【语音识别】基于matlab GUI HMM中文语音识别【含Matlab源码 1385期】

一、获取代码方式
获取代码方式1:
完整代码已上传我的资源:【语音识别】基于matlab GUI HMM中文语音识别【含Matlab源码 1385期】
获取代码方式2:
通过订阅紫极神光博客付费专栏,凭支付凭证,私信博主,可获得此代码。
备注:
订阅紫极神光博客付费专栏,可免费获得1份代码(有效期为订阅日起,三天内有效);
二、隐马尔可夫模型简介
隐马尔可夫模型(Hidden Markov model, HMM)是一种结构最简单的动态贝叶斯网的生成模型,它也是一种著名的有向图模型。它是典型的自然语言中处理标注问题的统计机器学模型,本文将重点介绍这种经典的机器学习模型。
1 引言
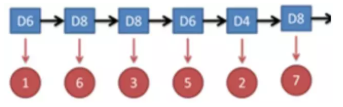
假设有三个不同的骰子(6面、4面、8面),每次先从三个骰子里面选择一个,每个骰子选中的概率为1/3,如下图所示,重复上述过程,得到一串数值[1,6,3,5,2,7]。这些可观测变量组成可观测状态链。同时,在隐马尔可夫模型中还有一条由隐变量组成的隐含状态链,在本例中即骰子的序列。比如得到这串数字骰子的序列可能为[D6, D8, D8, D6, D4, D8]。
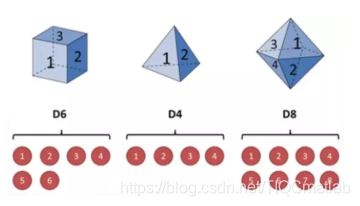
隐马尔可夫型示意图如下所示:
图中,箭头表示变量之间的依赖关系。图中各箭头的说明如下:
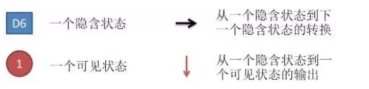
在任意时刻,观测变量(骰子)仅依赖于状态变量(哪类骰子),同时t时刻的状态qt仅依赖于t-1时刻的状态qt-1。这就是马尔科夫链,即系统的下一时刻仅由当前状态(无记忆),即“齐次马尔可夫性假设”
2 隐马尔可夫模型的定义
根据上面的例子,这里给出隐马尔可夫的定义。隐马尔科夫模型是关于时序的概率模型,描述由一个隐藏的马尔可夫链随机生成不可观测的状态随机序列,再由各个状态生成一个可观测的随机序列的过程,隐藏的马尔可夫链随机生成的状态序列,称为状态序列(也就上面例子中的D6,D8等);每个状态生成一个观测,而由此产生的观测随机序列,称为观测序列(也就上面例子中的1,6等)。序列的每个位置又可以看作是一个时刻。
隐马尔可夫模型由初始的概率分布、状态转移概率分布以及观测概率分布确定。具体的形式如下,这里设Q是所有可能的状态的集合,V是所有可能的观测的集合,即有:



3 前向算法

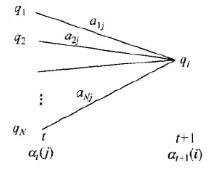
对于步骤一的初始,是初始时刻的状态i1 = q1和观测o1的联合概率。步骤(2) 是前向概率的递推公式,计算到时刻t+1部分观测序列为o1,o2,…,ot,ot+1 且在时刻t+1处于状态qi的前向概率。如上图所示,既然at(j)是得到时刻t观测到o1,o2,…,ot并在时刻t处于状态的qj前向概率,那么at(j)aji就是到时刻t观测到o1,o2,…,ot并在是时刻t处于qj状态而在时刻t+1到达qi状态的联合概率。对于这个乘积在时刻t的所有可能的N个状态求和,其结果就是到时刻t观测为o1,o2,…,ot,并在时刻t+1处于状态qi的联合概率。最后第三步,计算出P(O|lamda)的结果。
当然这里只是介绍了诸多算法中的一种,类似的还有后向算法(大家可以看相关的书籍进行了解)。对于动态规划的解决隐马尔科夫模型预测问题,应用最多的是维特比算法。
三、部分源代码
%本程序应用多窗谱法估计的语音信号功率谱密度(PSD)来进行谱减语音增强
clear;
a=2; %过减因子
b=0.01; %增益补偿因子
c=0; %c=0时,不对增益矩阵进行开方,c=1时,进行开方运算
%读取语音文件---------------------------------------------------------------
[filename,pathname]=uigetfile('SNR_0-增大.wav','请选择语音文件:');
[wavin_t,fs]=audioread([pathname filename]);
wav_length=length(wavin_t);
%基音周期最大为20ms,为使ifft还原后语音失真尽量小,帧长至少要为基音周期的2倍
%根据fs选择帧长:
% switch fs
% case 8000
% frame_len=320;step_len=160;
% case 10000
% frame_len=400;step_len=200;
% case 12000
% frame_len=480;step_len=240;
% case 16000
% frame_len=640;step_len=320;
% case 44100
% frame_len=1800;step_len=900;
% otherwise
% frame_len=1800;step_len=900;
% end;
frame_len=320;step_len=160;
frame_num=ceil((wav_length-step_len)/step_len);
wavin=zeros(1,frame_num*frame_len);
wavin(1:wav_length)=wavin_t(:);
inframe=zeros(frame_len,frame_num);
for i=1:frame_num;
inframe(:,i)=wavin(((i-1)*step_len+1):((i-1)*step_len+frame_len));
end;
%inframe=(ENFRAME(wavin,frame_len,step_len))'; %分帧
%frame_num=size(inframe,2); %求帧数
window=hamming(frame_len); %定义汉明窗
%分别对每帧fft,求幅值,求相角-----------------------------------------------
for i=1:frame_num;
fft_frame(:,i)=fft(window.*inframe(:,i));
abs_frame(:,i)=abs(fft_frame(:,i));
ang_frame(:,i)=angle(fft_frame(:,i));
end;
%每相邻三帧平滑-------------------------------------------------------------
abs_frame_f=abs_frame;
for i=2:frame_num-1;
abs_frame_f(:,i)=mean(abs_frame(:,(i-1):(i+1)),2);
end;
abs_frame=abs_frame_f;
%求增益矩阵-----------------------------------------------------------------
%矩阵中每一元素为:
%g(k)=(Py(k)-a*Pn(k))/Py(k)
%Py和Pn分别为带噪语音和噪声的功率谱估计,都用MATLAB中自带的pmtm函数来估计
%可根据需要调节a的大小,来得到更好的效果
%用多窗谱法法对每一帧数据进行功率谱估计
for i=1:frame_num;
per_PSD(:,i)=pmtm(inframe(:,i),3,frame_len,'twosided');
end;
%对功率谱的每相邻三帧进行平滑
per_PSD_f=per_PSD;
for i=2:frame_num-1;
per_PSD_f(:,i)=mean(per_PSD(:,(i-1):(i+1)),2);
end;
per_PSD=per_PSD_f;
%取前20帧作为噪声帧,取其平均作为噪声的功率谱估计
noise_PSD=mean(per_PSD(:,1:20),2);
%求增益矩阵
for k=1:frame_num;
g(:,k)=(per_PSD(:,k)-a*noise_PSD)./per_PSD(:,k);
end;
function test(hmm)
clc;
load mylabel.mat;
load myhmm.mat;
tn=98;%测试样本个数
num=length(label);%模版个数
ccount=0;%识别正确的命令个数
for i=1:tn
fname = sprintf('test\\%d.wav',i);
x = audioread(fname);
[x1 x2] = vad(x);
x=0.2*x/max(x);%幅度统一化
m = mfcc(x);
m = m(x1-2:x2-2,:);
for j=1:num
pout(j) = viterbi(hmm{j}, m);
end
[d,n] = max(pout);
%n = mod(n, 10);
fprintf('第%d个命令, 识别为%s%s\n', i,label(n,1),label(n,2));
aa=ceil(i/7);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
四、运行结果

五、matlab版本及参考文献
1 matlab版本
2014a
2 参考文献
[1]韩纪庆,张磊,郑铁然.语音信号处理(第3版)[M].清华大学出版社,2019.
[2]柳若边.深度学习:语音识别技术实践[M].清华大学出版社,2019.
文章来源: qq912100926.blog.csdn.net,作者:海神之光,版权归原作者所有,如需转载,请联系作者。
原文链接:qq912100926.blog.csdn.net/article/details/120712367

- 点赞
- 收藏
- 关注作者
评论(0)