Google Earth Engine——使用 R、dplyr 和 ggplot 可视化科罗拉多州丹佛市的每小时交通犯罪数据

【摘要】
丹佛市在其开放数据目录中公开保存过去五年的犯罪数据。在本教程中,我们将使用 R 访问和可视化这些数据,这些数据本质上是具有犯罪类型、社区等特征的时空参考点。
首先,我们将加载一些稍后会用到的包。
library(dplyr)library(ggplot2)library(lubridate)
然后,我们需要...
丹佛市在其开放数据目录中公开保存过去五年的犯罪数据。在本教程中,我们将使用 R 访问和可视化这些数据,这些数据本质上是具有犯罪类型、社区等特征的时空参考点。
首先,我们将加载一些稍后会用到的包。
-
library(dplyr)
-
library(ggplot2)
-
library(lubridate)
然后,我们需要下载包含原始数据的逗号分隔值文件。
-
data_url <- "https://www.denvergov.org/media/gis/DataCatalog/crime/csv/crime.csv"
-
d <- read.csv(data_url)
让我们将列名小写,并用str()函数查看数据的结构。
-
names(d) <- tolower(names(d))
-
str(d)
-
## 'data.frame': 479762 obs. of 19 variables:
-
## $ incident_id : num 2.02e+09 2.02e+09 2.02e+10 2.02e+10 2.02e+09 ...
-
## $ offense_id : num 2.02e+15 2.02e+15 2.02e+16 2.02e+16 2.02e+15 ...
-
## $ offense_code : int 2399 5441 2399 2308 5016 1316 5499 5499 7399 1102 ...
-
## $ offense_code_extension: int 0 0 1 0 0 0 0 0 2 0 ...
-
## $ offense_type_id : chr "theft-other" "traffic-accident" "theft-bicycle" "theft-from-bldg" ...
-
## $ offense_category_id : chr "larceny" "traffic-accident" "larceny" "larceny" ...
-
## $ first_occurrence_date : chr "12/27/2018 3:58:00 PM" "11/13/2015 7:45:00 AM" "6/8/2017 1:15:00 PM" "12/7/2019 1:07:00 PM" ...
-
## $ last_occurrence_date : chr "" "" "6/8/2017 5:15:00 PM" "12/7/2019 6:30:00 PM" ...
-
## $ reported_date : chr "12/27/2018 4:51:00 PM" "11/13/2015 8:38:00 AM" "6/12/2017 8:44:00 AM" "12/9/2019 1:35:00 PM" ...
-
## $ incident_address : chr "2681 N HANOVER CT" "4100 BLOCK W COLFAX AVE" "1705 17TH ST" "1350 N IRVING ST" ...
-
## $ geo_x : int 3178210 3129148 3140790 3132400 3188580 3142086 3152605 3148176 3143312 NA ...
-
## $ geo_y : int 1700715 1694748 1699792 1694088 1716158 1699093 1710822 1694866 1690483 NA ...
-
## $ geo_lon : num -105 -105 -105 -105 -105 ...
-
## $ geo_lat : num 39.8 39.7 39.8 39.7 39.8 ...
-
## $ district_id : int 5 1 6 1 5 6 2 6 1 6 ...
-
## $ precinct_id : int 512 122 612 122 521 612 212 623 123 611 ...
-
## $ neighborhood_id : chr "stapleton" "west-colfax" "union-station" "west-colfax" ...
-
## $ is_crime : int 1 0 1 1 1 1 1 1 1 1 ...
-
## $ is_traffic : int 0 1 0 0 0 0 0 0 0 0 ...
下面的代码使用该dplyr包对数据进行子集化以仅包括交通事故犯罪 ( filter(...)),并解析日期/时间列,以便我们可以提取诸如小时-分钟(以评估一天中的模式)、当天周(例如,1 = 星期日,2 = 星期一,...)和年(一年中的哪一天?),使用mutate()函数为这些变量创建新列。
-
accidents <- d %>%
-
filter(offense_type_id == "traffic-accident") %>%
-
mutate(datetime = mdy_hms(first_occurrence_date, tz = "MST"),
-
hr = hour(datetime),
-
dow = wday(datetime),
-
yday = yday(datetime))
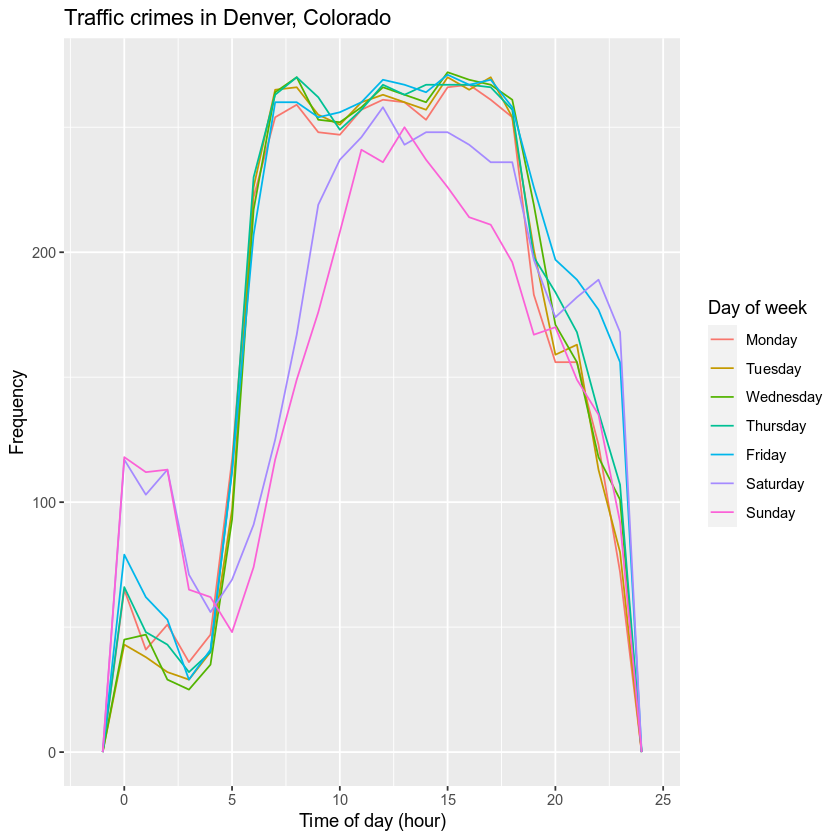
最后,我们将按小时和星期几对数据进行分组,对于这两个数量的每种组合,计算交通事故犯罪的数量。然后我们将创建一个新变量day,它是数字dow列 (1, 2, ...)的字符表示形式 (Sunday, Monday , ...)。我们还将创建一个新变量offense_type,它是该offense-type-id列的更易于阅读的版本。使用 ggplot,我们将为一周中的每一天创建一个带有颜色的密度图。此工作流用于dplyr处理我们的数据,然后将结果通过管道传输到ggplot2,以便我们在全局环境中仅创建一个对象p,即我们的绘图。
-
p <- accidents %>%
-
count(hr, dow, yday, offense_type_id) %>%
-
# the call to mutate() makes new variables with better names
-
mutate(day = factor(c("Sunday", "Monday", "Tuesday",
-
"Wednesday", "Thursday", "Friday",
-
"Saturday")[dow],
-
levels = c("Monday", "Tuesday",
-
"Wednesday", "Thursday", "Friday",
-
"Saturday", "Sunday")),
-
offense_type = ifelse(
-
offense_type_id == "traffic-accident-hit-and-run",
-
"Hit and run",
-
ifelse(
-
offense_type_id == "traffic-accident-dui-duid",
-
"Driving under the influence", "Traffic accident"))) %>%
-
ggplot(aes(x = hr,
-
fill = day,
-
color = day)) +
-
geom_freqpoly(binwidth = 1) + # 60 sec/min * 60 min
-
scale_color_discrete("Day of week") +
-
xlab("Time of day (hour)") +
-
ylab("Frequency") +
-
ggtitle("Traffic crimes in Denver, Colorado")
-
p
文章来源: blog.csdn.net,作者:此星光明2021年博客之星云计算Top3,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/qq_31988139/article/details/120538160

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)