2021年大数据Spark(二十七):SparkSQL案例一花式查询和案例二WordCount

目录
案例一:花式查询
-
package cn.itcast.sql
-
-
import org.apache.spark.SparkContext
-
import org.apache.spark.rdd.RDD
-
import org.apache.spark.sql.{DataFrame, SparkSession}
-
-
/**
-
* Author itcast
-
* Desc 演示SparkSQL的各种花式查询
-
*/
-
object FlowerQueryDemo {
-
case class Person(id:Int,name:String,age:Int)
-
-
def main(args: Array[String]): Unit = {
-
//1.准备环境-SparkSession
-
val spark: SparkSession = SparkSession.builder().appName("SparkSQL").master("local[*]").getOrCreate()
-
val sc: SparkContext = spark.sparkContext
-
sc.setLogLevel("WARN")
-
-
//2.加载数据
-
val lines: RDD[String] = sc.textFile("data/input/person.txt")
-
-
//3.切割
-
//val value: RDD[String] = lines.flatMap(_.split(" "))//错误的
-
val linesArrayRDD: RDD[Array[String]] = lines.map(_.split(" "))
-
-
//4.将每一行(每一个Array)转为样例类(相当于添加了Schema)
-
val personRDD: RDD[Person] = linesArrayRDD.map(arr=>Person(arr(0).toInt,arr(1),arr(2).toInt))
-
-
//5.将RDD转为DataFrame(DF)
-
//注意:RDD的API中没有toDF方法,需要导入隐式转换!
-
import spark.implicits._
-
val personDF: DataFrame = personRDD.toDF
-
-
//6.查看约束
-
personDF.printSchema()
-
-
//7.查看分布式表中的数据集
-
personDF.show(6,false)//false表示不截断列名,也就是列名很长的时候不会用...代替
-
-
-
//演示SQL风格查询
-
//0.注册表名
-
//personDF.registerTempTable("t_person")//已经过时
-
//personDF.createTempView("t_person")//创建表,如果已存在则报错:TempTableAlreadyExistsException
-
//personDF.createOrReplaceGlobalTempView("t_person")//创建全局表,可以夸session使用,查询的时候使用:SELECT * FROM global_temp.表名;生命周期太大,一般不用
-
personDF.createOrReplaceTempView("t_person")//创建一个临时表,只有当前session可用!且表如果存在会替换!
-
-
//1.查看name字段的数据
-
spark.sql("select name from t_person").show
-
//2.查看 name 和age字段数据
-
spark.sql("select name,age from t_person").show
-
//3.查询所有的name和age,并将age+1
-
spark.sql("select name,age,age+1 from t_person").show
-
//4.过滤age大于等于25的
-
spark.sql("select name,age from t_person where age >=25").show
-
//5.统计年龄大于30的人数
-
spark.sql("select count(age) from t_person where age >30").show
-
//6.按年龄进行分组并统计相同年龄的人数
-
spark.sql("select age,count(age) from t_person group by age").show
-
-
-
//演示DSL风格查询
-
//1.查看name字段的数据
-
import org.apache.spark.sql.functions._
-
personDF.select(personDF.col("name")).show
-
personDF.select(personDF("name")).show
-
personDF.select(col("name")).show
-
personDF.select("name").show
-
-
//2.查看 name 和age字段数据
-
personDF.select(personDF.col("name"),personDF.col("age")).show
-
personDF.select("name","age").show
-
-
//3.查询所有的name和age,并将age+1
-
//personDF.select("name","age","age+1").show//错误,没有age+1这一列
-
//personDF.select("name","age","age"+1).show//错误,没有age1这一列
-
personDF.select(col("name"),col("age"),col("age")+1).show
-
personDF.select($"name",$"age",$"age"+1).show
-
//$表示将"age"变为了列对象,先查询再和+1进行计算
-
personDF.select('name,'age,'age+1).show
-
//'表示将age变为了列对象,先查询再和+1进行计算
-
-
-
//4.过滤age大于等于25的,使用filter方法/where方法过滤
-
personDF.select("name","age").filter("age>=25").show
-
personDF.select("name","age").where("age>=25").show
-
-
//5.统计年龄大于30的人数
-
personDF.where("age>30").count()
-
-
//6.按年龄进行分组并统计相同年龄的人数
-
personDF.groupBy("age").count().show
-
-
}
-
-
}
案例二:WordCount
前面使用RDD封装数据,实现词频统计WordCount功能,从Spark 1.0开始,一直到Spark 2.0,建立在RDD之上的一种新的数据结构DataFrame/Dataset发展而来,更好的实现数据处理分析。DataFrame 数据结构相当于给RDD加上约束Schema,知道数据内部结构(字段名称、字段类型),提供两种方式分析处理数据:DataFrame API(DSL编程)和SQL(类似HiveQL编程),下面以WordCount程序为例编程实现,体验DataFrame使用。
基于DSL编程
使用SparkSession加载文本数据,封装到Dataset/DataFrame中,调用API函数处理分析数据(类似RDD中API函数,如flatMap、map、filter等),编程步骤:
第一步、构建SparkSession实例对象,设置应用名称和运行本地模式;
第二步、读取HDFS上文本文件数据;
第三步、使用DSL(Dataset API),类似RDD API处理分析数据;
第四步、控制台打印结果数据和关闭SparkSession;
基于SQL编程
也可以实现类似HiveQL方式进行词频统计,直接对单词分组group by,再进行count即可,步骤如下:
第一步、构建SparkSession对象,加载文件数据,分割每行数据为单词;
第二步、将DataFrame/Dataset注册为临时视图(Spark 1.x中为临时表);
第三步、编写SQL语句,使用SparkSession执行获取结果;
第四步、控制台打印结果数据和关闭SparkSession;
具体演示代码如下:
-
package cn.itcast.sql
-
-
import org.apache.spark.SparkContext
-
import org.apache.spark.rdd.RDD
-
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession}
-
-
/**
-
* Author itcast
-
* Desc 使用SparkSQL完成WordCount---SQL风格和DSL风格
-
*/
-
object WordCount {
-
def main(args: Array[String]): Unit = {
-
//1.准备环境
-
val spark: SparkSession = SparkSession.builder().appName("WordCount").master("local[*]").getOrCreate()
-
val sc: SparkContext = spark.sparkContext
-
sc.setLogLevel("WARN")
-
import spark.implicits._
-
-
//2.加载数据
-
//val rdd: RDD[String] = sc.textFile("data/input/words.txt")//可以使用该方式,然后使用昨天的知识将rdd转为df/ds
-
val df: DataFrame = spark.read.text("data/input/words.txt")
-
val ds: Dataset[String] = spark.read.textFile("data/input/words.txt")
-
//df.show()//查看分布式表数据
-
//ds.show()//查看分布式表数据
-
-
-
//3.做WordCount
-
//切割
-
//df.flatMap(_.split(" ")) //注意:直接这样写报错!因为df没有泛型,不知道_是String!
-
//df.flatMap(row=>row.getAs[String]("value").split(" "))
-
val wordsDS: Dataset[String] = ds.flatMap(_.split(" "))
-
//wordsDS.show()
-
-
//使用SQL风格做WordCount
-
wordsDS.createOrReplaceTempView("t_words")
-
val sql:String =
-
"""
-
|select value,count(*) as count
-
|from t_words
-
|group by value
-
|order by count desc
-
|""".stripMargin
-
spark.sql(sql).show()
-
-
//使用DSL风格做WordCount
-
wordsDS
-
.groupBy("value")
-
.count()
-
.orderBy($"count".desc)
-
.show()
-
-
/*
-
+-----+-----+
-
|value|count|
-
+-----+-----+
-
|hello| 4|
-
| her| 3|
-
| you| 2|
-
| me| 1|
-
+-----+-----+
-
-
+-----+-----+
-
|value|count|
-
+-----+-----+
-
|hello| 4|
-
| her| 3|
-
| you| 2|
-
| me| 1|
-
+-----+-----+
-
*/
-
-
}
-
}
无论使用DSL还是SQL编程方式,底层转换为RDD操作都是一样,性能一致,查看WEB UI监控中Job运行对应的DAG图如下:
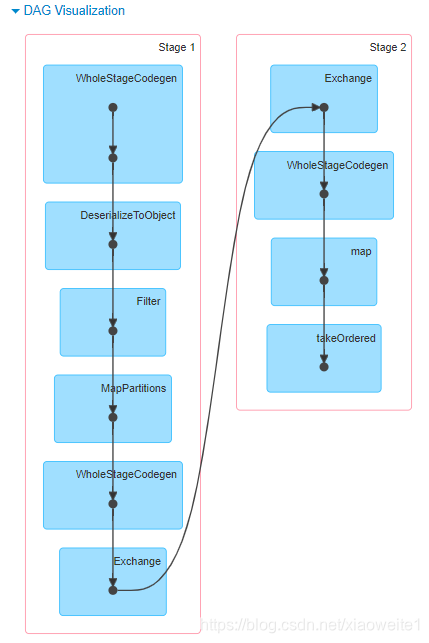
从上述的案例可以发现将数据封装到Dataset/DataFrame中,进行处理分析,更加方便简洁,这就是Spark框架中针对结构化数据处理模:Spark SQL模块。
官方文档:http://spark.apache.org/sql/
文章来源: lansonli.blog.csdn.net,作者:Lansonli,版权归原作者所有,如需转载,请联系作者。
原文链接:lansonli.blog.csdn.net/article/details/115793854

- 点赞
- 收藏
- 关注作者
评论(0)