MapReduce 教程 – MapReduce 基础知识和 MapReduce 示例

MapReduce 教程:简介
在这篇 MapReduce 教程博客中,我将向您介绍 MapReduce,它是 Hadoop 框架中处理的核心构建块之一。在继续之前,我建议您熟悉我在之前的HDFS 教程博客中介绍的 HDFS 概念。这将帮助您快速轻松地理解 MapReduce 概念。
在开始之前,让我们对以下内容做一个简单的了解。
什么是大数据?

大数据可以称为海量数据,传统的数据处理单元几乎无法处理这些数据。大数据的一个更好的例子是目前流行的社交媒体网站,如 Facebook、Instagram、WhatsApp 和 YouTube。

什么是Hadoop?
Hadoop 是由 Apache Foundation 设计和部署的大数据框架。它是一种开源软件实用程序,可在计算机网络中并行工作,以找到大数据的解决方案并使用 MapReduce 算法对其进行处理。
谷歌在 2004 年 12 月发表了一篇关于 MapReduce 技术的论文。这成为了 Hadoop 处理模型的起源。因此,MapReduce 是一种编程模型,它允许我们对庞大的数据集进行并行和分布式处理。我在这个 MapReduce 教程博客中涵盖的主题如下:
- 并行和分布式处理的传统方式
- 什么是 MapReduce?
- MapReduce 示例
- MapReduce 的优势
- MapReduce 程序
- MapReduce 程序说明
- MapReduce 用例:KMeans 算法
MapReduce 教程:传统方式
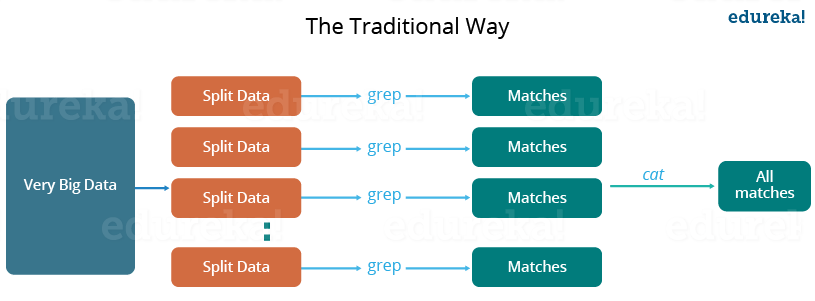
让我们了解一下,当 MapReduce 框架不存在时,并行和分布式处理过去是如何以传统方式发生的。所以,让我们举个例子,我有一个天气日志,其中包含从 2000 年到 2015 年的年平均气温。在这里,我想计算每年温度最高的那一天。
因此,就像传统方式一样,我将数据拆分为更小的部分或块,并将它们存储在不同的机器中。然后,我将找到存储在相应机器中的每个零件的最高温度。最后,我将结合从每台机器接收到的结果以获得最终输出。让我们看看与这种传统方法相关的挑战:
- 关键路径问题:在不延迟下一个里程碑或实际完成日期的情况下完成工作所花费的时间。因此,如果任何 机器延迟工作,整个工作都会被延迟。
- 可靠性问题:如果任何处理部分数据的机器出现故障怎么办?这种故障转移的管理成为一个挑战。
- 等分问题:我将如何将数据分成更小的块,以便每台机器都可以使用部分数据。换句话说,如何平均分配数据,以免单个机器过载或未充分利用。
- 单个拆分可能会失败:如果任何机器无法提供输出,我将无法计算结果。所以,应该有一种机制来保证系统的这种容错能力。
- 结果的聚合: 应该有一种机制来聚合每台机器生成的结果以产生最终输出。
这些是我在使用传统方法并行处理大量数据集时必须单独注意的问题。
为了克服这些问题,我们有 MapReduce 框架,它允许我们执行这样的并行计算,而无需担心可靠性、容错等问题。因此,MapReduce 为您提供了编写代码逻辑的灵活性,而无需关心系统的设计问题.
MapReduce 教程:什么是 MapReduce?
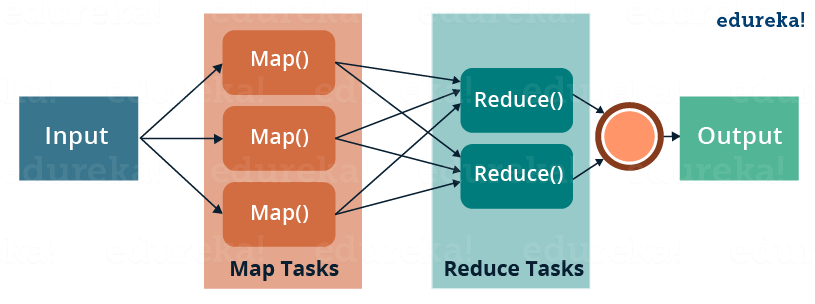
MapReduce 是一个编程框架,它允许我们在分布式环境中对大型数据集进行分布式和并行处理。

大数据Hadoop认证培训课程
- 讲师指导的课程
- 真实案例研究
- 评估
- 终身访问
- MapReduce 由两个不同的任务组成——Map 和 Reduce。
- 正如 MapReduce 名称所暗示的那样,reducer 阶段发生在 mapper 阶段完成之后。
- 因此,第一个是映射作业,其中读取并处理一个数据块以生成键值对作为中间输出。
- Mapper 或 map 作业(键值对)的输出是 Reducer 的输入。
- 减速器从多个映射作业接收键值对。
- 然后,reducer 将这些中间数据元组(中间键值对)聚合成一组较小的元组或键值对,即最终输出。
让我们更多地了解 MapReduce 及其组件。MapReduce 主要有以下三个类。他们是,
映射器类
使用 MapReduce 进行数据处理的第一阶段是Mapper 类。在这里,RecordReader 处理每个 Input 记录并生成相应的键值对。Hadoop 的 Mapper 存储将这些中间数据保存到本地磁盘中。
- 输入拆分
它是数据的逻辑表示。它代表了一个工作块,其中包含 MapReduce 程序中的单个映射任务。
- 记录阅读器
它与 Input split 交互,将得到的数据以Key-Value Pairs的形式进行转换。
减速机类
映射器生成的中间输出被馈送到减速器,减速器对其进行处理并生成最终输出,然后将其保存在HDFS 中。
司机班
MapReduce 作业的主要组件是驱动程序类。它负责设置一个 MapReduce Job 来运行 Hadoop。我们用数据类型和它们各自的作业名称来指定Mapper和Reducer类的名称。
MapReduce 教程:MapReduce 的字数统计示例
让我们通过一个例子来理解 MapReduce 是如何工作的,我有一个 名为 example.txt 的文本文件,其内容如下:
现在,假设我们必须使用 MapReduce 对 sample.txt 执行字数统计。因此,我们将找到独特的词和这些独特词的出现次数。
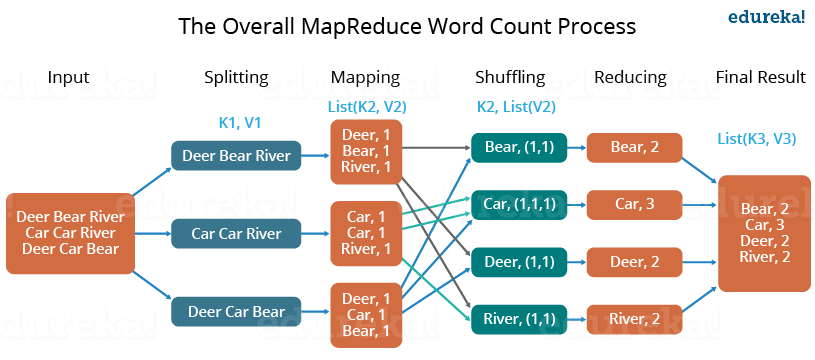
- 首先,我们将输入分成三部分,如图所示。这将在所有地图节点之间分配工作。
- 然后,我们对每个映射器中的单词进行标记,并为每个标记或单词提供一个硬编码值 (1)。将硬编码值设为 1 的基本原理是每个单词本身都会出现一次。
- 现在,将创建一个键值对列表,其中键是单个单词,值是一个。因此,对于第一行(Dear Bear River),我们有 3 个键值对——Dear, 1;熊,1;River, 1. 映射过程在所有节点上保持不变。
- 在映射器阶段之后,会发生分区过程,在该过程中进行排序和混洗,以便将所有具有相同键的元组发送到相应的减速器。
- 因此,在排序和改组阶段之后,每个 reducer 都会有一个唯一的键和与该键对应的值列表。例如熊,[1,1];汽车,[1,1,1]...等
- 现在,每个 Reducer 计算该值列表中存在的值。如图所示,reducer 获取了一个值为 [1,1] 的键 Bear 的值列表。然后,它计算列表中 1 的数量,并给出最终输出 - Bear, 2。
- 最后,然后收集所有输出键/值对并将其写入输出文件中。
MapReduce 教程:MapReduce 的优势
MapReduce 的两个最大优点是:
1.并行处理:
在 MapReduce 中,我们将作业分配给多个节点,每个节点同时处理作业的一部分。因此,MapReduce 基于分而治之的范式,它帮助我们使用不同的机器处理数据。由于数据由多台机器而不是一台机器并行处理,因此处理数据所需的时间大大减少,如下图(2)所示。
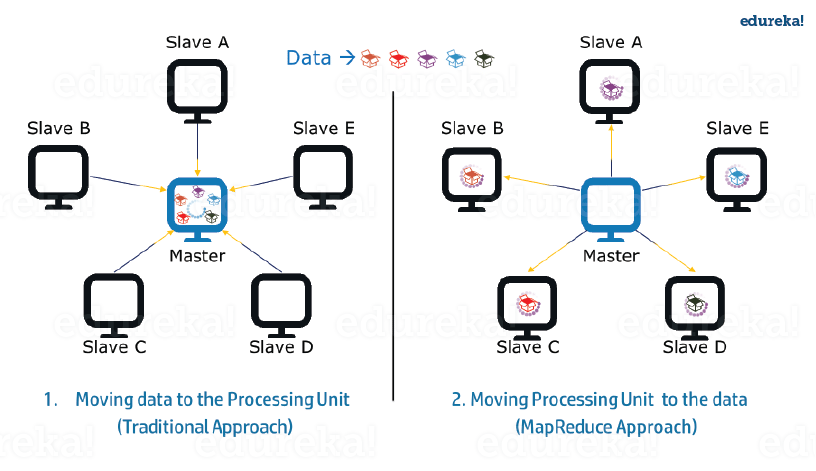
图: 传统方式对比。MapReduce 方式 – MapReduce 教程
2. 数据局部性:
我们不是将数据移动到处理单元,而是将处理单元移动到 MapReduce 框架中的数据。在传统系统中,我们习惯于将数据带到处理单元进行处理。但是,随着数据的增长并变得非常庞大,将大量数据带到处理单元会带来以下问题:
- 将大量数据转移到处理过程中成本高昂,并且会降低网络性能。
- 处理需要时间,因为数据由单个单元处理,这成为瓶颈。
- 主节点可能会负担过重并可能出现故障。
现在,MapReduce 允许我们通过将处理单元带入数据来克服上述问题。因此,正如您在上图中所看到的,数据分布在多个节点之间,每个节点处理驻留在其上的部分数据。这使我们具有以下优势:
MapReduce 教程:MapReduce 示例程序
在深入细节之前,让我们先看一下 MapReduce 示例程序,以便对 MapReduce 环境中的实际工作方式有一个基本的了解。我采用了相同的字数统计示例,我必须找出每个单词的出现次数。不要担心伙计们,如果你不明白当您第一次看到代码时,请耐心等待我引导您完成 MapReduce 代码的每个部分。
MapReduce 教程:MapReduce 程序讲解
整个 MapReduce 程序可以从根本上分为三个部分:
- 映射器阶段代码
- 减速器阶段代码
- 驱动程序代码
我们将依次理解这三个部分的代码。
映射器代码:
public static class Map extends Mapper<LongWritable,Text,Text,IntWritable> {
public void map(LongWritable key, Text value, Context context) throws IOException,InterruptedException {
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
value.set(tokenizer.nextToken());
context.write(value, new IntWritable(1));
}- 我们创建了一个 Map 类,它扩展了 MapReduce 框架中已经定义的类 Mapper。

- 我们在类声明之后使用尖括号定义输入和输出键/值对的数据类型。
- Mapper 的输入和输出都是一个键/值对。
- 输入:
- 的关键是什么,但在文本文件中的每一行的偏移:LongWritable
- 的值是每个单独的线(如图所示在右边的图): 文本
- 输出:
- 的关键是切分词:文本
- 在我们的例子中,我们有硬编码的值是 1:IntWritable
- 示例 – 亲爱的 1、熊 1 等。
- 我们已经编写了一个 java 代码,其中我们对每个单词进行了标记,并为它们分配了一个等于1的硬编码值。

减速机代码:
public static class Reduce extends Reducer<Text,IntWritable,Text,IntWritable> {
public void reduce(Text key, Iterable<IntWritable> values,Context context)
throws IOException,InterruptedException {
int sum=0;
for(IntWritable x: values)
{
sum+=x.get();
}
context.write(key, new IntWritable(sum));
}
}- 我们创建了一个 Reduce 类,它像 Mapper 一样扩展了类 Reducer。
- 我们在类声明之后使用尖括号定义输入和输出键/值对的数据类型,就像对 Mapper 所做的那样。
- Reducer 的输入和输出都是一个键值对。
- 输入:
- 在关键的无非是那些已经在整理和洗牌阶段之后,已经产生唯一词:文本
- 该值是与每个键对应的整数列表:IntWritable
- 示例 – Bear、[1, 1] 等。
- 输出:
- 的关键是所有的唯一单词出现在输入文本文件:文本
- 该值是每个唯一单词的出现次数:IntWritable
- 例子——熊,2;汽车、3等
- 我们汇总了与每个键对应的每个列表中存在的值,并生成了最终答案。
- 通常,为每个唯一的单词创建一个 reducer,但是,您可以在 mapred-site.xml 中指定 reducer 的数量。
驱动程序代码:
Configuration conf= new Configuration();
Job job = new Job(conf,"My Word Count Program");
job.setJarByClass(WordCount.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
Path outputPath = new Path(args[1]);
//Configuring the input/output path from the filesystem into the job
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));- 在驱动程序类中,我们将 MapReduce 作业的配置设置为在 Hadoop 中运行。
- 我们指定作业的名称,映射器和化简器的输入/输出数据类型。
- 我们还指定了映射器和化简器类的名称。
- 还指定了输入和输出文件夹的路径。
- 方法 setInputFormatClass () 用于指定 Mapper 将如何读取输入数据或工作单元是什么。在这里,我们选择了 TextInputFormat,以便映射器一次从输入文本文件中读取一行。
- main() 方法是驱动程序的入口点。在此方法中,我们为作业实例化一个新的 Configuration 对象。
C源颂歌:
package co.edureka.mapreduce;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.fs.Path;
public class WordCount{
public static class Map extends Mapper<LongWritable,Text,Text,IntWritable> {
public void map(LongWritable key, Text value,Context context) throws IOException,InterruptedException{
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
value.set(tokenizer.nextToken());
context.write(value, new IntWritable(1));
}
}
}
public static class Reduce extends Reducer<Text,IntWritable,Text,IntWritable> {
public void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException,InterruptedException {
int sum=0;
for(IntWritable x: values)
{
sum+=x.get();
}
context.write(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws Exception {
Configuration conf= new Configuration();
Job job = new Job(conf,"My Word Count Program");
job.setJarByClass(WordCount.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
Path outputPath = new Path(args[1]);
//Configuring the input/output path from the filesystem into the job
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//deleting the output path automatically from hdfs so that we don't have to delete it explicitly
outputPath.getFileSystem(conf).delete(outputPath);
//exiting the job only if the flag value becomes false
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}运行 MapReduce 代码:
运行 MapReduce 代码的命令是:
hadoop jar hadoop-mapreduce-example.jar WordCount /sample/input /sample/output现在,我们将研究基于 MapReduce 算法的用例。
用例:使用 Hadoop 的 MapReduce 的 KMeans 集群。
KMeans 算法是最简单的无监督机器学习算法之一。通常,无监督算法仅使用输入向量从数据集进行推断,而不参考已知或标记的结果。
使用 Python 和较小的数据集或.csv文件执行 KMeans 算法很容易。但是,当涉及到在大数据级别执行数据集时,通常的程序就不能再方便了。
这正是您使用大数据工具处理大数据的时候。Hadoop 的MapReduce。以下代码片段是 MapReduce 执行Mapper、Reducer和Driver作业的组件
//映射器类
public void map(LongWritable key, Text value, OutputCollector<DoubleWritable, DoubleWritable> output, Reporter reporter) throws IOException {
String line = value.toString();
double point = Double.parseDouble(line);
double min1, min2 = Double.MAX_VALUE, nearest_center = mCenters.get(0);
for (double c : mCenters) {
min1 = c - point;
if (Math.abs(min1) < Math.abs(min2)) {
nearest_center = c;
min2 = min1;
}
}
output.collect(new DoubleWritable(nearest_center),
new DoubleWritable(point));
}
}//减速器类
public static class Reduce extends MapReduceBase implements
Reducer<DoubleWritable, DoubleWritable, DoubleWritable, Text> {
@Override
public void reduce(DoubleWritable key, Iterator<DoubleWritable> values, OutputCollector<DoubleWritable, Text> output, Reporter reporter)throws IOException {
double newCenter;
double sum = 0;
int no_elements = 0;
String points = "";
while (values.hasNext()) {
double d = values.next().get();
points = points + " " + Double.toString(d);
sum = sum + d;
++no_elements;
}
newCenter = sum / no_elements;
output.collect(new DoubleWritable(newCenter), new Text(points));
}
}//驱动类
public static void run(String[] args) throws Exception {
IN = args[0];
OUT = args[1];
String input = IN;
String output = OUT + System.nanoTime();
String again_input = output;
int iteration = 0;
boolean isdone = false;
while (isdone == false) {
JobConf conf = new JobConf(KMeans.class);
if (iteration == 0) {
Path hdfsPath = new Path(input + CENTROID_FILE_NAME);
DistributedCache.addCacheFile(hdfsPath.toUri(), conf);
} else {
Path hdfsPath = new Path(again_input + OUTPUT_FIE_NAME);
DistributedCache.addCacheFile(hdfsPath.toUri(), conf);
}
conf.setJobName(JOB_NAME);
conf.setMapOutputKeyClass(DoubleWritable.class);
conf.setMapOutputValueClass(DoubleWritable.class);
conf.setOutputKeyClass(DoubleWritable.class);
conf.setOutputValueClass(Text.class);
conf.setMapperClass(Map.class);
conf.setReducerClass(Reduce.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(input + DATA_FILE_NAME));
FileOutputFormat.setOutputPath(conf, new Path(output));
JobClient.runJob(conf);
Path ofile = new Path(output + OUTPUT_FIE_NAME);
FileSystem fs = FileSystem.get(new Configuration());
BufferedReader br = new BufferedReader(new InputStreamReader(fs.open(ofile)));
List<Double> centers_next = new ArrayList<Double>();
String line = br.readLine();
while (line != null) {
String[] sp = line.split("t| ");
double c = Double.parseDouble(sp[0]);
centers_next.add(c);
line = br.readLine();
}
br.close();
String prev;
if (iteration == 0) {
prev = input + CENTROID_FILE_NAME;
} else {
prev = again_input + OUTPUT_FILE_NAME;
}
Path prevfile = new Path(prev);
FileSystem fs1 = FileSystem.get(new Configuration());
BufferedReader br1 = new BufferedReader(new InputStreamReader(fs1.open(prevfile)));
List<Double> centers_prev = new ArrayList<Double>();
String l = br1.readLine();
while (l != null) {
String[] sp1 = l.split(SPLITTER);
double d = Double.parseDouble(sp1[0]);
centers_prev.add(d);
l = br1.readLine();
}
br1.close();
Collections.sort(centers_next);
Collections.sort(centers_prev);
Iterator<Double> it = centers_prev.iterator();
for (double d : centers_next) {
double temp = it.next();
if (Math.abs(temp - d) <= 0.1) {
isdone = true;
} else {
isdone = false;
break;
}
}
++iteration;
again_input = output;
output = OUT + System.nanoTime();
}
}现在,我们将通过完整的可执行代码
//源代码
import java.io.IOException;
import java.util.*;
import java.io.*;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.filecache.DistributedCache;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapred.*;
import org.apache.hadoop.mapred.Reducer;
@SuppressWarnings("deprecation")
public class KMeans {
public static String OUT = "outfile";
public static String IN = "inputlarger";
public static String CENTROID_FILE_NAME = "/centroid.txt";
public static String OUTPUT_FILE_NAME = "/part-00000";
public static String DATA_FILE_NAME = "/data.txt";
public static String JOB_NAME = "KMeans";
public static String SPLITTER = "t| ";
public static List<Double> mCenters = new ArrayList<Double>();
public static class Map extends MapReduceBase implements Mapper<LongWritable, Text, DoubleWritable, DoubleWritable> {
@Override
public void configure(JobConf job) {
try {
Path[] cacheFiles = DistributedCache.getLocalCacheFiles(job);
if (cacheFiles != null && cacheFiles.length > 0) {
String line;
mCenters.clear();
BufferedReader cacheReader = new BufferedReader(
new FileReader(cacheFiles[0].toString()));
try {
while ((line = cacheReader.readLine()) != null) {
String[] temp = line.split(SPLITTER);
mCenters.add(Double.parseDouble(temp[0]));
}
} finally {
cacheReader.close();
}
}
} catch (IOException e) {
System.err.println("Exception reading DistribtuedCache: " + e);
}
}
@Override
public void map(LongWritable key, Text value, OutputCollector<DoubleWritable, DoubleWritable> output, Reporter reporter) throws IOException {
String line = value.toString();
double point = Double.parseDouble(line);
double min1, min2 = Double.MAX_VALUE, nearest_center = mCenters.get(0);
for (double c : mCenters) {
min1 = c - point;
if (Math.abs(min1) < Math.abs(min2)) {
nearest_center = c;
min2 = min1;
}
}
output.collect(new DoubleWritable(nearest_center),
new DoubleWritable(point));
}
}
public static class Reduce extends MapReduceBase implements
Reducer<DoubleWritable, DoubleWritable, DoubleWritable, Text> {
@Override
public void reduce(DoubleWritable key, Iterator<DoubleWritable> values, OutputCollector<DoubleWritable, Text> output, Reporter reporter)throws IOException {
double newCenter;
double sum = 0;
int no_elements = 0;
String points = "";
while (values.hasNext()) {
double d = values.next().get();
points = points + " " + Double.toString(d);
sum = sum + d;
++no_elements;
}
newCenter = sum / no_elements;
output.collect(new DoubleWritable(newCenter), new Text(points));
}
}
public static void main(String[] args) throws Exception {
run(args);
}
public static void run(String[] args) throws Exception {
IN = args[0];
OUT = args[1];
String input = IN;
String output = OUT + System.nanoTime();
String again_input = output;
int iteration = 0;
boolean isdone = false;
while (isdone == false) {
JobConf conf = new JobConf(KMeans.class);
if (iteration == 0) {
Path hdfsPath = new Path(input + CENTROID_FILE_NAME);
DistributedCache.addCacheFile(hdfsPath.toUri(), conf);
} else {
Path hdfsPath = new Path(again_input + OUTPUT_FIE_NAME);
DistributedCache.addCacheFile(hdfsPath.toUri(), conf);
}
conf.setJobName(JOB_NAME);
conf.setMapOutputKeyClass(DoubleWritable.class);
conf.setMapOutputValueClass(DoubleWritable.class);
conf.setOutputKeyClass(DoubleWritable.class);
conf.setOutputValueClass(Text.class);
conf.setMapperClass(Map.class);
conf.setReducerClass(Reduce.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(input + DATA_FILE_NAME));
FileOutputFormat.setOutputPath(conf, new Path(output));
JobClient.runJob(conf);
Path ofile = new Path(output + OUTPUT_FIE_NAME);
FileSystem fs = FileSystem.get(new Configuration());
BufferedReader br = new BufferedReader(new InputStreamReader(fs.open(ofile)));
List<Double> centers_next = new ArrayList<Double>();
String line = br.readLine();
while (line != null) {
String[] sp = line.split("t| ");
double c = Double.parseDouble(sp[0]);
centers_next.add(c);
line = br.readLine();
}
br.close();
String prev;
if (iteration == 0) {
prev = input + CENTROID_FILE_NAME;
} else {
prev = again_input + OUTPUT_FILE_NAME;
}
Path prevfile = new Path(prev);
FileSystem fs1 = FileSystem.get(new Configuration());
BufferedReader br1 = new BufferedReader(new InputStreamReader(fs1.open(prevfile)));
List<Double> centers_prev = new ArrayList<Double>();
String l = br1.readLine();
while (l != null) {
String[] sp1 = l.split(SPLITTER);
double d = Double.parseDouble(sp1[0]);
centers_prev.add(d);
l = br1.readLine();
}
br1.close();
Collections.sort(centers_next);
Collections.sort(centers_prev);
Iterator<Double> it = centers_prev.iterator();
for (double d : centers_next) {
double temp = it.next();
if (Math.abs(temp - d) <= 0.1) {
isdone = true;
} else {
isdone = false;
break;
}
}
++iteration;
again_input = output;
output = OUT + System.nanoTime();
}
}
}现在,你们对 MapReduce 框架有了基本的了解。您可能已经意识到 MapReduce 框架如何帮助我们编写代码来处理 HDFS 中存在的大量数据。与 Hadoop 1.x 相比,Hadoop 2.x 中的 MapReduce 框架发生了重大变化。这些更改将在本 MapReduce 教程系列的下一篇博客中讨论。我将在那个博客中分享一个可下载的综合指南,它解释了 MapReduce 程序的每个部分。

- 点赞
- 收藏
- 关注作者
评论(0)