【语音识别】基于matlab GUI MFCC+VAD端点检测智能语音门禁系统【含Matlab源码 451期】

一、MFCC简介
1 引言
语音识别是一种模式识别, 就是让机器通过识别和理解过程把语音信号转变为相应的文本或命令的技术。语音识别技术主要包括特征提取技术、模式匹配准则及模型训练技术3个方面。目前一些语音识别系统的适应性比较差, 主要体现在对环境依赖性强, 因此要提高系统鲁棒性和自适应能力。支持向量机 (Support Vector Machine, SVM) 是基于统计学理论发展起来的新的机器学习方法, 采用将数据从低维空间映射到高维空间的思想, 由支持向量来决定最优分割线, SVM先自动找出对分类有较好区分能力的支持矢量, 然后构造出分类器来最大化类与类的间隔, 因此有较好的适应能力和较高的分准率。
本文在现有语音识别技术基础上, 提出一种MFCC (Mel Frequency Cepstrum Coefficients, Mel频率倒谱系数) +SVM的语音识别方法, 实现对几种英文单词的分类。实验结果表明, 该识别方法具有较高的准确率。
2 语音识别系统
语音识别过程一般分为3个阶段:信号处理、特征提取和模式识别, 如图1所示。

图1 语音识别系统原理
3 MFCC特征提取
特征提取是数据挖掘和模式识别中的一个重要步骤。其目的是从原有特征数据中提取出与特定任务, 如分类、压缩、识别等密切相关的新特征 (或特征子集) , 以有效地完成特定任务或进一步减少计算量。
研究者通常使用经典的特征提取技术, 如MFCC、连续小波变换 (Continuous Wavelet Transform, CWT) 和短时傅里叶变换 (Short-Time Fourier Transform, STFT) 来提取语音片段的特征。Mel频率是基于人耳听觉特性提出来的, 它与Hz频率成非线性对应关系。MFCC则是利用它们之间的这种关系, 计算得到的Hz频谱特征。由于MFCC具有良好的识别性能和抗噪能力, 在语音识别中得到广泛的使用, 而且研究人员仍在对MFCC的各种参数进行实验和调整, 并通过同其它模型的协同工作来找出提高识别率的方法。
MFCC参数的提取包括以下几个步骤 (如图2所示) :
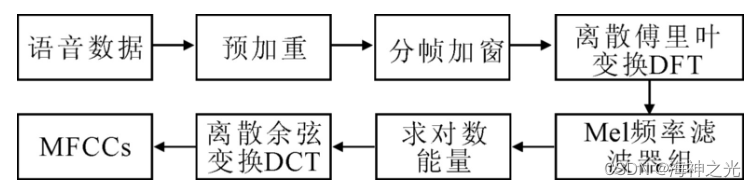
图2 MFCCs特征的提取过程
(1) 预加重。通过一个一阶有限激励响应高通滤波器, 使信号的频谱变得平坦, 不易受到有限字长效应的影响。
(2) 分帧。根据语音的短时平稳特性, 语音可以以帧为单位进行处理。n为每一帧语音采样序列的点数, 本系统取n=256。
(3) 加窗。为了减小语音帧的截断效应, 降低帧两端的坡度, 使语音帧的两端不引起急剧变化而平滑过渡, 需要让语音帧乘以一个窗函数。目前常用的窗函数是Hamming窗。
(4) 对每帧序列s (n) 进行预加重、分帧加窗后, 然后经过离散FFT变换, 将s (n) 取模的平方得到离散功率谱S (n) 。
(5) 计算S (n) 通过M个滤波器Hm (n) 后所得的功率谱, 即计算S (n) 和Hm (n) 在各离散频率点上的乘积之和, 得到M个参数Pm, m=0, 1, …, M-1。
(6) 计算Pm的自然对数, 得到Lm, m=0, 1, …, M-1。
(7) 对L0, L1, …, Lm-1计算其离散余弦变换, 得到Dm, m=0, 1, …, M-1。
(8) 舍去代表直流成分的L0, L1, …, Lm-1, 取L0, L1, …, Lm-1作为MFCC参数。
二、部分源代码
- 1
- 2
三、运行结果

四、matlab版本及参考文献
1 matlab版本
2014a
2 参考文献
[1]韩纪庆,张磊,郑铁然.语音信号处理(第3版)[M].清华大学出版社,2019.
[2]柳若边.深度学习:语音识别技术实践[M].清华大学出版社,2019.
[3] 李玲俐.一种基于MFCC和SVM的语音识别方法[J].软件导刊. 2012,11(03)
文章来源: qq912100926.blog.csdn.net,作者:海神之光,版权归原作者所有,如需转载,请联系作者。
原文链接:qq912100926.blog.csdn.net/article/details/124669577

- 点赞
- 收藏
- 关注作者
评论(0)