静态网页爬虫②

爬取整个网站
为了爬取整个网站,我们得先分析该网站的数据是如何加载的。
还是以某瓣读书为例,当我们点击第二页后,观察浏览器的地址栏,发现网址变了。网址变成了 https://book.douban.com/top250?start=25,和原来相比后面多了一个 ?start=25。
这部分被称为 查询字符串,查询字符串作为用于搜索的参数或处理的数据传送给服务器处理,格式是 ?key1=value1&key2=value2。
? 前面是网页的地址,后面是查询字符串。以键值对 key=value 的形式赋值,多个键值对之间用 & 连接在一起。例如 ?a=1&b=2 表示:a 的值为 1,b 的值为 2。
查询字符串用于信息的传递,服务器通过它就能知道你想要什么,从而给你返回对应的内容。比如你在知乎搜索 python,网址会变成 https://www.zhihu.com/search?type=content&q=python,后面的查询字符串告诉服务器你想要的是有关 python 的内容,于是服务器便将有关 python 的内容返回给你了。
了解了查询字符串的相关知识后,接下来我们多翻几页豆瓣读书的页面,观察一下网址的变化规律:
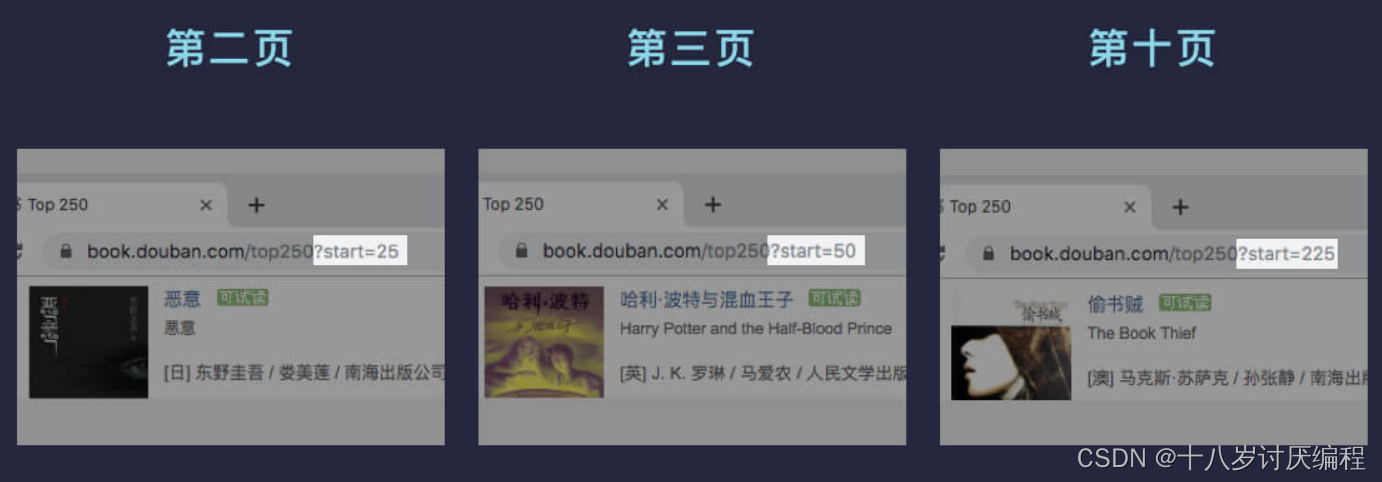
第二页 start=25,第三页 start=50,第十页 start=225,而每页的书籍数量是 25。你有没有发现其中的规律?
因为每页展示 25 本书,根据规律其实不难推测出 start 参数表示从第几本书开始展示,所以第一页 start 是 0,第二页 start 是 25,第三页 start 是 50,第十页 start 是 225。因此 start 的计算公式为 start = 25 * (页码数 - 1)(25 为每页展示的数量)。我们来通过代码自动生成某瓣图书 Top250 所有数据(10 页)的地址:
url = 'https://book.douban.com/top250?start={}'
# num 从 0 开始因此不用再 -1
urls = [url.format(num * 25) for num in range(10)]
print(urls)
# 输出:
# [
# 'https://book.douban.com/top250?start=0',
# 'https://book.douban.com/top250?start=25',
# 'https://book.douban.com/top250?start=50',
# 'https://book.douban.com/top250?start=75',
# 'https://book.douban.com/top250?start=100',
# 'https://book.douban.com/top250?start=125',
# 'https://book.douban.com/top250?start=150',
# 'https://book.douban.com/top250?start=175',
# 'https://book.douban.com/top250?start=200',
# 'https://book.douban.com/top250?start=225'
# ]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
有了所有网页的链接后,我们就可以爬取整个网站的数据了!
我们可以修改代码,将前文中的某瓣top250进行整个的爬取:
import requests
from bs4 import BeautifulSoup
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.41 Safari/537.36 Edg/101.0.1210.32'
}
num = 0
# 为了对整个某瓣进行爬取,我们先对数据处理的部分进行封装
def getTarget(url):
global num
#首先对网页发出请求并获得响应
req = requests.get(url,headers = headers)
#将网页的源代码形式解析
soup = BeautifulSoup(req.text,'html.parser')
#进行元素的第一次提取
result1 = soup.select('.item .pic')
for i in result1:
num += 1
name = i.select('a img')[0]['alt']
link = i.select('a')[0]['href']
print(num,' ',name,link)
for i in range(0,230,25):
address = 'https://movie.douban.com/top250?start={}'.format(i)
getTarget(address)
# 暂停 1 秒防止访问太快被封
time.sleep(1)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
结果(不完整):
反爬虫
反爬虫 是网站限制爬虫的一种策略。它并不是禁止爬虫(完全禁止爬虫几乎不可能,也可能误伤正常用户),而是限制爬虫,让爬虫在网站可接受的范围内爬取数据,不至于导致网站瘫痪无法运行。
常见的反爬虫方式有 判别身份 和 IP 限制 两种,我们一一介绍,并给出相应的反反爬虫技巧。
判别身份
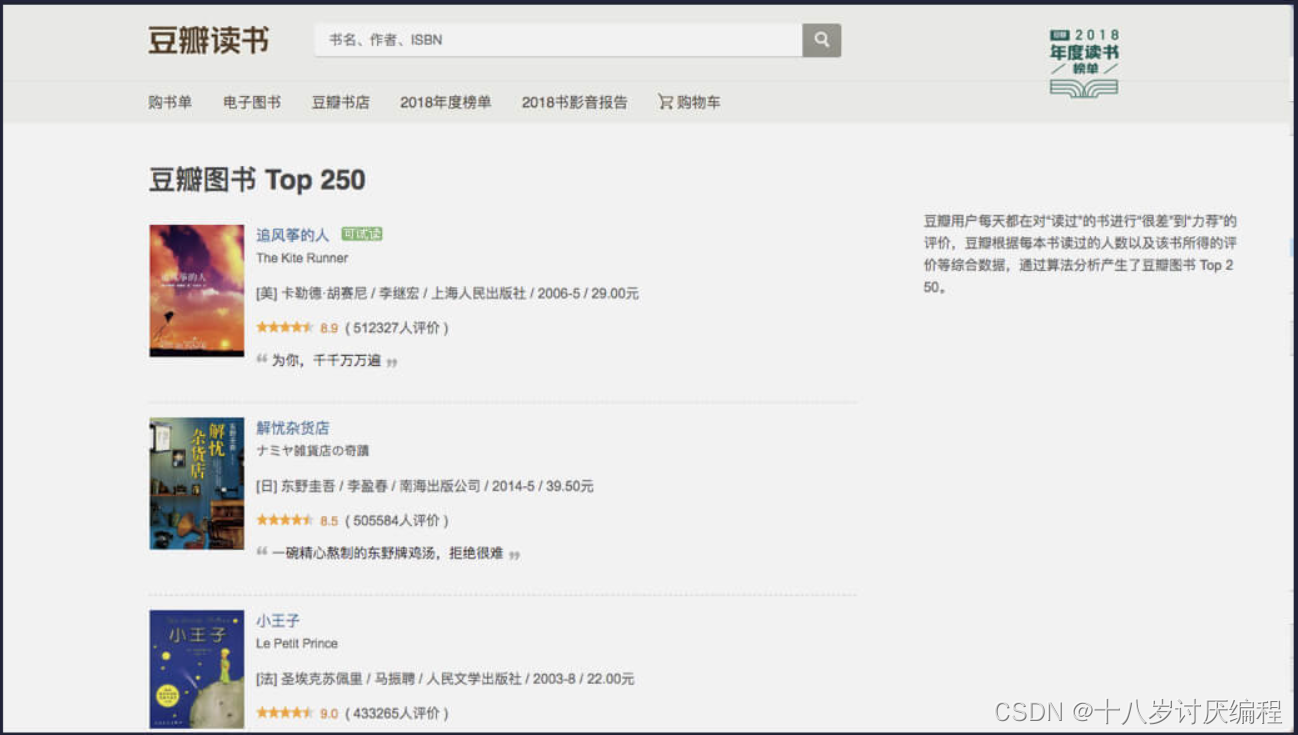
有些网站在识别出爬虫后,会拒绝爬虫的访问,比如某瓣。我们以某瓣图书 Top250 为例,用浏览器打开是下面这样的:
如果用爬虫直接爬取它,我们看看结果会是什么:
import requests
res = requests.get('https://book.douban.com/top250')
print(res.text)
- 1
- 2
- 3
- 4
输出结果为空,什么都没有。这是因为某瓣将我们的爬虫识别了出来并拒绝提供内容。
你可能会有疑问,爬虫不是模拟浏览器访问网站、获取网页源代码的吗?怎么会被识别出来呢?
其实,不管是浏览器还是爬虫,访问网站时都会带上一些信息用于身份识别。而这些信息都被存储在一个叫 请求头(request headers)的地方。
服务器会通过请求头里的信息来判别访问者的身份。请求头里的字段有很多,我们暂时只需了解 user-agent(用户代理)即可。user-agent 里包含了操作系统、浏览器类型、版本等信息,通过修改它我们就能成功地伪装成浏览器。
我们可以根据下图的指示操作,看看请求头长什么样:
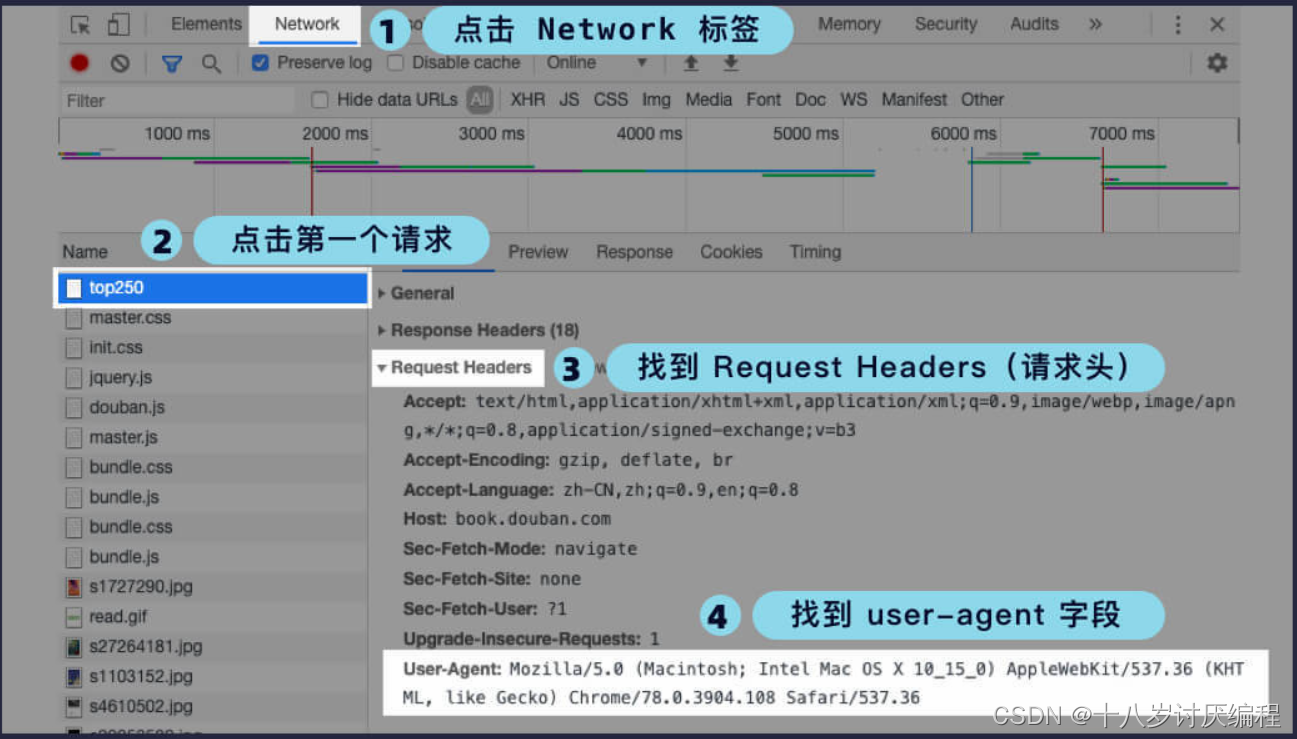
我的浏览器的 user-agent 是 Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36,而 requests 默认的 user-agent 是 python-requests/2.22.0。
默认的 user-agent 和在头上贴着“我是爬虫”的纸条没有什么区别,难怪会被服务器识别出来。因此我们需要修改请求头里的 user-agent 字段内容,将爬虫伪装成浏览器。所以接下来我们来看看如何在 requests 库中修改请求头。
我们打开 requests 的官方文档(http://cn.python-requests.org/zh_CN/latest/)并搜索 定制请求头,找到对应的文档:
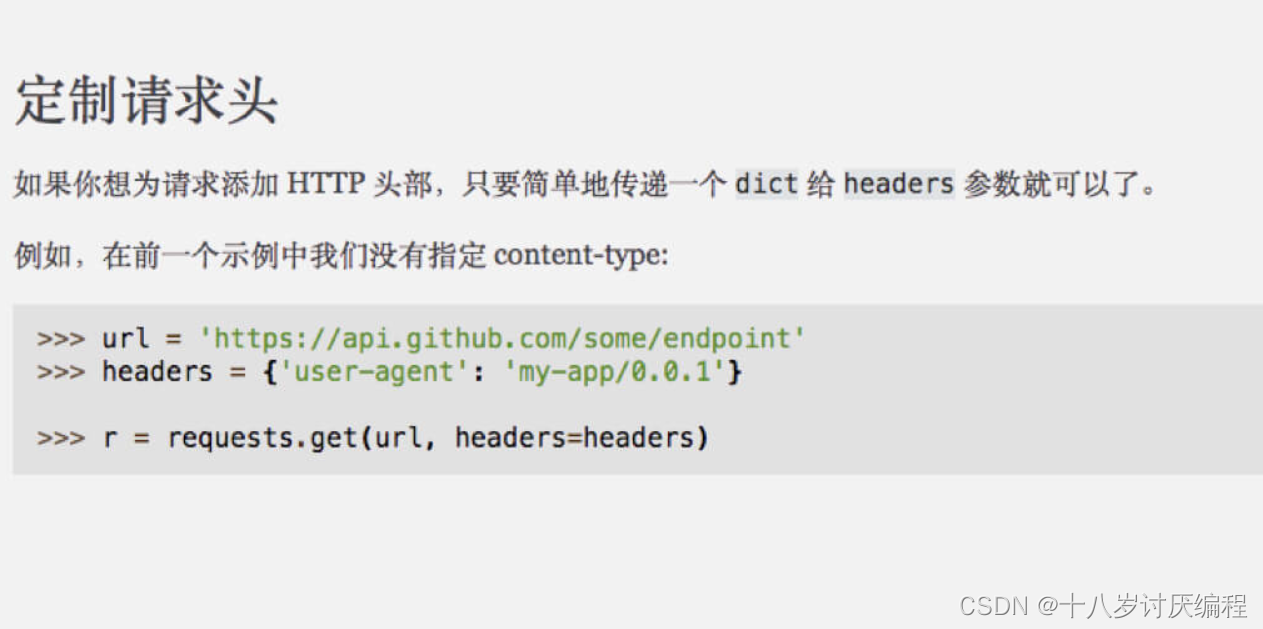
在 requests 的官方文档中我们可以看到,我们只需定义一个 字典(请求头字段作为键,字段内容作为值)传递给 headers 参数即可。
除了 user-agent 之外的其他请求头字段也能以同样的方式添加进去,但大部分情况下我们只需要添加 user-agent 字段即可(有些甚至不需要)。当我们加了 user-agent 字段还是无法获取到数据时,说明该网站还通过别的信息来验证身份,我们可以将请求头里的字段都添加进去试试。
判别身份是最简单的一种反爬虫方式,我们也能通过一行代码,将爬虫伪装成浏览器轻易地绕过这个限制。所以,大部分网站还会进行 IP 限制 防止过于频繁的访问。
IP 限制
IP(Internet Protocol)全称互联网协议地址,意思是分配给用户上网使用的网际协议的设备的数字标签。你可以将 IP 地址理解为门牌号,我只要知道你家的门牌号就能找到你家。
IP 地址也是一样,只要知道服务器的 IP 地址就能找到对应的服务器。你在网上冲浪时电脑也会被分配一个 IP 地址,这样服务器就知道是谁在访问他们的网站了。
前面说过,当我们爬取大量数据时,如果我们不加以节制地访问目标网站,会使网站超负荷运转,一些个人小网站没什么反爬虫措施可能因此瘫痪。而大网站一般会限制你的访问频率,因为正常人是不会在 1s 内访问几十次甚至上百次网站的。
所以,如果你访问过于频繁,即使改了 user-agent 伪装成浏览器了,也还是会被识别为爬虫,并限制你的 IP 访问该网站。
因此,我们常常使用 time.sleep() 来降低访问的频率,比如前文中的爬取整个网站的代码,我们每爬取一个网页就暂停一秒。这样,对网站服务器的压力不会太大,对方也就睁一只眼闭一只眼不理会我们的爬虫。虽然速度较慢,但也能获取到我们想要的数据了。
除了降低访问频率之外,我们也可以使用代理来解决 IP 限制的问题。代理的意思是通过别的 IP 访问网站。这样,在 IP 被封后我们可以换一个 IP 继续爬取数据,或者每次爬取数据时都换不同的 IP,避免同一个 IP 访问的频率过高,这样就能快速地大规模爬取数据了。
我们打开官方文档,看看如何使用代理:
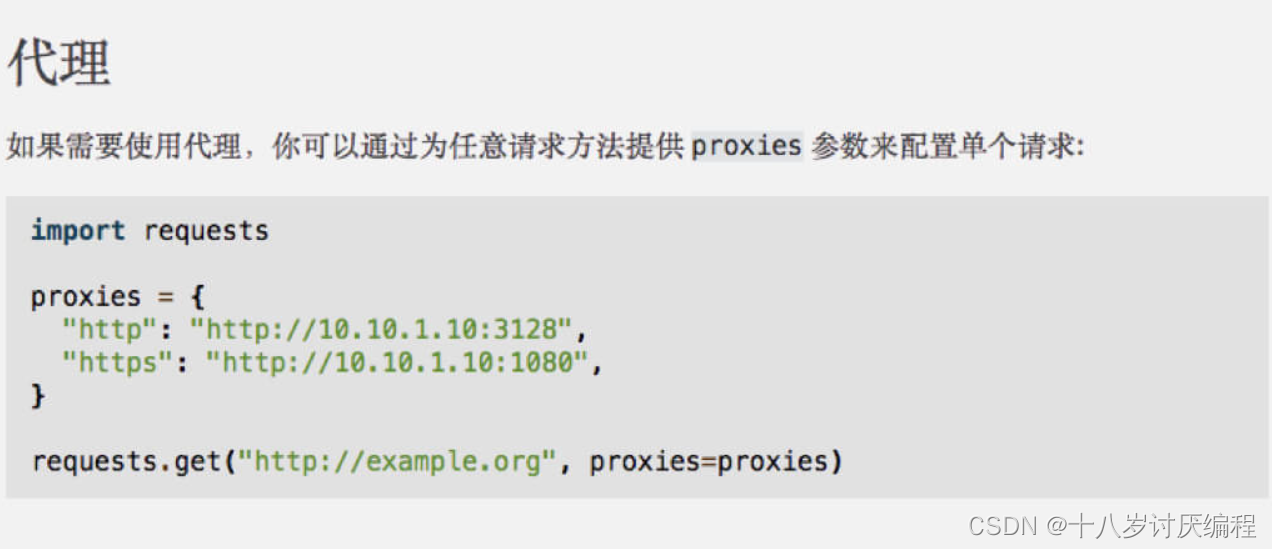
和 headers 一样,也是定义一个字典,但传递给的是 proxies 参数。我们需要将 http 和 https 这两种协议作为键,对应的 IP 代理作为值,最后将整个字典作为 proxies 参数传递给 requests.get() 方法即可。IP 代理有免费的和收费的,你可以自行在网上寻找。
提示:http 和 https 都是浏览器和服务器之间通讯的协议,https 更加的安全,也被越来越多的网站所使用。
官方文档中给了代理的基本用法,但在爬取大量数据时我们需要很多的 IP 用于切换。因此,我们需要建立一个 IP 代理池(列表),每次从中随机选择一个传给 proxies 参数。我们来看一下如何实现:
import requests
import random
from bs4 import BeautifulSoup
def get_douban_books(url, proxies):
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36'
}
# 使用代理爬取数据
res = requests.get(url, proxies=proxies, headers=headers)
soup = BeautifulSoup(res.text, 'html.parser')
items = soup.find_all('div', class_='pl2')
for i in items:
tag = i.find('a')
name = tag['title']
link = tag['href']
print(name, link)
url = 'https://book.douban.com/top250?start={}'
urls = [url.format(num * 25) for num in range(10)]
# IP 代理池(瞎写的并没有用)
proxies_list = [
{
"http": "http://10.10.1.10:3128",
"https": "http://10.10.1.10:1080",
},
{
"http": "http://10.10.1.11:3128",
"https": "http://10.10.1.11:1080",
},
{
"http": "http://10.10.1.12:3128",
"https": "http://10.10.1.12:1080",
}
]
for i in urls:
# 从 IP 代理池中随机选择一个
proxies = random.choice(proxies_list)
get_douban_books(i, proxies)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
这样,我们就能既快速又不会被限制地爬取数据了。但毫无节制的爬虫已经和网络攻击没什么区别了,严重的甚至会导致网站瘫痪。恶意地大量访问别人的网站,消耗服务器资源是非常不道德、甚至违法的。
其实,除了反爬虫措施远不只这两种。比如验证码,当你的操作异常时网站经常会弹出验证码。验证码技术也在不断地升级,从原先简单的随机生成的数字字母,演变成随机汉字,再由按顺序点击图中对应的汉字演变成滑块拼图。
还有些验证码是一个数学题,你得计算出答案。像 12306 的验证码就更复杂了,需要识别出图中的物体。验证码的形式千千万万,破解起来也较为困难。我们这里不涉及。
了解了一些反爬虫措施和反反爬虫技巧后,我们来看看爬虫中的君子协议—robots.txt。
robots.txt
robots.txt 是一种存放于网站根目录下的文本文件,用于告诉爬虫此网站中的哪些内容是不应被爬取的,哪些是可以被爬取的。
我们只要在网站域名后加上 /robots.txt 即可查看,比如某瓣读书的 robots.txt 地址是:https://book.douban.com/robots.txt。打开它后的内容如下:
User-agent: *
Disallow: /subject_search
Disallow: /search
Disallow: /new_subject
Disallow: /service/iframe
Disallow: /j/
User-agent: Wandoujia Spider
Disallow: /
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
User-agent: * 表示针对所有爬虫(* 是通配符),接下来是符合该 user-agent 的爬虫要遵守的规则。比如 Disallow: /search 表示禁止爬取 /search 这个页面,其他同理。
robots.txt 也能针对某一个爬虫限制,比如最后的 User-agent: Wandoujia Spider 表示针对 Wandoujia Spider 这个爬虫,Disallow: / 表示禁止整个网站的爬取。
但我们说过,robots.txt 只是一个君子协议,网站只是告诉大家哪些页面禁止爬取数据,并不能阻止你去爬取。即便如此,我们还是应该遵守规则,下次在爬取网站时,记得先打开该网站的 robots.txt 查看哪些页面可以爬取数据,哪些页面禁止爬取数据。
文章来源: blog.csdn.net,作者:十八岁讨厌编程,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/zyb18507175502/article/details/124637478

- 点赞
- 收藏
- 关注作者
评论(0)