【语音识别】基于matlab GUI智能语音识别门禁系统【含Matlab源码 596期】

一、案例简介
本文基于Matlab设计实现了一个文本相关的声纹识别系统,可以判定说话人身份。
1 系统原理
a 声纹识别
这两年随着人工智能的发展,不少手机App都推出了声纹锁的功能。这里面所采用的主要就是声纹识别相关的技术。声纹识别又叫说话人识别,它和语音识别存在一点差别。

b 梅尔频率倒谱系数(MFCC)
梅尔频率倒谱系数(Mel Frequency Cepstrum Coefficient, MFCC)是语音信号处理中最常用的语音信号特征之一。
实验观测发现人耳就像一个滤波器组一样,它只关注频谱上某些特定的频率。人耳的声音频率感知范围在频谱上的不遵循线性关系,而是在Mel频域上遵循近似线性关系。
梅尔频率倒谱系数考虑到了人类的听觉特征,先将线性频谱映射到基于听觉感知的Mel非线性频谱中,然后转换到倒谱上。普通频率转换到梅尔频率的关系式为:
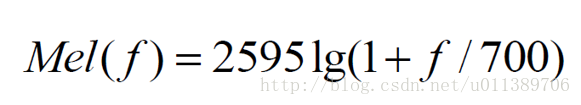
c 矢量量化(VectorQuantization)
本系统利用矢量量化对提取的语音MFCC特征进行压缩。
VectorQuantization (VQ)是一种基于块编码规则的有损数据压缩方法。事实上,在 JPEG 和 MPEG-4 等多媒体压缩格式里都有 VQ 这一步。它的基本思想是:将若干个标量数据组构成一个矢量,然后在矢量空间给以整体量化,从而压缩了数据而不损失多少信息。
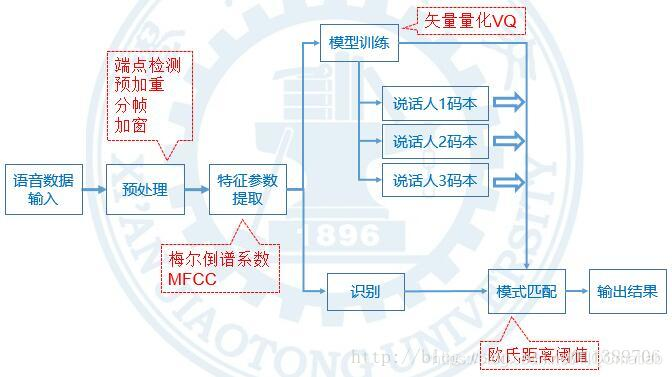
3 系统结构
本文整个系统的结构如下图:
3.1 训练过程
首先对语音信号进行预处理,之后提取MFCC特征参数,利用矢量量化方法进行压缩,得到说话人发音的码本。同一说话人多次说同一内容,重复该训练过程,最终形成一个码本库。
3.2 识别过程
在识别时,同样先对语音信号预处理,提取MFCC特征,比较本次特征和训练库码本之间的欧氏距离。当小于某个阈值,我们认定本次说话的说话人及说话内容与训练码本库中的一致,配对成功。
4 测试实验

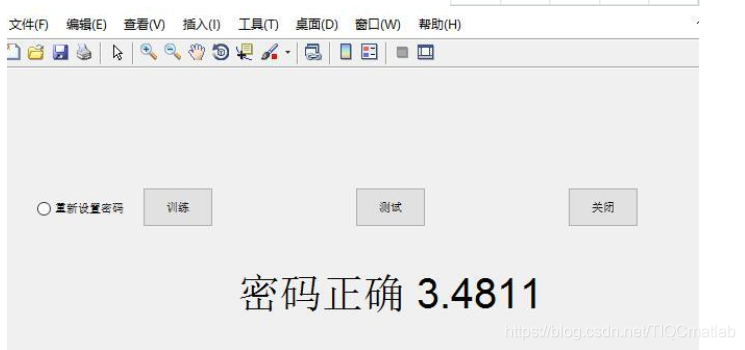
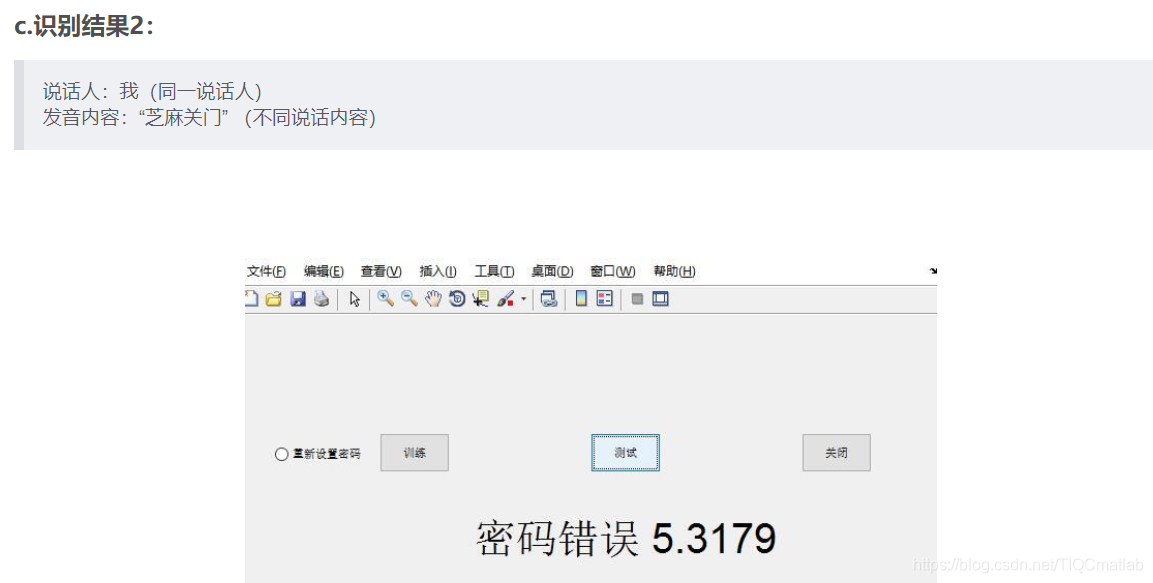
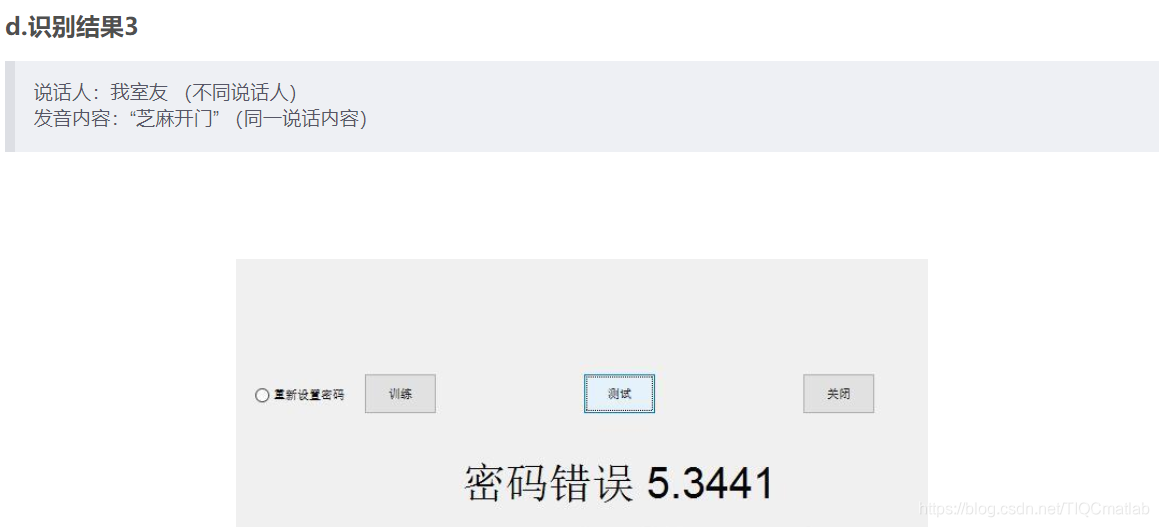
可以看到只有说话人及说话内容与码本库完全一致时才会显示“密码正确”,否则显示“密码错误”,实现了声纹锁的相关功能。
二、部分源代码
function varargout = GUI(varargin)
gui_Singleton = 1;
gui_State = struct('gui_Name', mfilename, ...
'gui_Singleton', gui_Singleton, ...
'gui_OpeningFcn', @GUI_OpeningFcn, ...
'gui_OutputFcn', @GUI_OutputFcn, ...
'gui_LayoutFcn', [] , ...
'gui_Callback', []);
if nargin && ischar(varargin{1})
gui_State.gui_Callback = str2func(varargin{1});
end
if nargout
[varargout{1:nargout}] = gui_mainfcn(gui_State, varargin{:});
else
gui_mainfcn(gui_State, varargin{:});
end
% End initialization code - DO NOT EDIT
% --- Executes just before GUI is made visible.
function GUI_OpeningFcn(hObject, eventdata, handles, varargin)
% This function has no output args, see OutputFcn.
% varargin command line arguments to GUI (see VARARGIN)
% Choose default command line output for GUI
handles.output = hObject;
% Update handles structure
guidata(hObject, handles);
% UIWAIT makes GUI wait for user response (see UIRESUME)
% uiwait(handles.figure1);
% --- Outputs from this function are returned to the command line.
function varargout = GUI_OutputFcn(hObject, eventdata, handles)
% Get default command line output from handles structure
varargout{1} = handles.output;
% --- Executes on button press in trainrec.
function trainrec_Callback(hObject, eventdata, handles)
speaker_id = trainrec();
set(handles.train_current,'string','Hurraay,DONE!');
speaker_iden = sprintf('you re speaker number %d', speaker_id);
% set(handles.speaker,'string',speaker_iden);
set(handles.access,'BackgroundColor','blue');
set(handles.access,'string','YOU HAVE ACCESS, TRAIN COMMANDS NOW!');
% if access_ == 1
% set(handles.access,'string','YOU HAVE ACCESS, TRAIN COMMANDS NOW!');
% else
% set(handles.access,'string','YOU DONT HAVE ACCESS,SPEAKER NOT RECOGNIZED!');
% end
% --- Executes on button press in command.
function command_Callback(hObject, eventdata, handles)
trai_pairs=30;
out_neurons=5;
hid_neurons=6;
in_nodes=13;
eata=0.1;emax=0.001;q=1;e=0;lamda=.7; t=1;
load backp.mat W V;
recObj = audiorecorder;
Fs=8000;
Nseconds = 1;
while(1)
fprintf('say any word immediately after hitting enter');
input('');
recordblocking(recObj, 1);
x = getaudiodata(recObj);
[kk,g] = lpc(x,12);
Z=(kk);
Z=double(Z);
p1=max(Z);
Z=Z/p1;
for p=1:trai_pairs
z=transpose(Z(p,:));
% calculate output
y=(tansig(V*(z)));
o=(tansig(W*(y)));
break
end
b=o(1);
c=o(2);
d=o(3);
e=o(4);
f=o(5);
a= max(o);
if (b==a )
display('AHEAD');
set(handles.ahead,'BackgroundColor','green');
set(handles.command,'string','Ahead');
pause(2);
elseif (c== a)
display('STOP');
set(handles.stop,'BackgroundColor','green');
set(handles.command,'string','Stop');
pause(2);
elseif (d== a)
display('BACK');
set(handles.back,'BackgroundColor','green');
set(handles.command,'string','Back');
pause(2);
elseif (e==a)
display('LEFT');
set(handles.left,'BackgroundColor','green');
set(handles.command,'string','Left');
pause(2);
elseif (f==a)
display('RIGHT');
set(handles.right,'BackgroundColor','green');
set(handles.command,'string','Right');
pause(2);
end
set(handles.ahead,'BackgroundColor','white');
set(handles.left,'BackgroundColor','white');
set(handles.right,'BackgroundColor','white');
set(handles.stop,'BackgroundColor','white');
set(handles.back,'BackgroundColor','white');
end
function traincommands()
Fs=8000;
Nseconds = 1;
samp=6;
words=5;
recObj = audiorecorder;
aheaddir = 'C:\Users\Rezetane\Desktop\HRI Proj\Speech-Recognition-master\data\train_commands\ahead\';
backdir = 'C:\Users\Rezetane\Desktop\HRI Proj\Speech-Recognition-master\data\train_commands\back\';
stopdir = 'C:\Users\Rezetane\Desktop\HRI Proj\Speech-Recognition-master\data\train_commands\stop\';
rightdir = 'C:\Users\Rezetane\Desktop\HRI Proj\Speech-Recognition-master\data\train_commands\right\';
leftdir = 'C:\Users\Rezetane\Desktop\HRI Proj\Speech-Recognition-master\data\train_commands\left\';
s_right = numel(dir([rightdir '*.wav']));
for i= 1:1:samp
filename = sprintf('%ss%d.wav', aheaddir, i);
fprintf('Reading %ss%d ',aheaddir,i);
[x,Fs] = audioread(filename);
[s(i,:),g] = lpc(x,12);
end
for i= (samp+1):1:2*samp
filename = sprintf('%ss%d.wav', stopdir, i- samp);
fprintf('Reading %ss%d ',stopdir,i);
[x,Fs] = audioread(filename);
[s(i,:),g] = lpc(x,12);
%plot(s(i,:));
end
for i= (2*samp+1):1:3*samp
filename = sprintf('%ss%d.wav', backdir, i-2*samp);
fprintf('Reading %ss%d ',backdir,i);
[x,Fs] = audioread(filename);
[s(i,:),g] = lpc(x,12);
end
for i= (3*samp+1):1:4*samp
filename = sprintf('%ss%d.wav', leftdir, i-3*samp);
fprintf('Reading %ss%d ',leftdir,i);
[x,Fs] = audioread(filename);
[s(i,:),g] = lpc(x,12);
end
for i= (4*samp+1):1:5*samp
filename = sprintf('%ss%d.wav', rightdir, i- 4*samp);
fprintf('Reading %ss%d ',rightdir,i);
[x,Fs] = audioread(filename);
[s(i,:),g] = lpc(x,12);
end
S=zeros(1,13);
for i=1:1:samp
S=cat(1,S,s(i,:));
S=cat(1,S,s(samp+i,:));
S=cat(1,S,s(2*samp+i,:));
S=cat(1,S,s(3*samp+i,:));
S=cat(1,S,s(4*samp+i,:));
end
S(1,:)=[];
save speechp.mat S
trai_pairs=30; % 48 samples
out_neurons=5; % no of words
hid_neurons=6; %matka
in_nodes=13; %features are 13
eata=0.1;emax=0.001;q=1;e=0;lamda=.7; t=1;
load speechp.mat S
p1=max(max(S));
s=S/p1;
Z= double(s);
dummy=[1 -1 -1 -1 -1;
-1 1 -1 -1 -1;
-1 -1 1 -1 -1;
-1 -1 -1 1 -1;
-1 -1 -1 -1 1];
t=trai_pairs/out_neurons;
D=dummy;
for i= 1:1:5
D=cat(1,D,dummy);
end
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
三、运行结果

四、matlab版本及参考文献
1 matlab版本
2014a
2 参考文献
[1]韩纪庆,张磊,郑铁然.语音信号处理(第3版)[M].清华大学出版社,2019.
[2]柳若边.深度学习:语音识别技术实践[M].清华大学出版社,2019.
文章来源: qq912100926.blog.csdn.net,作者:海神之光,版权归原作者所有,如需转载,请联系作者。
原文链接:qq912100926.blog.csdn.net/article/details/115054253

- 点赞
- 收藏
- 关注作者
评论(0)