Python—OpenCV创建级联文件(Windows7/10环境)

目录
之前使用Python+OpenCV实现交通路标识别,具体实现步骤及心得如下:
OpenCV训练属于自己的xml文件,需以下几个步骤:
1、首先下载OpenCV(Windows版);
2、准备数据集,分为正样本集和负样本集;
3、生成路径,将正样本集的路径要存成 *.vec格式;负样本集的路径不做要求,*.txt就可以;
4、训练xml文件。
OpenCV创建级联文件需要先下载OpenCV(Windows版)。
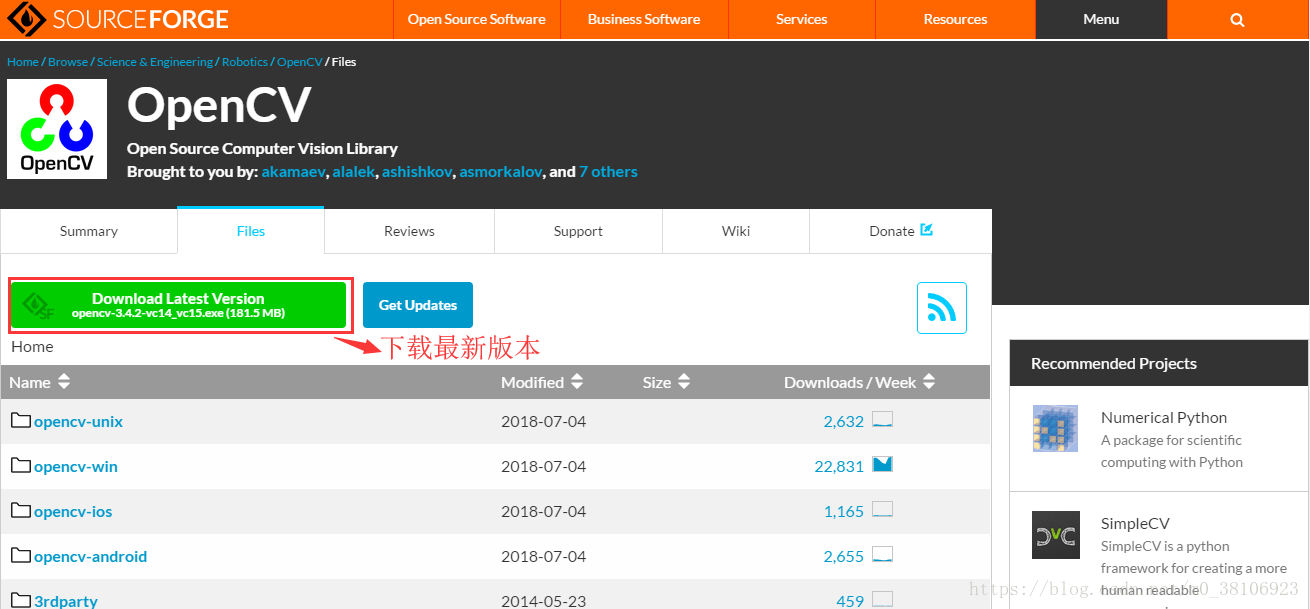
接下来傻瓜式安装操作,安装到指定路径。

安装成功后开始配置环境变量(配置环境变量比较简单,此处省略),稍后会用到OpenCV中的opencv_createsamples.exe和opencv_traincascade.exe文件训练级联文件,我的安装路径在D盘,所以设置环境变量的路径是D:\opencv\opencv\build\x64\vc15\bin。 注意:若直接在D:\opencv\opencv\build\x64\vc15\bin路径下训练模型,可以不用配置环境变量。

需要准备正样本数据集(所要识别的物体)和负样本数据集(背景图片、干扰图片),数据集数量越多种类越复杂越好。
通常正样本数据裁剪为20*20或40*40大小的像素即可(这里我使用40*40像素训练模型,9小时+可以训练完成),注意:像素过大训练速度相当慢,图片像素最好是正方形图片,长宽相等。
通常负样本数据集是识别物体的背景环境照片,图片越多越复杂抗干扰能力越强,负样本图片可以不用裁剪为固定大小,但是为了提升训练速度建议进行合理裁剪。
正样本图片如下:
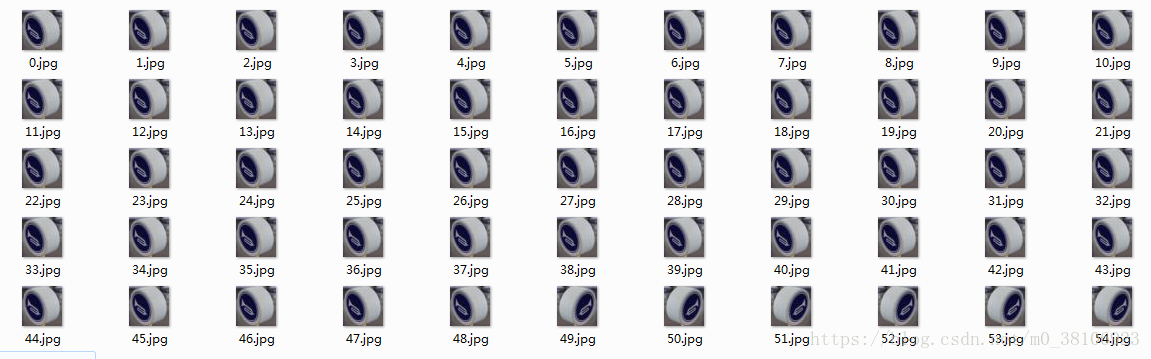
负样本图片如下:

为了操作方便,我写了Python程序实现批量调整图片数据大小和图片命名,具体如下:
-
# -*- coding:utf8 -*-
-
import os
-
from PIL import Image
-
'''
-
批量重命名文件夹中的图片文件
-
-
'''
-
class BatchRename():
-
def __init__(self):
-
self.path = r'C:\Users\Administrator\Desktop\opencv-haar-classifier-training-master\positive_images'
-
-
def rename(self):
-
filelist = os.listdir(self.path)
-
total_num = len(filelist)
-
i = 0
-
for item in filelist:
-
if item.endswith('.jpg'):
-
src = os.path.join(os.path.abspath(self.path), item)
-
print(src)
-
dst = os.path.join(os.path.abspath(self.path), str(i) + '.jpg')
-
try:
-
os.rename(src, dst)
-
print ('converting %s to %s ...' % (src, dst))
-
i = i + 1
-
except :
-
continue
-
print ('total %d to rename & converted %d jpgs' % (total_num, i))
-
-
if __name__ == '__main__':
-
demo = BatchRename()
-
demo.rename()
-
-
'''
-
批量修改图片尺寸
-
'''
-
#提取目录下所有图片,更改尺寸后保存到另一目录
-
import os.path
-
import glob
-
def convertjpg(jpgfile,outdir,width=40,height=40):
-
img=Image.open(jpgfile)
-
try:
-
new_img=img.resize((width,height),Image.BILINEAR)
-
new_img.save(os.path.join(outdir,os.path.basename(jpgfile)))
-
except Exception as e:
-
print(e)
-
for jpgfile in glob.glob(r"C:\Users\Administrator\Desktop\opencv-haar-classifier-training-master\positive_images\*.jpg"):
-
#像素修改后存入images文件
-
convertjpg(jpgfile,r"C:\Users\Administrator\Desktop\opencv-haar-classifier-training-master\images")
1、首先按照要求创建训练文件夹
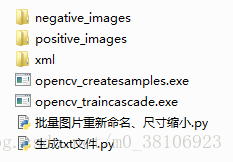
negative_images文件夹存放负样本图片。
positive_images文件夹存放正样本图片。
xml文件夹存放稍后生成的xml级联文件。
opencv_createsamples.exe负责生成*.vec文件。
opencv_traincascade.exe负责训练级联文件模型。
另外我还写了两个Python文件负责批量处理图片命名、尺寸缩小和生成对应的txt文件。
2、生成指定的txt文件路径
执行这一步之前保证文件已经命名规范,尺寸缩小到合适大小。
运行生成txt文件.py文件,生成对应的正样本路径和负样本路径文件,效果如下:
文件夹结构如下:
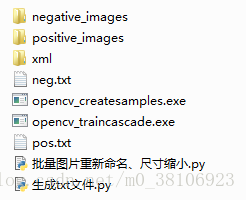
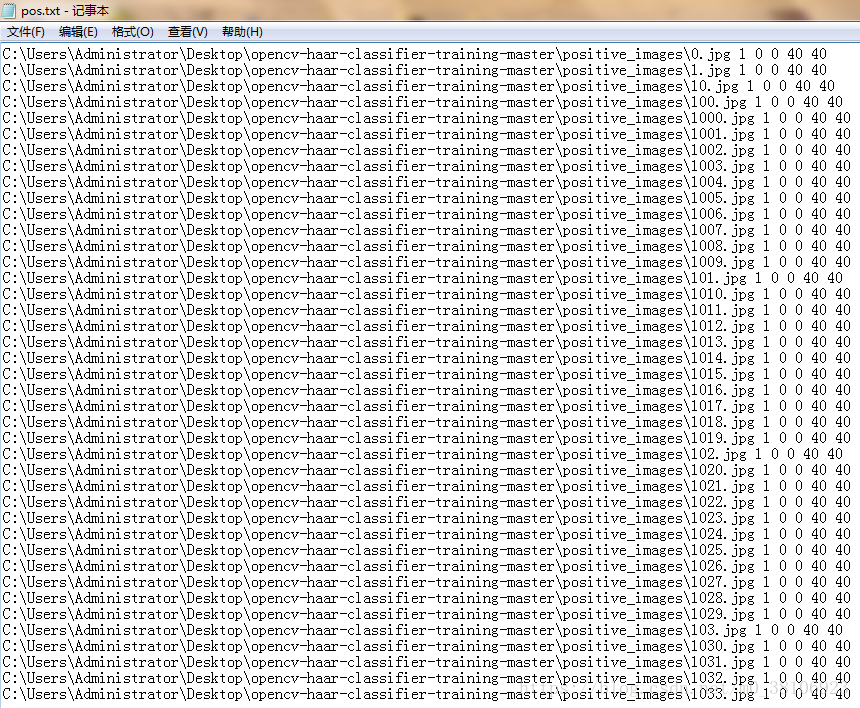
正样本路径文件(pos.txt)格式如下:
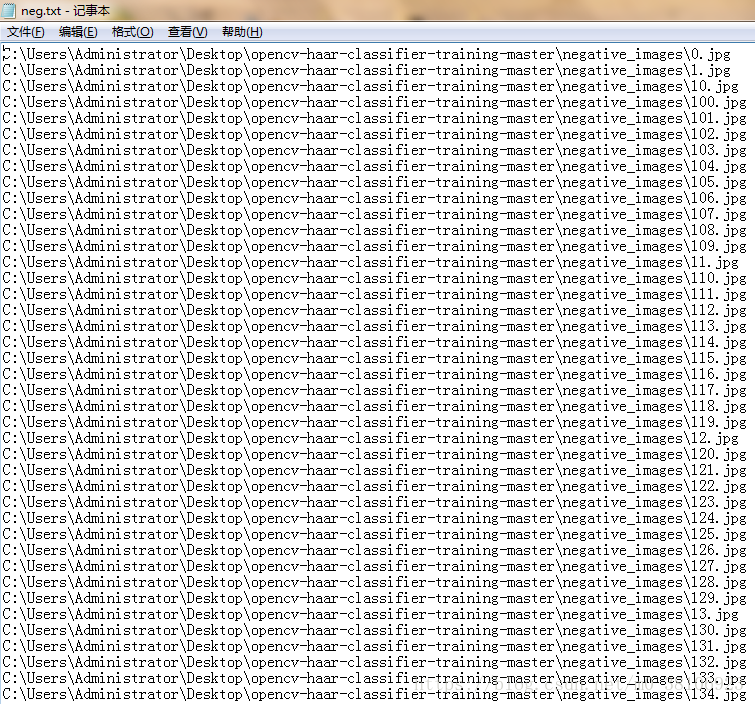
正样本路径文件(neg.txt)格式如下:
生成对应的txt文件Python代码如下:
-
import os
-
'''
-
正样本数据生成txt文件
-
'''
-
file_dir=os.getcwd()
-
file_dir=r'C:\Users\Administrator\Desktop\opencv-haar-classifier-training-master\positive_images'
-
L=[]
-
i=0
-
with open("pos.txt","w+") as f:
-
for root, dirs, files in os.walk(file_dir):
-
for file in files:
-
if os.path.splitext(file)[1] == '.jpg':
-
L.append(os.path.join(root, file))
-
f.write(L[i]+' 1'+' 0'+' 0'+' 40'+' 40'+'\n')
-
i+=1
-
'''
-
负样本数据生成txt文件
-
'''
-
file_dir=r'C:\Users\Administrator\Desktop\opencv-haar-classifier-training-master\negative_images'
-
L=[]
-
i=0
-
with open("neg.txt","w+") as f:
-
for root, dirs, files in os.walk(file_dir):
-
for file in files:
-
if os.path.splitext(file)[1] == '.jpg':
-
L.append(os.path.join(root, file))
-
f.write(L[i]+'\n')
-
i+=1
3、获取正样本矢量集vec文件
在文件夹下新建createsamples.bat,批处理文件,内容如下:
-
opencv_createsamples.exe -vec pos.vec -info pos.txt -num 1100 -w 40 -h 40
-
pause
其中,-vec后面是将生成的正样本矢量集vec文件,-info后面是正样本路径文件,-num后面的数字是正样本个数,-w后面的数字是正样本图片的长,-h后面的数字是正样本图片的高。
双击createsamples.bat后出现pos.vec即为运行成功。
此时文件夹结构如下:
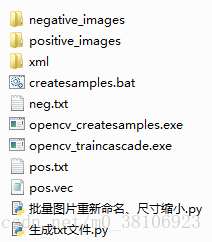
4、训练级联文件模型
在文件夹下新建train.dat文件,内容如下:
-
opencv_traincascade.exe -data xml -vec pos.vec -bg neg.txt -numPos 1100 -numNeg 3205 -numStages 15 -w 40 -h 40 -minHitRate 0.999 -maxFalseAlarmRate 0.5 -mode ALL
-
pause
其中,-data 是存放训练好的分类器的路径 ,-vec 就是存放.vec的路径, -bg 负样本描述文件, -numPos 每一阶段训练的正样本数量 , -numNeg 每一阶段训练的负样本数量 (网上说-numPos的参数要比实际正样本数量小,-numNeg 的参数要比实际负样本数量大 ), -numStages 训练阶段数 (这个参数不能太大也不能太小 ,太大训练时间过长,如果太小的话 生成的xml文档分类效果可能就不太好 ), -featureType 选择LBP还是HAAR 在此选用LBP ,-w -h 训练样本尺寸 和vec生成的尺寸大小相同 不然会宕机, -minHitRate 最小命中率 ,-maxFalseAlarmRate 最大虚警率 ,最后需要在加上 -mode ALL。
此时文件夹结构如下:
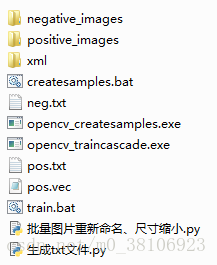
双击train.bat后进入训练模式,进入漫长等待,效果如下:
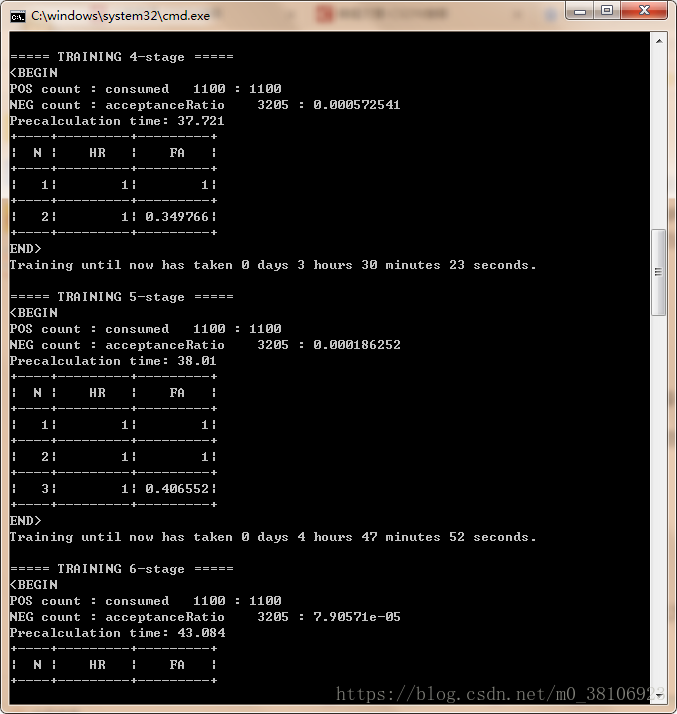
最后训练完成之后级联文件保存在xml文件夹中。
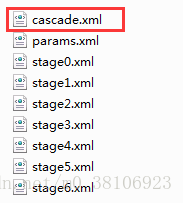
其中,只有第一个cascade.xml文件是我们所需要的文件,其余文件是训练过程中生成的检查的文件,防止训练过程中出现意外程序重头训练。
下面使用Python代码进行模型测试,效果如下:

验证Python代码如下:
-
import numpy as np
-
import cv2
-
face_cascade = cv2.CascadeClassifier('cascade.xml')
-
cap = cv2.VideoCapture(0)
-
while True:
-
ret,img = cap.read()
-
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
-
faces = face_cascade.detectMultiScale(gray, 1.3, 5)
-
for (x,y,w,h) in faces:
-
cv2.rectangle(img,(x,y),(x+w,y+h),(255,0,0),2)
-
cv2.imshow('img',img)
-
if cv2.waitKey(1) &0xFF == ord('q'):
-
break
-
cap.release()
-
cv2.destroyAllWindows()
最后我将模型搭建在树莓派上,发现识别效果,处理速度还是蛮不错的。
文章来源: handsome-man.blog.csdn.net,作者:不脱发的程序猿,版权归原作者所有,如需转载,请联系作者。
原文链接:handsome-man.blog.csdn.net/article/details/81912705

- 点赞
- 收藏
- 关注作者
评论(0)