PyTorch: 张量的变换、数学运算及线性回归

本文已收录于Pytorch系列专栏: Pytorch入门与实践 专栏旨在详解Pytorch,精炼地总结重点,面向入门学习者,掌握Pytorch框架,为数据分析,机器学习及深度学习的代码能力打下坚实的基础。免费订阅,持续更新。
张量变换
1.torch.reshape
torch.reshape(input,shape)
功能:变换张量形状
注意事项:当张量在内存中是连续时,新张量与 input 共享数据内存
- input : 要变换的张量
- shape 新张量的形状
code:
t = torch.randperm(8)
t_reshape = torch.reshape(t, (-1, 2, 2)) # -1表示该维度不用关心,是由其他几个维度计算而来的
print("t:{}\nt_reshape:\n{}".format(t, t_reshape))
t[0] = 1024
print("t:{}\nt_reshape:\n{}".format(t, t_reshape))
print("t.data 内存地址:{}".format(id(t.data)))
print("t_reshape.data 内存地址:{}".format(id(t_reshape.data)))
改变其中一个数,另一个张量随之改变,可见是内存共享的。
t:tensor([5, 4, 2, 6, 7, 3, 1, 0])
t_reshape:
tensor([[[5, 4],
[2, 6]],
[[7, 3],
[1, 0]]])
t:tensor([1024, 4, 2, 6, 7, 3, 1, 0])
t_reshape:
tensor([[[1024, 4],
[ 2, 6]],
[[ 7, 3],
[ 1, 0]]])
t.data 内存地址:2030792110712
t_reshape.data 内存地址:2030792110712
2.torch.transpose
torch.transpose(input, dim0, dim1)
功能:交换张量的两个维度
- input : 要变换的张量
- dim0 要交换的维度
- dim1 要交换的维度
code
# torch.transpose
t = torch.rand((2, 3, 4))
t_transpose = torch.transpose(t, dim0=1, dim1=2) # c*h*w h*w*c
print("t shape:{}\nt_transpose shape: {}".format(t.shape, t_transpose.shape))
t shape:torch.Size([2, 3, 4])
t_transpose shape: torch.Size([2, 4, 3])
3.torch.t()
torch.t(input)
功能:2 维张量转置,对矩阵而言,等价于torch.transpose(input, 0, 1)
4.torch.squeeze()
torch.squeeze(input, dim=None, out=None)
功能:压缩长度为 1 的维度(轴)
- dim : 若为 None ,移除所有长度为 1 的轴;若指定维度,当且仅当该轴长度为 1 时,可以被移除;
5.torch.unsqueeze()
torch.usqueeze(input, dim, out=None)
功能:
-
依据dim 扩展维度
-
dim : 扩展的维度, 这个维度就是1了
张量的数学运算
1.加减乘除
-
torch.add()
torch.add(input, alpha=1, other, out=None)功能:逐元素计算 input+alpha × other
- input : 第一个张量
- alpha : 乘项因子
- other : 第二个张量
-
torch.addcdiv()加法集合除法
-
torch.addcmul()加法集合乘法
torch.addcmul(input, value=1, tensor1, tensor2,out= None) -
torch.sub()
-
torch.mul()
code:
t_0 = torch.randn((3, 3))
t_1 = torch.ones_like(t_0)
t_add = torch.add(t_0, 10, t_1)
print("t_0:\n{}\nt_1:\n{}\nt_add_10:\n{}".format(t_0, t_1, t_add))
t_0:
tensor([[ 0.6614, 0.2669, 0.0617],
[ 0.6213, -0.4519, -0.1661],
[-1.5228, 0.3817, -1.0276]])
t_1:
tensor([[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]])
t_add_10:
tensor([[10.6614, 10.2669, 10.0617],
[10.6213, 9.5481, 9.8339],
[ 8.4772, 10.3817, 8.9724]])
Process finished with exit code 0
2.对数,指数,幂函数
- torch.log(input, out=None)
- torch,log10(input, out=None)
- torch.log2(input, out=None)
- torch.exp(input, out=None)
- torch.pow(input, out=None)
3.三角函数
- torch.abs(input, out=None)
- torch.acos(input, out=None)
- torch.cosh(input, out=None)
- torch.cos(input, out=None)
- torch.asin(input, out=None)
- torch.atan(input, out=None)
- torch.atan2(input, other, out=None)
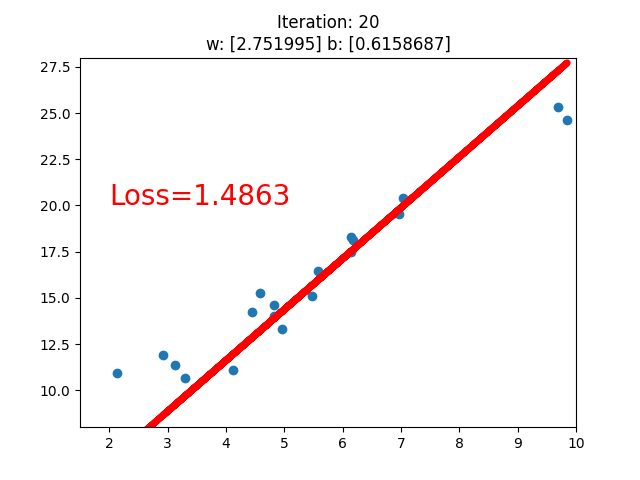
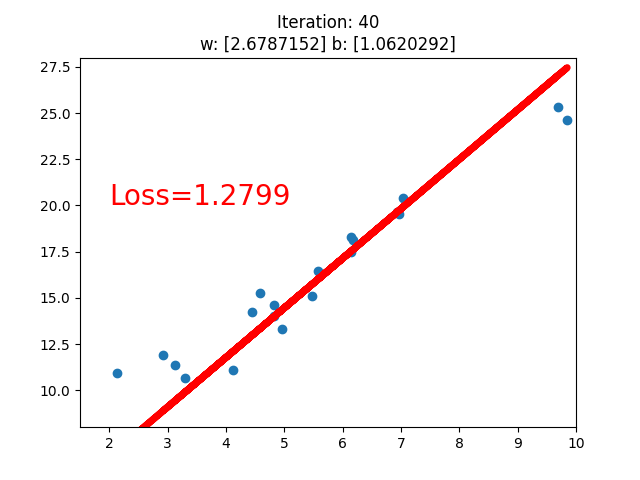
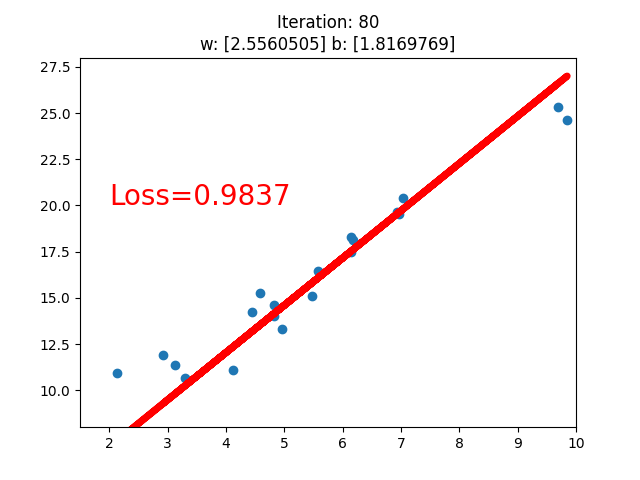
应用:线性回归
线性回归是分析一个变量与另外一(多)个变量之间关系的方法。
因变量:y
自变量 x
关系 :线性 y =wx + b
分析:求解 w b
求解步骤
-
确定模型 Model:y = wx + b
-
选择损失函数 MSE:
-
求解梯度并更新 w,b
w = w-LR * w.grad
b = b-LR * w.grad
code:
import torch
import matplotlib.pyplot as plt
torch.manual_seed(10)
lr = 0.05
# Create training data
x = torch.rand(20, 1) * 10 # x data (tensor), shape=(20, 1)
y = 2*x + (5 + torch.randn(20, 1)) # y data (tensor), shape=(20, 1)
# Build Linear Regression Parameters
# Initialize w and b, where w is initialized to a normal distribution and b is initialized to 0
# Automatic differentiation is required, so set requires grad to True.
w = torch.randn((1), requires_grad=True)
b = torch.zeros((1), requires_grad=True)
for iteration in range(1000):
# forward propagation
wx = torch.mul(w, x)
y_pred = torch.add(wx, b)
# Calculate MSE loss
loss = (0.5 * (y - y_pred) ** 2).mean()
# backpropagation
loss.backward()
# update parameters
b.data.sub_(lr * b.grad)
w.data.sub_(lr * w.grad)
# zeroing out the gradient of a tensor
w.grad.zero_()
b.grad.zero_()
# Draw
if iteration % 20 == 0:
plt.scatter(x.data.numpy(), y.data.numpy())
plt.plot(x.data.numpy(), y_pred.data.numpy(), 'r-', lw=5)
plt.text(2, 20, 'Loss=%.4f' % loss.data.numpy(), fontdict={'size': 20, 'color': 'red'})
plt.xlim(1.5, 10)
plt.ylim(8, 28)
plt.title("Iteration: {}\nw: {} b: {}".format(iteration, w.data.numpy(), b.data.numpy()))
plt.pause(0.5)
if loss.data.numpy() < 1:
break
可以看到,经过不断地迭代之后。逐渐收敛,当Loss值小于1时停止迭代。



- 点赞
- 收藏
- 关注作者
评论(0)