这次彻底搞懂Impala与Flink应用开发【玩转华为云】

本文主要内容有
- 一 MRS服务这个有啥用
- 二 先配置好各云服务
- 三 Impala实验搞起
- 四 再搞Flink实验测试下

一 😍 MRS服务这个有啥用
1.1 什么是MRS?
MRS是华为云大数据MapReduce服务,是一个在云上部署和管理Hadoop系统的整体服务,一键部署Hadoop集群

能供租户完全可控的一站式企业级大数据集群云服务,完全兼容开源接口,结合咱们华为云计算、存储优势及大数据行业深厚经验,目的给你高性能、低成本、灵活易用的全栈大数据平台。轻松运行Hadoop、Spark、Hbase、Kafka、Storm等大数据组件,并具备在后续根据业务需要进行定制开发的能力,帮助企业快速构建海量数据信息处理系统,并通过对海量信息数据实时与非实时的分析挖掘,发现全新价值点和企业商机;

1.2 服务的功能怎么样?
1.2.1 趋势是什么
现代企业的数据集群在向集中化和云化方向发展,那么企业级大数据集群需要满足
- 不同用户在集群上运行不同类型的应用和作业(分析、查询、流处理等),同时存放不同类型和格式的数据;
- 某些类型的用户(例如银行、政府单位等)对数据安全非常关注,很难容忍将自己的数据与其他用户放在一起。
这给大数据集群带来了以下挑战:
- 合理地分配和调度资源,以支持多种应用和作业在集群上平稳运行
- 对不同的用户进行严格的访问控制,以保证数据和业务的安全
多租户把大数据集群的资源隔离成一个个资源集合,让它们彼此互不干扰,用户通过“租用”需要的资源集合,来运行应用和作业,并存放数据。在大数据集群上可以存在多个资源集合来支持多个用户的不同业务需求;所以呢,集群提供了完整的企业级大数据多租户解决方案,多租户是MRS大数据集群中的多个资源集合(每个资源集合就是一个租户),具有分配和调度资源(资源包括计算资源和存储资源)能力;
1.2.2 特性是啥
调度器增强
多租户根据调度器类型分为开源的Capacity调度器和华为自主研发的增强型Superior调度器。
为满足企业需求,克服Yarn社区在调度上遇到的挑战与困难,华为自主研发的Superior调度器,不仅集合了当前Capacity调度器与Fair调度器的优点,还做了以下增强:
- 增强资源共享策略
Superior调度器支持队列层级,在同集群集成开源调度器的特性,并基于可配置策略进一步共享资源。针对实例,MRS集群管理员可通过Superior调度器为队列同时配置绝对值或百分比的资源策略计划。Superior调度器的资源共享策略将YARN的标签调度增强为资源池特性,YARN集群中的节点可根据容量或业务类型不同,进行分组以使队列更有效地利用资源。
- 基于租户的资源预留策略
部分租户可能在某些时间中运行关键任务,租户所需的资源应保证可用。Superior调度器构建了支持资源预留策略的机制,在这些租户队列运行的任务可立即获取到预留资源,以保证计划的关键任务可正常执行。
- 租户和资源池的用户公平共享
Superior调度器提供了队列内用户间共享资源的配置能力。每个租户中可能存在不同权重的用户,高权重用户可能需要更多共享资源。
- 大集群环境下的调度性能优势
Superior调度器接收到各个NodeManager上报的心跳信息,并将资源信息保存在内存中,使得调度器能够全局掌控集群的资源使用情况。Superior调度器采用了push调度模型,令调度更加精确、高效,大大提高了大集群下的资源使用率。另外,Superior调度器在NodeManager心跳间隔较大的情况下,调度性能依然优异,不牺牲调度性能,也能避免大集群环境下的“心跳风暴”。
- 优先策略
1.3 可以覆盖哪些场景
1.3.1 海量数据分析场景
海量数据分析是现代大数据系统中的主要场景。通常企业会包含多种数据源,接入后需要对数据进行ETL(Extract-Transform-Load)处理形成模型化数据,以便提供给各个业务模块进行分析梳理,这类业务通常有以下特点:
- 对执行实时性要求不高,作业执行时间在数十分钟到小时级别。
- 数据量巨大。
- 数据来源和格式多种多样。
- 数据处理通常由多个任务构成,对资源需要进行详细规划。
例如在环保行业中,可以将天气数据存储在OBS,定期转储到HDFS中进行批量分析,在1小时内MRS可以完成10TB的天气数据分析

该场景下MRS的优势如下
- 低成本:利用OBS实现低成本存储
- 海量数据分析:利用Hive实现TB/PB级的数据分析
- 可视化的导入导出工具:通过可视化导入导出工具Loader,将数据导出到DWS,完成BI分析
1.3.2 海量数据存储场景
用户拥有大量结构化数据后,通常要提供基于索引的准实时查询能力,如车联网场景下,根据汽车编号查汽车维护信息,存储时,汽车信息会基于汽车编号进行索引,这样来实现该场景下的秒级响应,通常这类数据量比较庞大,用户可能保存1至3年的数据;
例如在车联网行业,某车企将数据储存在HBase中,以支持PB级别的数据存储和毫秒级的数据详单查询

该场景下MRS的优势如下
- 实时:利用Kafka实现海量汽车的消息实时接入
- 海量数据存储:利用HBase实现海量数据存储,并实现毫秒级数据查询
- 分布式数据查询:利用Spark实现海量数据的分析查询
1.3.3 实时数据处理场景
实时数据处理通常用于异常检测、欺诈识别、并基于规则告警、业务流程监控等场景,在数据输入系统的过程中,详细对数据进行处理;
例如在梯联网行业,智能电梯的数据,实时传入到MRS的流式集群中进行实时告警

该场景下MRS的优势如下
- 实时数据采集:利用Flume实现实时数据采集,并提供丰富的采集和存储连接方式。
- 海量的数据源接入:利用Kafka实现万级别的电梯数据的实时接入。
1.4 优势具体有哪些
MRS服务拥有强大的Hadoop内核团队,基于华为FusionInsight大数据企业级平台构筑,历经行业数万节点部署量的考验,提供多级用户SLA保障
MRS具有如下优势:
- 高性能
MRS支持自研的CarbonData存储技术。CarbonData是一种高性能大数据存储方案,以一份数据同时支持多种应用场景,并通过多级索引、字典编码、预聚合、动态Partition、准实时数据查询等特性提升了IO扫描和计算性能,实现万亿数据分析秒级响应。同时MRS支持自研增强型调度器Superior,突破单集群规模瓶颈,单集群调度能力超10000节点。
- 低成本
基于多样化的云基础设施,提供了丰富的计算、存储设施的选择,同时计算存储分离,提供了低成本海量数据存储方案。MRS可以按业务峰谷,自动弹性伸缩,帮助客户节省大数据平台闲时资源。MRS集群可以用时再创建、用时再扩容,用完就可以销毁、缩容,确保成本最优。
- 高安全
MRS服务拥有企业级的大数据多租户权限管理能力,拥有企业级的大数据安全管理特性,支持按照表/按列控制访问权限,支持数据按照表/按列加密。
- 易运维
MRS提供可视化大数据集群管理平台,提高运维效率。并支持滚动补丁升级,可视化补丁发布信息,一键式补丁安装,无需人工干预,不停业务,保障用户集群长期稳定。
- 高可靠
MRS服务经过大规模的可靠性、长稳验证,满足企业级高可靠要求,同时支持数据跨AZ/跨Region自动备份的数据容灾能力,自动反亲和技术,虚拟机分布在不同物理机上
二 🎯 先配置好各云服务
2.1 买MRS集群
点华为云官网左上角的图标回到首页,点击“产品->大数据->MapReduce服务”进入MRS服务控制台,如下
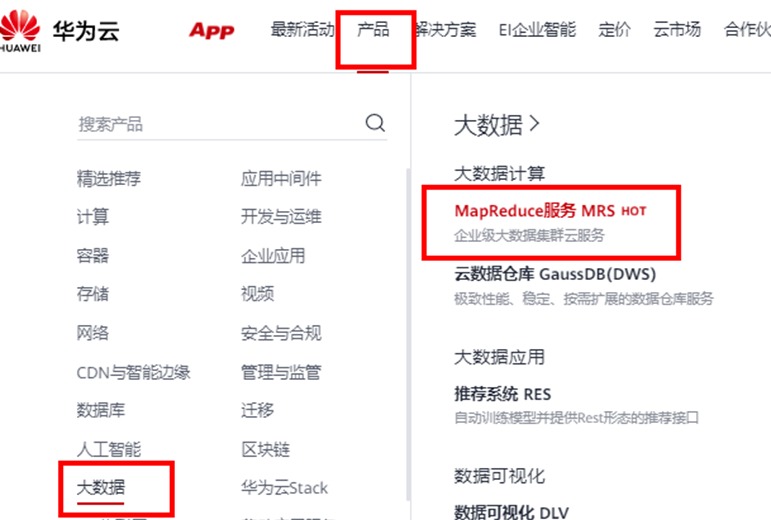
点击“立即购买”

选“自定义购买”
区域:华北-北京四
集群名称:mrs
版本类型:普通版
集群版本:MRS 3.1.0 WXL
集群类型:自定义
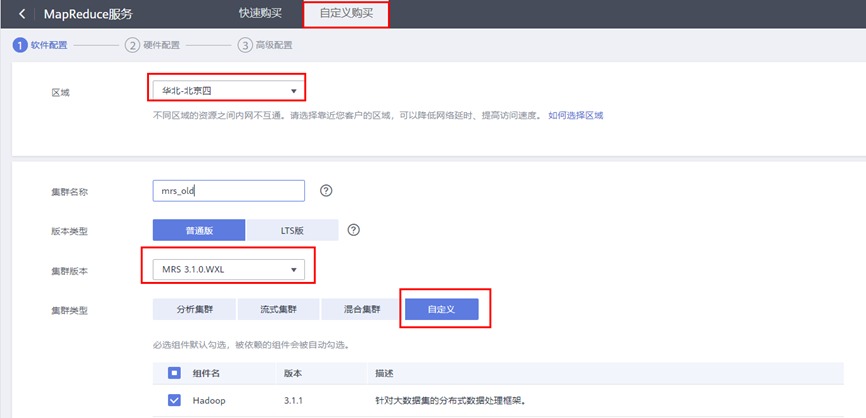
勾选组件:Hadoop/Impala/Kafka/Flink/Zookeeper/Ranger
元数据:本地元数据

说明:如果希望把Hive元数据存放在MySQL中,可以选择配置数据连接
确认无误后点击“下一步”
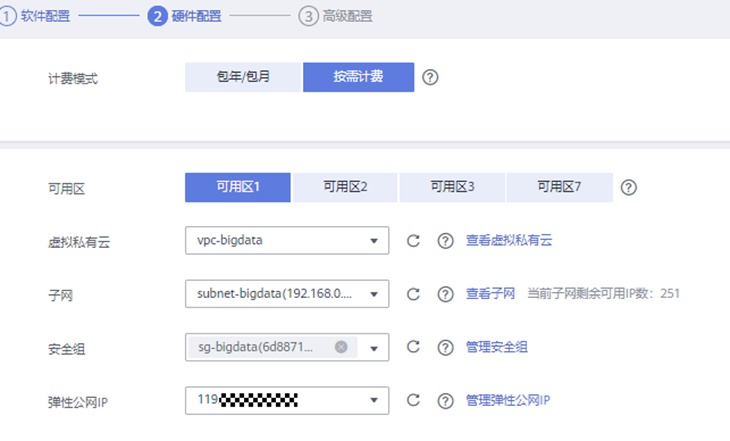
接下来配置硬件
计费模式:按需计费
可用区:任意均可
虚拟私有云:vpc-bigdata
子网:subnet-bigdata
安全组:sg-bigdata
弹性公网IP:选择下拉框中的任意IP即可
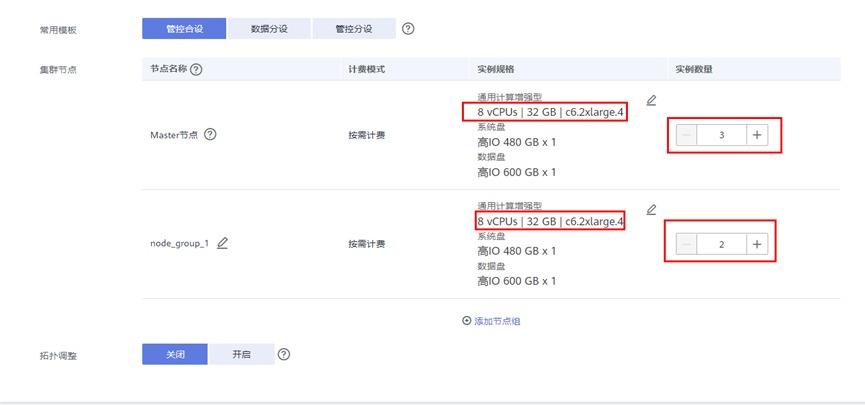
集群节点
实例规格:全部选择通用计算增强型
8 vCPUs |32 GB | c6.2xlarge.4
系统盘:高IO 480 GB x 1
数据盘:高IO 600 GB x 1
实例数量:Master节点3台
分析Core节点:2台
无需添加分析Task节点
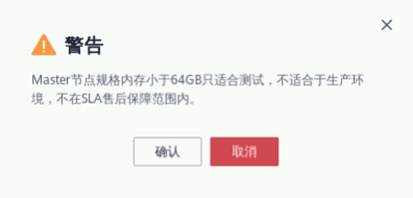
注意1:当实例规格选为“8 vCPUs |32 GB | c6.2xlarge.4”时,可能会出现如下警告。由于本次实验仅用于学习测试,不受影响,点击确认即可
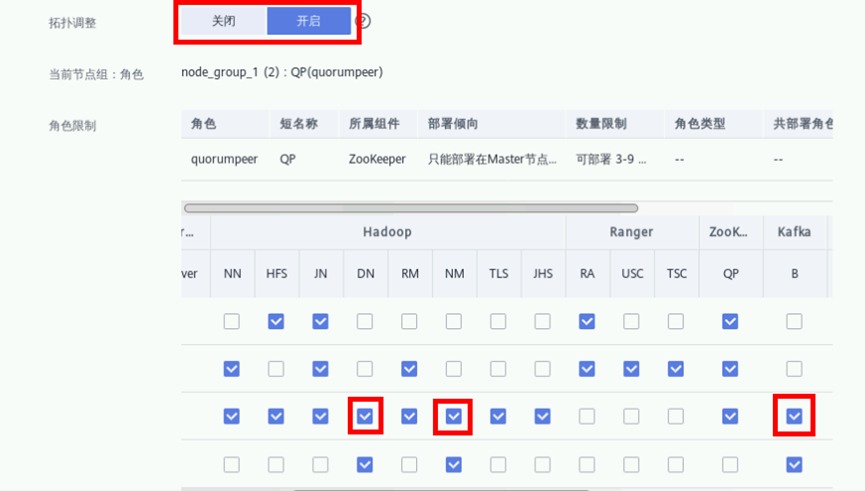
注意2:当node_group_1节点实例数量改为2后,可能会出现如下警告。暂时无需理会,后续步骤会解决

开启“拓扑调整”,勾选如下图位置所示的“DN, NM, B”。此操作表示在Master3节点分别部署DataNode, NodeManager, Broker以解决如上警告
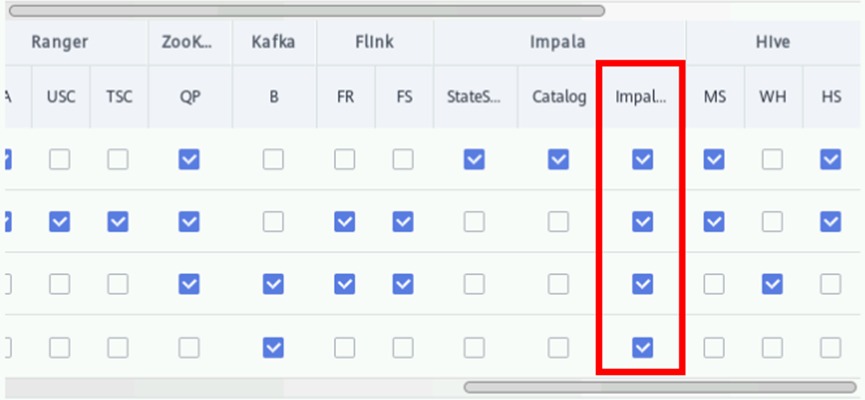
勾选所有节点上的Impalad服务
确认无误后点击“下一步”
接下来进行高级配置
标签,主机名前缀,弹性伸缩,引导操作均无需配置
委托:暂不绑定
告警:关闭
日志记录:关闭

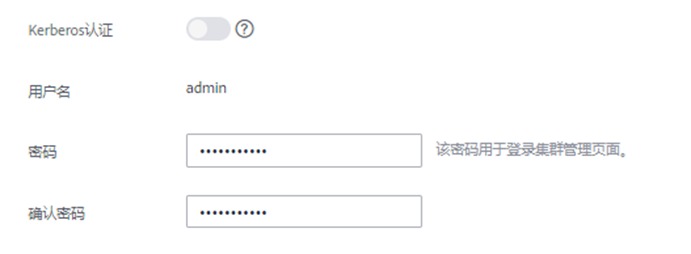
Kerberos认证:保持关闭状态
用户名:admin
密码:自定义密码,例如HWcloud@user0
确认密码:再次输入
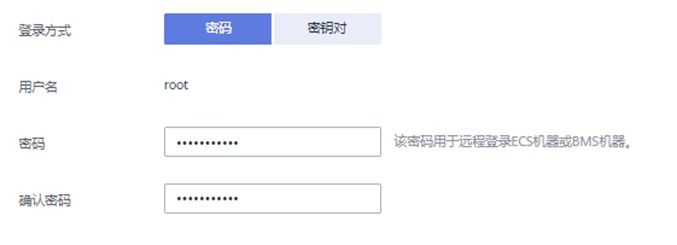
登录方式:密码
用户名:root
密码:自定义密码,例如HWcloud@user0
确认密码:再次输入
通信安全授权:勾选“确认授权”

确认无误后点击“立即购买->返回集群列表”
集群创建共计约等待【35分钟】(等待)。可在集群列表中查看到两台MRS集群的购买“状态”由“启动中”更新为“运行中”即可正常使用

点击集群名字,即可进入详情页面。其中弹性公网IP即为外部访问IP
添加安全组规则,默认情况下华为云外部无法直接连接集群,我们需要放开安全组限制
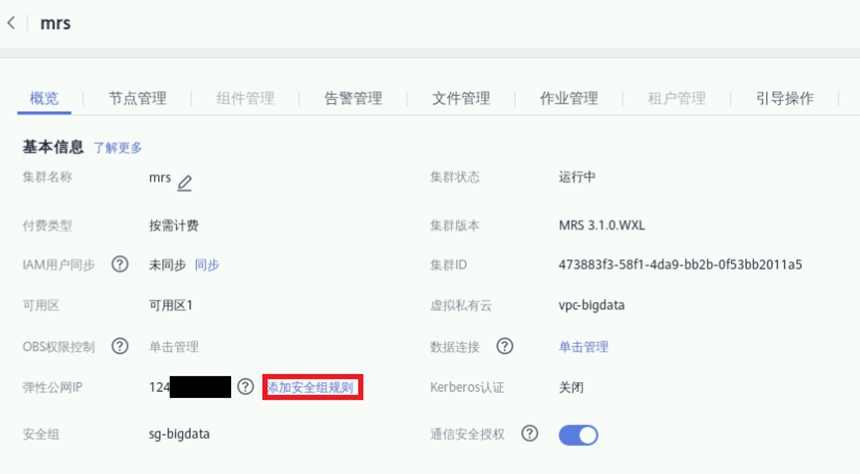
点击“管理安全组规则”
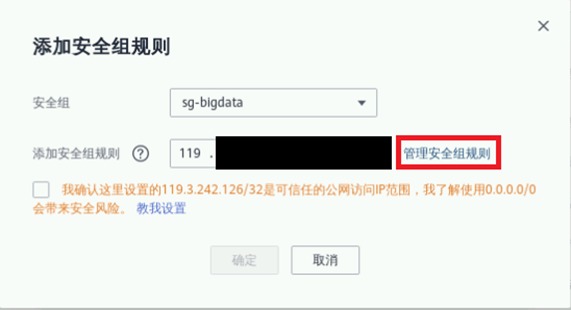
点击“入方向规则->添加规则”
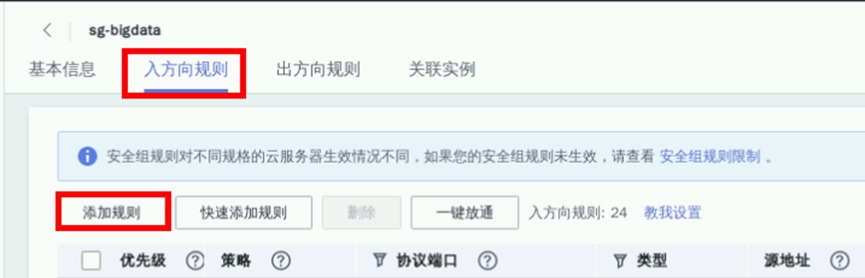
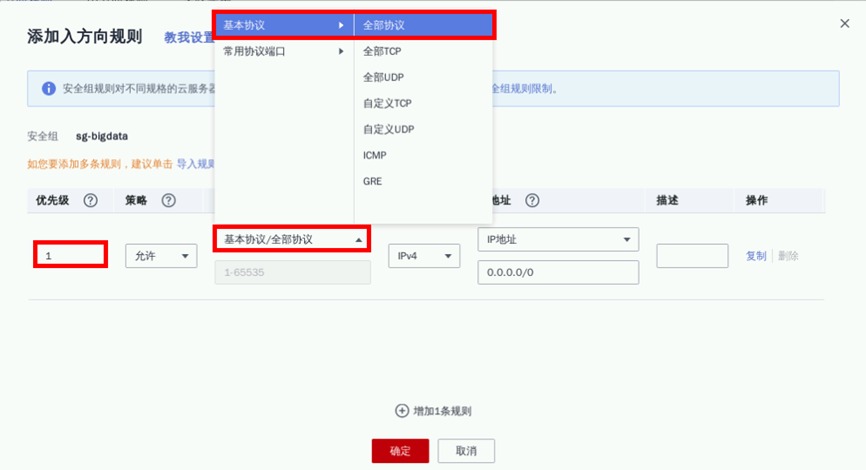
点击“基本协议/全部协议”,实际项目中要根据访问最小化原则放通入方向,并设置优先级。本实验为方便使用,可放通全部入方向规则,并设置优先级为1。点击“确定”
2.2 链接MRS集群
打开实验桌面的“Xfce终端”,用ssh命令连接集群,弹性公网IP见集群详情页那,连接成功后可显示“root@node-master...”信息
ssh root@xxx.xxx.xxx.xxx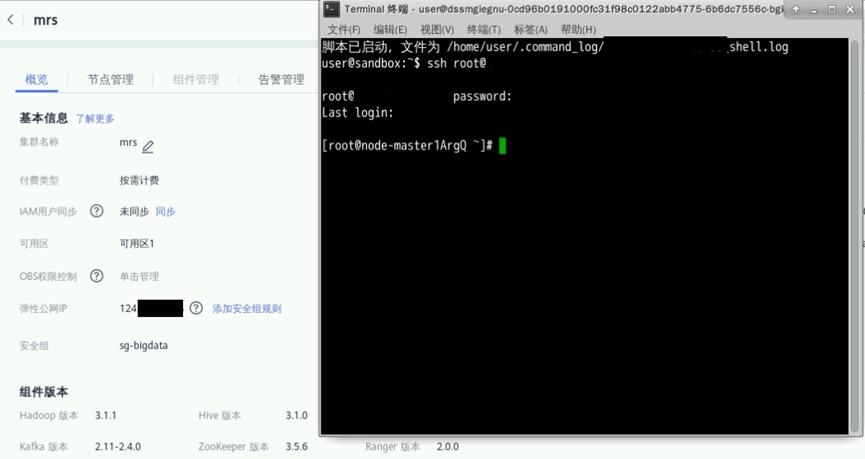
三 🚀 Impala实验搞起
Impala是用于处理存储在Hadoop集群中的大量数据的MPP(大规模并行处理)SQL查询引擎。 它是一个用C++和Java编写的开源软件。 与其他Hadoop的SQL引擎相比,它拥有高性能和低延迟的特点
3.1 背景信息
假定用户开发一个应用程序,用于管理企业中的使用A业务的用户信息,使用Impala客户端实现A业务操作流程如下:
普通表的操作:
1.创建用户信息表user_info。
2.在用户信息中新增用户的学历、职称信息。
3.根据用户编号查询用户姓名和地址。
4.A业务结束后,删除用户信息表
3.2 安装Impala客户端
在MRS集群详情页面,点击“前往Manager”
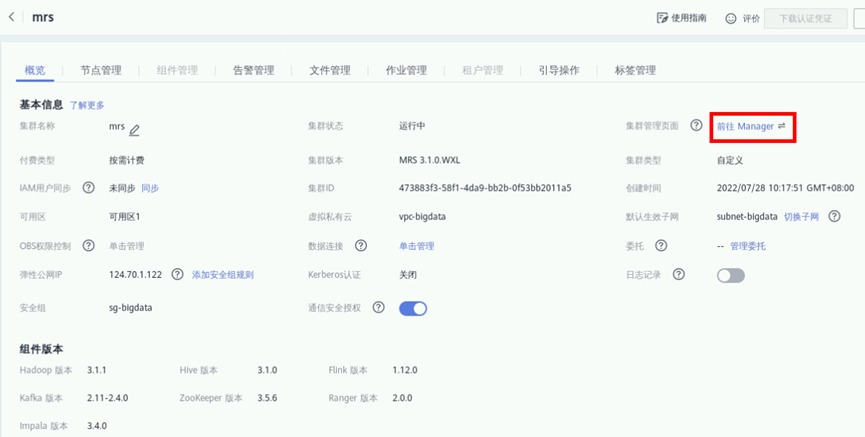
点击“确定”
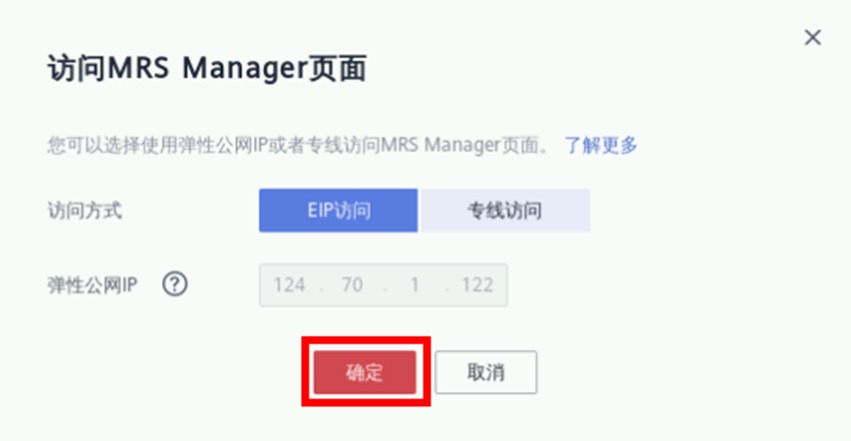
首次使用MRS Manager会显示如下页面,先后点击“高级->添加例外->确认安全例外”即可
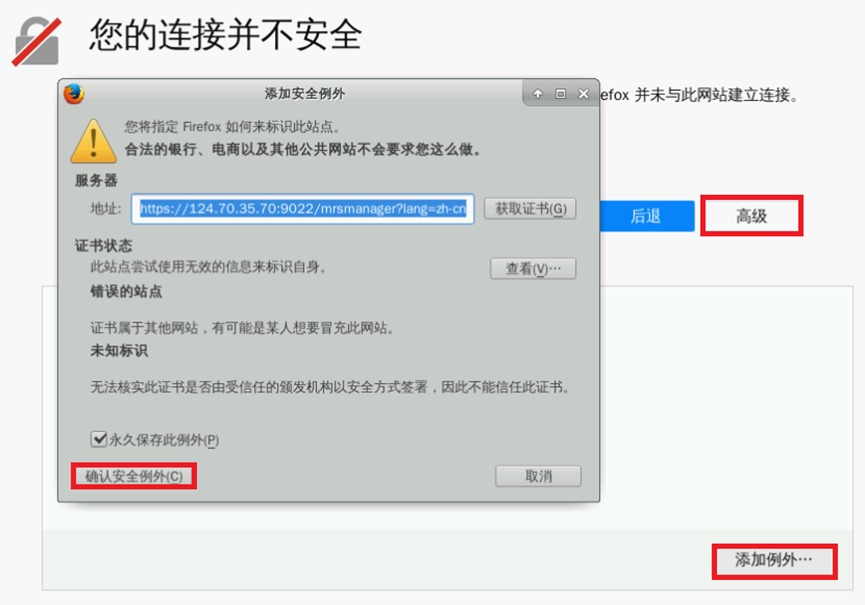
输入账号admin及集群创建时所对应的密码(例如HWcloud@user0)后登陆
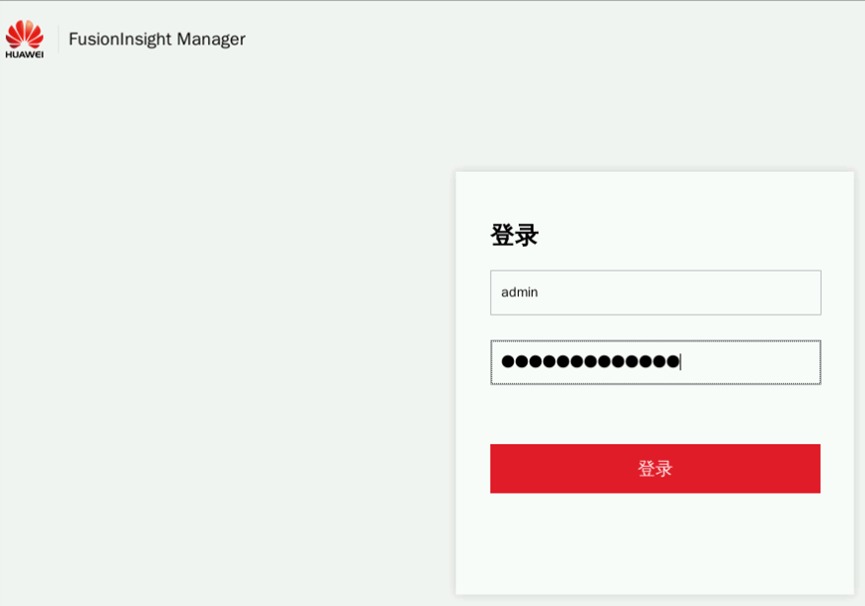
点击左侧大数据服务列表中的Impala,进入Impala详情页面
点击“更多->下载客户端”
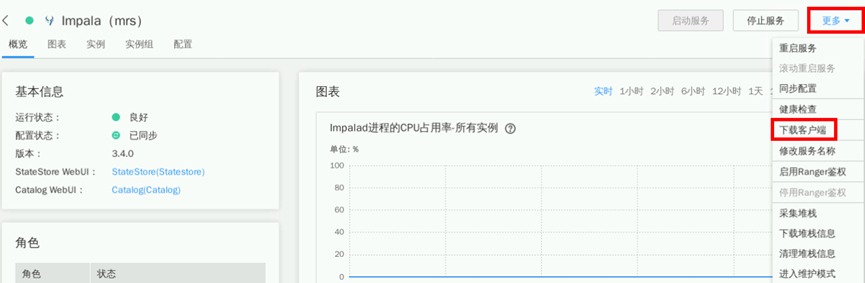
点击“x86_64->仅保存到如下路径->确定”,Impala客户端将会下载到集群主节点(即公网IP所对应服务器)的/tmp/FusionInsight-Client目录。下载时长约1分钟
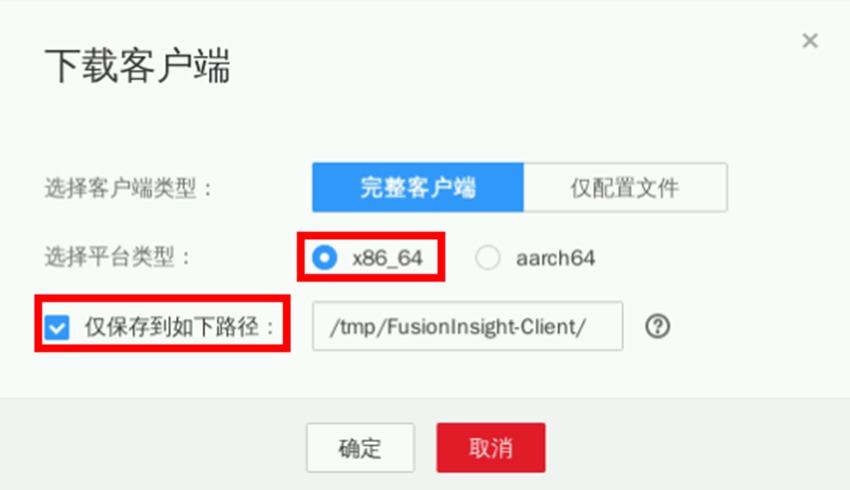
打开实验桌面的“Xfce终端”,使用ssh命令连接集群。弹性公网IP见集群详情页。连接成功后可显示“root@node-master...”信息
ssh root@xxx.xxx.xxx.xxx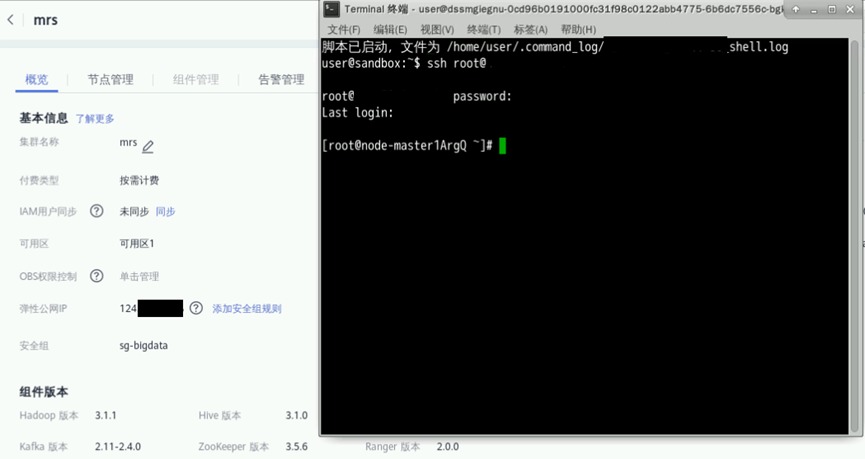
进入Impala客户端下载目录并解压
cd /tmp/FusionInsight-Client/
tar -vxf FusionInsight_Cluster_1_Impala_Client.tar
tar -vxf FusionInsight_Cluster_1_Impala_ClientConfig.tar安装Impala客户端至/opt/client目录
cd /tmp/FusionInsight-Client/FusionInsight_Cluster_1_Impala_ClientConfig
./install.sh /opt/client安装成功后将显示如下信息
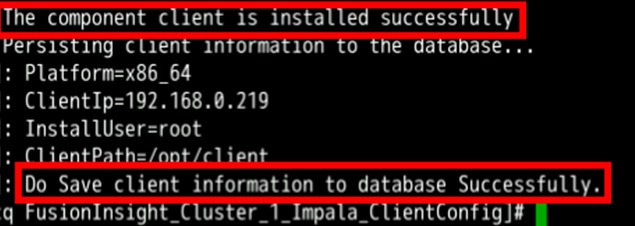
切换到Impala安装目录并启动
cd /opt/client
source bigdata_env
impala-shell启动成功将会显示如下界面
退出Impala环境
quit;3.3 创建用户信息数据
创建用户信息表user_info
vi user_info按键盘“i”键进入编辑模式,输入用户信息如下
12005000201 A 男 19 A城市
12005000202 B 女 23 B城市
12005000203 C 男 26 C城市
12005000204 D 男 18 D城市
12005000205 E 女 21 E城市
12005000206 F 男 32 F城市
12005000207 G 女 29 G城市
12005000208 H 女 30 H城市
12005000209 I 男 26 I城市
12005000210 J 女 25 J城市按ECS键退出编辑模式。输入“:wq” 然后回车保存并退出user_info
:wq3.4登录Impala客户端
运行Impala客户端命令
impala-shell3.5 内部表的操作
创建用户信息表user_info并添加相关数据
create table user_info(id string,name string,gender string,age int,addr string);
insert into table user_info(id,name,gender,age,addr) values ("12005000201","A","男",19,"A城市");在用户信息表user_info中新增用户的学历、职称信息
alter table user_info add columns(education string,technical string);根据用户编号查询用户姓名和地址
select name,addr from user_info where id='12005000201';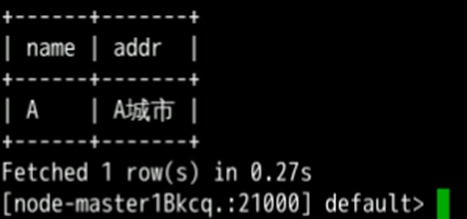
删除用户信息表
drop table user_info;3.6 外部表的操作
创建外部表
create external table user_info(id string,name string,gender string,age int,addr string) partitioned by(year string) row format delimited fields terminated by ' ' lines terminated by '\n' stored as textfile location '/hive/user_info';使用insert语句插入数据
insert into user_info partition(year="2018") values ("12005000201","A","男",19,"A城市");执行以下SQL语句,查看数据插入成功
select * from user_info;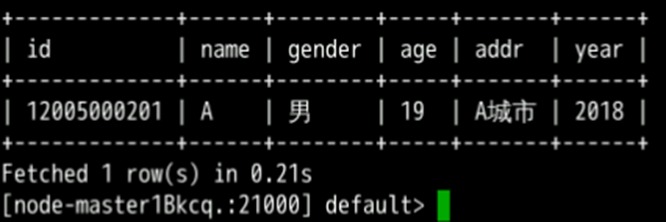
退出Impala环境
quit;3.6.1使用load data命令导入文件数据
上传文件至hdfs
hdfs dfs -put user_info /tmp进入Impala环境
impala-shell加载数据到表中
load data inpath '/tmp/user_info' into table user_info partition (year='2018');查询导入数据
select * from user_info;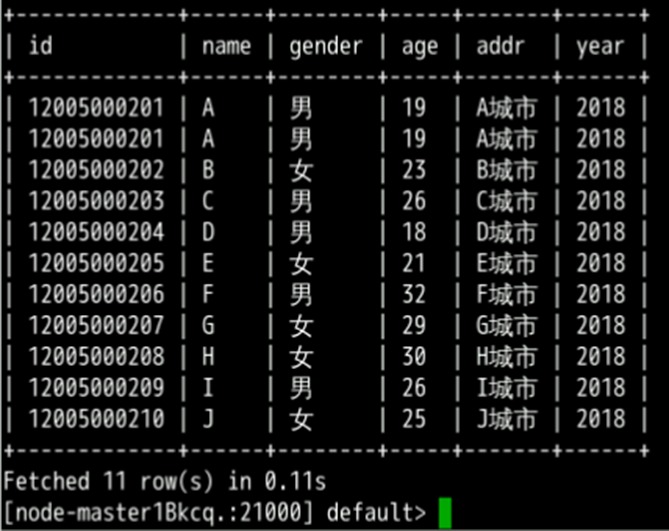
删除用户信息表
drop table user_info;四 😘 再搞Flink实验测试下
Flink是一个批处理和流处理结合的统一计算框架,其核心是一个提供了数据分发以及并行化计算的流数据处理引擎。它的最大亮点是流处理,是业界最顶级的开源流处理引擎。
Flink最适合的应用场景是低时延的数据处理(Data Processing)场景:高并发pipeline处理数据,时延毫秒级,且兼具可靠性
4.1场景介绍
假定某个Flink业务每秒就会收到1个消息记录。基于某些业务要求,开发的Flink应用程序实现功能:实时输出带有前缀的消息内容
4.2安装JDK环境
运行下列代码下载jdk1.8压缩文件
wget https://hcip-materials.obs.cn-north-4.myhuaweicloud.com/jdk-8u341-linux-x64.tar.gz下载完成后,运行下列命令进行解压:
tar -zxvf jdk-8u341-linux-x64.tar.gz解压成功后即可,无需修改启动配置文件
4.3 新建Flink Maven工程
打开实验桌面的eclipse,点击“File->New->Project”
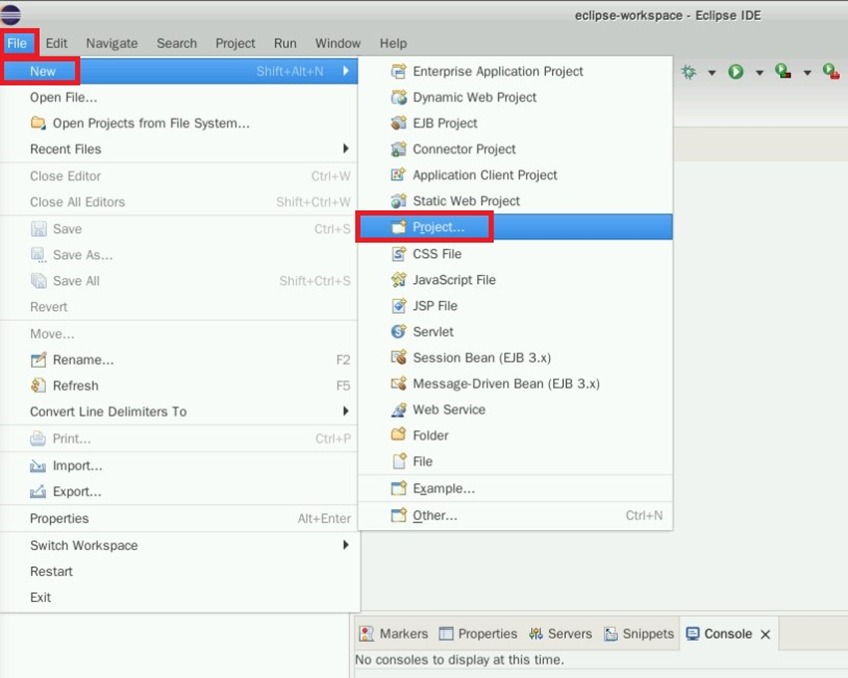
选择“Maven Project”,点击“Next”
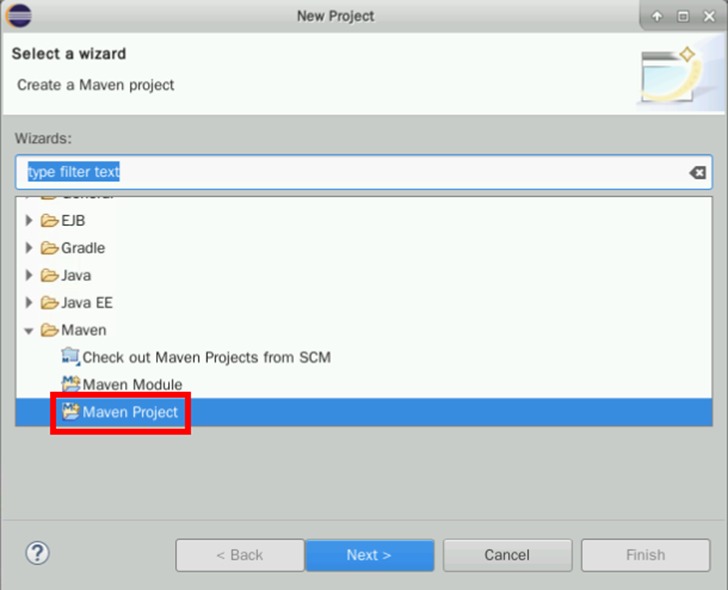
勾选“Create a simple project…”,点击“Next”
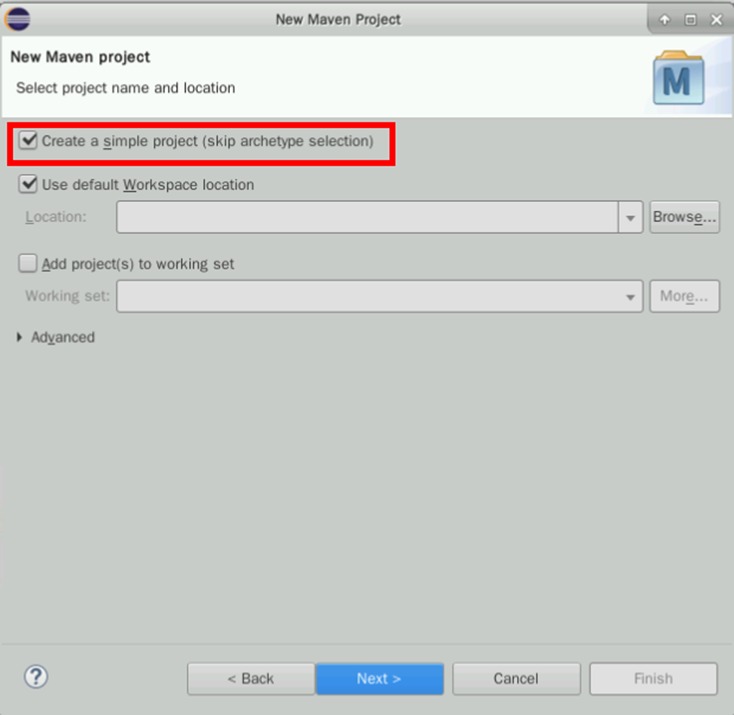
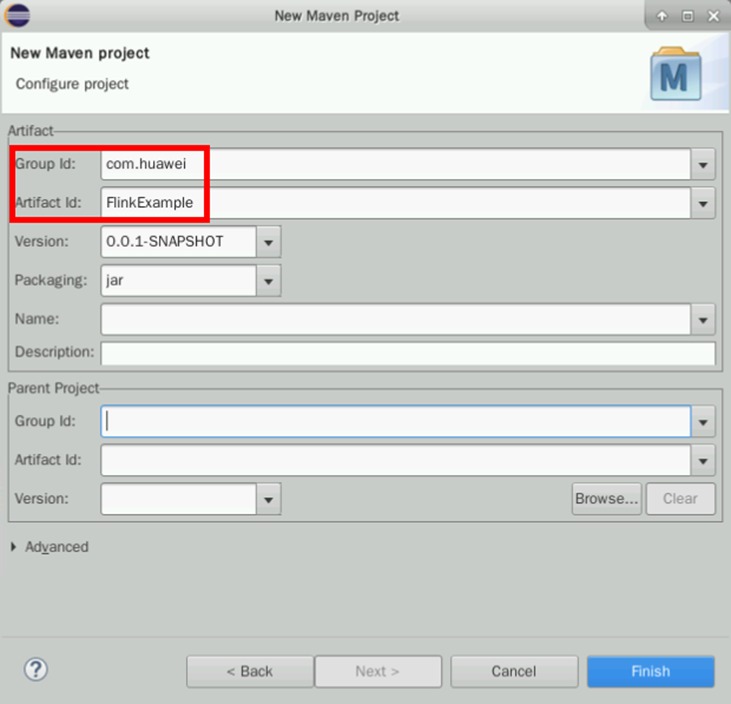
输入:
Group Id: com.huawei
Artifact Id: FlinkExample
点击“Finish”
4.4修改JDK路径
右上角选择Window标签,在下拉菜单最后一栏中找到Preferences
点击Preferences,在新窗口的左侧找到Java->Compiler
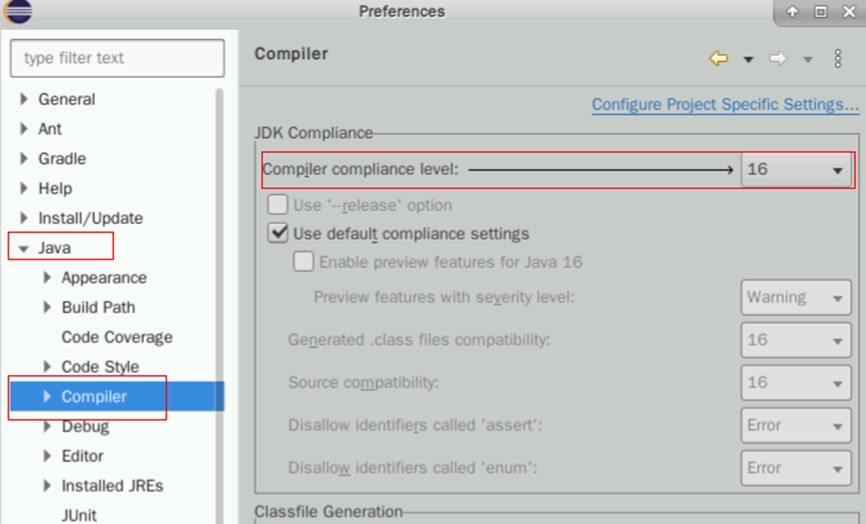
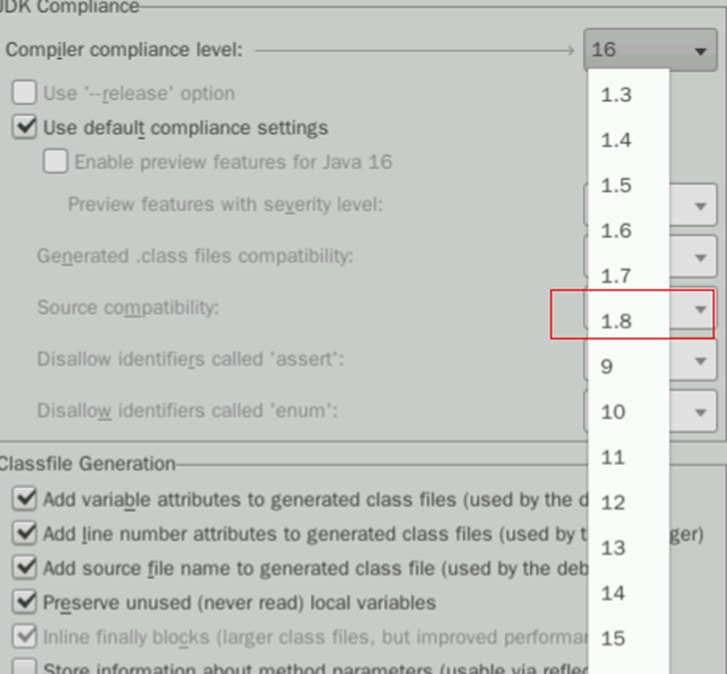
右侧找到Compiler Compliance level 16,点击16的下拉菜单,在列表中找到1.8,选择1.8即可
确认改为1.8之后,点击Apply and Close
然后在下方还能找到Installed JREs标签,点击Add按钮进行配置
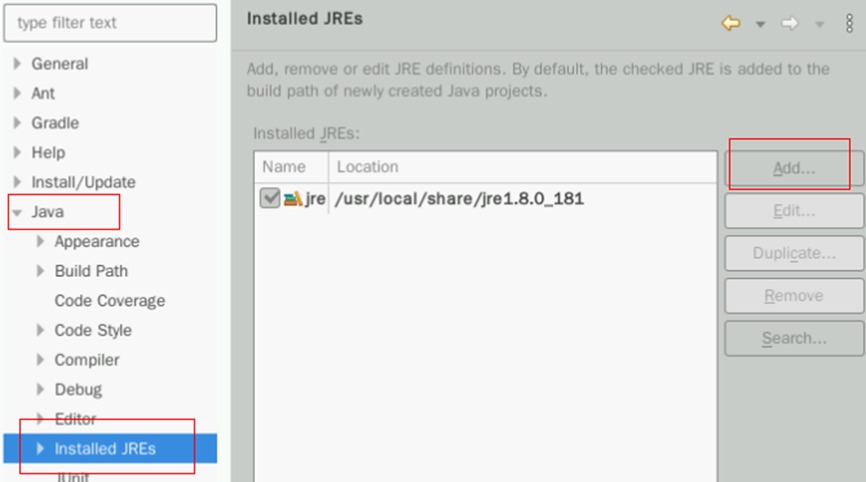
在弹出的新窗口处选择Standard VM,然后点击Next
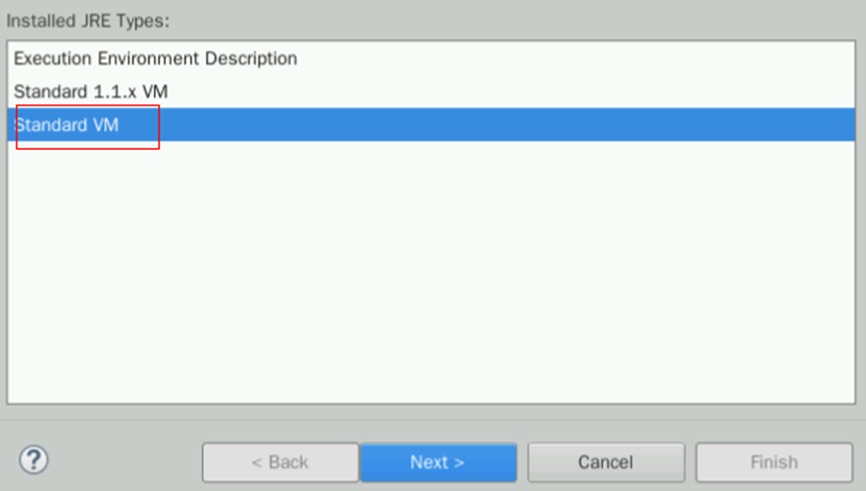
在JRE home处填入/home/user/jdk1.8.0_341,即可自动匹配关联下方信息
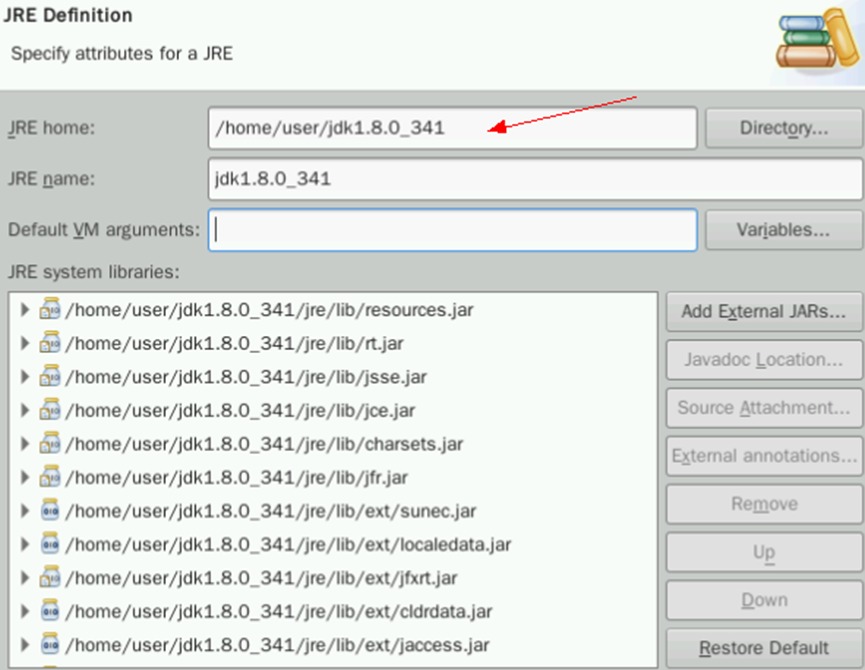
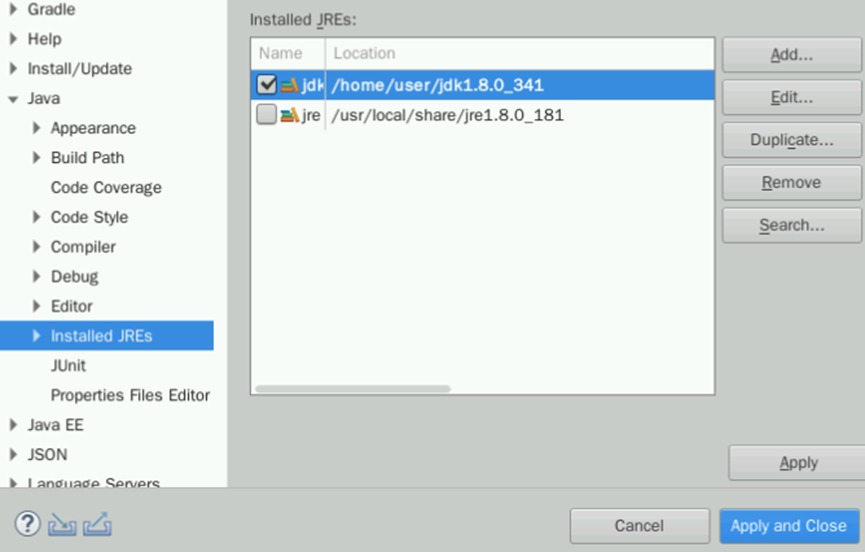
确认无误后点击Finish,然后勾选新增的jdk前的框。点击Apply and Close
回到初始界面,看到项目名称下有一个类似JRE System Library [J2SE-1.5]的标签
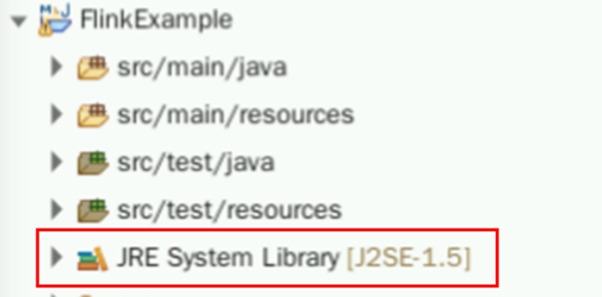
右键点击该标签,选择Build Path->Configure Build Path
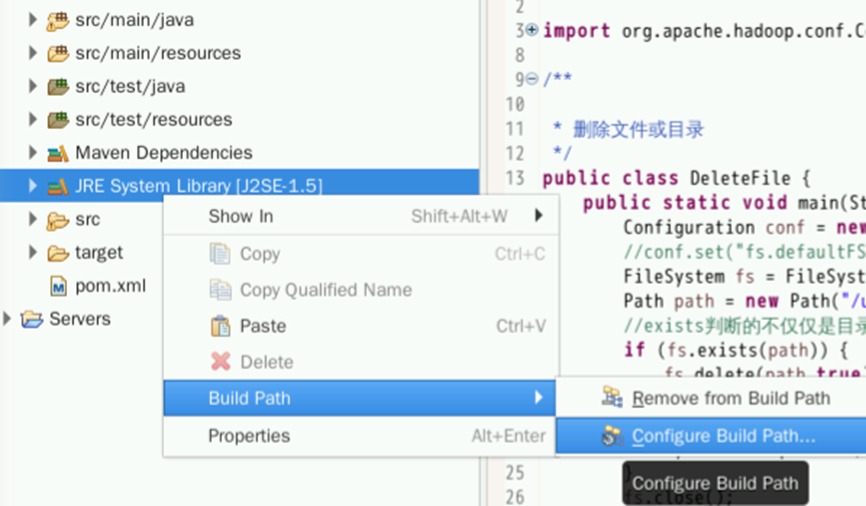
在新窗口点击Add Library
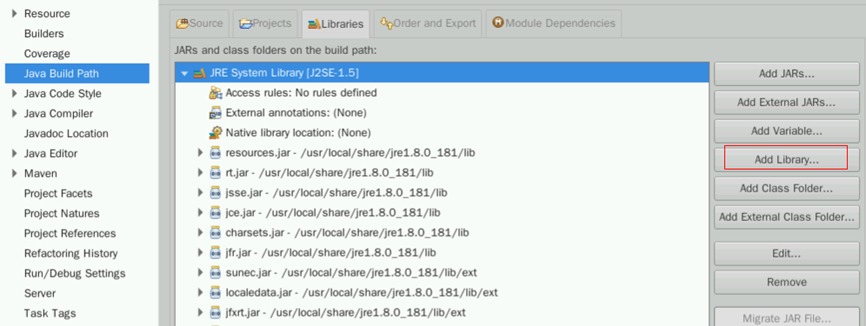
选择JRE System Library,点击Next
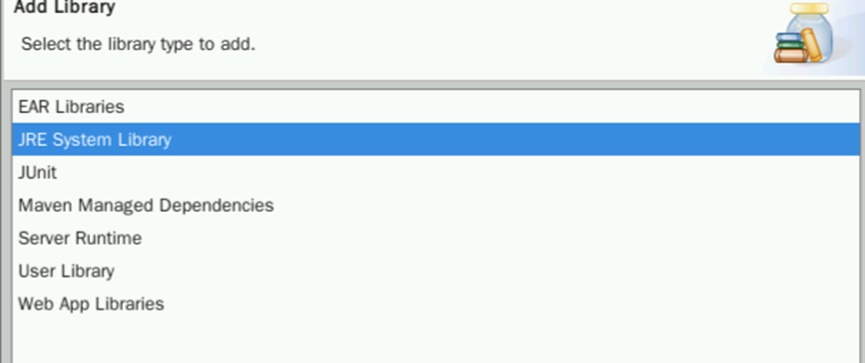
此时应该能看到Workspace default JRE (jdk1.8.0_341),保证勾选后点击Finish
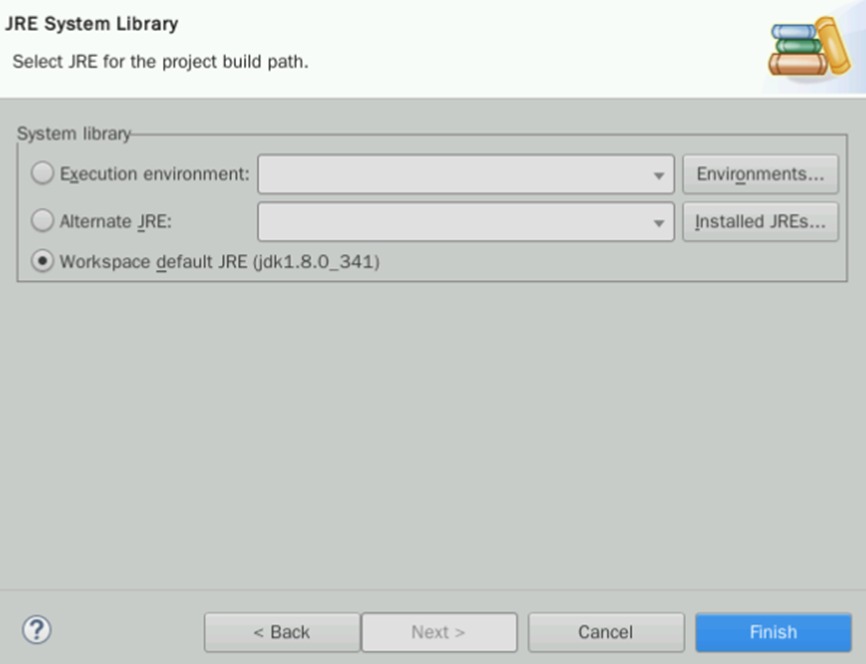
将之前的J2SE-1.5直接删除。选择该模块,在右边找到Remove
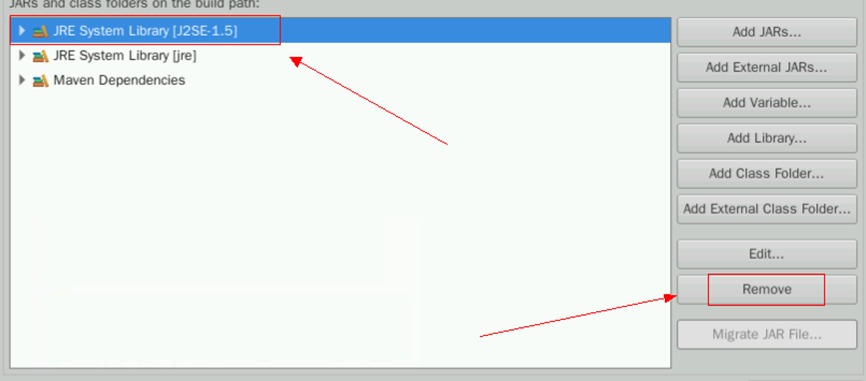
删除之后,点击右下角的Apply And Close即可
4.5配置POM文件
打开“FlinkExample->pom.xml”文件
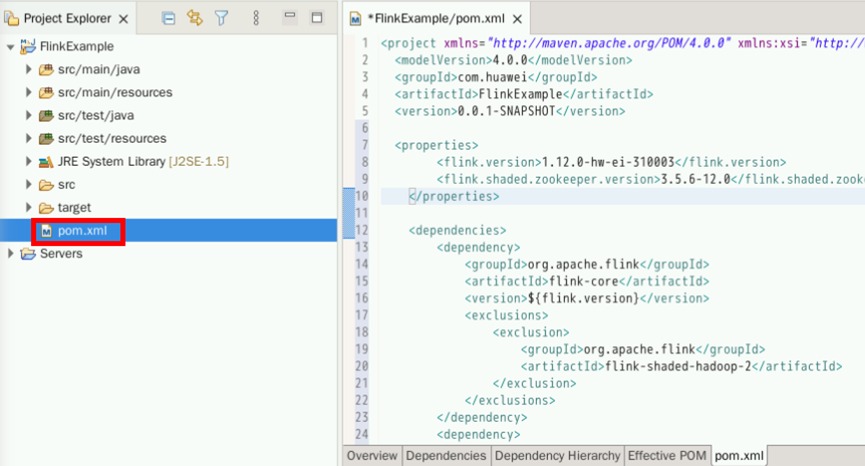
将pom.xml文件内容替换如下
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.huawei</groupId>
<artifactId>FlinkExample</artifactId>
<version>0.0.1-SNAPSHOT</version>
<properties>
<flink.version>1.12.0-hw-ei-310003</flink.version>
<flink.shaded.zookeeper.version>3.5.6-12.0</flink.shaded.zookeeper.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-core</artifactId>
<version>${flink.version}</version>
<exclusions>
<exclusion>
<groupId>org.apache.flink</groupId>
<artifactId>flink-shaded-hadoop-2</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
<exclusions>
<exclusion>
<groupId>org.apache.flink</groupId>
<artifactId>flink-shaded-hadoop-2</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>${flink.version}</version>
<exclusions>
<exclusion>
<groupId>org.apache.flink</groupId>
<artifactId>flink-shaded-hadoop-2</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-shaded-zookeeper-3</artifactId>
<version>${flink.shaded.zookeeper.version}</version>
</dependency>
</dependencies>
<repositories>
<repository>
<id>huaweicloud2</id>
<name>huaweicloud2</name>
<url>https://mirrors.huaweicloud.com/repository/maven/</url>
</repository>
<repository>
<id>huaweicloud1</id>
<name>huaweicloud1</name>
<url>https://repo.huaweicloud.com/repository/maven/huaweicloudsdk/</url>
</repository>
</repositories>
<build>
<plugins>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>assembly</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>关闭pom.xml,下载第三方依赖程序包需要一定时间,预计约需5分钟左右
4.6 开发程序
4.6.1 创建程序包
在“src/main/java”处右键“new->package”
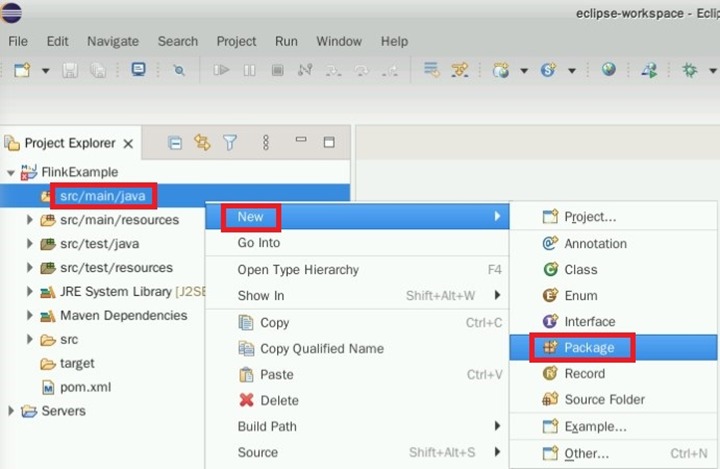
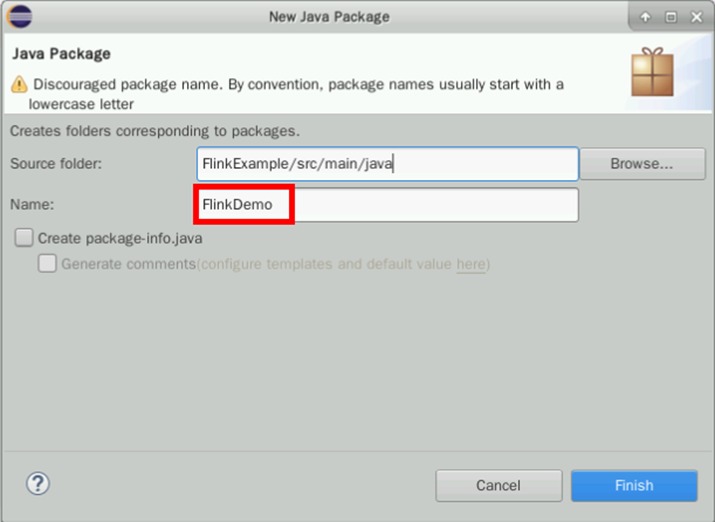
创建包FlinkDemo,点击“Finish”
4.6.2 创建类WriteIntoKafka
在上步FlinkDemo处右键点击,选择“New->Class”创建Java类WriteIntoKafka
package FlinkDemo;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import org.apache.flink.streaming.util.serialization.SimpleStringSchema;
public class WriteIntoKafka {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
ParameterTool paraTool = ParameterTool.fromArgs(args);
DataStream<String> messageStream = env.addSource(new SimpleStringGenerator());
messageStream.addSink(
new FlinkKafkaProducer<String>(paraTool.get("topic"), new SimpleStringSchema(), paraTool.getProperties()));
env.execute();
}
public static class SimpleStringGenerator implements SourceFunction<String> {
private static final long serialVersionUID = 2174904787118597072L;
boolean running = true;
long i = 0;
public void run(SourceContext<String> ctx) throws Exception {
while (running) {
ctx.collect("element-" + (i++));
Thread.sleep(1000);
}
}
public void cancel() {
running = false;
}
}
}4.6.3 程序打包
在FlinkExample右键,选择“Run As->Maven install”导出Jar包
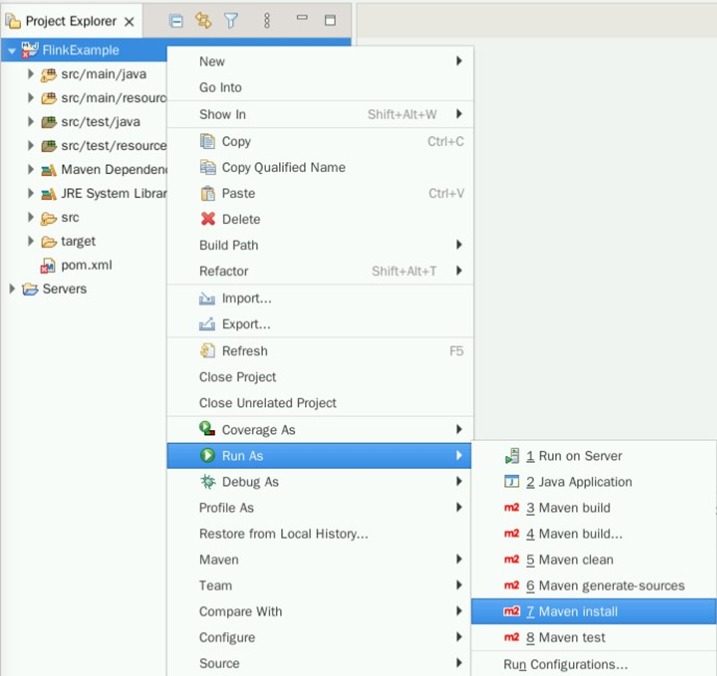
成功导出Jar包后,可以在target文件夹下找到FlinkExample-0.0.1-SNAPSHOT.jar
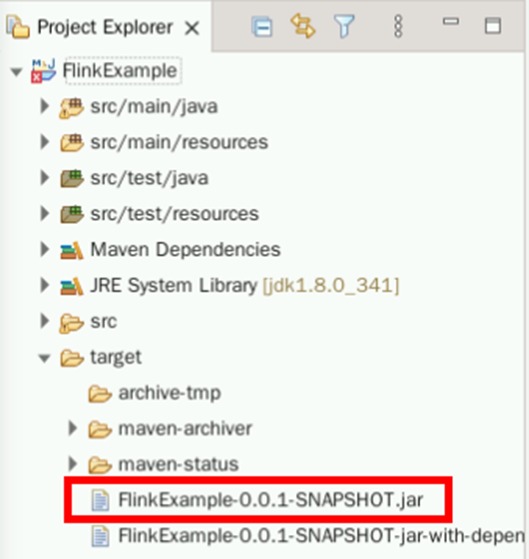
将FlinkExample-0.0.1-SNAPSHOT.jar上传至大数据集群/home/omm目录下。弹性公网IP见集群详情页
scp /home/user/eclipse-workspace/FlinkExample/target/FlinkExample-0.0.1-SNAPSHOT.jar root@xxx.xxx.xxx.xxx:/home/omm4.6.4 安装Flink客户端
类似于Impala客户端安装,需要进入MRS Manager页面,找到对应Flink服务
点击“更多->下载客户端”
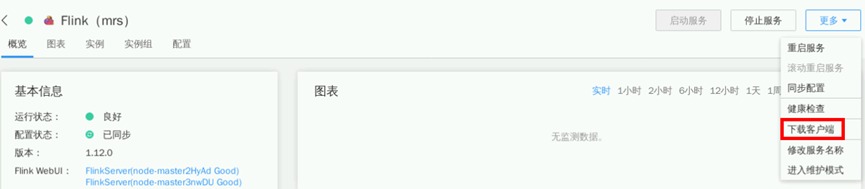
点击“x86_64->仅保存到如下路径”,保存路径修改为“/home/omm”。Flink客户端将会下载到集群主节点(即公网IP所对应服务器)的对应目录。下载时长约1分钟
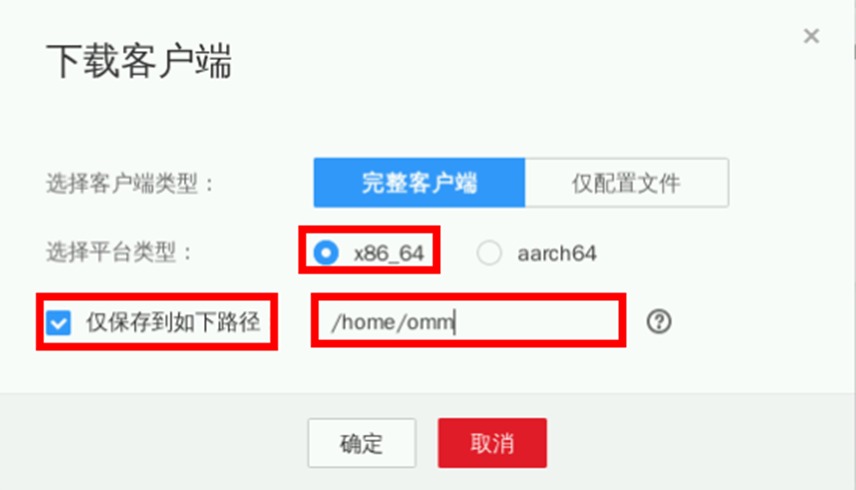
打开实验桌面的“Xfce终端”,使用ssh命令连接集群。弹性公网IP见集群详情页。连接成功后可显示“root@node-master...”信息
ssh root@xxx.xxx.xxx.xxx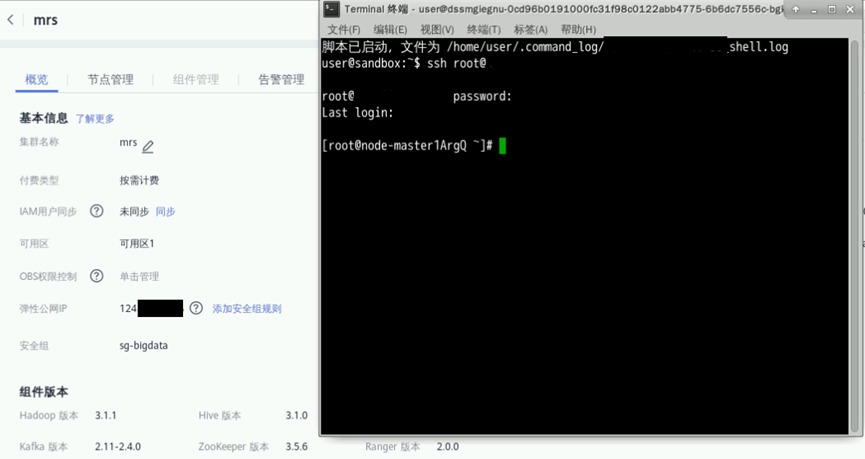
修改文件所属用户、用户组信息、操作权限
cd /home/omm
chown omm:wheel FlinkExample-0.0.1-SNAPSHOT.jar
chmod 777 FlinkExample-0.0.1-SNAPSHOT.jar
chmod 777 FusionInsight_Cluster_1_Flink_Client.tar解压客户端
tar -vxf FusionInsight_Cluster_1_Flink_Client.tar
tar -vxf FusionInsight_Cluster_1_Flink_ClientConfig.tar安装Flink客户端至/home/omm目录
cd FusionInsight_Cluster_1_Flink_ClientConfig
./install.sh /home/omm/FlinkClient安装成功后将显示如下信息
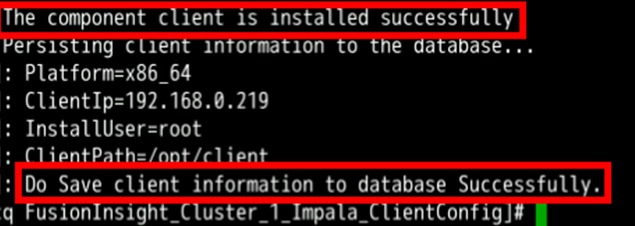
4.6.5 WriteIntoKafka程序运行
4.6.5.1查询集群Kafka Broker信息
在MRS Manager页面,找到对应Kafka服务
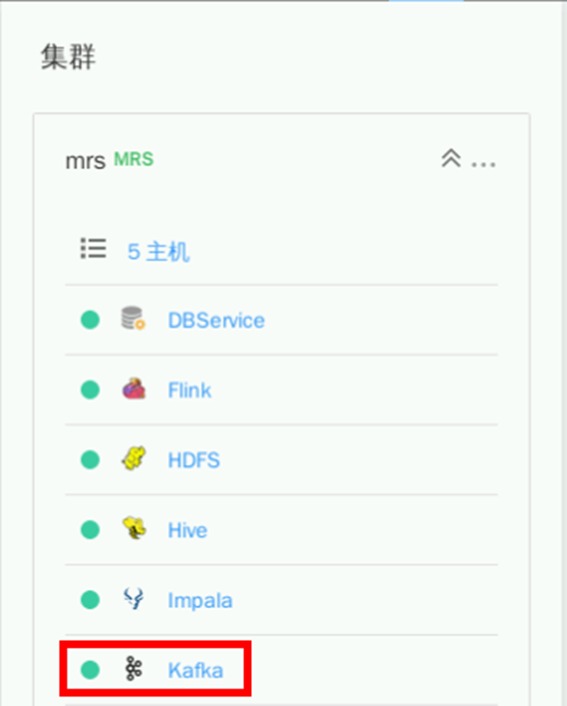
点击“实例”即可看到Broker所对应的业务IP信息
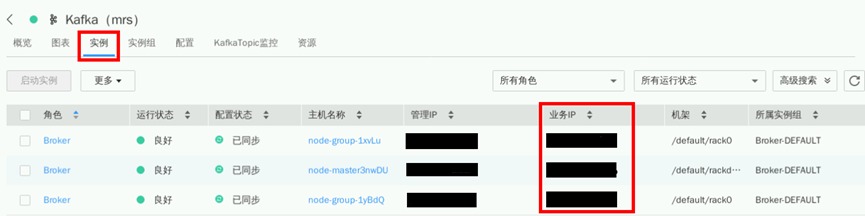
4.6.5.2查询集群Zookeeper信息
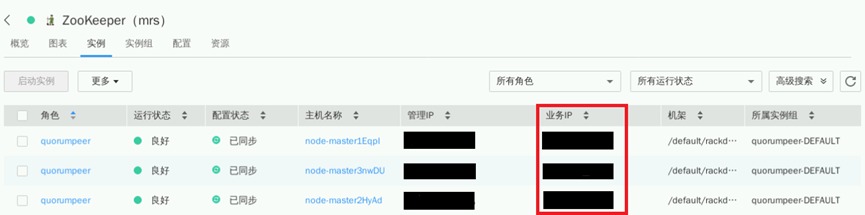
同理,在MRS Manager页面,找到对应Zookeeper服务
点击“实例”即可看到Broker所对应的业务IP信息
4.6.5.3创建kafka主题Topic
进入Kakfa客户端目录
cd /opt/Bigdata/components/FusionInsight_HD_8.1.0.1/Kafka/client/install_files/kafka/bin为脚本添加可执行权限:
chmod 777 kafka-topics.sh
chmod 777 kafka-run-class.sh
chmod 777 kafka-console-producer.sh
chmod 777 kafka-console-consumer.sh创建Topic
./kafka-topics.sh --create --zookeeper xxx.xxx.xxx.xxx:2181/kafka --topic FlinkTopic --replication-factor 2 --partitions 2其中“xxx.xxx.xxx.xxx:2181” 为集群中的Zookeeper任一服务地址,端口保持不变
4.6.5.4查看topic
执行命令
./kafka-topics.sh --list --zookeeper xxx.xxx.xxx.xxx:2181/kafka
4.6.6WriteIntoKafka程序运行
4.6.6.1创建Kafka消费者
新建Xfce终端窗口,登录集群。
ssh root@xxx.xxx.xxx.xxx进入Kafka目录。
cd /opt/Bigdata/components/FusionInsight_HD_8.1.0.1/Kafka/client/install_files/kafka/bin执行命令创建消费者,这里IP地址为broker的任一业务IP地址。
./kafka-console-consumer.sh --topic FlinkTopic --bootstrap-server xxx.xxx.xxx.xxx:9092 --from-beginning3.6.6.2启动WriteIntoKafka作为Kafka生产者
新建Xfce终端窗口,登录集群
ssh root@xxx.xxx.xxx.xxxFlink应用处于安全性考虑,需要由非root用户启动
su omm切换到Flink安装目录
cd /home/omm/FlinkClient应用环境变量信息
source bigdata_env检查“FlinkYarnSessionCli”进程是否启动
jps注意:若无“FlinkYarnSessionCli”进程,则启动Yarn集群
cd Flink/flink/bin
./yarn-session.sh &运行Flink应用程序
flink run --class FlinkDemo.WriteIntoKafka /home/omm/FlinkExample-0.0.1-SNAPSHOT.jar --topic FlinkTopic --bootstrap.servers xxx.xxx.xxx.xxx:9092运行成功后可在Kafka消费者窗口看到数据输出
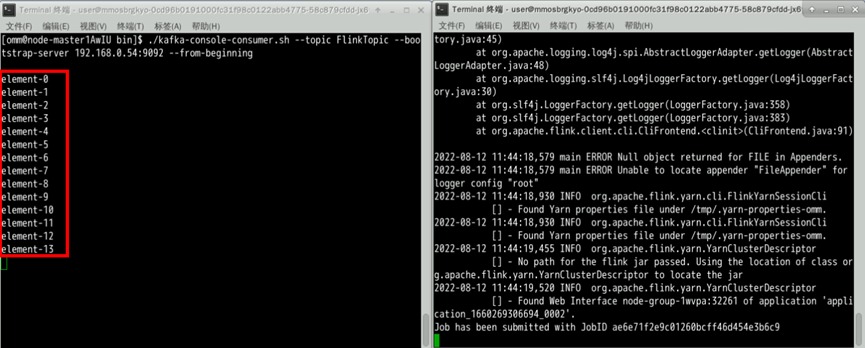
任务完成

- 点赞
- 收藏
- 关注作者
评论(0)