MapReduce切片机制

【摘要】
MapReduce切片机制
为什么需要切片
MapReduce是一个分布式计算框架,处理的是海量数据的计算。那么并行运算必不可免,但是到底并行多少个Map任务来计算呢?每个Map任务计算哪些数据呢...
MapReduce切片机制
为什么需要切片
MapReduce是一个分布式计算框架,处理的是海量数据的计算。那么并行运算必不可免,但是到底并行多少个Map任务来计算呢?每个Map任务计算哪些数据呢?这些我们数据我们不能够凭空估计,只能根据实际数据的存储情况来动态分配,而我们要介绍的切片就是要解决这个问题,
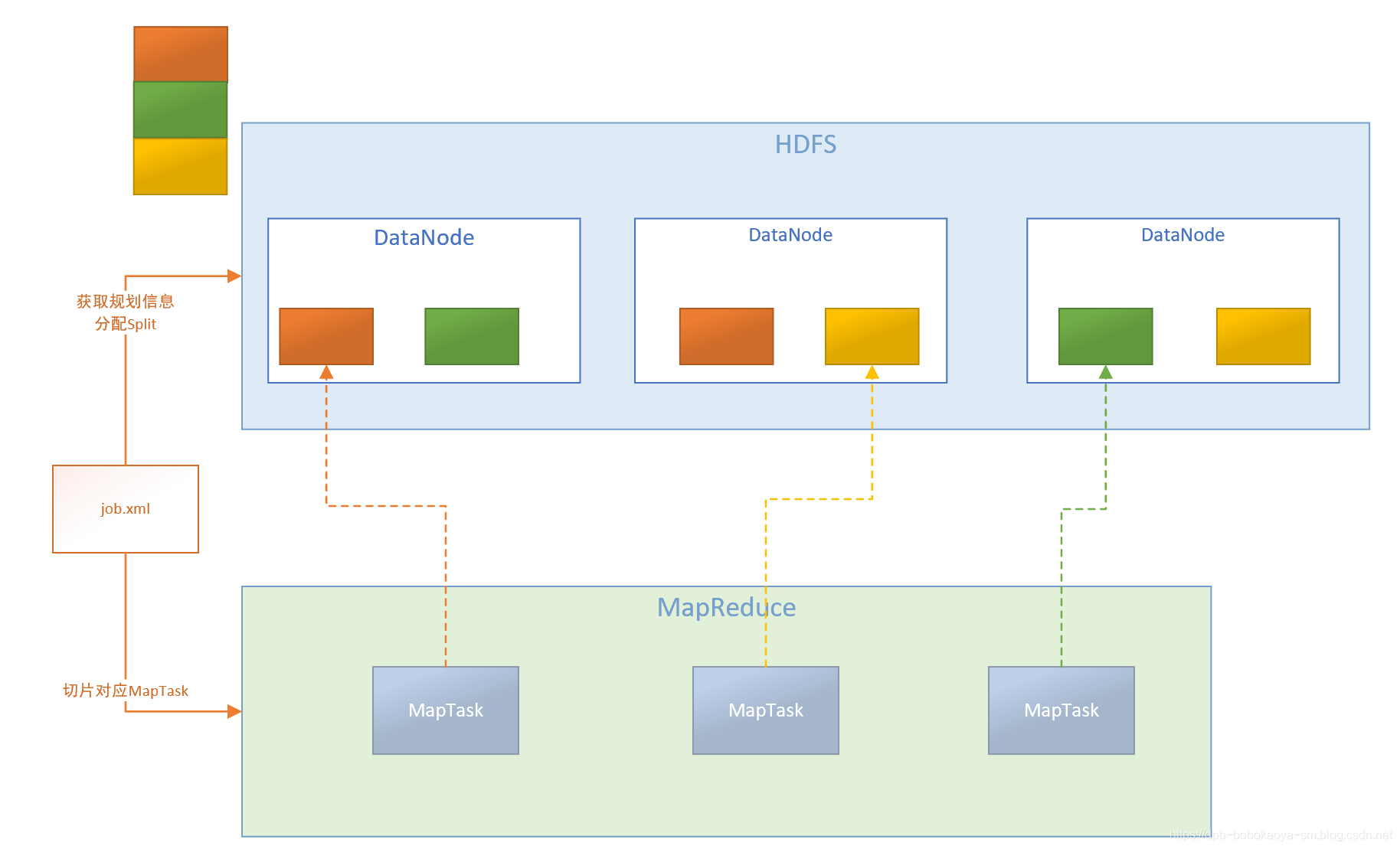
切片机制原理
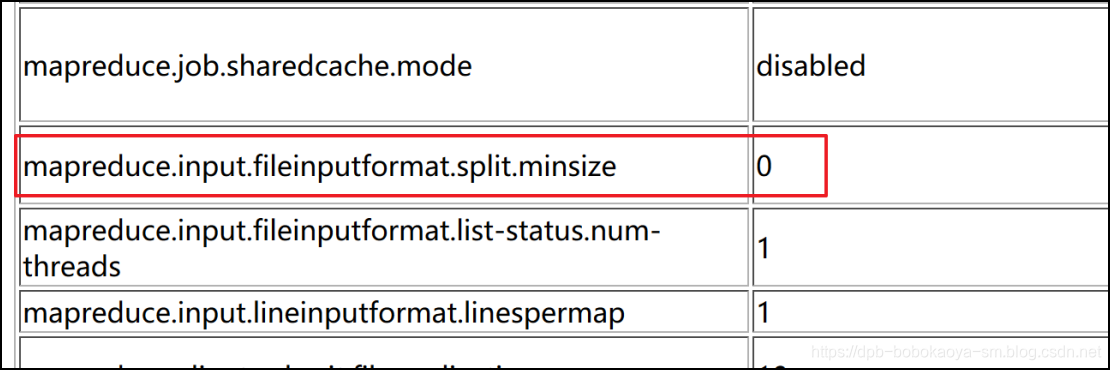
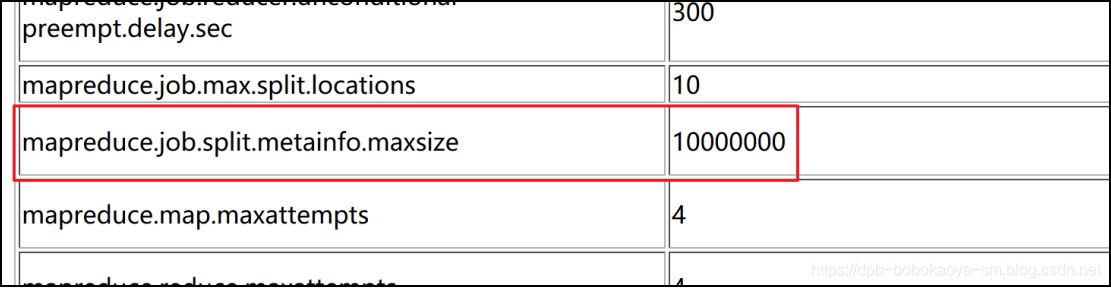
切片的规则我们需要通过阅读源代码来了解。首先我们来看下hadoop中默认的两个参数配置
1.默认参数
mapreduce.job.split.metainfo.maxsize 10000000
mapreduce.input.fileinputformat.split.minsize 0
- 1
- 2
2. 源码查看





注意:SPLIT_SLOP = 1.1,即当划分后剩余文件大小除splitSize大于1.1时,循环继续,小于1.1时退出循环,将剩下的文件大小归到一个切片上去。
// 128MB
long blockSize = file.getBlockSize();
// 128MB
long splitSize = computeSplitSize(blockSize, minSize, maxSize);
// 文件的大小 260MB
long bytesRemaining = length;
// 第一次 260/128=2.x > 1.1
// 第二次 132/128=1.03 <1.1 不执行循环
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
// 获取块的索引
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
// 将块的信息保存到splits集合中
splits.add(makeSplit(path, length-bytesRemaining, splitSize,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
// 260-128=132MB
bytesRemaining -= splitSize;
}
// 将剩余的132MB添加到splits集合中
if (bytesRemaining != 0) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(makeSplit(path, length-bytesRemaining, bytesRemaining,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
3.切片总结
FileInputFormat中默认的切片机制
- 简单地按照文件的内容长度进行切片
- 切片大小,默认等于block大小,可以通过调整参数修改,注意1.1的问题
- 切片时不考虑数据集整体,而是逐个针对每一个文件单独切片
- 一个切片(split)对应一个MapTask事例
- 一个job的map阶段并行度由客户端在提交job时决定
比如待处理数据有两个文件:
file1.txt 260M
file2.txt 10M
经过FileInputFormat的切片机制运算后,形成的切片信息如下
file1.txt.split1-- 0~128
file1.txt.split2-- 128~260
file2.txt.split1-- 0~10M。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
文章来源: dpb-bobokaoya-sm.blog.csdn.net,作者:波波烤鸭,版权归原作者所有,如需转载,请联系作者。
原文链接:dpb-bobokaoya-sm.blog.csdn.net/article/details/89031776

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)