性能分析之性能建模简述

前言
经常在性能领域里听到建模这个词,也看到有些人写了一些文章或 PPT 描述建模。今天在网上也搜索了一下,看到有五花八门的内容。我也写一下我对性能建模的理解。
建模的定义
在一开始做性能项目的时候,就有些疑惑,到底什么是性能建模呢。搜索了下建模的定义:
建模就是建立模型,就是为了理解事物而对事物做出的一种抽象,是对事物的一种无歧义的书面描述。
建立系统模型的过程,又称模型化。建模是研究系统的重要手段和前提。凡是用模型描述系统的因果关系或相互关系的过程都属于建模。因描述的关系各异,所以实现这一过程的手段和方法也是多种多样的。可以通过对系统本身运动规律的分析,根据事物的机理来建模;也可以通过对系统的实验或统计数据的处理,并根据关于系统的已有的知识和经验来建模。还可以同时使用几种方法。
大概有这么几处地方涉及到了模型这个概念:
- 业务模型
- 测试模型
- 监控模型
- 分析模型
- 失效模型
- 排队模型
(如果有人看到有其他的性能模型的概念,也请告诉我一下)这些要怎么做呢?
业务模型和测试模型
基本上业务模型和测试模型的创建是来源于生产环境的数据统计。
如下图所示:
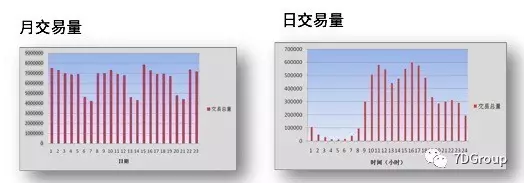
做了这些业务的统计后,再把峰值(每小时或每分钟或每秒)的业务提取出来,做成如下表:
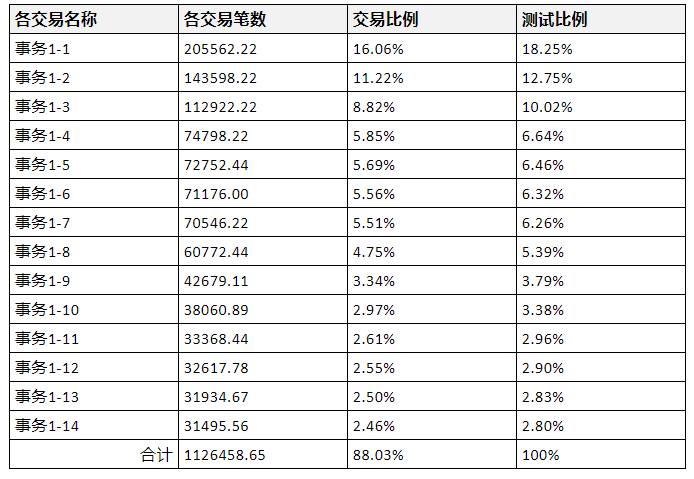
其中交易的比例是根据实际的业务数据比例,过滤掉业务量太小不太可能出现大并发的业务之后,就有了测试比例。于是这个列表中就同时有了业务模型和测试模型。而这一操作过程就是建模的过程了。
这个过程如果被称为建模也不是不可以,但是还是感觉像在打擦边球的感觉,没有那么让人觉得很高大上。
监控模型
监控模型也是差不多的过程,它的依赖条件是部署架构。所以要先画出来有多少台机器,每个机器上都安装了什么,再看用什么工具去做监控。这个抽象的分析过程我们也可以趋炎附势地称之为建模吧。
如下所示:
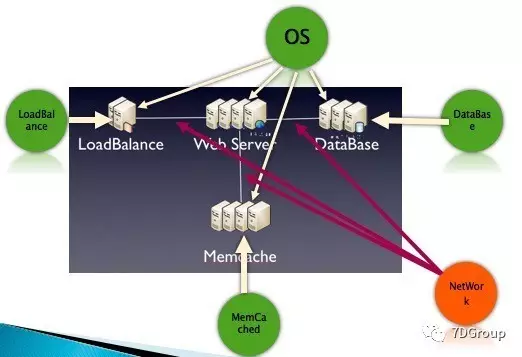
这里是我在之前一个项目中画的简图(我把 Web Server 和 APP Server 画到一起了),这里涉及到的机器大概有 150 台。
这里要监控的点有多少呢,我们可以来数一下:
- 150 个OS
- 2 个 LB
- 130 个web server
- 20 个 DB
- 4 个 MemCached
- 1 Network
177个监控点 in total。
网络之所以只写一个是因为全用的是交换机,也就是这些机器都在同一网段里。如果是生产系统,可能还会涉及到多个网段,包括路由器、防火墙等内容也是要监控的。
这个是网络部署的层面,如果有业务逻辑架构图的话,也可以根据业务逻辑架构图来画。
这个过程,我们称之为监控建模。
分析模型
其实分析模型涉及到挺多内容的,我们暂且来简化一下。先说响应时间的分段模型,如下图所示:
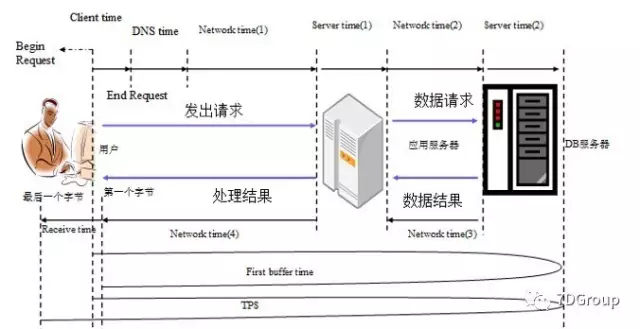
这个图想必有很多人看到过。这里基本上把响应时间拆分到比较细的粒度了。根据这个图做时间分段,可以明确地知道响应时间到底在哪个环节消耗得多。
画出这个图的过程就是响应时间分析建模的过程。
响应时间分析模型中还有分层,这个比较难做,并且现在大部分人对从驱动层到上层的应用层分析做不到那么细的粒度,更何况在大部分场景下也不是那么有必要。因为通过监控工具就可以看出在哪个层面出问题了。
这里我画个简图说明一下:
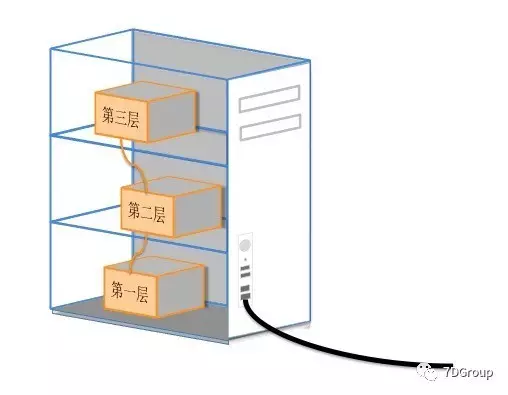
这个图要表达的意思是,从数据进到一台主机,从第一层开始,每一层都是可以拆分来分析的。如果出现一些比较极端的问题,比如说在第一层出现了问题,那么在第三层的监控中就不太可能看得出来。但是通过上一图的响应时间分段分析,就可以确定是这个主机有问题。这种的分析要求技术功底就比较强了。
比如说运行一个 tomcat 服务器。要分析的层面就有:
这样划分是不是够细了呢?在一个具体的问题中,往往是不够的。如下所说:
-
OS 层(拿 linux 举例来说):又要横向和纵向细分。像 CPU、内存、IO、
File System、Process 等等,到这一层,有少数性能问题是可以通过改系统级的参数来解决问题的,也就是系统级的问题。那如果不是系统级的问题呢?就要接着看。 -
JVM 层:JVM 中又要分为堆和栈、
class loader、execution engine等,堆又要分为年轻代、年老代,持久代(sun jdk 1.8版本之后是metaspace元空间)。这些也是这个分析建模中要涉及的。 在这些之后呢。 -
Tomcat 层:应用服务器的架构相对来说比较简单,像 tomcat,要理解的内容就是 server、service、engine、host、context等,这些是 tomcat 架构层的内容。从监控和配置的角度来看,要关注的内容就是线程池、超时(超时又分为
connection timeout和keepalive timeout)、队列、缓冲区大小等内容。这些分析了之后,能对 tomcat 层有个了解了。 -
业务代码层:通常我们遇到的问题在这一层是最多的,所以也就有了很多人认为性能分析其实代码功底是必须的,并且只要会了这一层的内容,就非常专家了。因为其他的层面基本上是成熟的。可以理解这个想法,但是不能赞同只学习这一层的做法。因为性能问题确实就是会出现各个层面的问题。
像这种代码层的问题,在我的经验中是最容易定位的。基本上做了profile之后都是可以快速定位的。所以在前面的文章中我有写到剖析工具的内容。这些剖析工具的使用比较简单,不过要看懂数据,就得明白一些原理,不然看个堆栈都不知道是什么意思。
这些层面的抽象过程就是分析建模的过程。
所以基本上性能分析建模是分段和分层就可以了的,这个思路对大部分人来说是可以理解和接受的,但是难的是把这些内容能融会贯通的解释。
失效模型
在在性能领域里提失效模型的时候基本上都不是正经的失效模型。因为做得太简单。解释得太表面。
失效模型是在以上的模型中模拟问题出现来分析影响的。它是有非常完整的数学理论来支撑的。这个过程不仅耗时费力,而且短时间内很难把失效模型创建得特别完整。如果要做得粒度比较细的话,我觉得基本上在IT行业中是不现实的。
不过,我觉得有一种方式可以让失效模型能很快用起来,就是宏观分析。不像在分析模型中提到的那么细。而是把一台主机、或一类主机、或一个网络、或一个服务做为最细的粒度来做。
这个过程不费太多的时间,但是需要特别有经验的人来针对一个系统分析。这个建模的过程,也有完整的理论支撑。分析失效模型和影响分析是最重要的。
摘一个表格看一下:
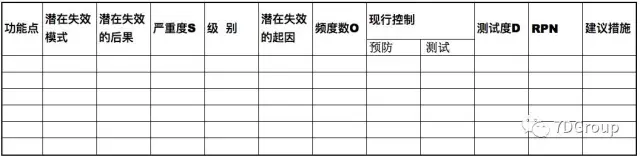
这是一个 SOD 分级表,RPN 是风险系数。
举例来说,如果有两个机房的服务器做分布式,如果基中一个机房停电了,对整个系统的影响是什么,流量的切换,压力的承载都要详细分析并通过测试,并且把相应的解决措施写出来。这个在很多企业都有做。并且这个一定要针对一个特定的系统做,只是理论的分析,没什么价值。
排队模型
排队模型在性能分析中可以做宏观分析手段,也可以做为微观分析手段。小到一个磁盘的 IO 模型,大到一个完整的系统流量建模,都可以创建对应的模型。
这就是最简单的模型:M/M/1/∞ /∞ /FCFS。

这个在我之前的文章中已经有比较多的描述了,请看这篇文章:性能分析之排队论应用
这就是另一个模型:M/M/C/∞ /∞ /FCFS。

我看到网上有人写理发店模型的,其实那个还不能称为模型,它只是排队理论的一个小例子而已。
说到排队论,这个数学理论非常完善,有兴趣的可以看看相关的书。数学公式也是比较完整的。在《性能之巅洞悉系统、企业与云计算》那本书中有提到 /M/D/1 的模型的例子,是用来分析磁盘 IO 的。这个还不能算是架构级分析的例子。
我前几天用R语言做了一个 /M/M/C/FCFS 的模型实例,通过计算已经以算出平均响应时间和等待时间了。但是对一个具体的系统来说,这个模型仍然需要重建。因为一些输入的变量是必须通过统计分析才能得到的,所以我还做了一些例子,并且用 SPSS 分析了到达链的分布。
总结
对性能建模的内容写了这么多,希望能让做性能的人知道什么是真正的性能建模。

- 点赞
- 收藏
- 关注作者
评论(0)