数据仓库设计规范(更新中)

设计规范
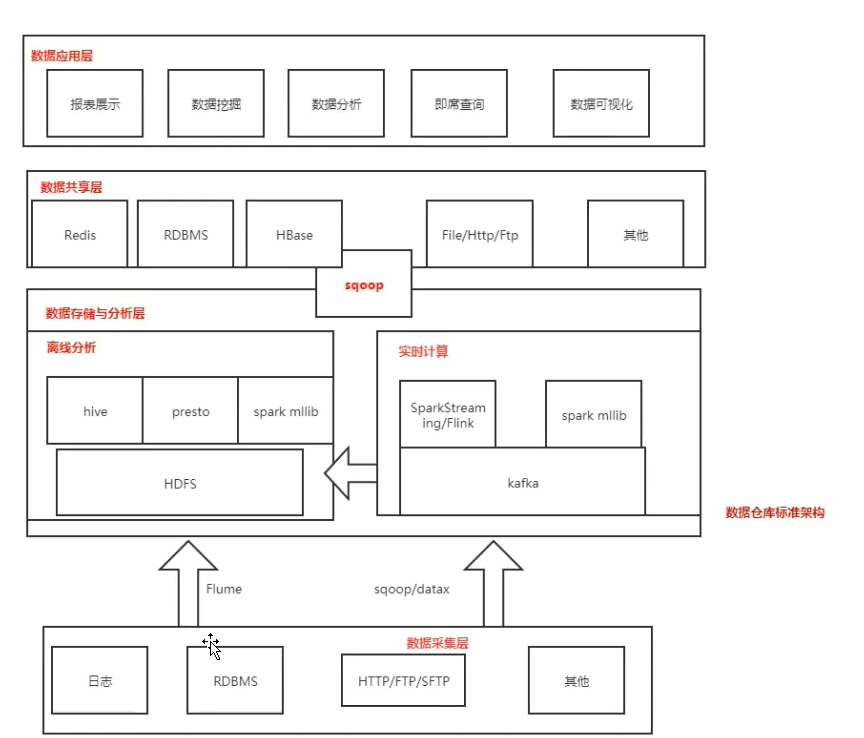
逻辑架构
-
数据采集
数据采集层:数据采集层的任务就是把数据从各种数据源中采集和存储到数据库上,期间有可能会做一些ETL (抽取extra,转化transfer,装载load )操作。
数据源种类可以有多种:
日志:所占份额最大;
存储在备份服务器上业务数据库:如Mysg|、 Oracle ;
来自HTTP/FTP的数据:合作伙伴提供的接口
其他数据源:如Excel等需要手工录入的数据. -
数据存储
-
数据计算
HDFS是大数据环境下数据仓库/数据平台最完美的数据存储解决方案。离线数据分析与计算,也就是对实时性要求不高的部分,Hive 是不错的选择。使用Hadoop框架自然而然也提供了MapReduce 接口,如果可以开发Java,或者对SQL不熟,那么也可以使用MapReduce来做分析与计算。
Spark性能比MapReduce好很多,同时使用SparkSQL操作Hive。
- 数据展现
技术架构
数据采集→Kafka→hdfs→Flink→HBase
分层设计
ods→dw→dws→sh→
数据仓库的要求
- 高效率:数据仓库的分析数据一般分为日、周、月、季、年等,可以看出,以日为周期的数据要求的效率最高,要求24小时甚至12小时内,客户能看到昨天的数据分析。由于有的企业每日的数据量很大,如果数据仓库设计的不好,需要延时一-到两天才能显示数据,这显然是不能出现这种事情的。
- 高质量:数据仓库所提供的各种信息,肯定要准确的数据。数据仓库通常要经过数据清洗,装载,查询,展现等多个流程而得到的,如果复杂的架构会有更多层次,那么由于数据源有脏数据或者代码不严谨,都可以导致数据不准确或者有错误,如果客户看到错误的信息就可能导致分析出错误的决策,造成损失经济的损失。
- 高扩展性:之所以有的大型数据仓库系统架构设计复杂,是因为考虑到了未来3-5年的扩展.性,因为如果在未来需要扩展一些新的功能了,就可以不用重建数据仓库系统,就能很稳定运行。因为重建-一个数据仓库是比较耗费人力和财力。可扩展性主要体现在数据建模的合理性。
为了达到上述的要求,建立起一个高效率、高数据质量、良好的可扩展性,再加上为了提高建仓的速度,根据在实际生产环境中的经验的总结,于是数据仓库需要分层。
数据仓库分层的原因
1、用空间换时间,通过数据预处理提高效率,通过大量的预处理可以提升应用系统的用户体验(效率),但是数据仓库会存在大量冗余的数据.
2、增强可扩展性,方便以后业务的变更。如果不分层的话,当源业务系统的业务规则发生变化整个数据仓库需要重建,这样将会影响整个数据清洗过程,工作量巨大。
3、通过分层管理来实现分步完成工作,简化数据清洗的过程,使每一层处理逻辑变得更简单。因为把原来一步的工作分到了多个步骤去完成,相当于把一个复杂的工作拆成了多个简单的工作,把-一个大的黑盒变成了一个白盒,每一层的处理逻辑都相对简单和容易理解,这样我们比较容易保证每一个步骤的正确性,当数据发生错误的时候,往往我们只需要局部调整某个步骤即可。
数据仓库具体的分层
标准的数据仓库分层: stg(数据缓冲层), ods (数据贴源层),dw:dwd dws dwt (数据仓库
层),ads (数据集市层),app (应用层)。
stg:源数据缓冲层,它和源系统数据是同构的,而且这一层数据粒度是最细的,数据层与
业务源的数据结构- – -对应,是数据存储的临时存储区域,数据在其中只作暂时性保存,当新的数据到达缓储区时,现有数据被删除或覆盖。
主题划分
-
面向主题域管理
为了提高指标管理的效率,你需要按照业务线,主题域,和业务过程三级目录方式来进行指标管理 -
划分原子指标和派生指标
原子指标+原子指标=派生指标 -
进行指标的命名规范
原则:简单易懂+统一
易懂:直接判断这个指标到底属于那个业务过程
统一:确保派生指标和它继承的原子指标命名是一致的 -
对于原子指标,指标名适用与”动作+度量"的命名方式
例子:注册用户数登录用户贷款申请用户数 -
对于派生指标来说,严格遵循“时间周期 +统计粒度+修饰词+原子指标”
30天90天内+ 12期内无逾期用户
分级管理
指标比较多,很难管理,所以需要按照原则或者等级进行划分
一级指标:核心指标领导看的
二级指标:原子指标和业务 部门门创建的派生指标
命名规范
层级
根据主题划分
ods→dw→dws→sh→ads
任务
按照天月日等等
表
- 常规表
使我们需要固化的表,正常使用的,没有下线的,长时间去维护的表。
规范:分层前缀[dwd|dws|ads|app].业务域(CMIS/CMS/APP)主题域(event) xxx_ 更新频率(all/inc)增量/全量。
dwd.xxx_XX_all每日全量
dwd.xxx_xx_inc每日增量
dwd.xxx_XXX_month_all每月全量
dwd.xxx_XXX_month_inc每月增量
- 1
- 2
- 3
- 4
-
中间表/临时表
temp/mid_ table_ name_ time (20210705) dim/ods -
维度表:
维度表基于底层数据,抽象出来具有描述性质的表。也可以手动维护。
dim.xxxx
字段
表和列的注释是否有缺失,复杂的指标计算逻辑是有注释
模型规范
建模方法
建模工具
血缘关系
维度退化
元数据管理
开发规范
任务是否支持多次重跑而输出不变,不能有insert into这个语句
脚本注释
字段别名
脚本格式
流程规范
- 参与角色 : 数据产品经理+数据分析师+ 运营+开发人员
- 需求 分析: 提出需求→需求分析→需求评审→ETL设计→单元测试→线上冒烟测试→数
- 设计阶段:模型设计
- 开发阶段:代码开发
- 测试阶段:自测
- 发布验收:上线
文章来源: hiszm.blog.csdn.net,作者:孙中明,版权归原作者所有,如需转载,请联系作者。
原文链接:hiszm.blog.csdn.net/article/details/120623653

- 点赞
- 收藏
- 关注作者
评论(0)