2021年大数据Spark(三十七):SparkStreaming实战案例二 UpdateStateByKey

【摘要】
目录
SparkStreaming实战案例二 UpdateStateByKey
需求
1.updateStateByKey
2.mapWithState
代码实现
SparkStreaming实战案例二 UpdateStateByKey
需求
对从Socket接收的数据做WordCount并要求能够和历史数据进行累加!...
目录
SparkStreaming实战案例二 UpdateStateByKey
SparkStreaming实战案例二 UpdateStateByKey
需求
对从Socket接收的数据做WordCount并要求能够和历史数据进行累加!
如:
先发了一个spark,得到spark,1
然后不管隔多久再发一个spark,得到spark,2
也就是说要对数据的历史状态进行维护!
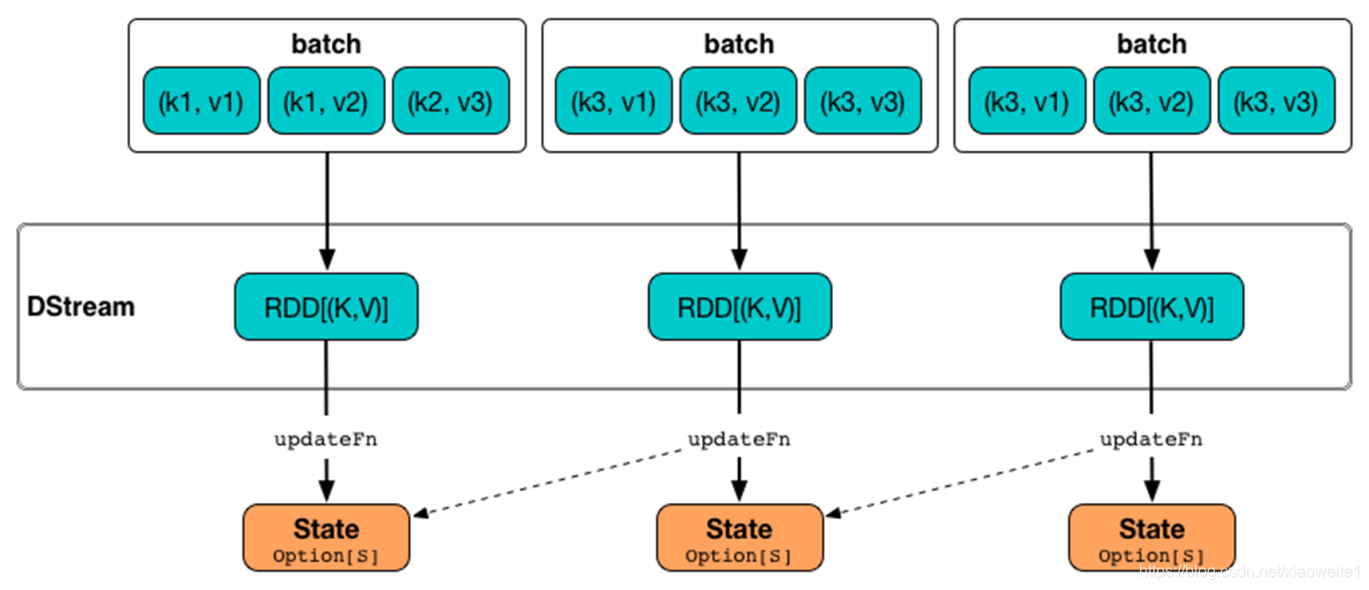
注意:可以使用如下API对状态进行维护
1.updateStateByKey
统计全局的key的状态,但是就算没有数据输入,他也会在每一个批次的时候返回之前的key的状态。假设5s产生一个批次的数据,那么5s的时候就会更新一次的key的值,然后返回。
这样的缺点就是,如果数据量太大的话,而且我们需要checkpoint数据,这样会占用较大的存储。
如果要使用updateStateByKey,就需要设置一个checkpoint目录,开启checkpoint机制。因为key的state是在内存维护的,如果宕机,则重启之后之前维护的状态就没有了,所以要长期保存它的话需要启用checkpoint,以便恢复数据。
2.mapWithState
也是用于全局统计key的状态,但是它如果没有数据输入,便不会返回之前的key的状态,有一点增量的感觉。
这样做的好处是,我们可以只是关心那些已经发生的变化的key,对于没有数据输入,则不会返回那些没有变化的key的数据。这样的话,即使数据量很大,checkpoint也不会像updateStateByKey那样,占用太多的存储。
代码实现
-
package cn.itcast.streaming
-
-
import org.apache.spark.rdd.RDD
-
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
-
import org.apache.spark.streaming.{Seconds, State, StateSpec, StreamingContext}
-
import org.apache.spark.{SparkConf, SparkContext}
-
-
/**
-
* 使用SparkStreaming接收Socket数据,node01:9999
-
* 对从Socket接收的数据做WordCount并要求能够和历史数据进行累加!
-
* 如:
-
* 先发了一个spark,得到spark,1
-
* 然后不管隔多久再发一个spark,得到spark,2
-
* 也就是说要对数据的历史状态进行维护!
-
*/
-
object SparkStreamingDemo02_UpdateStateByKey {
-
def main(args: Array[String]): Unit = {
-
//1.创建环境
-
val conf: SparkConf = new SparkConf().setAppName(this.getClass.getSimpleName.stripSuffix("$")).setMaster("local[*]")
-
val sc: SparkContext = new SparkContext(conf)
-
sc.setLogLevel("WARN")
-
//batchDuration the time interval at which streaming data will be divided into batches
-
//流数据将被划分为批的时间间隔,就是每隔多久对流数据进行一次微批划分!
-
val ssc: StreamingContext = new StreamingContext(sc, Seconds(5))
-
-
// The checkpoint directory has not been set. Please set it by StreamingContext.checkpoint()
-
//注意:因为涉及到历史数据/历史状态,也就是需要将历史数据/状态和当前数据进行合并,作为新的Value!
-
//那么新的Value要作为下一次的历史数据/历史状态,那么应该搞一个地方存起来!
-
//所以需要设置一个Checkpoint目录!
-
ssc.checkpoint("./ckp")
-
-
//2.接收socket数据
-
val linesDS: ReceiverInputDStream[String] = ssc.socketTextStream("node1",9999)
-
-
//3.做WordCount
-
//======================updateStateByKey=======================
-
//val 函数名称 :(参数类型)=>函数返回值类型 = (参数名称:参数类型)=>{函数体}
-
//参数1:Seq[Int]:当前批次的数据,如发送了2个spark,那么key为spark,参数1为:Seq[1,1]
-
//参数2:Option[Int]:上一次该key的历史值!注意:历史值可能有可能没有!如果没有默认值应该为0,如果有就取出来
-
//返回值:Option[Int]:当前批次的值+历史值!
-
//Option表示:可能有Some可能没有None
-
val updateFunc= (currentValues:Seq[Int],historyValue:Option[Int])=>{
-
//将当前批次的数据和历史数据进行合并作为这一次新的结果!
-
if (currentValues.size > 0) {
-
val newValue: Int = currentValues.sum + historyValue.getOrElse(0)//getOrElse(默认值)
-
Option(newValue)
-
}else{
-
historyValue
-
}
-
}
-
-
val resultDS: DStream[(String, Int)] = linesDS
-
.flatMap(_.split(" "))
-
.map((_, 1))
-
//.reduceByKey(_ + _)
-
// updateFunc: (Seq[V], Option[S]) => Option[S]
-
.updateStateByKey(updateFunc)
-
-
//======================mapWithState=======================
-
//Spark 1.6提供新的状态更新函数【mapWithState】,mapWithState函数也会统计全局的key的状态,
-
//但是如果没有数据输入,便不会返回之前的key的状态,只是关心那些已经发生的变化的key,对于没有数据输入,则不会返回那些没有变化的key的数据。
-
val mappingFunc = (word: String, current: Option[Int], state: State[Int]) => {
-
val newCount = current.getOrElse(0) + state.getOption.getOrElse(0)
-
val output = (word, newCount)
-
state.update(newCount)
-
output
-
}
-
-
val resultDS2 = linesDS
-
.flatMap(_.split(" "))
-
.map((_, 1))
-
.mapWithState(StateSpec.function(mappingFunc))
-
-
-
//4.输出
-
resultDS.print()
-
resultDS2.print()
-
-
//5.启动并等待程序停止
-
// 对于流式应用来说,需要启动应用
-
ssc.start()
-
// 流式应用启动以后,正常情况一直运行(接收数据、处理数据和输出数据),除非人为终止程序或者程序异常停止
-
ssc.awaitTermination()
-
// 关闭流式应用(参数一:是否关闭SparkContext,参数二:是否优雅的关闭)
-
ssc.stop(stopSparkContext = true, stopGracefully = true)
-
}
-
}
文章来源: lansonli.blog.csdn.net,作者:Lansonli,版权归原作者所有,如需转载,请联系作者。
原文链接:lansonli.blog.csdn.net/article/details/115985521

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)