间隔设置。
设:=r,e为第一个根,则其共轭值z,=r,e也是一个根,与i对应的共振峰频率为F,3dB带宽为B,,则它们存在下面的关系:
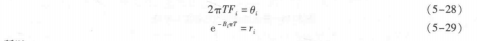
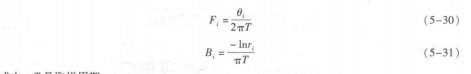
式中,T是取样周期。
因为预测器阶数p是预先选定的,所以复共轭对的数量最多是p/2。因而在判断某一个极点属于哪一个共振峰的问题就不太复杂。而且,不属于共振峰的额外极点容易排除掉,因为其带宽比共振峰带宽要大得多

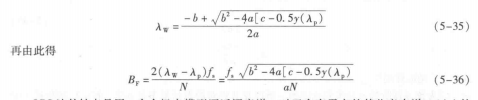
LPC法的缺点是用一个全极点模型逼近语音谱, 对于含有零点的某些音来说, A(x) 的根反映了极零点的复合效应,无法区分这些根是相应于零点还是极点,或完全与声道的谐振极点有关。
三、部分源代码
clear all; clc; close all;
waveFile='手放开.wav'; %
[x, fs]=audioread(waveFile); %
- 1
- 2
- 3
- 4
- 5
四、运行结果



五、matlab版本及参考文献
1 matlab版本
2014a
2 参考文献
[1]韩纪庆,张磊,郑铁然.语音信号处理(第3版)[M].清华大学出版社,2019.
[2]柳若边.深度学习:语音识别技术实践[M].清华大学出版社,2019.
文章来源: qq912100926.blog.csdn.net,作者:海神之光,版权归原作者所有,如需转载,请联系作者。
原文链接:qq912100926.blog.csdn.net/article/details/114972064

- 点赞
- 收藏
- 关注作者
评论(0)