深入了解PyTorch:autograd

🍀关于torch.tensor
torch.Tensor是整个package中的核心类如果将属性requires_grad设置为True,它将追踪在这个类上定义的所有操作.当代码要进行反向传播的时候,直接调用.backword()就可以自动计算所有的梯度在这个Tensor上的所有梯度将被累加进属性.grad中
如果想终止一个Tensor在计算图中的追踪回溯,只需要执行.detach()就可以将该Tensor从计算图中撤下,在未来的回溯计算中也不会再计算该Tensor
除了.detach(),如果想终止对计算图的回溯,也就是不再进行方向传播求导数的过程,也可以采用代码块的方式with torch.no_grad():,这种方式非常适用于对模型进行预测的时候,因为预测阶段不再需要对梯度进行计算
🍀关于torch.Function
Function类是和Tensor类同等重要的一个核心类,它和Tensor共同构建了一个完整的类,每一个Tensor拥有一个.grad_fn属性,代表引用了哪个具体的Function创建了该Tensor
如果某个张量Tensor是用户自定义的,则其对应的grad_fn is None.
🍀有关Tensor的操作
import torch
x = torch.ones(3,3)
print(x)
y = torch.ones(2,2,requires_grad=True)
print(y)
运行结果如下
在具有requires_grad=True的基础上对Tensor执行加法操作
z = y + 2
print(z)
运行结果如下
print(x.grad_fn)
print(y.grad_fn)
接下来分两种情况,一种是没有进行加法操作,另一种是进行了加法操作,这也就印证了
如果某个张量Tensor是用户自定义的,则其对应的grad_fn is None.
运行结果如下

接下来进行比加法操作稍微复杂的操作演示
k = z * z * 2
out = k.mean()
print(k,out)
运行结果如下
接下来介绍方法.requires_grad_()该方法可以原地改变Tensor的属性.requires_grad的值,如果没有改变默认为FALSE
a = torch.randn(2,2)
a = ((a * 3) / (a - 1))
print(a.requires_grad)
a.requires_grad_(True)
print(a.requires_grad)
b = (a * a).sum()
print(b)
print(b.grad_fn)
运行结果如下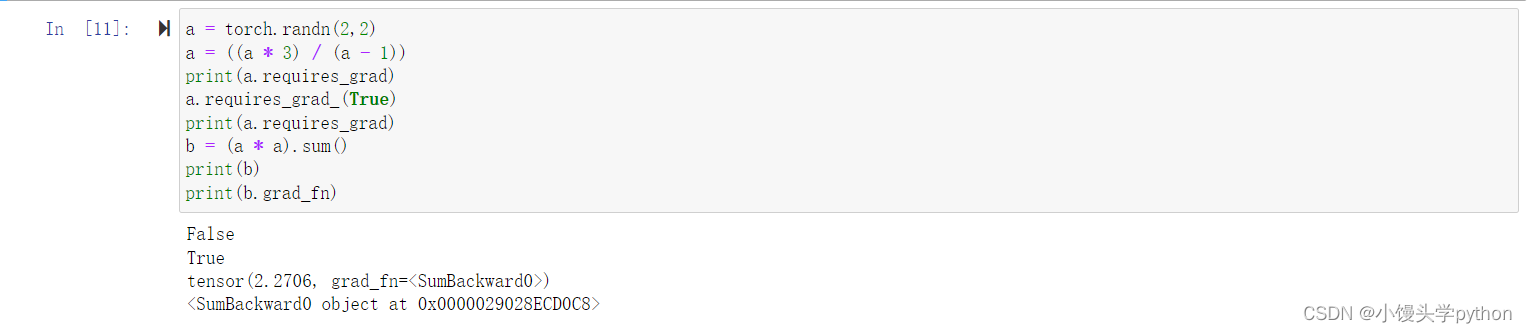
🍀关于梯度Gradients的介绍
反向传播(Backpropagation)是深度学习中一种用于计算梯度的算法。它可以有效地计算神经网络中各个参数对于损失函数的梯度,进而用于网络参数的更新和优化。
反向传播的过程可以简单分为两个步骤:前向传播和反向传播。
前向传播:在前向传播过程中,输入数据通过神经网络的各个层进行正向计算,得到最终的输出结果。中间每一层的计算都可以看作是一个函数,通过层与层之间的变换(如矩阵乘法、激活函数等),将输入数据逐层传递并进行计算,直至输出层得到最终的预测结果。
反向传播:在反向传播过程中,通过计算链式法则,将输出结果与真实标签之间的误差反向传播回每一层网络,计算每个参数对于损失函数的梯度。这样,就可以得到每个参数的梯度信息,进而根据梯度信息进行参数的更新和优化。
反向传播的基本思路是利用链式法则来计算导数,通过不断链式求导,将误差逐层反向传播回网络的每一个参数。这样可以高效地计算出每个参数对于整个网络输出的误差的贡献程度,从而进行梯度更新和权重调整。
反向传播算法的重要性在于它使得深度神经网络的训练变得可行。通过求解参数的梯度,我们可以使用梯度下降等优化方法对神经网络进行训练,最小化损失函数,使得网络在给定输入上获得更准确的输出。
这里注意,反向传播通过.backword()来实现
关于自动求导的属性设置:可以通过设置.requires_grad=True来执行自动求导,也可以通过代码块的限制来停止自动求导
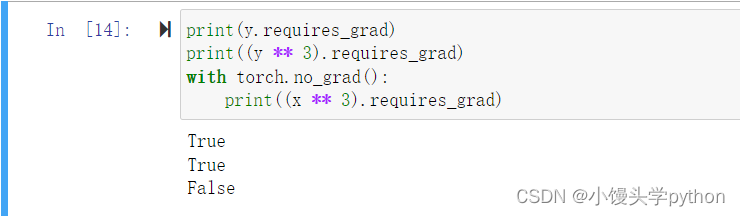
print(y.requires_grad)
print((y ** 3).requires_grad)
with torch.no_grad():
print((x ** 3).requires_grad)
运行结果如下
可以通过.detach()进而获得一个新的张量Tensor,且拥有相同的内容但不需要自动求导
print(y.requires_grad)
z = y.detach()
print(z.requires_grad)
print(y.eq(z).all())
运行结果如下
🍀总结
本篇文章是在b站学习后完成的,若有人想了解视频可以点击Python人工智能20个小时玩转NLP自然语言处理【黑马程序员】

- 点赞
- 收藏
- 关注作者
评论(0)