【Linux】翻山越岭——进程地址空间


@[toc]
一、是什么
回顾我们学习C/C++时的地址空间:
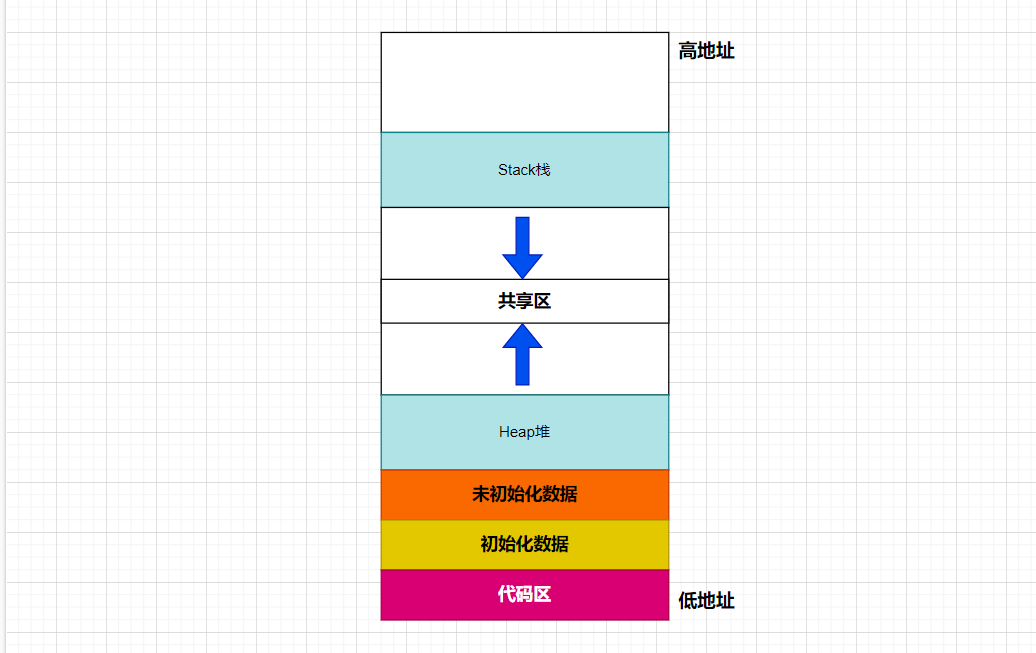
有了这个基本框架,我们对于语言的学习更加易于理解,但是地址空间究竟是什么❓我们对其并不了解,是不是内存呢?对于是什么这个问题,我们需要通过一个例子来进行切入,见一见现象
下面我们通过代码看现象:
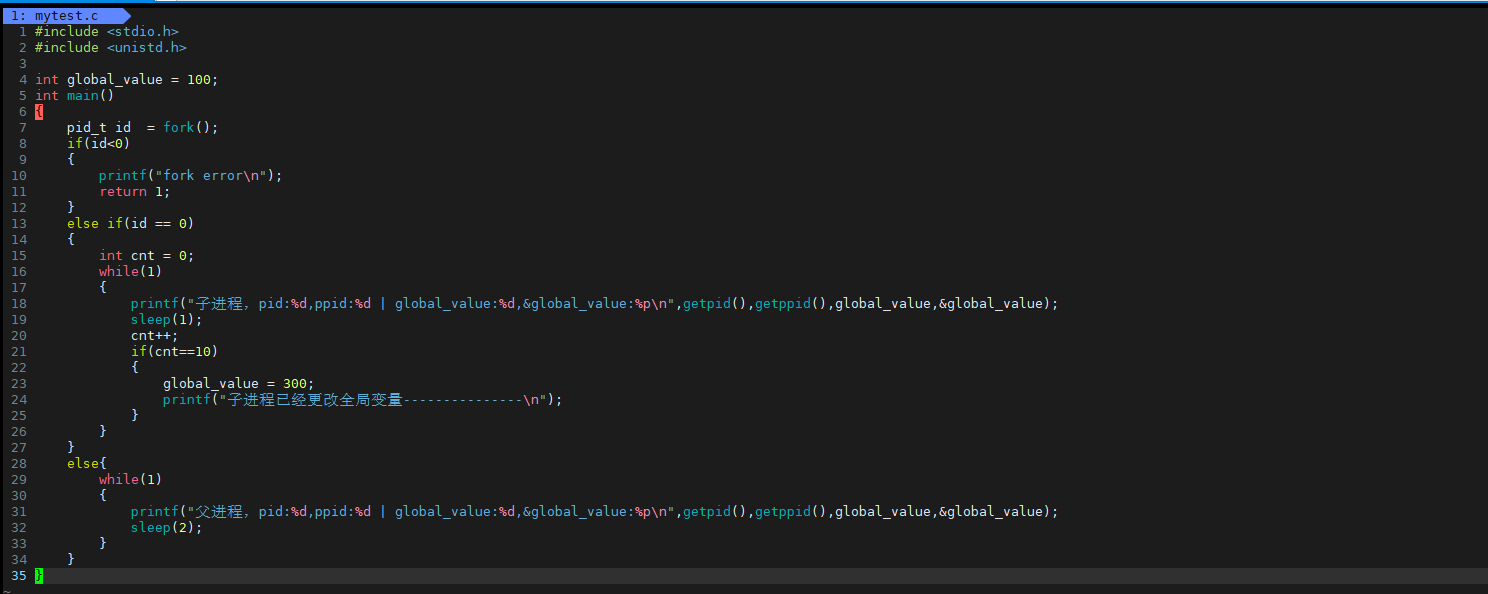
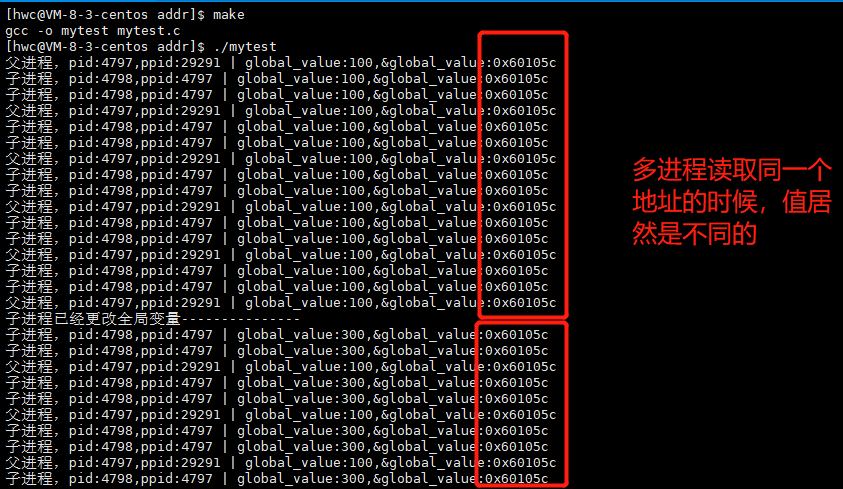
我们发现子进程把全局变量global_value修改之后,子进程和父进程的值是不同的,这些我们都能理解,因为进程之间具有独立性。但是这里global_value的地址居然是相同的!!!多进程在读取同一个地址的时候怎么可能出现不同的结果,地址相同说明了这里的地址并不是对应的物理地址,如果是物理地址改完之后打印出来的值是一样的,这也很好理解。
这里的地址实际上是虚拟地址(线性地址),Linux也有可能叫做逻辑地址。
我们可以感性地理解虚拟空间。
进程会认为自己是独占系统资源的,然而实际上并不是。操作系统会给每个进程创建地址空间,然后通过页表映射到物理内存,找到
虚拟空间。所以对于我们而言,直接使用虚拟地址,操作系统再从虚拟地址到页表加载到内存,在通过页表映射,找到对应的物理内存。也就是说,操作系统自动完成。
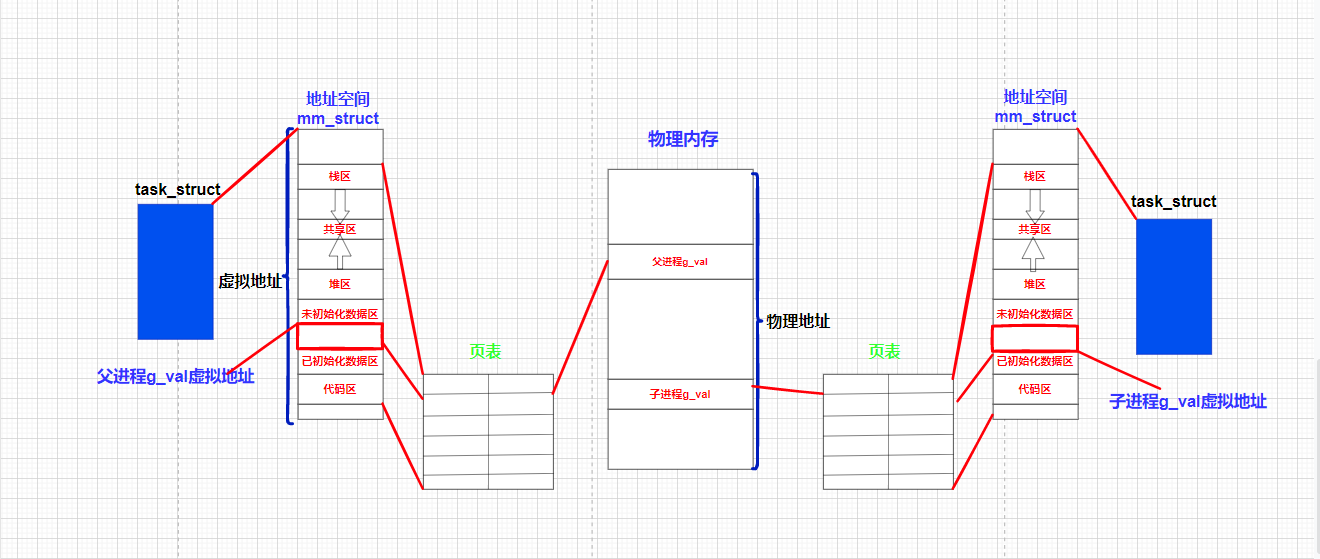
所以,对于我们刚开始的现象很好解释了:
父进程和子进程都有自己的独立的进程地址空间,且都有自己的页表结构,子进程由父进程创建,所以子进程的地址空间是从父进程拷贝而来,刚开始的g_val经过映射指向同一个物理内存,所以刚开始看到的都是100
后来子进程修改了自己地址空间的g_val的值,当操作系统通过页表映射发现g_val的值是共享的,但是我们知道进程具有独立性,所以操作系统为了保证进程的独立性,当子进程或者父进程任何一方尝试对共享数据进行写入,那么操作系统会在物理内存上重新开辟一块新的内存空间,拷贝数据,然后在修改映射关系,不再指向老的变量,在整个修改的过程中,和父子进程的虚拟地址没有任何关系,只是底层经过页表映射到不同的区域,所以我们看到了地址是一样的,但是内容却是不一样的,这就是现象的由来!
写时拷贝
上述的任何一方尝试写入,操作系统先进行数据拷贝,更改页表映射,然后再让进程进行修改的技术称为写时拷贝
进程地址空间上的地址从全0到全1按照正常的方式排列,所以是连续的地址,所以这个地址空间也被称为线性地址;对于磁盘程序内部的地址称为逻辑地址,在Linux下,虚拟地址到线性地址、逻辑地址是一样的,但在其他地方,区分比较明确,
二、为什么
了解了进程地址空间是什么了以后,那为什么存在进程地址空间呢?
- 进程地址空间保证了数据的安全性
每个进程都有进程地址空间,所有的进程都要通过页表映射到物理内存,如果进程直接访问物理内存,万一进程越界非法访问、非法读写时,页表就可以进行拦截,而且直接访问物理内存对于账号信息是非常不安全的,所以保证了内存数据的安全性
- 地址空间的存在,可以更方便的进行进程和进程的数据代码的解耦,保证了进程独立性的特征
对于进程而言,都有独立的地址空间及页表,通过页表映射到不同的物理内存上,所以一个进程数据的改变不会影响到另一个进程,保证了进程的独立性,而对于上面我们所说的父进程和子进程而言,子进程的地址空间从父进程拷贝,页表都指向同一块物理内存,但是即使此时的数据是共享的,在修改数据的时候也会发生我们所说的写时拷贝,保证了进程的独立性
- 让进程以统一的视角,看待进程对应的代码和数据各个区域,方便编译器也以统一的视角来进行编译代码
可执行程序被编译器编译的时候每个代码和数据在内存中已经有虚拟地址了(在磁盘上称为逻辑地址),也就是说,地址空间对于操作系统和编译器都是遵守的。所以当程序被加载到内存成为进程后,每个变量/函数都具备了物理地址。
所以我们现在有两套地址:1.标识物理内存中代码和数据的地址2.在程序内部互相跳转的时候的虚拟地址
加载完成之后,代码的各个区域的地址已经知道。进程被调度时,CPU拿到虚拟地址,经过地址空间查页表通过映射,进行访问查到物理地址往后执行。也就是CPU通过了虚拟地址——页表映射——物理地址执行。也就是在整个CPU运行过程中,CPU并没有见到物理地址,用的都是虚拟地址。
另外,对于磁盘内可执行程序编译好,这个可执行程序的地址不叫虚拟地址,是逻辑地址。但是对于Linux而言,虚拟地址、线性地址、逻辑地址都是一样的。
三、怎么做
由操作系统管理进程地址空间。并且操作系统会为每个进程创建进程地址空间,但是对于操作系统来说,存在着比较多的进程,所以操作系统需要对进程地址空间进行管理。如何去管理?先描述,在组织。这是我们之前所说的。
进程本身是需要被管理的(通过先描述,在组织),所以操作系统会使用内核数据结构对地址空间进行管理,这个地址空间实际是内存的一种数据结构mm_struct,OS会为每个进程创建一个mm_struct对象,进行管理。
说了这么多,mm_struct是什么样子的,打开VScode,我们可以来看一看mm_struct的源代码:
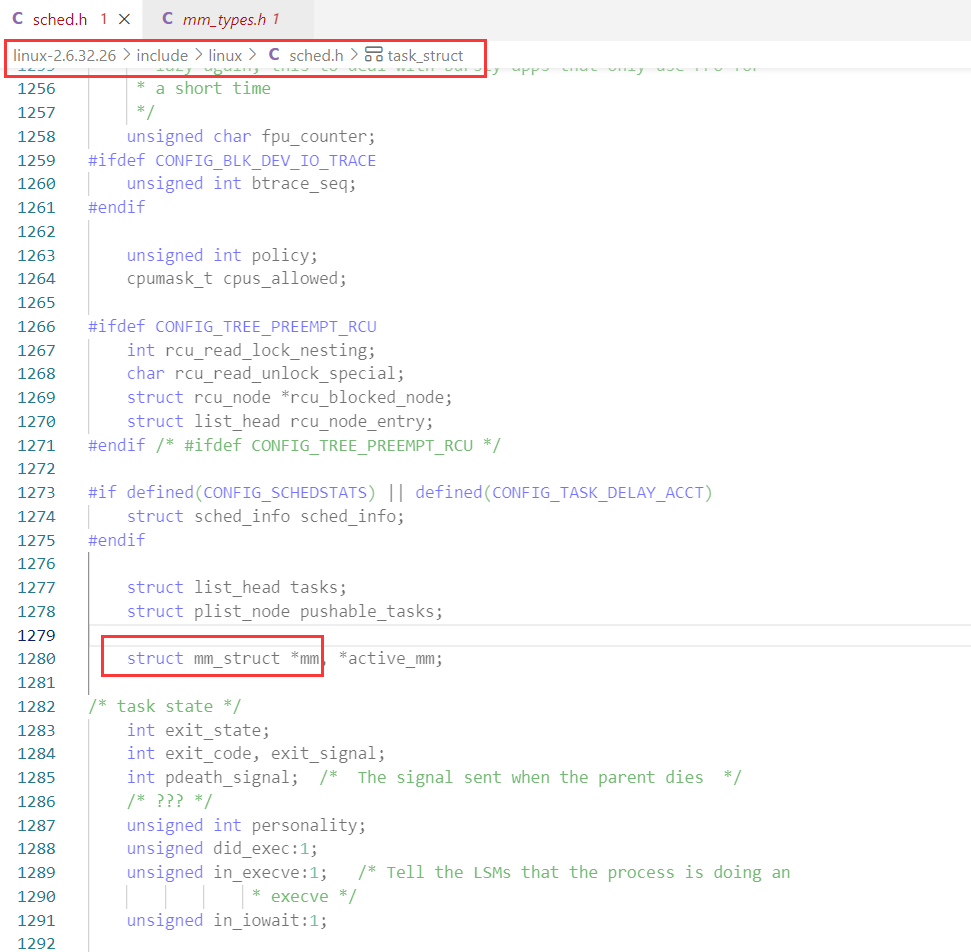
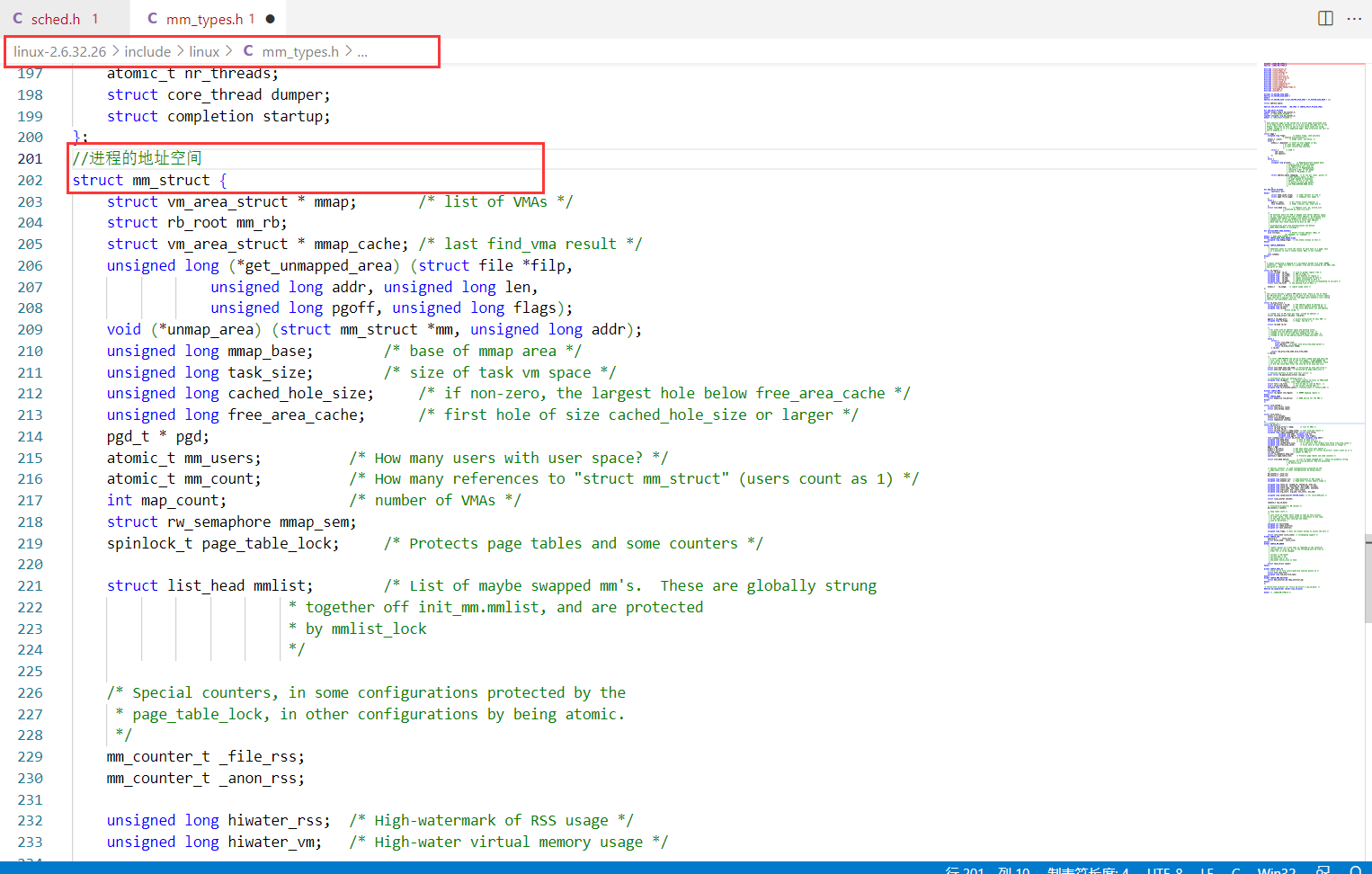
每个进程都有对应的task_struct,在其属性中有mm_struct,可以找到进程的地址空间。
区域划分和调整
地址空间有很多个区域,比如栈区、堆区、数据区、代码段,那进程地址空间是如何进行区域划分和区域调整的:把一个区域的end和start进行调整和维护内存区域
struct mm_struct{
uint32_t code_start,code_end;
uint32_t data_start,data_end;
uint32_t heap_start,heap_end;
uint32_t stack_start,stack_end;
}
所谓的区域调整,本质就是修改各个区域的end或start.
补充:
对于区域划分,进程地址空间的划分实际上是这个样子:
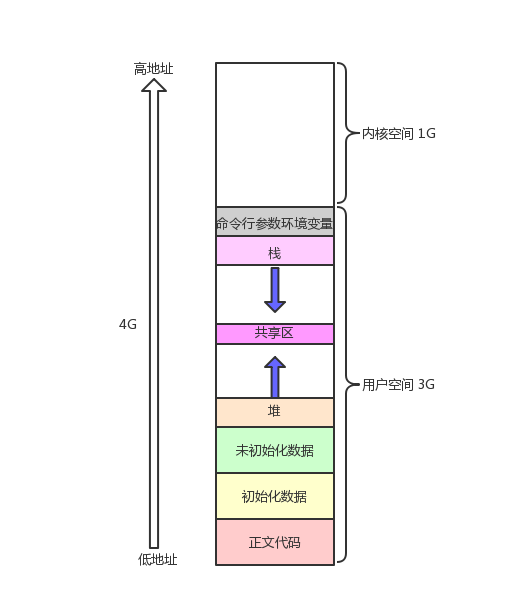
0-3G是用户空间,而命令行参数和环境变量是在用户空间的,这也是为什么我们可以在main()函数通过第三个参数env获取环境变量的原因。3-4G是内核空间。

- 点赞
- 收藏
- 关注作者
评论(0)