

RAG技术是什么?一文带你解锁RAGA技术,基于向量检索的RAG实现:公司HR制度智能问答系统

【摘要】 一、RAG:检索增强生成技术 1.1 传统大型语言模型(LLM)的局限性大型语言模型(LLM)在自然语言处理领域取得了显著的成就,但它们也存在一些局限性:知识更新滞后:LLM的知识库通常是静态的,不能实时更新,导致模型可能无法获取最新的信息。私有领域知识缺失:LLM可能不了解特定用户或企业的私有领域或业务知识。错误信息生成:LLM有时可能会生成看似合理但实际上是错误的信息,尤其是在处理复杂...
一、RAG:检索增强生成技术
1.1 传统大型语言模型(LLM)的局限性
大型语言模型(LLM)在自然语言处理领域取得了显著的成就,但它们也存在一些局限性:
- 知识更新滞后:LLM的知识库通常是静态的,不能实时更新,导致模型可能无法获取最新的信息。
- 私有领域知识缺失:LLM可能不了解特定用户或企业的私有领域或业务知识。
- 错误信息生成:LLM有时可能会生成看似合理但实际上是错误的信息,尤其是在处理复杂或专业性较强的问题时。
1.2 RAG技术的应用动机
RAG(Retrieval Augmented Generation)技术的出现,旨在解决上述问题,并增强LLM的能力:
- 提高准确性:通过检索相关信息,RAG能够提高生成文本的准确性。
- 降低训练成本:与传统需要大量数据训练的LLM相比,RAG通过检索机制减少所需的训练数据量,从而降低训练成本。
- 适应性增强:RAG模型能够适应新的或不断变化的数据,因为它们能够检索最新的信息,快速适应新数据和事件。
1.3 RAG技术概念
RAG技术,即检索增强生成,是一种通过检索方法来增强生成模型能力的新型技术。
详细讲解请参考链接:https://www.bilibili.com/video/BV1zm421G7hk/?spm_id_from=333.337.search-card.all.click
1.4 RAG技术的类比
RAG技术可以类比为开卷考试的过程:让LLM先“翻书”(检索信息),再“回答问题”(生成文本)。
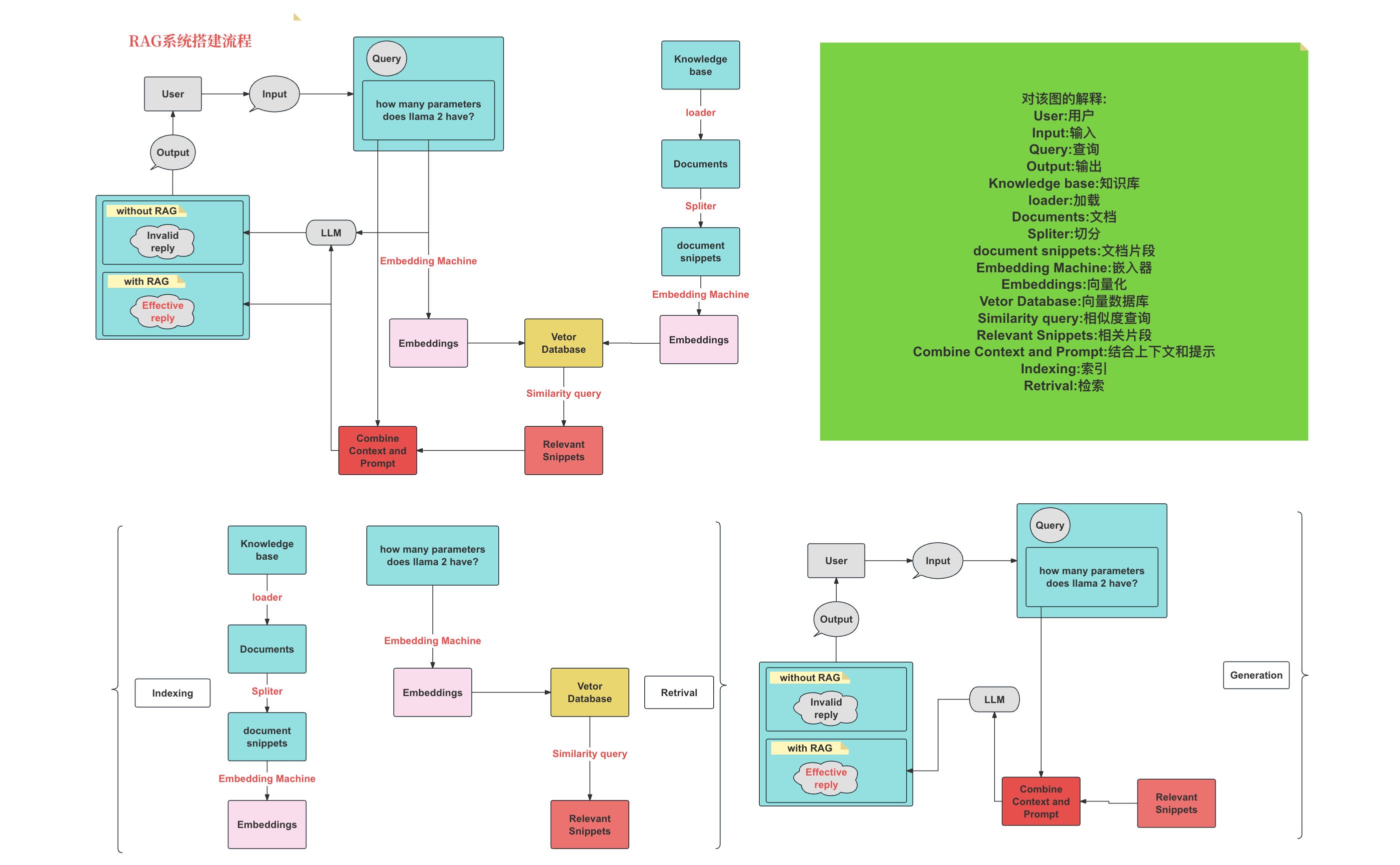
二、基础RAG流程

RAG(Retrieval Augmented Generation)的基础流程结合了信息检索(Retrieval)和文本生成(Generation)两个主要步骤,以提高生成文本的准确性和相关性。以下是RAG的基础流程:
-
用户输入查询:
用户向系统提出一个问题或请求。 -
检索阶段:
- 向量表示:系统首先将用户的查询转换为向量形式(Embedding),这通常通过预训练的神经网络模型来实现。
- 向量数据库检索:然后,系统在向量数据库中检索与查询向量最相似的文档或信息的向量表示。
- 相关文档提取:根据相似度得分,系统提取最相关的文档或信息片段。
-
生成阶段:
- 构建上下文:系统将检索到的相关文档或信息作为上下文,与用户的原始查询一起构建成一个完整的输入。
- 调用生成模型:使用大型语言模型(LLM)如GPT或BERT,基于构建的上下文生成回答或完成特定任务。
- 生成文本输出:模型生成的文本经过处理后,作为最终答案输出给用户。
-
后处理:
- 答案优化:对生成的文本进行后处理,如消除不相关的内容、提高可读性等。
- 反馈学习:系统可能会根据用户的反馈进行学习,以优化未来的性能。
-
输出结果:
- 呈现答案:将生成的答案呈现给用户,完成一次交互。
-
监控与评估:
- 性能监控:监控系统的性能,包括检索的准确性和生成文本的质量。
- 持续改进:根据监控结果和用户反馈,不断调整和优化RAG流程。
RAG流程的关键在于有效地结合检索到的信息和生成模型的能力,以提供准确、相关且高质量的回答。这个流程可以根据不同的应用场景和需求进行调整和优化。
三、向量检索技术
3.1 检索方式
向量检索技术主要包括以下两种方式:
- 关键字搜索:通过用户输入的关键字来查找文本数据。
- 语义搜索:不仅考虑关键词的匹配,还考虑词汇之间的语义关系,以提供更准确的搜索结果。
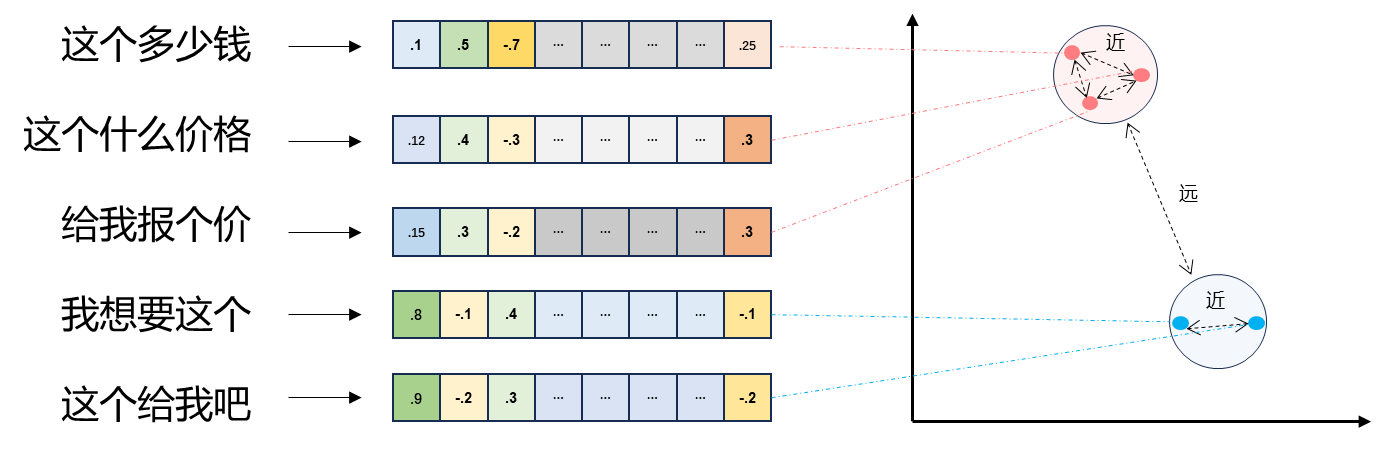
3.2 向量与Embeddings的定义
在数学中,向量是指具有大小(magnitude)和方向的量,可以形象化地表示为带箭头的线段。在自然语言处理中:
- 文本向量化:将文本转换为一组浮点数,每个下标对应一个维度。
- Embeddings:整个数组对应于n维空间中的一个点,即文本向量。
- 语义相似度:向量之间可以计算距离,距离的远近对应于语义相似度的大小。
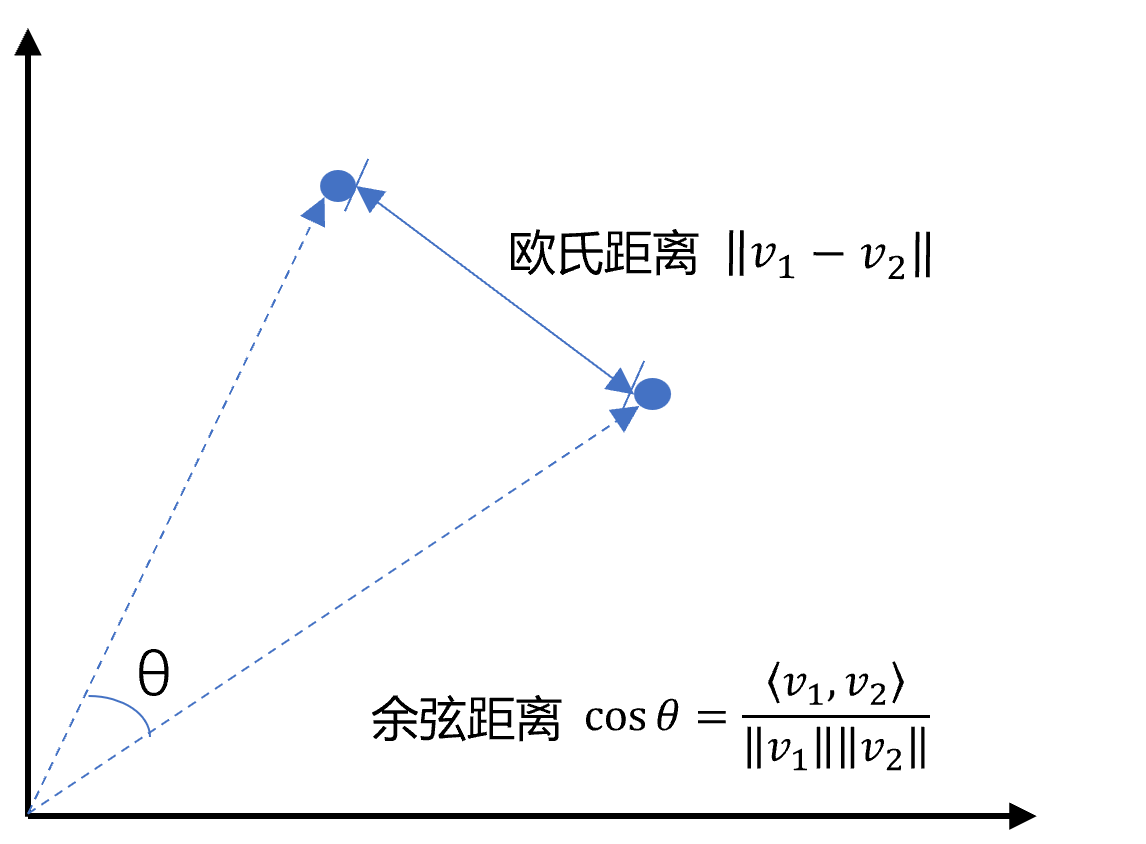
3.3 向量间的相似度计算
from openai import OpenAI
from dotenv import load_dotenv
import numpy as np
from numpy import dot
from numpy.linalg import norm
load_dotenv()
client = OpenAI()
def cos_sim(a, b):
'''余弦距离 -- 越大越相似'''
return dot(a, b)/(norm(a)*norm(b))
def l2(a, b):
'''欧式距离 -- 越小越相似'''
x = np.asarray(a)-np.asarray(b)
return norm(x)
def get_embeddings(texts, model="text-embedding-3-large"):
# texts 是一个包含要获取嵌入表示的文本的列表,
# model 则是用来指定要使用的模型的名称
# 生成文本的嵌入表示。结果存储在data中。
data = client.embeddings.create(input=texts, model=model).data
# print(data)
# 返回了一个包含所有嵌入表示的列表
return [x.embedding for x in data]
# 且能支持跨语言
# query = "global conflicts"
query = "国际争端"
documents = [
"联合国就苏丹达尔富尔地区大规模暴力事件发出警告",
"土耳其、芬兰、瑞典与北约代表将继续就瑞典“入约”问题进行谈判",
"日本岐阜市陆上自卫队射击场内发生枪击事件 3人受伤",
"国家游泳中心(水立方):恢复游泳、嬉水乐园等水上项目运营",
"我国首次在空间站开展舱外辐射生物学暴露实验",
]
query_vec = get_embeddings([query])[0]
doc_vecs = get_embeddings(documents)
print("Cosine distance:")
print(cos_sim(query_vec, query_vec))
for vec in doc_vecs:
print(cos_sim(query_vec, vec))
print("\nEuclidean distance:")
print(l2(query_vec, query_vec))
for vec in doc_vecs:
print(l2(query_vec, vec))
输出结果:
Cosine distance:
0.9999999999999999
0.2370090408983918
0.28231843637704235
0.1152975379025242
0.14936589374726902
0.13168852079837604
Euclidean distance:
0.0
1.2353063919692502
1.1980664037889215
1.330189849783533
1.3043267095981308
1.3178098771928697
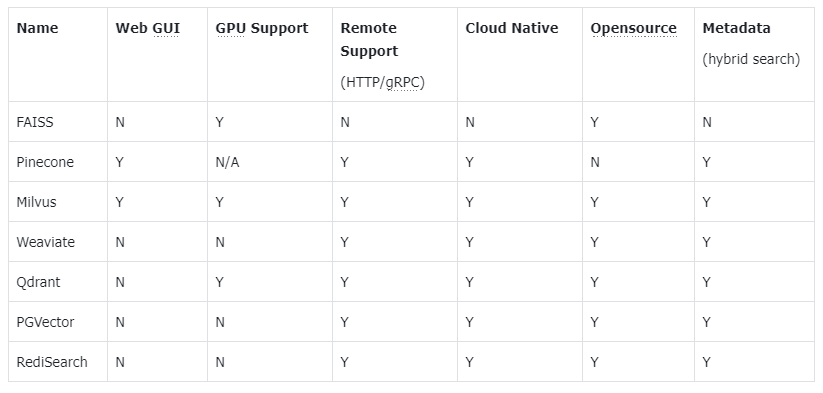
3.4 向量数据库
向量数据库是存储和管理向量数据的数据库,它们能够高效地执行向量搜索和相似度计算。以下是一些主流的向量数据库:
- FAISS:Meta开源的向量检索引擎,GitHub链接。
- Pinecone:商用向量数据库,仅提供云服务,官网。
- Milvus:开源向量数据库,同时提供云服务,官网。
- Weaviate:开源向量数据库,同时提供云服务,官网。
- Qdrant:开源向量数据库,同时提供云服务,官网。
- PGVector:Postgres的开源向量检索引擎,GitHub链接。
- RediSearch:Redis的开源向量检索引擎,GitHub链接。
- ElasticSearch:也支持向量检索,官网。
代码实现:
from pdfminer.high_level import extract_pages
from pdfminer.layout import LTTextContainer
from openai import OpenAI
import chromadb
from chromadb.config import Settings
from dotenv import load_dotenv
load_dotenv()
client = OpenAI()
def get_embeddings(texts, model="text-embedding-ada-002"):
print('11111222233333')
'''封装 OpenAI 的 Embedding 模型接口'''
data = client.embeddings.create(input=texts, model=model).data
return [x.embedding for x in data]
def extract_text_from_pdf(filename, page_numbers=None, min_line_length=1):
'''从 PDF 文件中(按指定页码)提取文字'''
paragraphs = []
buffer = ''
full_text = ''
# 提取全部文本
for i, page_layout in enumerate(extract_pages(filename)):
# 如果指定了页码范围,跳过范围外的页
if page_numbers is not None and i not in page_numbers:
continue
for element in page_layout:
if isinstance(element, LTTextContainer):
full_text += element.get_text() + '\n'
# 按空行分隔,将文本重新组织成段落
lines = full_text.split('\n')
for text in lines:
if len(text) >= min_line_length:
buffer += (' '+text) if not text.endswith('-') else text.strip('-')
elif buffer:
paragraphs.append(buffer)
buffer = ''
if buffer:
paragraphs.append(buffer)
return paragraphs
class MyVectorDBConnector:
def __init__(self, collection_name, embedding_fn):
"""内存模式"""
# chroma_client = chromadb.Client(Settings(allow_reset=True))
"""本地模式"""
chroma_client = chromadb.PersistentClient(path=f'./chroma/{collection_name}')
# chroma_client.reset()
# 创建一个 collection
self.collection = chroma_client.get_or_create_collection(name=collection_name)
self.embedding_fn = embedding_fn
def add_documents(self, documents):
'''向collection中添加文档与向量'''
self.collection.add(
embeddings=self.embedding_fn(documents), # 每个文档的向量
documents=documents, # 文档的原文
ids=[f"id{i}" for i in range(len(documents))] # 每个文档的 id
)
def search(self, query, top_n):
'''检索向量数据库'''
results = self.collection.query(
query_embeddings=self.embedding_fn([query]),
n_results=top_n
)
return results
if __name__ == '__main__':
paragraphs = extract_text_from_pdf("/Users/yuejunzhang/Desktop/AI_LLM06/day07Naive RAG Base/llama2.pdf", min_line_length=10)
print('paragraphs:', paragraphs)
# 创建一个向量数据库对象
vector_db = MyVectorDBConnector("demoaibook", get_embeddings)
# 向向量数据库中添加文档
vector_db.add_documents(paragraphs)
user_query = "llama 2有多少参数?"
results = vector_db.search(user_query, 3)
print('results: ',results)
for para in results['documents'][0]:
print(para+"\n")
3.4.1 主流向量数据库简介
四、HuggingFace向量模型本地部署
HuggingFace提供了丰富的预训练模型和便捷的部署方式:
# 模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('AI-ModelScope/bge-large-zh-v1.5')
五、基于向量检索的RAG实现:公司HR制度智能问答系统
以下是一个基于向量检索的RAG实现示例,用于构建公司HR制度的智能问答系统:
from dotenv import load_dotenv
load_dotenv()
from openai import OpenAI
from pdfminer.high_level import extract_pages
from pdfminer.layout import LTTextContainer
import chromadb
from chromadb.config import Settings
from docx import Document
client = OpenAI()
prompt_template = """
你是一个问答机器人。
你的任务是根据下述给定的已知信息回答用户问题。
确保你的回复完全依据下述已知信息。不要编造答案。
如果下述已知信息不足以回答用户的问题,请直接回复"我无法回答您的问题"。
已知信息:
__INFO__
用户问:
__QUERY__
请用中文回答用户问题。
"""
def extract_text_from_pdf(filename, page_numbers=None, min_line_length=1):
'''从 PDF 文件中(按指定页码)提取文字'''
paragraphs = []
buffer = ''
full_text = ''
# 提取全部文本
for i, page_layout in enumerate(extract_pages(filename)):
# 如果指定了页码范围,跳过范围外的页
if page_numbers is not None and i not in page_numbers:
continue
for element in page_layout:
if isinstance(element, LTTextContainer):
full_text += element.get_text() + '\n'
# 按空行分隔,将文本重新组织成段落
lines = full_text.split('\n')
for text in lines:
if len(text) >= min_line_length:
buffer += (' '+text) if not text.endswith('-') else text.strip('-')
elif buffer:
paragraphs.append(buffer)
buffer = ''
if buffer:
paragraphs.append(buffer)
return paragraphs
def extract_text_from_docx(filename, min_line_length=1):
'''从 DOCX 文件中提取文字'''
paragraphs = []
buffer = ''
full_text = ''
# 打开并读取文档
doc = Document(filename)
# 提取全部文本
for para in doc.paragraphs:
full_text += para.text + '\n'
# 按空行分隔,将文本重新组织成段落
lines = full_text.split('\n')
for line in lines:
if len(line) >= min_line_length:
buffer += (' ' + line) if not line.endswith('-') else line.strip('-')
elif buffer:
paragraphs.append(buffer)
buffer = ''
if buffer:
paragraphs.append(buffer)
return paragraphs
# 使用示例
docx_filename = "人事管理流程.docx"
paragraphs = extract_text_from_docx(docx_filename, min_line_length=10)
# paragraphs = extract_text_from_pdf("人事管理流程.pdf", page_numbers=[
# 2, 3], min_line_length=10)
def get_completion(prompt, model="gpt-3.5-turbo"):
'''封装 openai 接口'''
messages = [{"role": "user", "content": prompt}]
response = client.chat.completions.create(
model=model,
messages=messages,
temperature=0, # 模型输出的随机性,0 表示随机性最小
)
return response.choices[0].message.content
def build_prompt(prompt_template, **kwargs):
'''将 Prompt 模板赋值'''
prompt = prompt_template
for k, v in kwargs.items():
if isinstance(v, str):
val = v
elif isinstance(v, list) and all(isinstance(elem, str) for elem in v):
val = '\n'.join(v)
else:
val = str(v)
prompt = prompt.replace(f"__{k.upper()}__", val)
return prompt
class MyVectorDBConnector:
def __init__(self, collection_name, embedding_fn):
chroma_client = chromadb.Client(Settings(allow_reset=True))
# 为了演示,实际不需要每次 reset()
# chroma_client.reset()
# 创建一个 collection
self.collection = chroma_client.get_or_create_collection(name=collection_name)
self.embedding_fn = embedding_fn
def add_documents(self, documents):
'''向 collection 中添加文档与向量'''
self.collection.add(
embeddings=self.embedding_fn(documents), # 每个文档的向量
documents=documents, # 文档的原文
ids=[f"id{i}" for i in range(len(documents))] # 每个文档的 id
)
def search(self, query, top_n):
'''检索向量数据库'''
results = self.collection.query(
query_embeddings=self.embedding_fn([query]),
n_results=top_n
)
return results
def get_embeddings(texts, model="text-embedding-3-large"):
'''封装 OpenAI 的 Embedding 模型接口'''
data = client.embeddings.create(input=texts, model=model).data
return [x.embedding for x in data]
# 创建一个向量数据库对象
vector_db = MyVectorDBConnector("demo", get_embeddings)
# 向向量数据库中添加文档
vector_db.add_documents(paragraphs)
class RAG_Bot:
def __init__(self, vector_db, llm_api, n_results=2):
self.vector_db = vector_db
self.llm_api = llm_api
self.n_results = n_results
def chat(self, user_query):
# 1. 检索
search_results = self.vector_db.search(user_query, self.n_results)
print('search_results:',search_results)
# 2. 构建 Prompt
prompt = build_prompt(
prompt_template, info=search_results['documents'][0], query=user_query)
print('prompt:',prompt)
# 3. 调用 LLM
response = self.llm_api(prompt)
return response
# 创建一个RAG机器人
bot = RAG_Bot(
vector_db,
llm_api=get_completion
)
user_query = "视为不符合录用条件的情形有哪些?"
response = bot.chat(user_query)
print(response)
这个系统通过向量检索技术,结合LLM的强大生成能力,为用户提供准确、高效的问答服务。
【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com

- 点赞
- 收藏
- 关注作者
作者其他文章









评论(0)