大数据基础学习四:伪分布式 Hadoop 在 Ubuntu 上的安装流程完整步骤、易错点分析及需要注意的问题

文章目录
- 前言
- 一、创建 Ubuntu 用户
- 二、安装 Java
- 2.1、查看本地 Java 版本
- 2.2、验证 Java 在本地的配置情况
- 三、安装 ssh 服务
- 3.1、安装 openssh-server
- 3.2、查看 ssh 服务是否启动
- 四、Hadoop 伪分布式安装
- 4.1、hadoop 下载
- 4.2、进入下载安装包的目录
- 4.3、hadoop 解压
- 4.3.1、解压命令 tar zxvf 中 zxvf 分别是什么意思?
- 4.3.2、查看 hadoop 解压后目录文件
- 4.3.3、转移 hadoop 安装路径
- 4.4、查看 hadoop 目录所有者权限
- 4.5、修改 hadoop 目录的所有者
- 4.5、查看 hadoop 目录结构
- 4.6、Hadoop 约定目录结构分析
- 4.7、Hadoop 中的配置文件分析
- 4.8、设置 Hadoop 环境变量
- 五、准备启动 Hadoop 集群
- 5.1、hadoop 脚本的用法文档
- 5.2、查看 hadoop 的版本信息
- 六、伪分布式操作
- 6.1、修改配置文件
- 6.2、执行 NameNode 初始化
- 6.3、开启 NameNode 和 DataNode 守护进程
- 6.4、查看所有的 Java 进程
- 七、访问 Web 界面来查看 Hadoop 的信息
- 八、关闭 Hadoop
- 总结

这里不做详细叙述,请参考我之前的帖子,Ubuntu 添加和删除用户具体步骤以及可能报的错误(以 ubuntu-18.04.3 为例)。
对于 Ubuntu 本身,系统可能已经预装了Java,它的JDK版本为 openjdk,路径为"/usr/lib/jvm/default-java",之后配置 JAVA_HOME 环境变量可设置为该值。
Apache Hadoop 的 2.7 版和更高版本需要 Java7。它是在 OpenJDK 和 Oracle(HotSpot)的 JDK / JRE 上构建和测试的。早期版本(2.6 和更早版本)支持 Java 6。
输入java -version查看本地 jdk 版本号,没安装的话输入同样指令,根据提示下载需要版本,如下图所示:
输入javac,显示命令参数列表,说明配置成功,不显示请根据提示安装,如下图所示: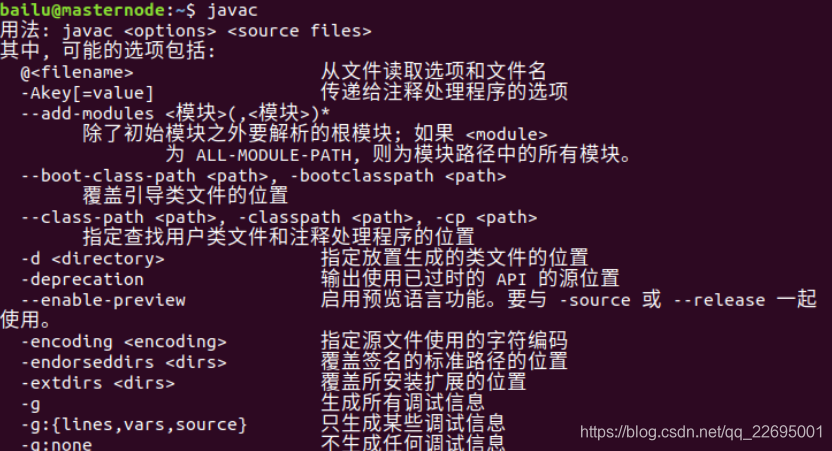
(具体安装 SSH 无密码登陆可以看我之前的帖子 Linux 中 ssh 配置无密码登陆完整步骤以及需要注意的问题)。
对于 Hadoop 的伪分布式和全分布式而言,Hadoop 的名称节点(NameNode)需要启动集群中所有机器的 Hadoop 的守护进程,这个过程可以通过 SSH 登陆来实现。Hadoop 并没有提供 SSH 输入密码登陆的形式,因此为了能够顺利登陆每台机器,需要将所有机器配置为名称节点可以无密码登陆的形式。
安装openssh-server,在终端输入如下代码:
sudo apt install openssh-server本人已经安装,如下图所示: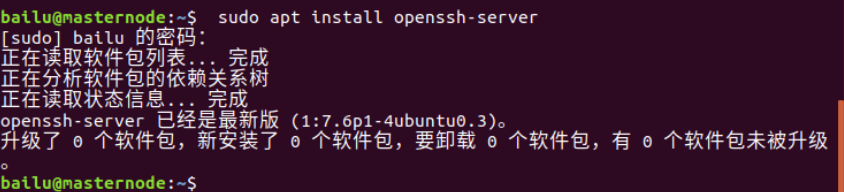
输入如下代码:
sudo ps -e|grep ssh回车,有 sshd,说明 ssh 服务已经启动,如下图所示: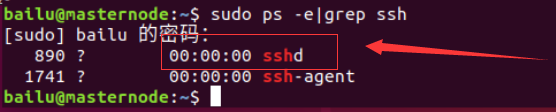
如果没有启动,输入sudo service ssh start,回车,ssh 服务就会启动。
伪分布式安装是指在一台机器上模拟一个小的集群,但是集群只有一个节点。
在 Linux 系统/Ubuntu 上打开自带火狐浏览器,输入地址 hadoop.apache.org,打开 hadoop 的页面,点击 Download 进行下载,如下图所示: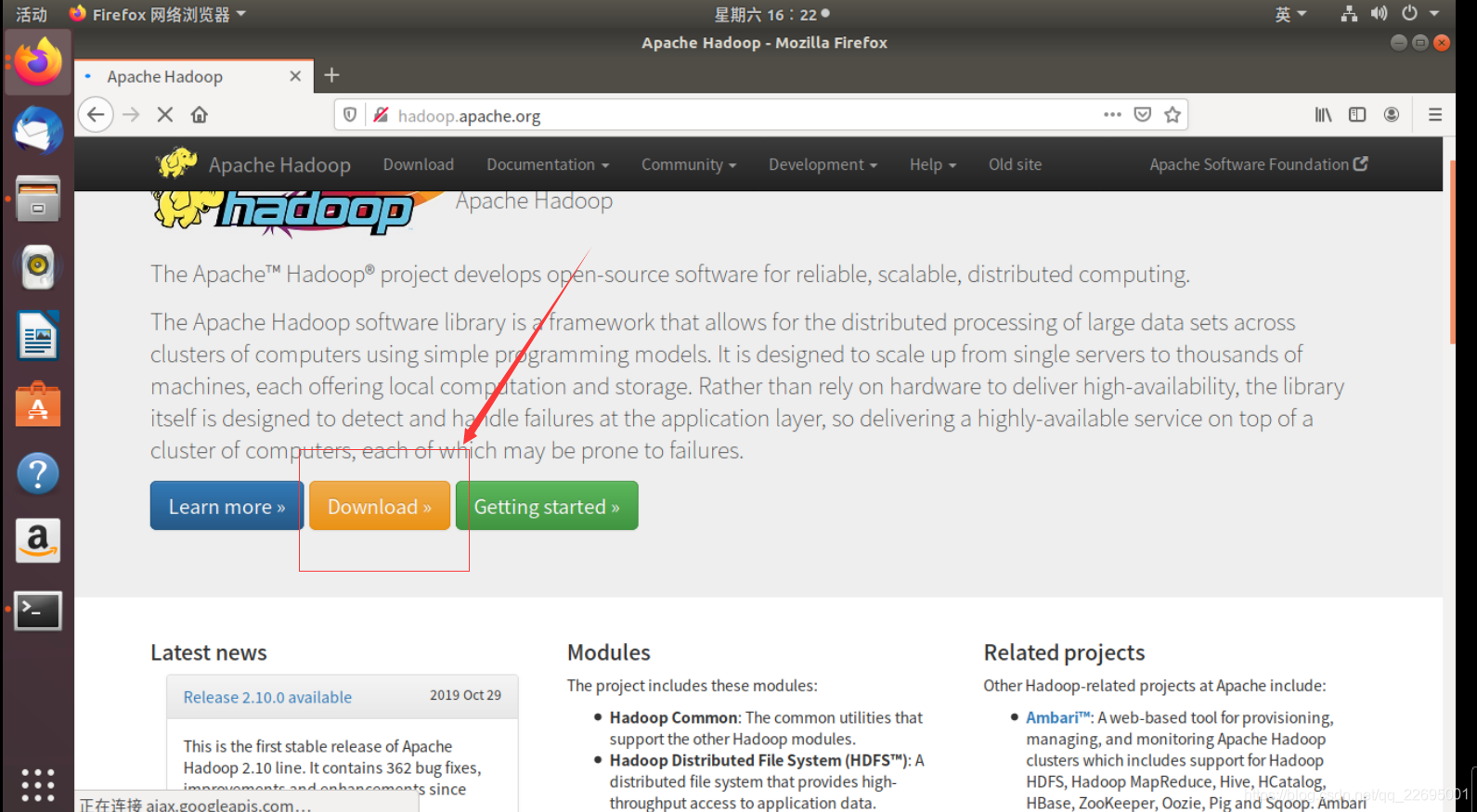
选择所需版本的 binary 链接,进入,如下图所示: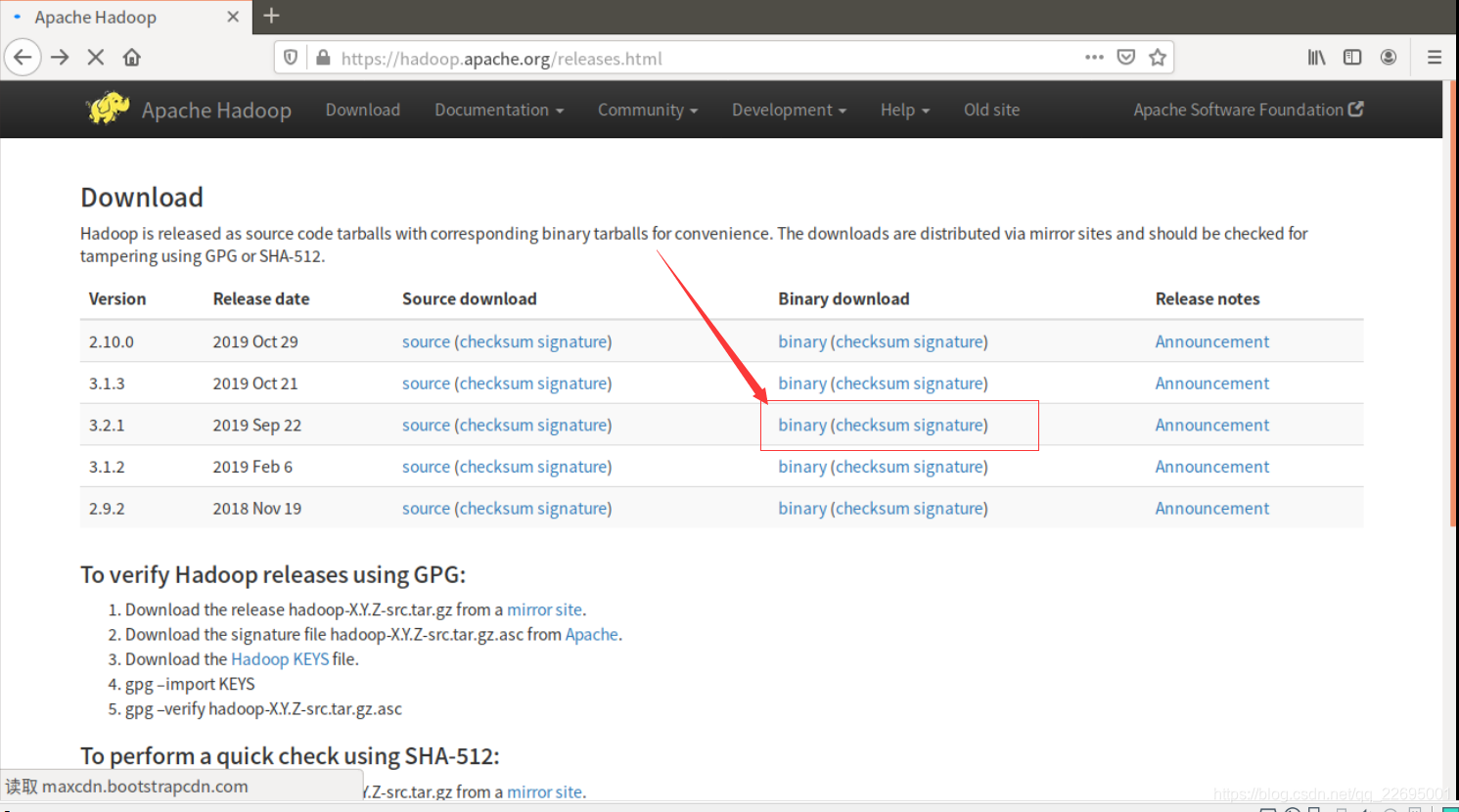
点击第一个镜像链接,进入下载页面,如下图所示: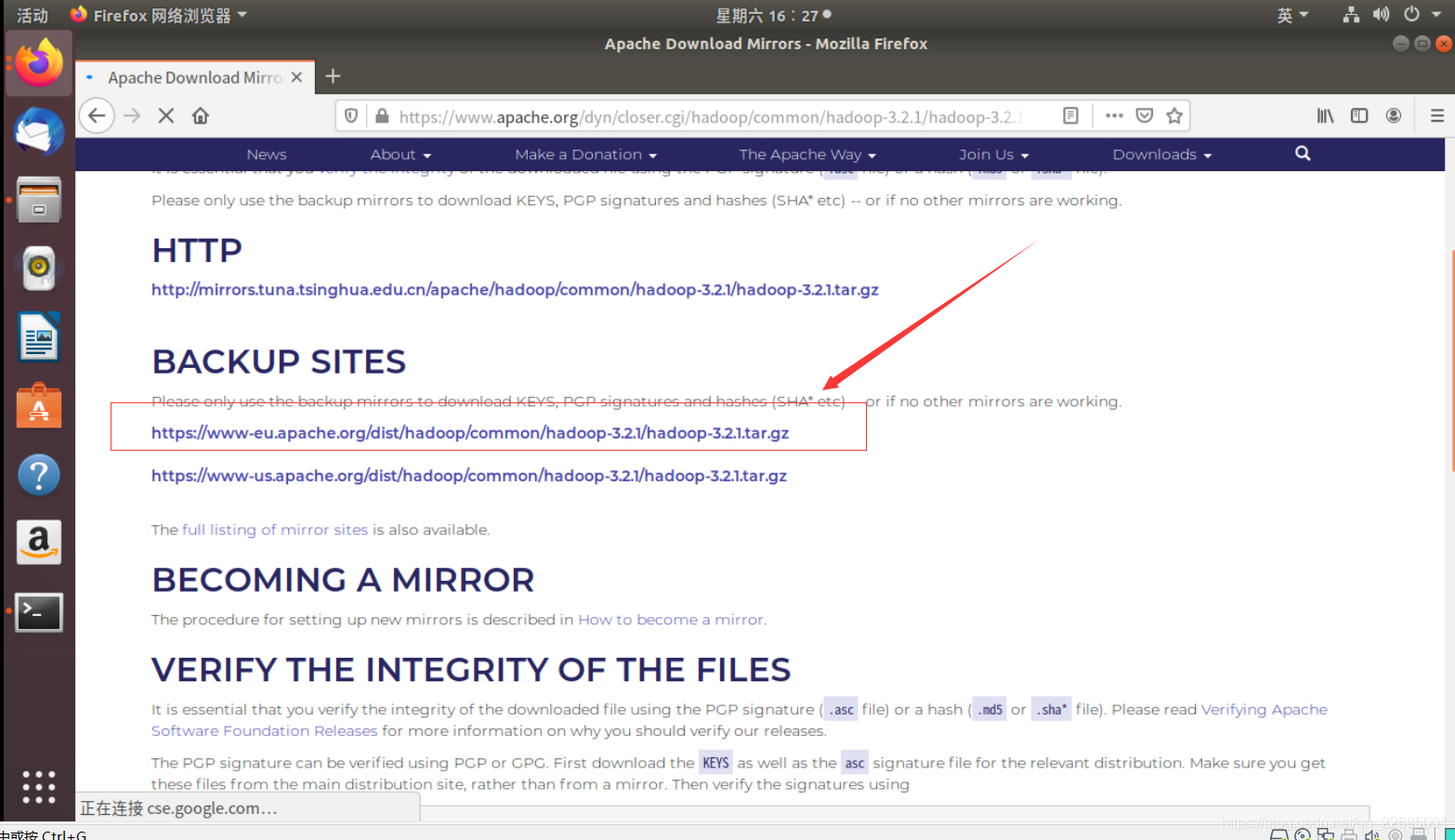
根据自己目录输入,我的如下图所示: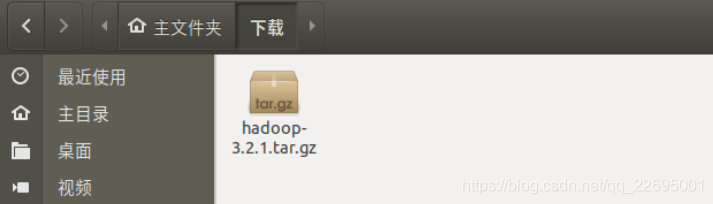

执行解压命令如下:
sudo tar -zxvf hadoop-3.2.1.tar.gz- x : 从 tar 包中把文件提取出来
- z : 表示 tar 包是被 gzip 压缩过的,所以解压时需要用 gunzip 解压
- v : 显示详细信息
- f xxx.tar.gz : 指定被处理的文件是 xxx.tar.gz
输入ll查看下载目录下的文件和目录,会看到多了一个目录 hadoop-3.2.1,这是安装包解压后的目录,如下图所示:
下载目录下输入如下命令将 hadoop-3.2.1 目录转移到 usr/local/hadoop 中:
sudo mv hadoop-3.2.1 /usr/local/hadoop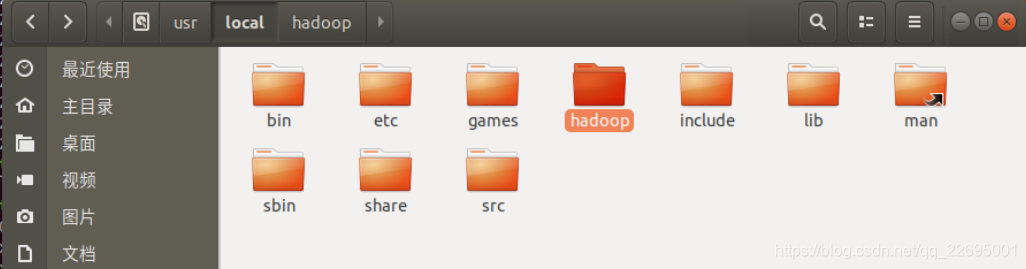
进入hadoop目录,可能会发现文件带锁,输入ll查看所有者不是本人,如下图所示: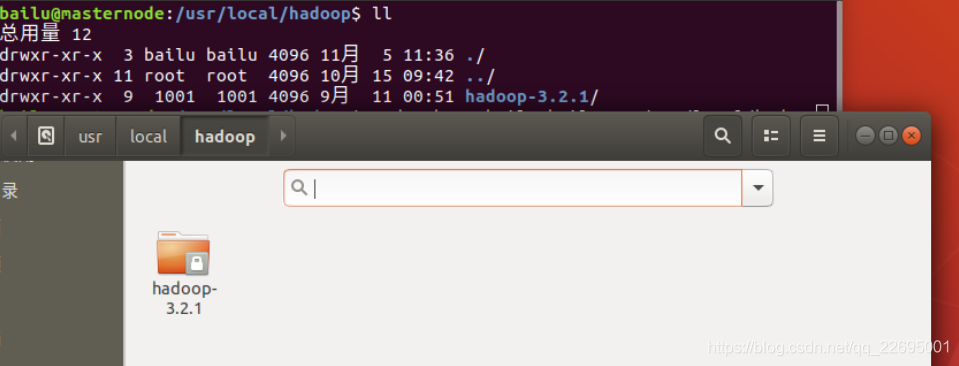
这时我们就需要将 hadoop 目录的所有者更改,根目录输入如下命令:
sudo chown bailu:bailu -R /usr/local/hadoop
修改之后查看所有者已经更改,如下图所示:
根目录输入cd /usr/local/hadoop进入 hadoop 目录,输入ll查看 hadoop 下目录结构,如下图所示: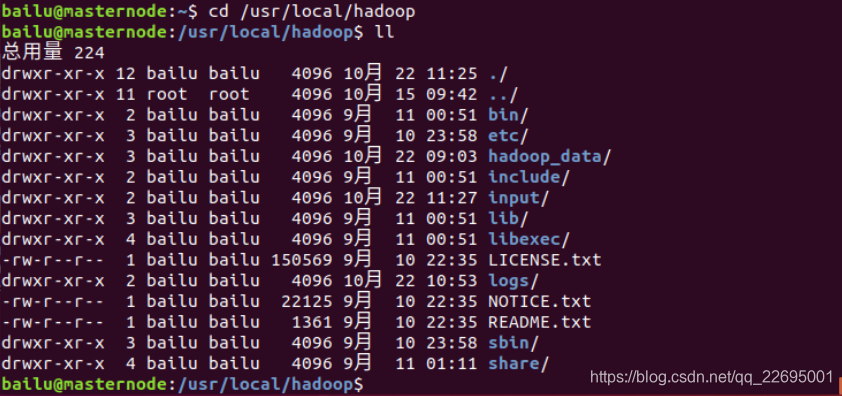
- bin:Hadoop最基本的管理脚本和使用脚本所在目录,这些脚本是sbin目录下管理脚本的基础实现,用户可以直接使用这些脚本管理和使用hadoop。
- etc:Hadoop配置文件所在目录,包括core-site.xml, hdfs-site.xml,mapred-site.xml等从hadoop1.0继承而来的配置文件和yarn-site.xml等hadoop 2.0新增的配置文件。
- include:对外提供的编程酷头文件(具体动态库和静态库在lib目录中),这些头文件均是用c++定义的,通常用于c++程序访问hdfs或者编写mapreduce程序。
- lib:该目录包含了Hadoop对外提供的的编程动态库和静态库,与include目录中的头文件结合使用。
- libexec:各个服务对应的shell配置文件所在目录,可用于配置日志输出目录,启动参数(比如JVM参数)等基本信息。
- sbin:Hadoop管理脚本所在目录,主要包含HDFS和YARN中各类服务的启动/关闭脚本。
- share:Hadoop各个模块编译后的jar包所在目录。
| 文件名称 | 格式 | 描述 |
|---|---|---|
| hadoop-env.sh | Bash脚本 | 记录配置Hadoop运行所需的环境变量,以运行Hadoop |
| core-site.xml | Hadoop配置XML | Hadoop core的配置项,如HDFS和MapReduce常用的I/O设置等 |
| hdfs-site.xml | Hadoop配置XML | Hadoop守护进程的配置项,包括NameNode、Secondary NameNode和DataNode等 |
| mapred-site.xml | Hadoop配置XML | MapReduce守护进程的配置项,包括JobTracker和TaskTracker |
| masters | 纯文本 | 运行SecondaryNameNode的机器列表(每行一个) |
| slaves | 纯文本 | 运行DataNode和TaskTracker的机器列表(每行一个) |
| hadoop-metrics.properties | Java属性 | 控制metrics在Hadoop上如何发布的属性 |
编辑 ~/.bashrc
任意目录下输入如下代码:
sudo gedit ~/.bashrc
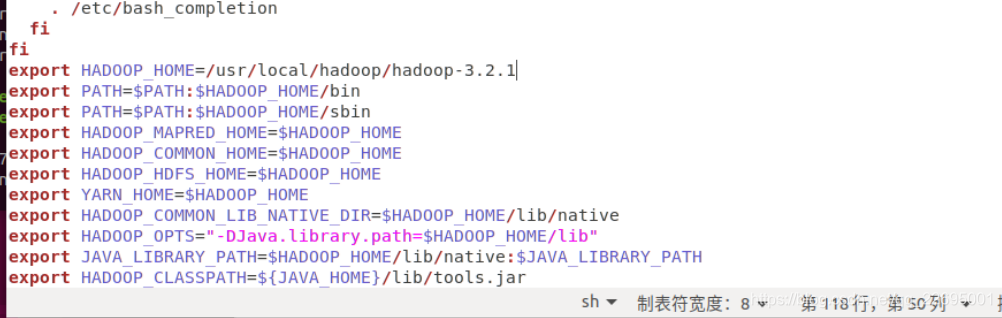
让环境变量立即生效source ~/.bashrc,如下图所示:
任意目录下输入如下代码:
sudo gedit /usr/local/hadoop/hadoop-3.2.1/etc/hadoop/hadoop-env.sh编辑 etc/hadoop/hadoop-env.sh 以定义一些参数,将原文本文件中的 JAVA_HOME 设置成真实的 JDK 地址,如下所示:
#设置为 Java 安装的根目录
export JAVA_HOME =/usr/java/latest 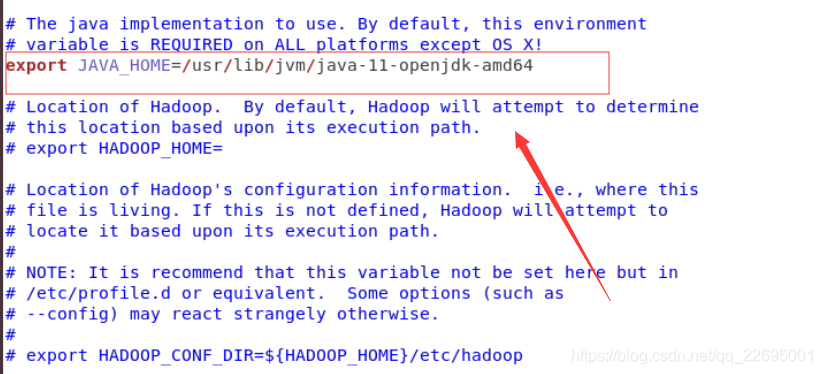
尝试以下命令:hadoop 根目录下输入 bin/hadoop 这将显示 hadoop 脚本的用法文档:
这时我们可以查看 hadoop 的版本信息,代码如下:
./bin/hadoop version 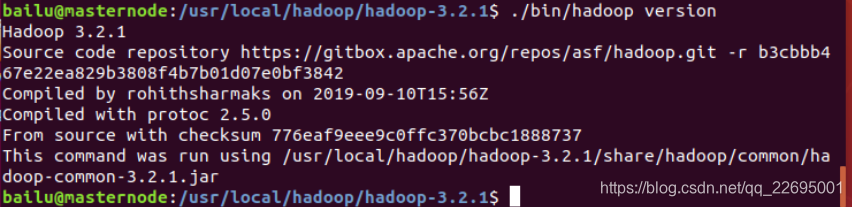
对于伪分布式,仅需修改 core-site.xml、hdfs-site.xml 文件
etc/hadoop/core-site.xml:
sudo gedit /usr/local/hadoop/hadoop-3.2.1/etc/hadoop/core-site.xml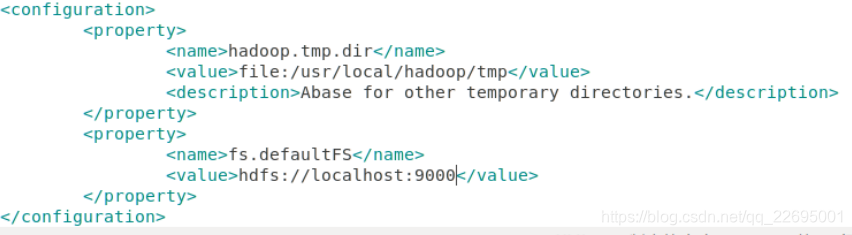
说明:
<name>标签设置配置项的名字,<value>设置配置项的值。- 对于 core-site.xml 文件,只需在其中指定 HDFS 的地址和端口号,端口号按照官方文档设置为 9000 即可。
etc/hadoop/hdfs-site.xml:
sudo gedit /usr/local/hadoop/hadoop-3.2.1/etc/hadoop/hdfs-site.xml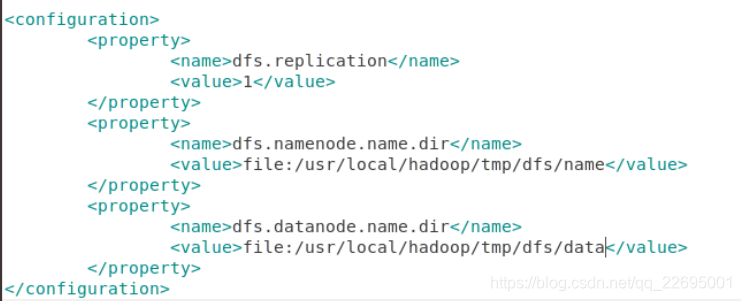
说明:
- 对于 hdfs-site.xml 文件,我们设置 replication 值为 1,这也是 Hadoop 运行的默认最小值,它限制了 HDFS 文件系统中同一份数据的副本数量。
- 这里采用伪分布式,在集群中只有一个节点,因此副本数量 replication 的值也只能设置为 1。
在配置完成后,首先需要初始化文件系统。由于 Hadoop 的很多工作是在自带的 HDFS 文件系统上完成的,因此需要将文件系统初始化之后才能进一步执行计算任务。
在 Hadoop 根目录执行 NameNode 初始化的命令如下:
./bin/hdfs namenode -format
遇到这一步,继续执行,如下图所示: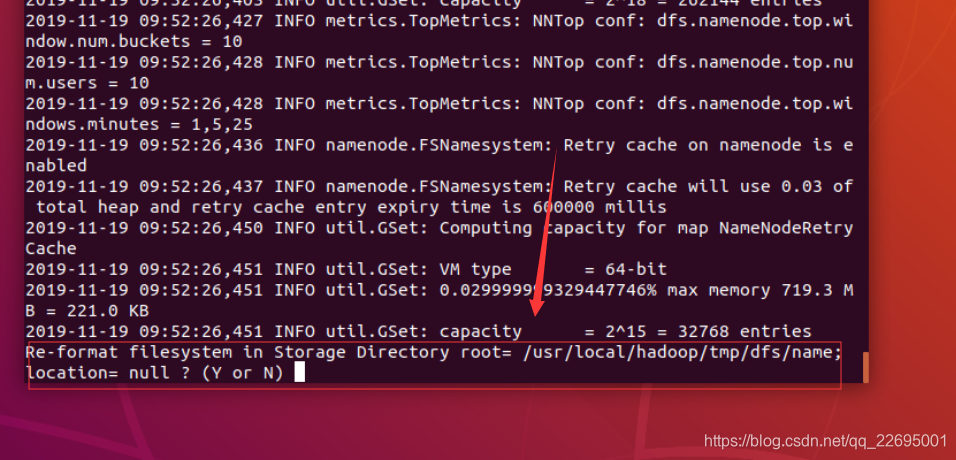
成功的话,会看到"successfully formatted"和"Exitting with status"的提示,若为"Exitting with status 1"则是出错。
如果出现启动错误,则可以在日志中查看错误原因。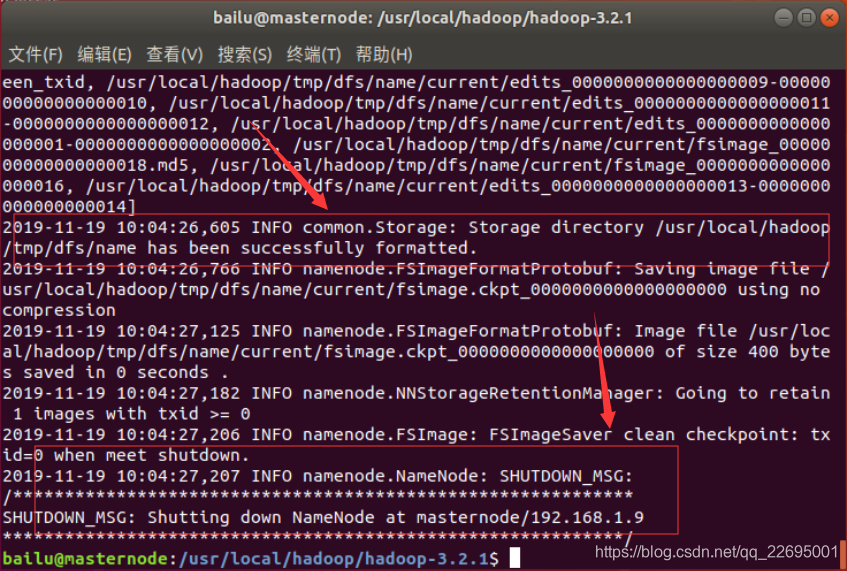
对于控制台报错请注意:
- 每一次的启动日志都是追加在日志文件之后,所以对于错误要拉到最后面看,对比下记录的时间就知道了。
- 一般出错的提示在最后面,通常是写着 Fatal、Error、Warning 或者 Java Exception 的地方。

运行之后,输入 jps 指令可以查看所有的 Java 进程。在正常启动时,可以得到如下类似结果:
jps(Java Virtual Machine Process Status Tool)是 java 提供的一个显示当前所有 java 进程 pid 的命令,适合在 linux/unix 平台上简单察看当前 java 进程的一些简单情况。很多人都是用过 unix 系统里的 ps 命令,这个命令主要是用来显示当前系统的进程情况,有哪些进程以及进程id。
jps 也是一样,它的作用是显示当前系统的 java 进程情况及进程 id。我们可以通过它来查看我们到底启动了几个 java 进程(因为每一个 java 程序都会独占一个 java 虚拟机实例)。
此时,可以通过 Linux 本地浏览器访问 Web 界面(http://localhost:9870)来查看 Hadoop 的信息。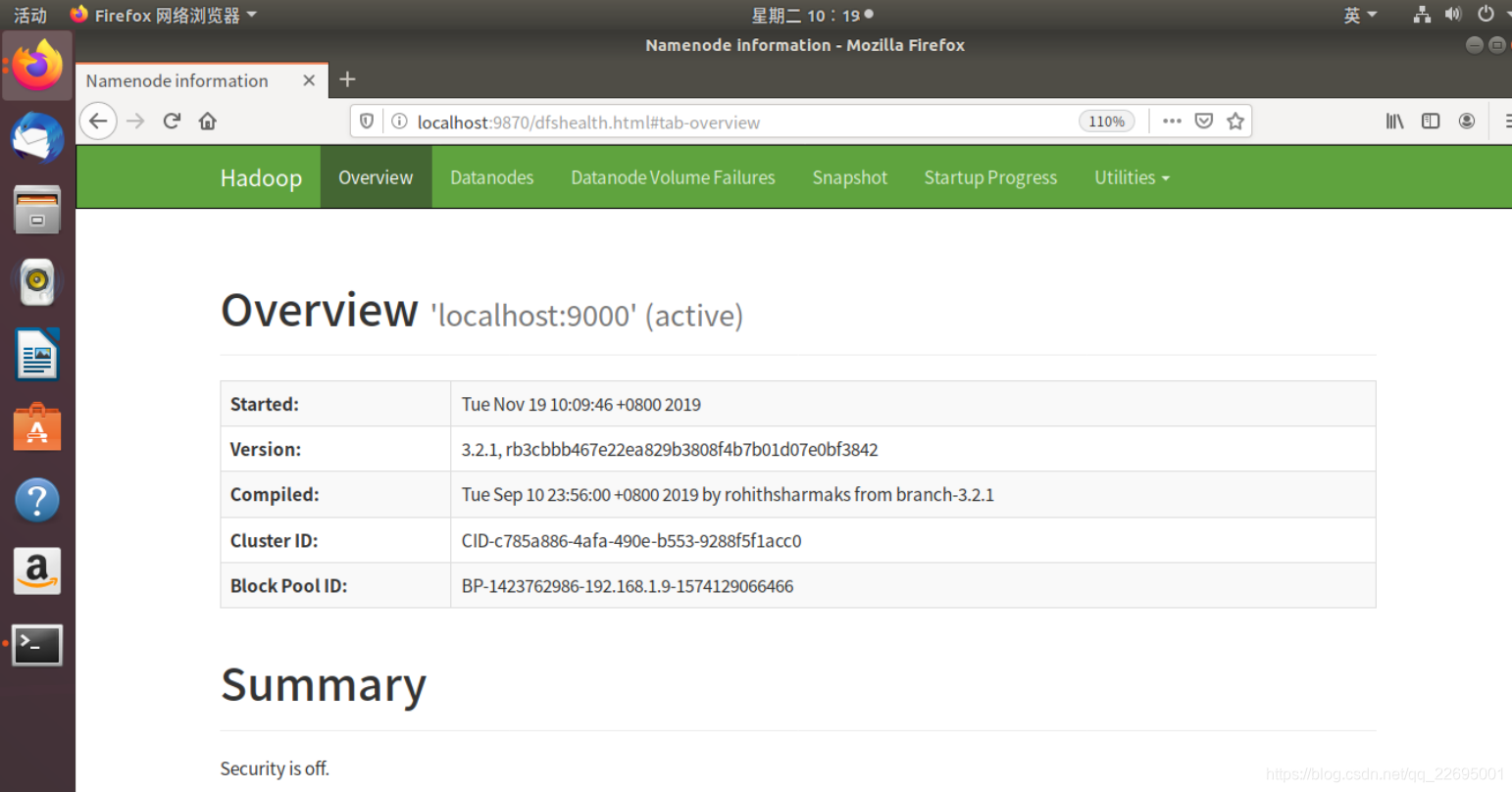
如果存在 DataNode 启动异常时或者没有启动的问题,请查看解决 Apache Hadoop 启动时 DataNode 没有启动的问题(注意这会删除 HDFS 中原有的所有数据,如果原有的数据很重要请不要这样做)。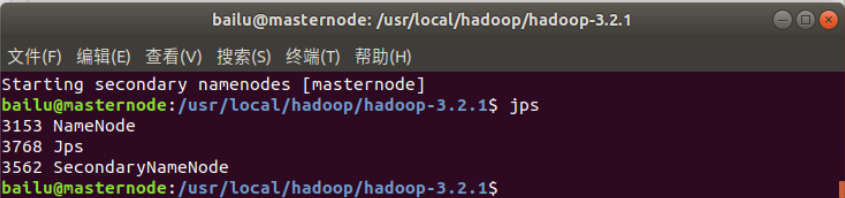
八、关闭 Hadoop
若要关闭 Hadoop,则在 Hadoop 根目录下运行如下命令:
./sbin/stop-dfs.sh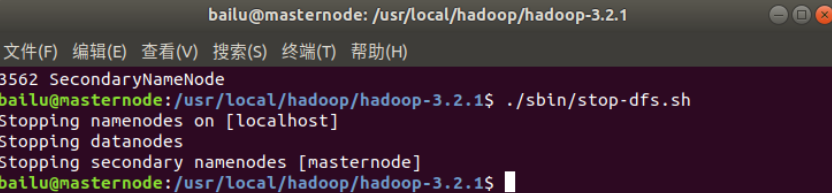

感谢大家的支持,我是白鹿,一个不懈奋斗的程序猿。希望本贴能帮助到大家,欢迎大家的一键三连!如果还有什么问题、建议或者补充可以留言在帖子下方,给予更多人帮助!

- 点赞
- 收藏
- 关注作者
评论(0)