Roof-line Model性能分析模型简介

【摘要】 REFRoofline Model与深度学习模型的性能分析 - 知乎Roofline: An Insightful Visual Performance Model for Floating-Point Programs and Multicore Architectures https://people.eecs.berkeley.edu/~kubitron/cs252/handouts...
REF
Roofline: An Insightful Visual Performance Model for Floating-Point Programs and Multicore Architectures
Roof-line Model模型简介
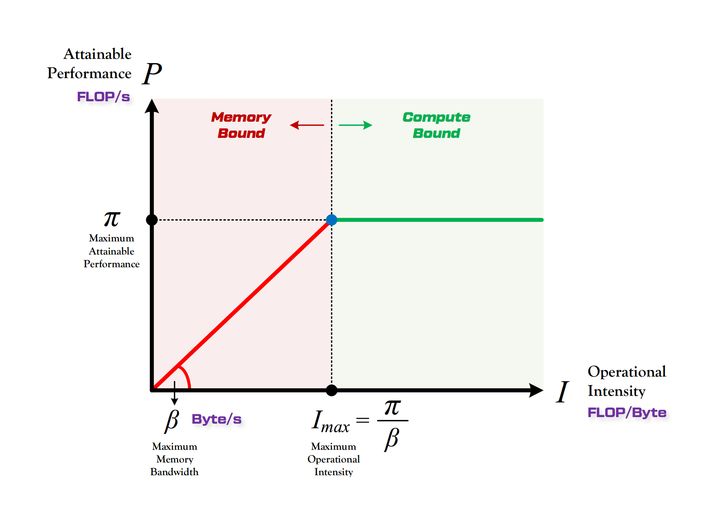
![]()
Roof-line Model讲的是我们理论能够获得的最大计算性能FLOPS。图像横坐标为计算强度,为实际的计算量除以访存量,而纵坐标为我们能够获得的最大理论计算性能。
当实际的计算强度(计算量/访存量)大于Imax时,我们理论上获得硬件最大的计算性能pi,这时程序计算时间为实际的计算量除以pi。
而实际计算强度小于Imax时,我们理论能获得的最大计算性能达不到pi,只能达到实际的计算量/访存量*beta。这个模型说明如果访存利用率低,我们难以达到硬件拥有的最大性能。
因此我们需要提升计算的计算强度,从而最大化实际能够获得的计算性能。例如算子融合,则是在相同计算量的时候避免了中间的访存过程,从而降低了访存量,提高了计算强度。而矩阵乘法,通过合理的分块等方式,也能够减低访存量增大计算强度。
要注意一个计算理论的访存量和实际实现的访存量。例如矩阵乘法,理论的访存量和实际的访存量可能完全不一样。而elemwise计算两者通常可能是一致的。此外,理论算力是明确的,但是对于带宽部分,由于存储系统存在层级,实际能够获得的带宽跟计算过程也有关,数据时间和空间局部性利用好的算法能够获得的理论带宽也就越高。
矩阵乘优化过程中的roof-line分析实践:

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)