MV3D-Net 用于自动驾驶的多视图3D目标检测网络

前言
MV3D-Net融合了视觉图像和激光雷达点云信息;它只用了点云的俯视图和前视图,这样既能减少计算量,又保留了主要的特征信息。随后生成3D候选区域,把特征和候选区域融合后输出最终的目标检测框。
论文地址:Multi-View 3D Object Detection Network for Autonomous Driving
开源代码:https://github.com/bostondiditeam/MV3D
一、框架了解
先看下总体网络结构:(可以点击图片放大查看)
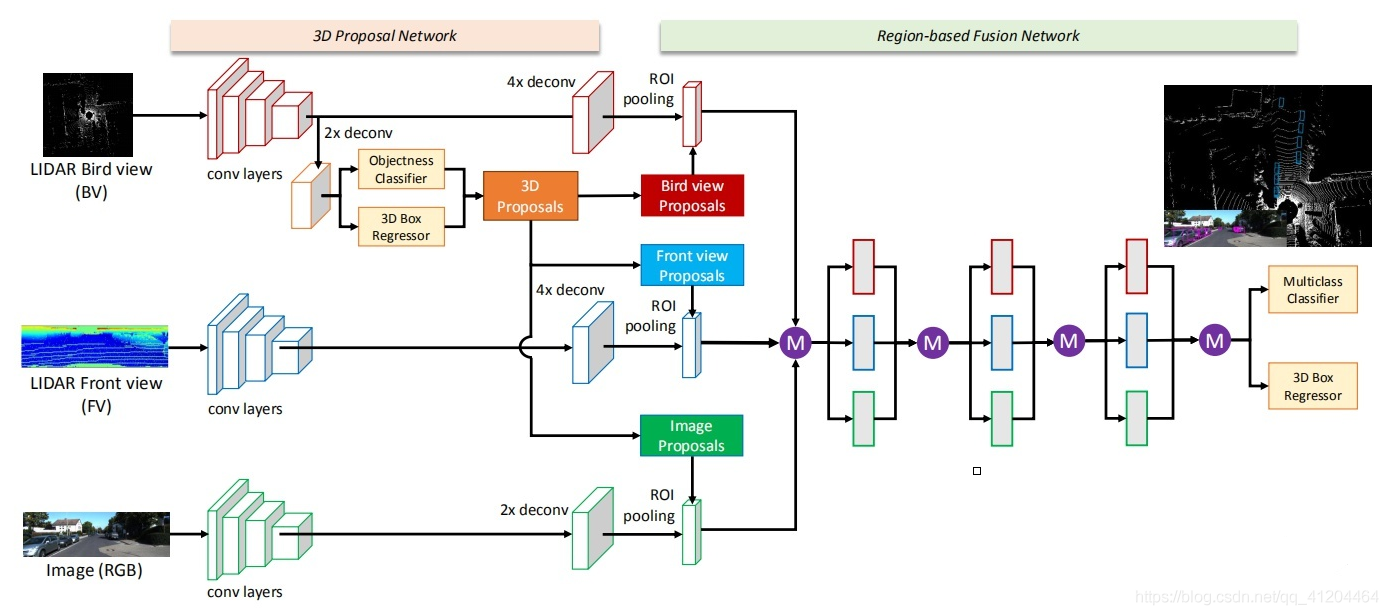
输入的数据:有三种,分别是点云俯视图、点云前视图和二维RGB图像。“点云投影”,其实并非简单地把三维压成二维,而是提取了高程、密度、光强等特征,分别作为像素值,得到的二维投影图片。
输出数据:类别标签、3D候选框、时间戳。
1.1 网络的主体部分

思路流程:
1)提取特征
- a. 提取点云俯视图特征
- b. 提取点云前视图特征
- c. 提取图像特征
2)从点云俯视图特征中计算候选区域
3)把候选区域分别与1)中a、b、c得到的特征进行整合
- a. 把俯视图候选区域投影到前视图和图像中
- b. 经过ROI pooling整合成同一维度
1.2 网络的融合部分
这部分网络主要是:把整合后的数据经过网络进行融合

二、MV3D的点云处理
MV3D将点云和图片数据映射到三个维度进行融合,从而获得更准确的定位和检测的结果。这三个维度分别为点云的俯视图、点云的前视图以及图片。

![]()
2.1 提取点云俯视图
点云俯视图由高度、强度、密度组成;作者将点云数据投影到分辨率为0.1的二维网格中。
高度图的获取方式为:将每个网格中所有点高度的最大值记做高度特征。为了编码更多的高度特征,将点云被分为M块,每一个块都计算相应的高度图,从而获得了M个高度图。
强度图的获取方式为:每个单元格中有最大高度的点的映射值。
密度图的获取方式为:统计每个单元中点云的个数,并且按照公式:
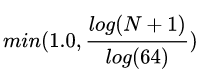
其中N为单元格中的点的数目。强度和密度特征计算的是整个点云,而高度特征是计算M切片,所以,总的俯视图被编码为(M + 2)个通道的特征。
2.2 提取点云前视图
由于激光点云非常稀疏的时候,投影到2D图上也会非常稀疏。相反,作者将它投影到一个圆柱面生成一个稠密的前视图。 假设3D坐标为:

那么前视图坐标:
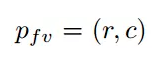
可以通过如下式子计算
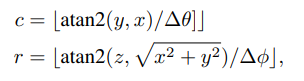
三、MV3D的图像处理
采用经典的VGG-16来提取图像特征,这里就不过多说明了。
四、俯视图计算候选区域
物体投射到俯视图时,保持了物体的物理尺寸,从而具有较小的尺寸方差,这在前视图/图像平面的情况下不具备的。在俯视图中,物体占据不同的空间,从而避免遮挡问题。
在道路场景中,由于目标通常位于地面平面上,并在垂直位置的方差较小,可以为获得准确的3Dbounding box提供良好基础。
候选区域网络就是熟悉的RPN。参考
五、特征整合
把候选区域分别与提取的特征进行整合

流程:
- a. 把俯视图候选区域投影到前视图和图像中
- b. 经过ROI pooling整合成同一维度
六、特征融合
有了整合后的数据,需要对特征进行融合,最终得到类别标签、3D候选框。
作者介绍了三种不同的融合方式,分别为
- a、Early Fusion 早期融合
- b、Late Fusion 后期融合
- c、Deep Fusion 深度融合。
各自的结构如下图所示。

最终选择了Deep Fusion 深度融合。融合的特征用作:分类任务(人/车/...)、更精细化的3D Box回归(包含对物体朝向的估计)。
七、模型效果
和其他模型对比的数据:


![]()
检测效果:

![]()
八、模型代码
代码地址:https://github.com/bostondiditeam/MV3D
作者使用KITTI提供的原始数据,点击链接

上图是用于原型制作的数据集 。
我们使用了[同步+校正数据] + [校准](校准矩阵)+ [轨迹]()
所以输入数据结构是这样的:

![]()
运行 src/data.py 后,我们获得了 MV3D 网络所需的输入。它保存在kitti中。

![]()
上图是激光雷达俯视图(data.py后)

上图是将 3D 边界框投影回相机图像中。
输入具体数据格式可以参考'data.py' 'data.py' 网址
https://drive.google.com/file/d/0B47OwD8fbxJNeU5WSUVua0JWcFU/view?usp=sharing
本文参考:https://zhuanlan.zhihu.com/p/86312623
https://zhuanlan.zhihu.com/p/353955895
https://cloud.tencent.com/developer/news/223860
论文地址:Multi-View 3D Object Detection Network for Autonomous Driving
代码地址:https://github.com/bostondiditeam/MV3D
本文只提供参考学习,谢谢。

- 点赞
- 收藏
- 关注作者
评论(0)