5 个数据科学项目——数据科学实践项目

随着人工智能的爆发式增长,公司急切地希望聘请熟练的数据科学家来发展他们的业务。除了获得数据科学认证外,简历上有几个数据科学项目总是好的。拥有理论知识是远远不够的。因此,在此博客中,您将学习如何实际使用数据科学方法来解决实际问题。
数据科学项目生命周期
有了正确的数据,数据科学可用于解决从欺诈检测和智能农业到预测气候变化和心脏病等问题。话虽如此,数据不足以解决问题,您需要一种方法或方法来为您提供最准确的结果。这给我们带来了一个问题:
你如何解决数据科学问题?
数据科学中的问题陈述可以通过以下步骤解决:
- 定义问题陈述/业务需求
- 数据采集
- 数据清洗
- 数据探索与分析
- 数据建模
- 部署和优化
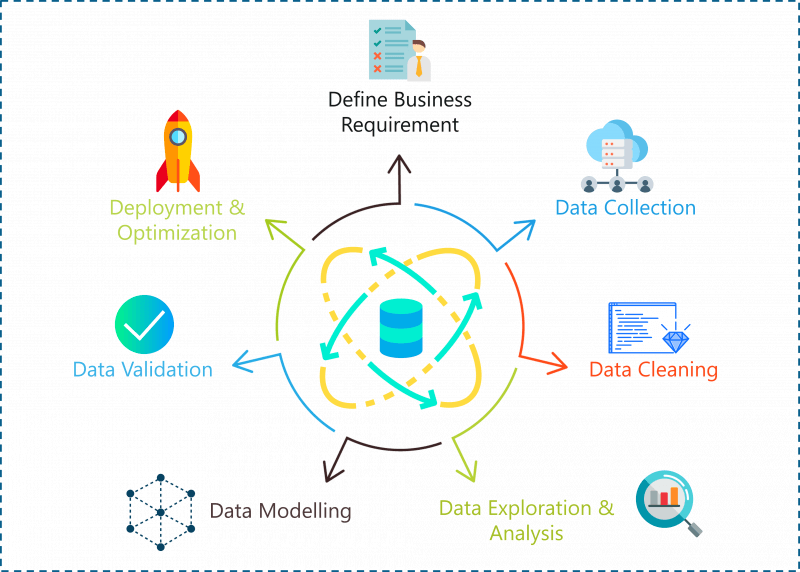
数据科学项目生命周期 – 数据科学项目
让我们详细看看这些步骤中的每一个:
步骤 1:定义问题陈述
在开始数据科学项目之前,您必须先定义要解决的问题。在这个阶段,您应该清楚项目的目标。
第 2 步:数据收集
顾名思义,在这个阶段,您必须获取解决问题所需的所有数据。收集数据并不容易,因为大多数时候您不会在数据库中找到等待您的数据。相反,您必须出去,做一些研究并收集数据或从互联网上获取数据。
第 3 步:数据清理
如果你问数据科学家他们最不喜欢的数据科学过程是什么,他们很可能会告诉你它是数据清理。数据清洗是去除冗余、缺失、重复和不必要的数据的过程。这个阶段被认为是数据科学中最耗时的阶段之一。然而,为了防止错误的预测,消除数据中的任何不一致是很重要的。
第 4 步:数据分析和探索
一旦你完成了数据的清理,是时候把内在的夏洛克福尔摩斯弄出来了。在数据科学生命周期的这个阶段,您必须检测数据中的模式和趋势。您可以在此处检索有用的见解并研究数据的行为。在此阶段结束时,您必须开始对您的数据和您正在解决的问题形成假设。
第 5 步:数据建模
这个阶段是关于构建一个最能解决你的问题的模型。模型可以是使用数据进行训练和测试的机器学习算法。这个阶段总是从一个叫做数据拼接的过程开始,在这个过程中你将整个数据集分成两个比例。一个用于训练模型(训练数据集),另一个用于测试模型的效率(测试数据集)。
然后使用训练数据集构建模型,最后使用测试数据集评估模型。
第 6 步:优化和部署:
这是数据科学生命周期的最后阶段。在这个阶段,你必须尝试提高数据模型的效率,让它做出更准确的预测。最终目标是将模型部署到生产或类似生产的环境中,以供最终用户接受。用户必须验证模型的性能,如果模型有任何问题,则必须在此阶段进行修复。
既然你知道问题是如何发生的 使用数据科学解决,让我们进入有趣的部分。在接下来的部分中,我将为您提供五个高级数据科学项目,这些项目可以让您在顶级 IT 公司工作。
R中的数据科学
在我们开始编码之前,这里有一个简短的免责声明:
我将使用 R 语言来运行整个数据科学工作流,因为R 是一种统计语言,它有 8000 多个包,让我们的生活更轻松。
1994 年人口普查收入数据的分类
问题陈述:构建一个模型,该模型将根据有关个人的可用数据预测美国任何个人的收入是大于还是小于 50,000 美元。
数据集描述:该人口普查收入数据集由 Barry Becker 在 1994 年收集并提供给公共网站http://archive.ics.uci.edu/ml/datasets/Census+Income。该数据集将帮助您了解一个人的收入如何根据教育背景、职业、婚姻状况、地理、年龄、每周工作小时数等各种因素而变化。
以下是用于预测个人收入是否超过 50,000 美元的自变量或预测变量列表:
- 年龄
- 工薪阶层
- 最终重量
- 教育
- Education-num(受教育年限)
- 婚姻状况
- 职业
- 关系
- 种族
- 性别
- 资本收益
- 资本损失
- 每周几小时
- 祖国
因变量是代表收入水平的“收入水平”。这是一个分类变量,因此它只能取两个值:
- <=50k
- >=50k
现在我们已经定义了我们的目标并收集了数据,是时候开始分析了。
第 1 步:导入数据
幸运的是,我们在网上找到了一个数据集,所以我们要做的就是将数据集导入到我们的 R 环境中,如下所示:
#Downloading train and test data
trainFile = "adult.data"; testFile = "adult.test"
if (!file.exists (trainFile))
download.file (url = "<a href="http://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data">http://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data</a>",
destfile = trainFile)
if (!file.exists (testFile))
download.file (url = "<a href="http://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.test">http://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.test</a>",
destfile = testFile)在上面的代码片段中,我们下载了训练数据集和测试数据集。
如果您查看训练数据,您会注意到预测变量没有标记。因此,在下面的代码片段中,我为每个预测变量分配了变量名称,为了使数据更具可读性,我去掉了不必要的空格。
#Assigning column names
colNames = c ("age", "workclass", "fnlwgt", "education",
"educationnum", "maritalstatus", "occupation",
"relationship", "race", "sex", "capitalgain",
"capitalloss", "hoursperweek", "nativecountry",
"incomelevel")
#Reading training data
training = read.table (trainFile, header = FALSE, sep = ",",
strip.white = TRUE, col.names = colNames,
na.strings = "?", stringsAsFactors = TRUE)现在为了研究我们数据集的结构,我们调用了 str() 方法。这为我们提供了数据集中存在的所有预测变量的描述性摘要:
#Display structure of the data
str (training)
> str (training)
'data.frame': 32561 obs. of 15 variables:
$ age : int 39 50 38 53 28 37 49 52 31 42 ...
$ workclass : Factor w/ 8 levels "Federal-gov",..: 7 6 4 4 4 4 4 6 4 4 ...
$ fnlwgt : int 77516 83311 215646 234721 338409 284582 160187 209642 45781 159449 ...
$ education : Factor w/ 16 levels "10th","11th",..: 10 10 12 2 10 13 7 12 13 10 ...
$ educationnum : int 13 13 9 7 13 14 5 9 14 13 ...
$ maritalstatus: Factor w/ 7 levels "Divorced","Married-AF-spouse",..: 5 3 1 3 3 3 4 3 5 3 ...
$ occupation : Factor w/ 14 levels "Adm-clerical",..: 1 4 6 6 10 4 8 4 10 4 ...
$ relationship : Factor w/ 6 levels "Husband","Not-in-family",..: 2 1 2 1 6 6 2 1 2 1 ...
$ race : Factor w/ 5 levels "Amer-Indian-Eskimo",..: 5 5 5 3 3 5 3 5 5 5 ...
$ sex : Factor w/ 2 levels "Female","Male": 2 2 2 2 1 1 1 2 1 2 ...
$ capitalgain : int 2174 0 0 0 0 0 0 0 14084 5178 ...
$ capitalloss : int 0 0 0 0 0 0 0 0 0 0 ...
$ hoursperweek : int 40 13 40 40 40 40 16 45 50 40 ...
$ nativecountry: Factor w/ 41 levels "Cambodia","Canada",..: 39 39 39 39 5 39 23 39 39 39 ...
$ incomelevel : Factor w/ 2 levels "<=50K",">50K": 1 1 1 1 1 1 1 2 2 2 ...因此,在导入数据并将其转换为可读格式后,我们将进入数据处理中的下一个关键步骤,即数据清理。
第 2 步:数据清理
数据清理阶段被认为是数据科学中最耗时的任务之一。此阶段包括删除 NA 值、删除冗余变量和数据中的任何不一致。
我们将通过检查我们的数据观察是否有任何缺失值来开始数据清理:
> table (complete.cases (training))
FALSE TRUE
2399 30162上面的代码片段表明 2399 个样本案例具有 NA 值。为了解决这个问题,让我们查看所有变量的摘要并分析哪些变量具有最多的空值。我们必须摆脱 NA 值的原因是它们会导致错误的预测,从而降低我们模型的准确性。
> summary (training [!complete.cases(training),])
age workclass fnlwgt education educationnum
Min. :17.00 Private : 410 Min. : 12285 HS-grad :661 Min. : 1.00
1st Qu.:22.00 Self-emp-inc : 42 1st Qu.:121804 Some-college:613 1st Qu.: 9.00
Median :36.00 Self-emp-not-inc: 42 Median :177906 Bachelors :311 Median :10.00
Mean :40.39 Local-gov : 26 Mean :189584 11th :127 Mean : 9.57
3rd Qu.:58.00 State-gov : 19 3rd Qu.:232669 10th :113 3rd Qu.:11.00
Max. :90.00 (Other) : 24 Max. :981628 Masters : 96 Max. :16.00
NA's :1836 (Other) :478
maritalstatus occupation relationship race
Divorced :229 Prof-specialty : 102 Husband :730 Amer-Indian-Eskimo: 25
Married-AF-spouse : 2 Other-service : 83 Not-in-family :579 Asian-Pac-Islander: 144
Married-civ-spouse :911 Exec-managerial: 74 Other-relative: 92 Black : 307
Married-spouse-absent: 48 Craft-repair : 69 Own-child :602 Other : 40
Never-married :957 Sales : 66 Unmarried :234 White :1883
Separated : 86 (Other) : 162 Wife :162
Widowed :166 NA's :1843
sex capitalgain capitalloss hoursperweek nativecountry
Female: 989 Min. : 0.0 Min. : 0.00 Min. : 1.00 United-States
Median : 0.0 Median : 0.00 Median :40.00 Canada
Mean : 897.1 Mean : 73.87 Mean :34.23 Philippines
3rd Qu.: 0.0 3rd Qu.: 0.00 3rd Qu.:40.00 Germany
Max. :99999.0 Max. :4356.00 Max. :99.00 (Other)
NA's : 583 从上面的总结中可以看出,三个变量具有大量的 NA 值:
- 工人阶级 – 1836
- 职业 – 1843
- 原住民 – 583
这三个变量必须清除,因为它们是预测个人收入水平的重要变量。
#Removing NAs
TrainSet = training [!is.na (training$workclass) & !is.na (training$occupation), ]
TrainSet = TrainSet [!is.na (TrainSet$nativecountry), ]一旦我们摆脱了 NA 值,下一步就是摆脱任何对预测结果不重要的不必要变量。摆脱这些变量很重要,因为它们只会增加模型的复杂性,而不会提高其效率。
其中一个变量是“fnlwgt”变量,它表示通过计算人口的任何特定社会经济特征的“加权计数”从 CPS 得出的人口总数。
此变量已从我们的数据集中删除,因为它无助于预测我们的结果变量:
#Removing unnecessary variables
TrainSet$fnlwgt = NULL这就是数据清理的全部内容,我们的下一步是数据探索。
第 3 步:数据探索
数据探索涉及分析每个特征变量以检查变量对于构建模型是否重要。
探索年龄变量
#Data Exploration
#Exploring the age variable
> summary (TrainSet$age)
Min. 1st Qu. Median Mean 3rd Qu. Max.
17.00 28.00 37.00 38.44 47.00 90.00
#Boxplot for age variable
boxplot (age ~ incomelevel, data = TrainSet,
main = "Income levels based on the Age of an individual",
xlab = "Income Level", ylab = "Age", col = "salmon")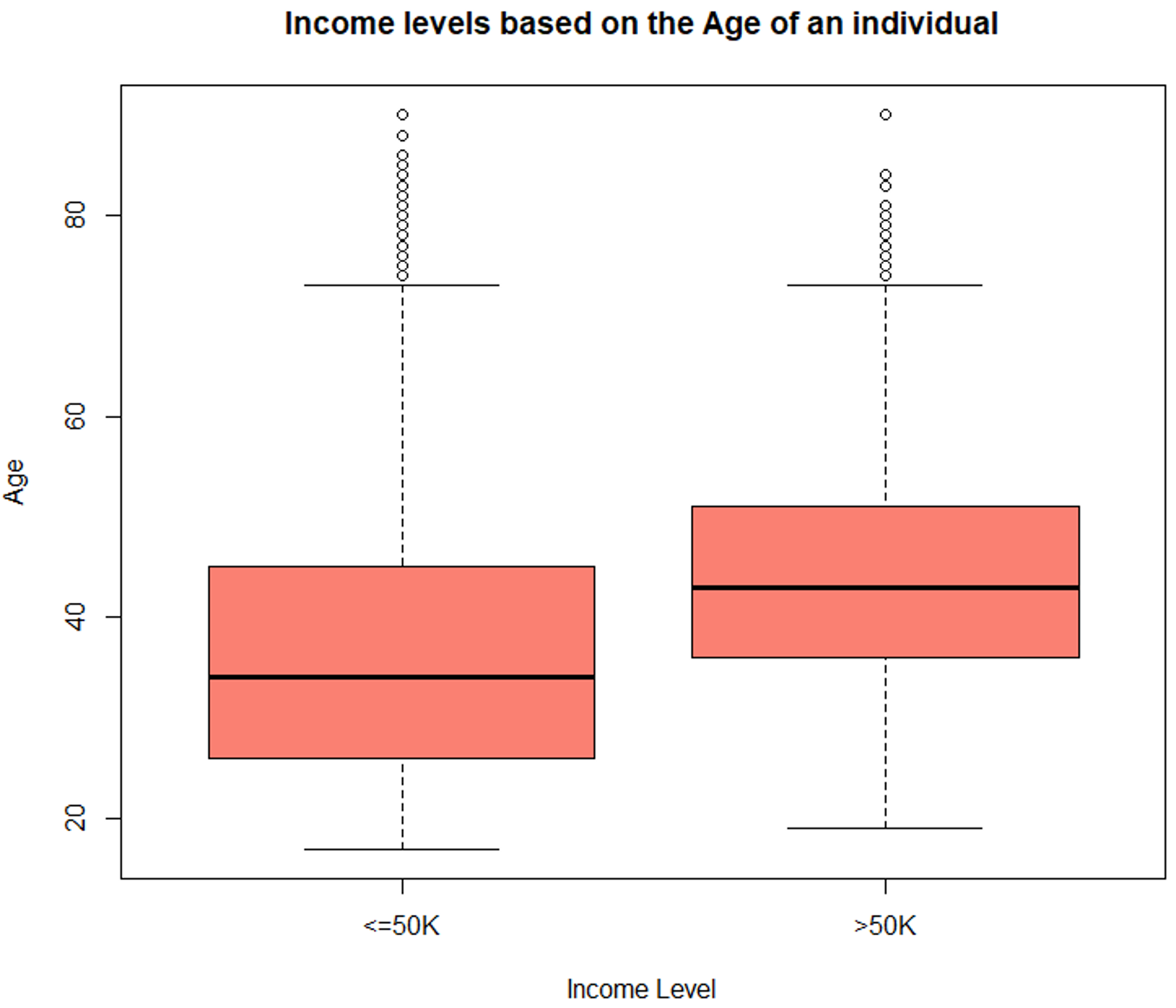
箱线图 – 数据科学项目
#Histogram for age variable
incomeBelow50K = (TrainSet$incomelevel == "<=50K")
xlimit = c (min (TrainSet$age), max (TrainSet$age))
ylimit = c (0, 1600)
hist1 = qplot (age, data = TrainSet[incomeBelow50K,], margins = TRUE,
binwidth = 2, xlim = xlimit, ylim = ylimit, colour = incomelevel)
hist2 = qplot (age, data = TrainSet[!incomeBelow50K,], margins = TRUE,
binwidth = 2, xlim = xlimit, ylim = ylimit, colour = incomelevel)
grid.arrange (hist1, hist2, nrow = 2)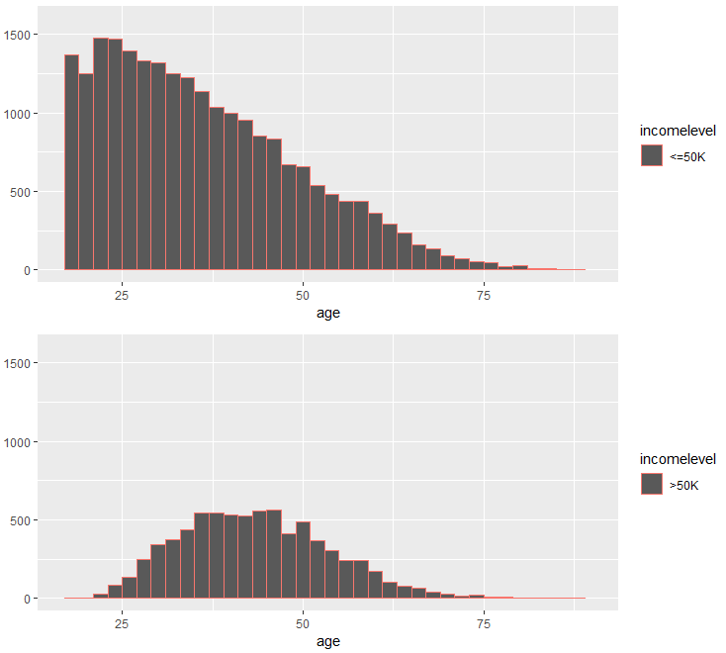
直方图 – 数据科学项目
上图显示年龄变量随收入水平而变化,因此它是一个强大的预测变量。
探索 'educationnum' 变量
该变量表示个人受教育的年数。让我们看看“educationnum”变量如何随收入水平变化:
> summary (TrainSet$educationnum)
Min. 1st Qu. Median Mean 3rd Qu. Max.
1.00 9.00 10.00 10.12 13.00 16.00
#Boxplot for education-num variable
boxplot (educationnum ~ incomelevel, data = TrainSet,
main = "Years of Education distribution for different income levels",
xlab = "Income Levels", ylab = "Years of Education", col = "green")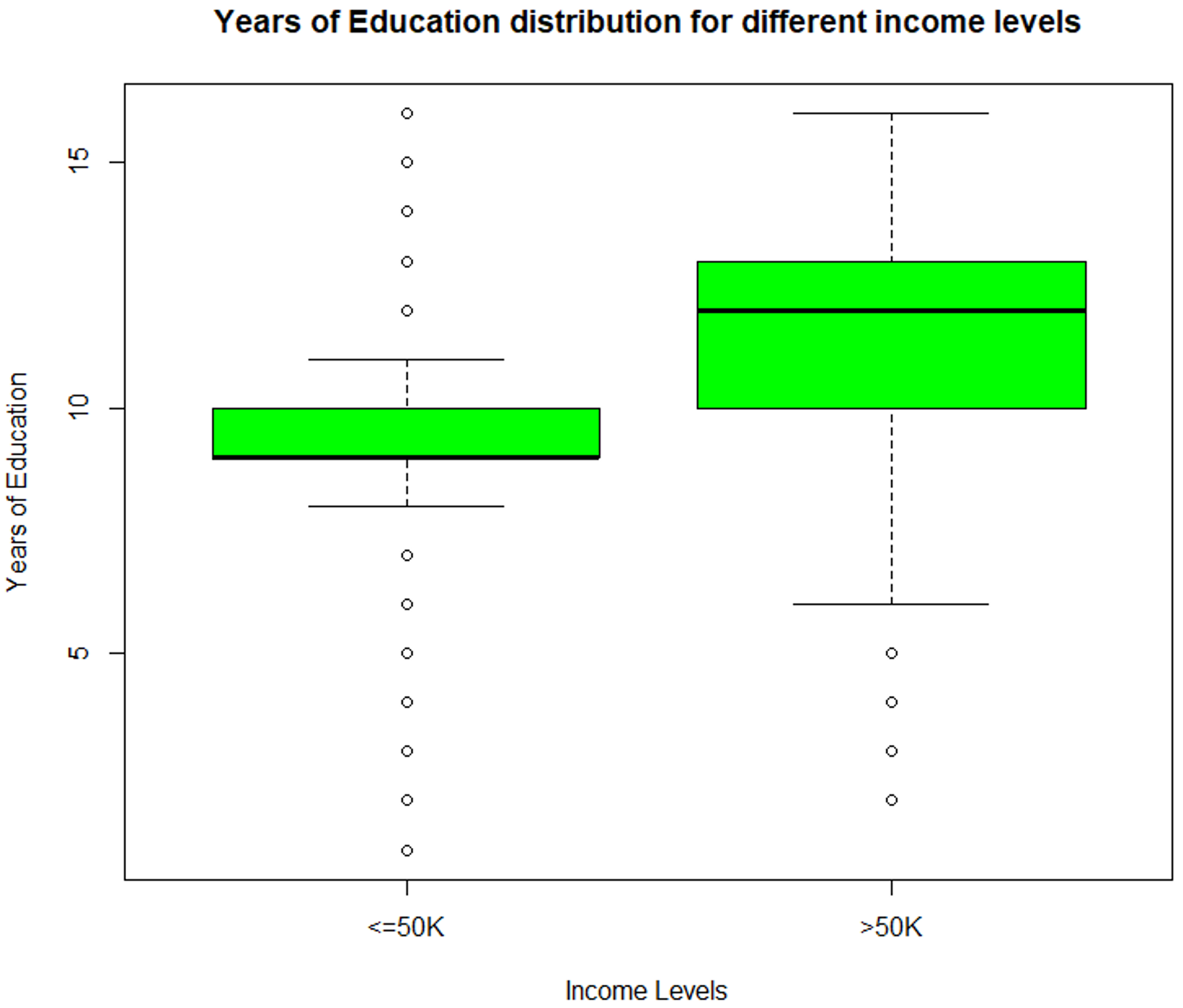
数据探索 (educationnum) – 数据科学项目
上图描述了 'educationnum' 变量随着收入水平 <=50k 和 >50k 而变化,从而证明它是预测结果的重要变量。
探索资本收益和资本损失变量
在研究了每个收入水平的资本收益和资本损失变量的汇总后,很明显它们的均值差异很大,因此表明它们是预测个人收入水平的合适变量。
> summary (TrainSet[ TrainSet$incomelevel == "<=50K",
+ c("capitalgain", "capitalloss")])
capitalgain capitalloss
Min. : 0.0 Min. : 0.00
1st Qu.: 0.0 1st Qu.: 0.00
Median : 0.0 Median : 0.00
Mean : 148.9 Mean : 53.45
3rd Qu.: 0.0 3rd Qu.: 0.00
Max. :41310.0 Max. :4356.00 探索小时/周变量
类似地,评估 'hoursperweek' 变量以检查它是否是一个重要的预测变量。
#Evaluate hours/week variable
> summary (TrainSet$hoursperweek)
Min. 1st Qu. Median Mean 3rd Qu. Max.
1.00 40.00 40.00 40.93 45.00 99.00
boxplot (hoursperweek ~ incomelevel, data = TrainSet,
main = "Hours Per Week distribution for different income levels",
xlab = "Income Levels", ylab = "Hours Per Week", col = "salmon")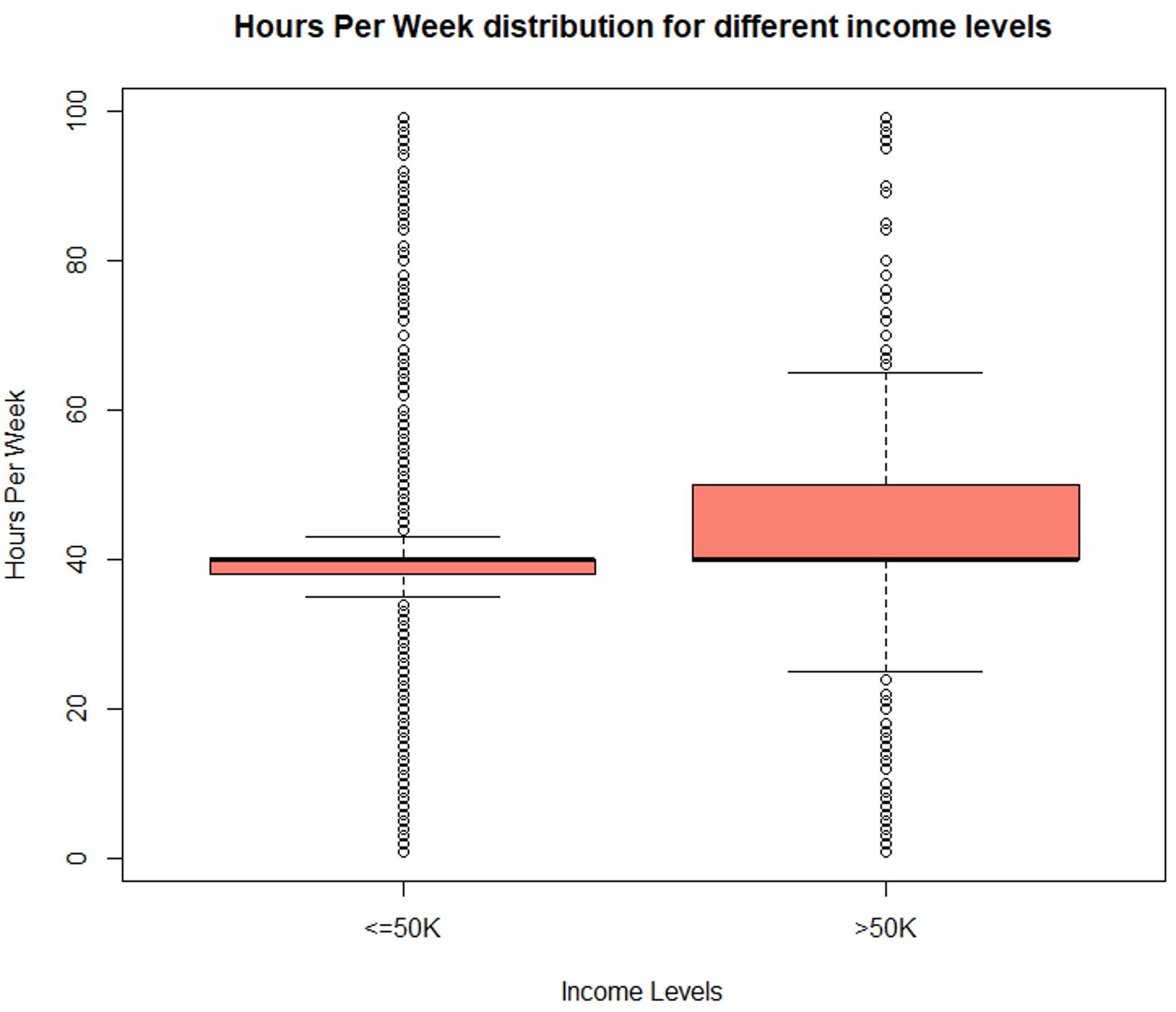
数据探索(每周小时数) – 数据科学项目
箱线图显示了不同收入水平的明显变化,这使其成为预测结果的重要变量。
同样,我们也将评估分类变量。在下面的部分中,我为每个变量创建了 qplots,在评估这些图之后,很明显这些变量对于预测个人的收入水平至关重要。
探索工人阶级变量
#Evaluating work-class variable
qplot (incomelevel, data = TrainSet, fill = workclass) + facet_grid (. ~ workclass)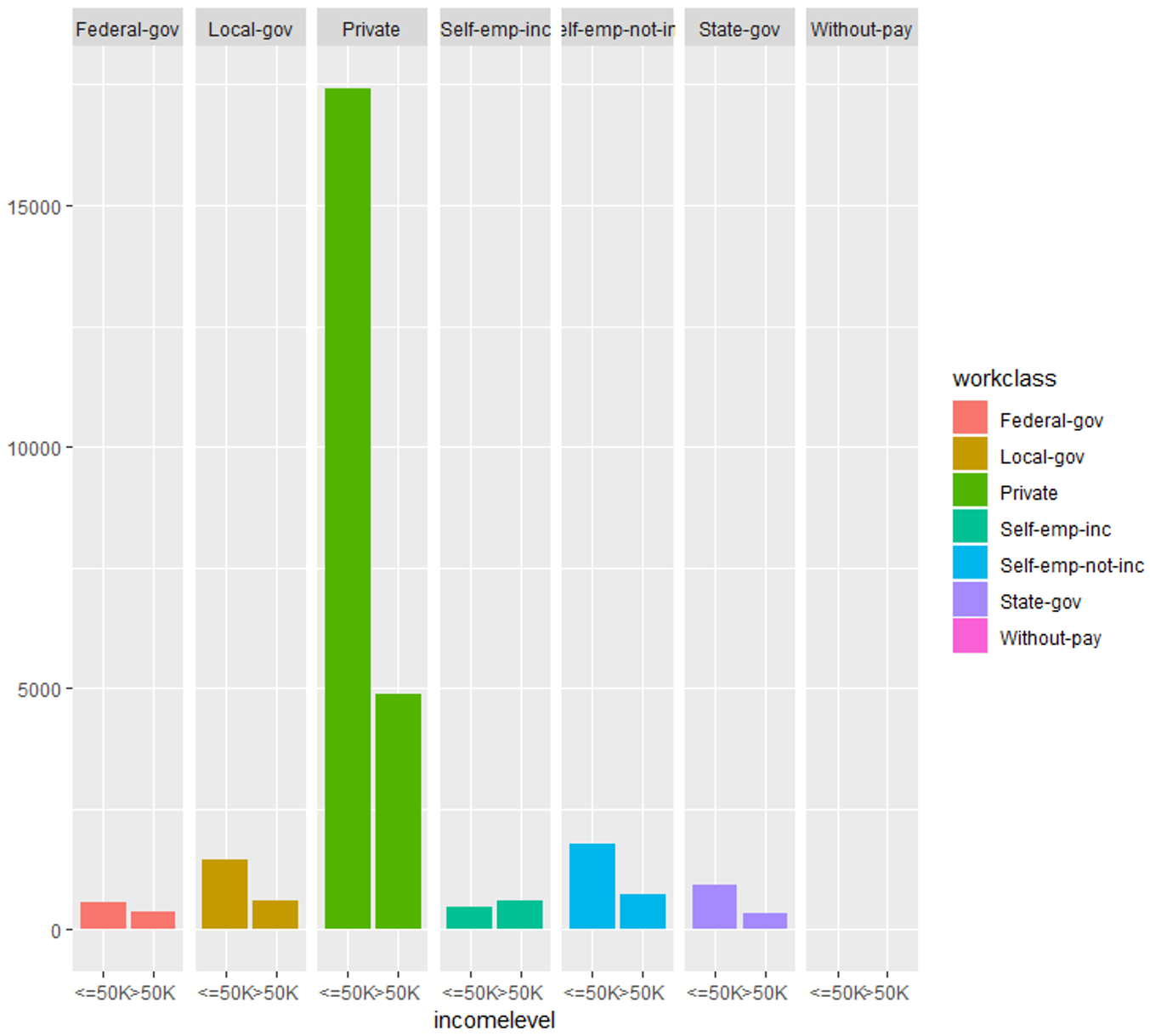
数据探索(工作班)——数据科学项目
#Evaluating occupation variable
qplot (incomelevel, data = TrainSet, fill = occupation) + facet_grid (. ~ occupation)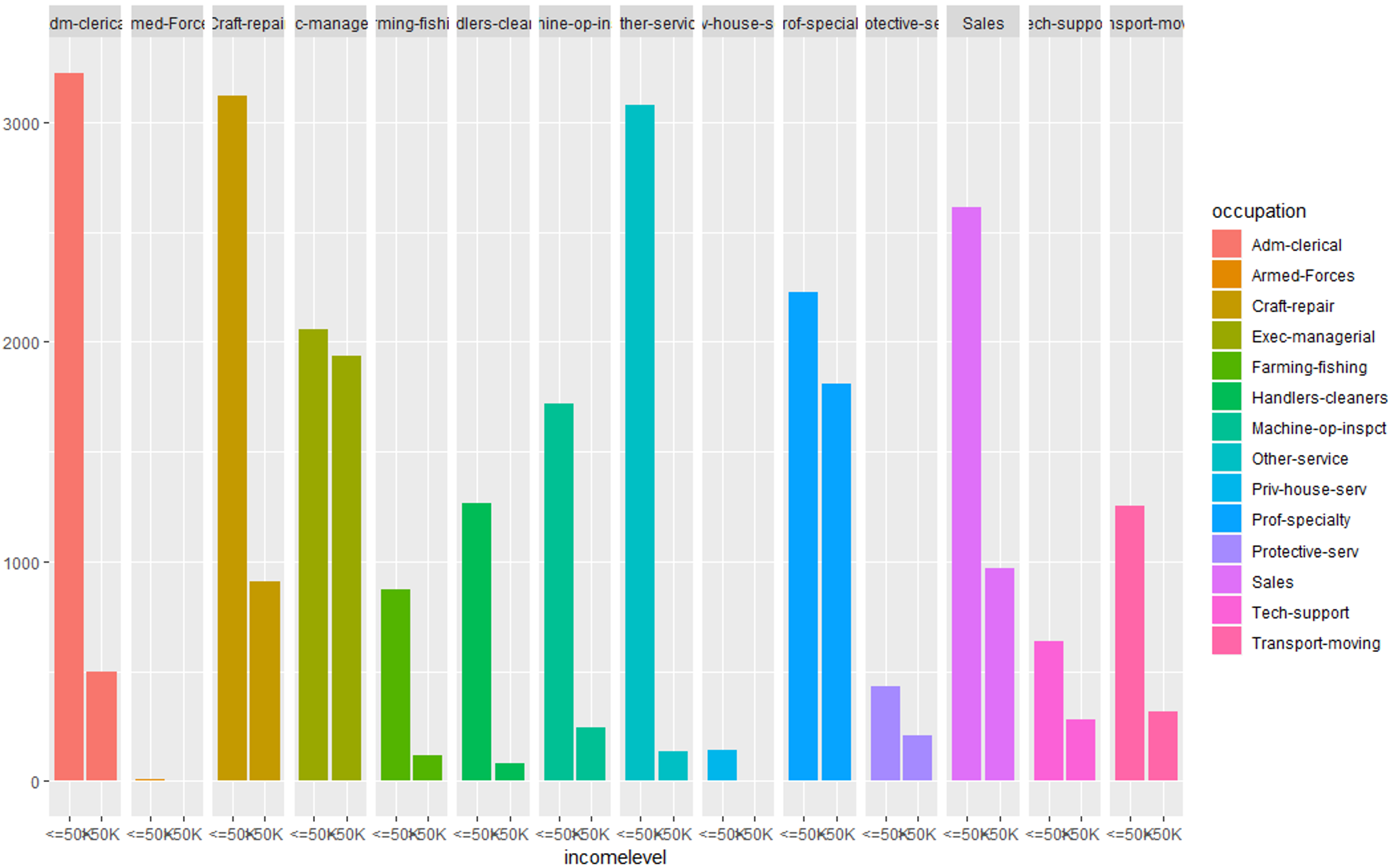
数据探索(职业) – 数据科学项目
#Evaluating marital-status variable
qplot (incomelevel, data = TrainSet, fill = maritalstatus) + facet_grid (. ~ maritalstatus)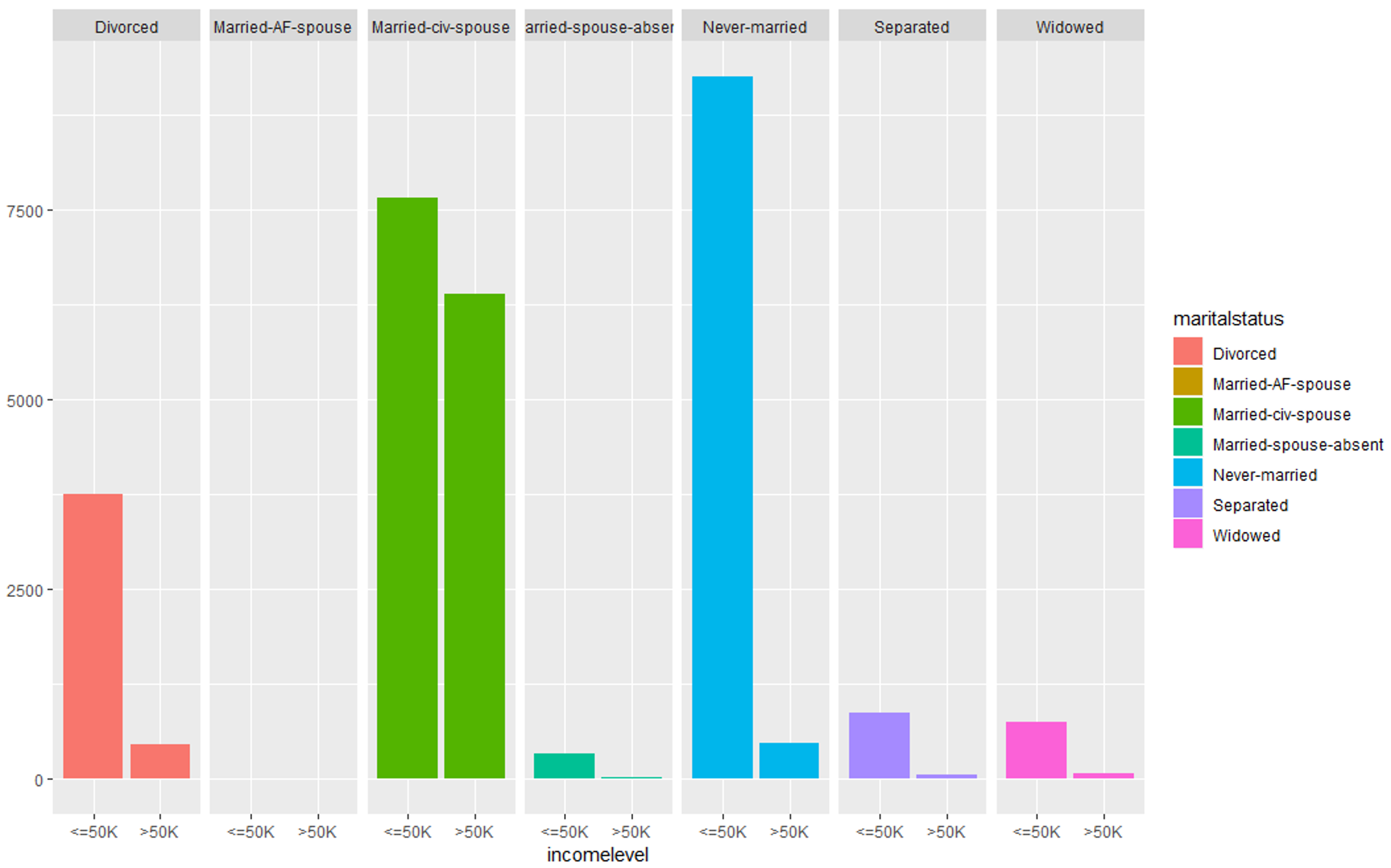
数据探索 (martialstatus) – 数据科学项目
#Evaluating relationship variable
qplot (incomelevel, data = TrainSet, fill = relationship) + facet_grid (. ~ relationship)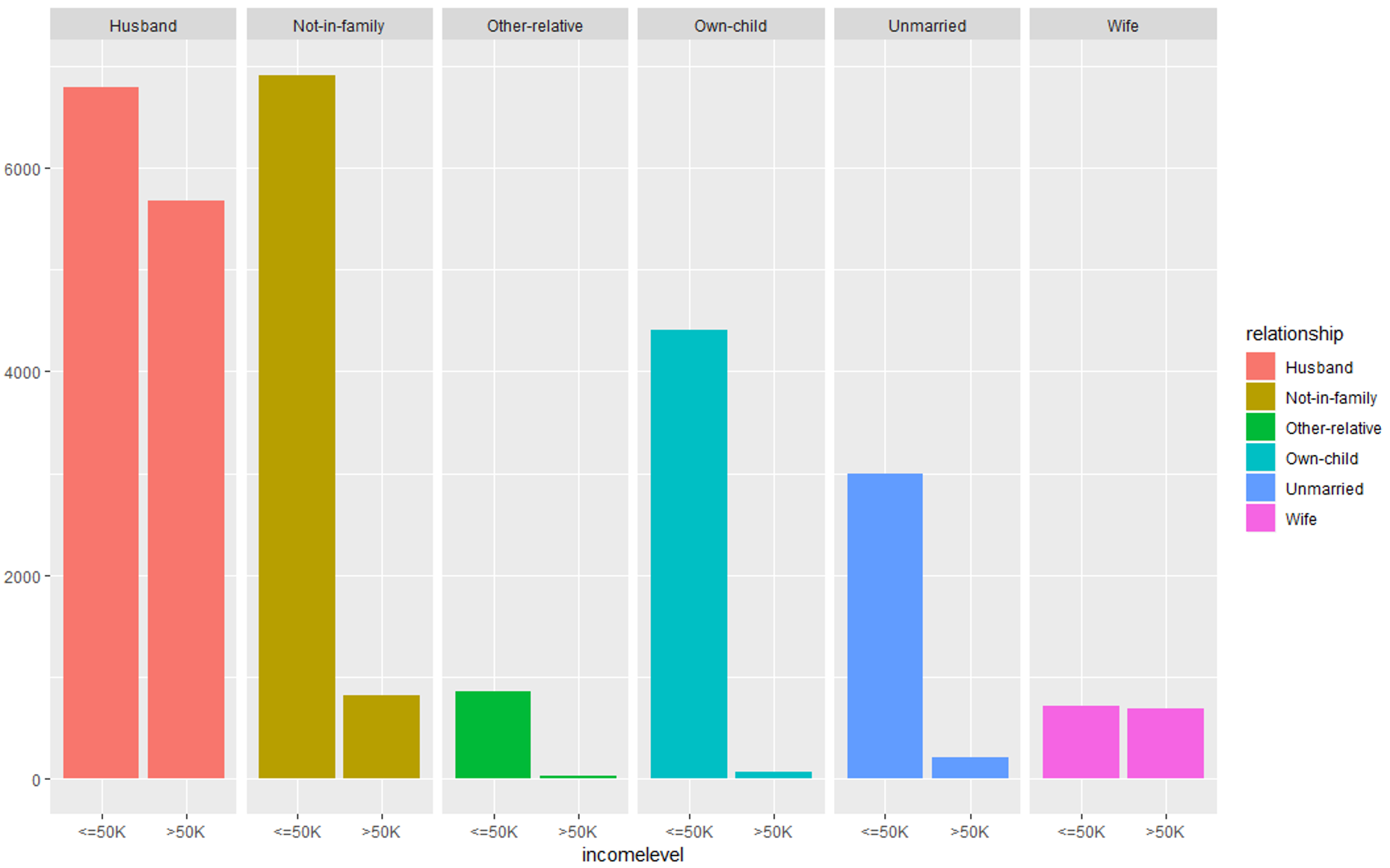
数据探索(关系) – 数据科学项目
所有这些图表都表明,这些预测变量集对于构建我们的预测模型很重要。
第 4 步:构建模型
因此,在评估了我们所有的预测变量之后,终于到了执行预测分析的时候了。在此阶段,我们将构建一个预测模型,该模型将根据我们在上一节中评估的预测变量来预测个人收入是否超过 50,000 美元。
为了构建这个模型,我使用了 boosting 算法,因为我们必须将一个人分为两类,即:
-
收入水平 <= 50,000 美元
-
收入水平 > 50,000 美元
#Building the model
set.seed (32323)
trCtrl = trainControl(method = "cv", number = 10)
boostFit = train (incomelevel ~ age + workclass + education + educationnum +
maritalstatus + occupation + relationship +
race + capitalgain + capitalloss + hoursperweek +
nativecountry, trControl = trCtrl,
method = "gbm", data = TrainSet, verbose = FALSE)由于我们使用的是集成分类算法,因此我还实施了交叉验证技术来防止模型过度拟合。
第 5 步:检查模型的准确性
为了评估模型的准确性,我们将使用混淆矩阵:
#Checking the accuracy of the model
> confusionMatrix (TrainSet$incomelevel, predict (boostFit, TrainSet))
Confusion Matrix and Statistics
Reference
Prediction <=50K >50K
<=50K 21404 1250 >50K 2927 4581
Accuracy : 0.8615
95% CI : (0.8576, 0.8654)
No Information Rate : 0.8067
P-Value [Acc > NIR] : < 2.2e-16
Kappa : 0.5998
Mcnemar's Test P-Value : < 2.2e-16
Sensitivity : 0.8797
Specificity : 0.7856
Pos Pred Value : 0.9448
Neg Pred Value : 0.6101
Prevalence : 0.8067
Detection Rate : 0.7096
Detection Prevalence : 0.7511
Balanced Accuracy : 0.8327
'Positive' Class : <=50K输出显示,我们的模型以大约 86% 的准确度计算了个人的收入水平,这是一个很好的数字。
到目前为止,我们使用训练数据集来构建模型,现在是使用测试数据集来验证模型的时候了。
步骤 5:加载和评估测试数据集
就像我们清理训练数据集的方式一样,我们的测试数据也必须以这样的方式准备,即它没有任何空值或不必要的预测变量,只有这样我们才能使用测试数据来验证我们的模型。
首先加载测试数据集:
#Load the testing data set
testing = read.table (testFile, header = FALSE, sep = ",",
strip.white = TRUE, col.names = colNames,
na.strings = "?", fill = TRUE, stringsAsFactors = TRUE)接下来,我们正在研究数据集的结构。
#Display structure of the data
> str (testing)
'data.frame': 16282 obs. of 15 variables:
$ age : Factor w/ 74 levels "|1x3 Cross validator",..: 1 10 23 13 29 3 19 14 48 9 ...
$ workclass : Factor w/ 9 levels "","Federal-gov",..: 1 5 5 3 5 NA 5 NA 7 5 ...
$ fnlwgt : int NA 226802 89814 336951 160323 103497 198693 227026 104626 369667 ...
$ education : Factor w/ 17 levels "","10th","11th",..: 1 3 13 9 17 17 2 13 16 17 ...
$ educationnum : int NA 7 9 12 10 10 6 9 15 10 ...
$ maritalstatus: Factor w/ 8 levels "","Divorced",..: 1 6 4 4 4 6 6 6 4 6 ...
$ occupation : Factor w/ 15 levels "","Adm-clerical",..: 1 8 6 12 8 NA 9 NA 11 9 ...
$ relationship : Factor w/ 7 levels "","Husband","Not-in-family",..: 1 5 2 2 2 5 3 6 2 6 ...
$ race : Factor w/ 6 levels "","Amer-Indian-Eskimo",..: 1 4 6 6 4 6 6 4 6 6 ...
$ sex : Factor w/ 3 levels "","Female","Male": 1 3 3 3 3 2 3 3 3 2 ...
$ capitalgain : int NA 0 0 0 7688 0 0 0 3103 0 ...
$ capitalloss : int NA 0 0 0 0 0 0 0 0 0 ...
$ hoursperweek : int NA 40 50 40 40 30 30 40 32 40 ...
$ nativecountry: Factor w/ 41 levels "","Cambodia",..: 1 39 39 39 39 39 39 39 39 39 ...
$ incomelevel : Factor w/ 3 levels "","<=50K.",">50K.": 1 2 2 3 3 2 2 2 3 2 ...在下面的代码片段中,我们正在寻找没有任何空数据或缺失数据的完整观察。
> table (complete.cases (testing))
FALSE TRUE
1222 15060
> summary (testing [!complete.cases(testing),])
age workclass fnlwgt education educationnum
20 : 73 Private :189 Min. : 13862 Some-college:366 Min. : 1.000
19 : 71 Self-emp-not-inc: 24 1st Qu.: 116834 HS-grad :340 1st Qu.: 9.000
18 : 64 State-gov : 16 Median : 174274 Bachelors :144 Median :10.000
21 : 62 Local-gov : 10 Mean : 187207 11th : 66 Mean : 9.581
22 : 53 Federal-gov : 9 3rd Qu.: 234791 10th : 53 3rd Qu.:10.000
17 : 35 (Other) : 11 Max. :1024535 Masters : 47 Max. :16.000
(Other):864 NA's :963 NA's :1 (Other) :206 NA's :1
maritalstatus occupation relationship race
Never-married :562 Prof-specialty : 62 : 1 : 1
Married-civ-spouse :413 Other-service : 32 Husband :320 Amer-Indian-Eskimo: 10
Divorced :107 Sales : 30 Not-in-family :302 Asian-Pac-Islander: 72
Widowed : 75 Exec-managerial: 28 Other-relative: 65 Black :150
Separated : 33 Craft-repair : 23 Own-child :353 Other : 13
Married-spouse-absent: 28 (Other) : 81 Unmarried :103 White :976
(Other) : 4 NA's :966 Wife : 78
sex capitalgain capitalloss hoursperweek nativecountry
: 1 Min. : 0.0 Min. : 0.00 Min. : 1.00 UnitedStates
Female:508 1st Qu.: 0.0 1st Qu.: 0.00 1st Qu.:20.00 Mexico
Mean : 608.3 Mean : 73.81 Mean :33.49 South
3rd Qu.: 0.0 3rd Qu.: 0.00 3rd Qu.:40.00 England
Max. :99999.0 Max. :2603.00 Max. :99.00 (Other)
NA's :1 NA's :1 NA's :1 NA's 从总结中可以清楚地看出,我们在 'workclass'、'occupation' 和 'nativecountry' 变量中有许多 NA 值,所以让我们摆脱这些变量。
#Removing NAs
TestSet = testing [!is.na (testing$workclass) & !is.na (testing$occupation), ]
TestSet = TestSet [!is.na (TestSet$nativecountry), ]
#Removing unnecessary variables
TestSet$fnlwgt = NULL第 6 步:验证模型
将测试数据集应用于预测模型以验证模型的效率。以下代码片段显示了这是如何完成的:
#Testing model
TestSet$predicted = predict (boostFit, TestSet)
table(TestSet$incomelevel, TestSet$predicted)
actuals_preds <- data.frame(cbind(actuals=TestSet$incomelevel, predicted=TestSet$predicted)) # make actuals_predicteds dataframe.
correlation_accuracy <- cor(actuals_preds)
head(actuals_preds)该表用于将预测值与个人的实际收入水平进行比较。通过在模型中引入一些变化或使用替代算法,可以进一步改进该模型。
因此,我们只是从头开始执行了整个数据科学项目。
在下面的部分中,我编译了一组项目,这些项目将帮助您获得数据清理、统计分析、数据建模和数据方面的经验 可视化。
将此视为您的家庭作业。
简历数据科学项目
沃尔玛销售预测
数据科学在预测零售业的销售和风险方面发挥着巨大作用。大多数领先的零售店都采用数据科学来跟踪客户需求并做出更好的业务决策。沃尔玛就是这样的零售商之一。
问题陈述:分析沃尔玛销售数据集,以预测其每个商店的部门销售额。
数据集说明:本项目使用的数据集包含历史训练数据,涵盖2010-02-05至2012-11-01的销售明细。为了分析这个问题,使用了以下预测变量:
- 商店 - 商店编号
- Dept——部门编号
- 日期——周
- CPI——消费者价格指数
- Weekly_Sales – 指定商店中指定部门的销售额
- IsHoliday – 该周是否为特殊假日周
通过研究这些预测变量对响应变量的依赖性,您可以预测或预测未来几个月的销售额。
逻辑:
- 导入数据集:本项目所需的数据集可以从Kaggle下载。
- 数据清理:在此阶段,您必须确保消除所有不一致,例如缺失值和任何冗余变量。
- 数据探索:在此阶段,您可以绘制箱线图和 qplots 以了解每个预测变量的显着性。请参阅人口普查收入项目以了解如何使用图表来研究每个变量的重要性。
- 数据建模:对于这个特定的问题陈述,由于结果是一个连续变量(销售数量),因此构建回归模型是合理的。线性回归算法可用于解决此类问题,因为它专门用于预测连续因变量。
- 验证模型:在这个阶段,您应该使用测试数据集评估数据模型的效率,最后使用混淆矩阵计算模型的准确性。
芝加哥犯罪分析
随着芝加哥发生的犯罪数量增加,执法机构正在尽最大努力了解此类行为背后的原因。像这样的分析不仅可以帮助了解这些犯罪背后的原因,而且还可以防止进一步的犯罪。
问题陈述:分析和探索芝加哥犯罪数据集,以了解有助于预测此类重罪未来发生的趋势和模式。
数据集描述:该项目使用的数据集包含 2014 年 1 月 1 日至 2016 年 10 月 24 日芝加哥市发生的所有犯罪事件。
对于此分析,数据集包含许多预测变量,例如:
- ID – 记录的标识符
- 案件编号 – 芝加哥警察链 RD 编号
- 日期 - 事件发生日期
- 描述 – IUCR 代码的辅助描述
- 位置 - 发生事件的位置
逻辑:
与任何其他数据科学项目一样,遵循以下描述的一系列步骤:
-
导入数据集:本项目所需的数据集可以从Kaggle下载。
-
数据清理:在此阶段,您必须确保消除所有不一致,例如缺失值和任何冗余变量。
-
数据探索:您可以通过将犯罪的发生转化为城市地理地图上的情节来开始此阶段。以图形方式研究每个预测变量将帮助您了解哪些变量对于构建模型至关重要。
-
数据建模:对于这个特定的问题陈述,由于犯罪的性质各不相同,因此构建聚类模型是合理的。K-means 是最适合这种分析的算法,因为使用 k-means 很容易构建集群。
-
分析模式:由于此问题陈述需要您绘制有关犯罪的模式和见解,因此此步骤主要涉及创建报告并从数据模型中得出结论。
-
验证模型:在这个阶段,您应该使用测试数据集评估数据模型的效率,最后使用混淆矩阵计算模型的准确性。
电影推荐引擎
每个成功的数据科学家在他的职业生涯中都至少构建了一个推荐引擎。个性化推荐引擎被视为数据科学项目的圣杯,这就是我在博客中添加这个项目的原因。
问题陈述:分析 Movie Lens 数据集以了解有助于向用户推荐新电影的趋势和模式。
数据集描述:本项目使用的数据集由明尼苏达大学的 GroupLens 研究项目收集。
数据集由以下预测变量组成:
- 943 位用户对 1682 部电影的 100k 评分。
- 每个用户至少对 20 部电影进行过评分
- 用户的详细信息,如年龄、性别、职业、地理等。
通过研究这些预测变量,可以建立一个模型来向用户推荐电影。
逻辑:
- 导入数据集:本项目所需的数据集可以从Kaggle下载。
- 数据清理:在此阶段进行必要的清理和转换,以便模型可以预测准确的结果。
- 数据探索:在此阶段,您可以评估电影类型如何影响观众的收视率。同样,您可以根据用户的年龄、性别和职业来评估他的电影选择。以图形方式研究每个预测变量将帮助您了解哪些变量对于构建模型至关重要。
- 数据建模:对于这个问题陈述,您可以使用 k-means 聚类算法,根据相似的电影观看模式对用户进行聚类。您还可以使用关联规则挖掘来研究用户与其电影选择之间的相关性。
- 验证模型:在这个阶段,您应该使用测试数据集评估数据模型的效率,最后使用混淆矩阵计算模型的准确性。
文本挖掘
在你的简历中加入文本挖掘项目肯定会增加你被聘为数据科学家的机会。它涉及高级分析和数据挖掘,这将使您成为熟练的数据科学家。文本挖掘的一个流行应用是情绪分析,它在社交媒体监控中非常有用,因为它有助于获得对某些主题的更广泛公众意见的概览。
问题陈述:使用自然语言处理技术对一组文档进行预处理、文本分析、文本挖掘和可视化。
数据集描述:该数据集包含来自原始三部曲剧集的著名星球大战系列的脚本,即 IV、V 和 VI。
逻辑:
- 导入数据集:对于这个项目,你可以在Kaggle上找到数据集。
- 预处理:在文本挖掘过程的这个阶段,您必须去除不一致性,例如停用词、标点符号、空格等。还可以执行词形还原和数据词干等过程以进行更好的分析。
- 构建文档术语矩阵 (DTM):此步骤涉及创建文档术语矩阵 (DTM)。它是一个列出文档中单词出现频率的矩阵。在这个矩阵上执行文本分析。
- 文本分析:文本分析涉及分析文档中每个单词的词频并找出单词之间的相关性以得出结论。
- 文本可视化:使用直方图和词云来表示重要词是文本挖掘的重要步骤之一,因为它可以帮助您理解文档中最重要的词。
所以这些是一些帮助您入门的数据科学项目。我已经为您提供了解决每个用例的蓝图,您只需按照步骤操作即可。如果您想尝试并做自己的事情,请不要犹豫。
另外,不要忘记在评论部分分享您的实现,我很想知道您的解决方案如何。
既然您知道如何使用数据科学解决现实世界的问题,我相信您很想了解更多信息。以下是可帮助您入门的博客列表:
有了这个,我们来到了这个博客的结尾。如果您对此主题有任何疑问,请在下方留言,我们会尽快回复您。
请继续关注有关趋势技术的更多博客。

- 点赞
- 收藏
- 关注作者
评论(0)