【字符识别】基于matlab模板匹配(区域生长法)字母+数字识别【含Matlab源码 1214期】

一、手写大写字母识别技术简介
0 引言
在高校教学过程中,考试是最为普遍的一种教学评估、综合练习的教学手段,随着科技进步,考试阅卷的方式也发生了巨大的变革。传统的阅卷方式主要以人工阅卷为主, 存在效率低下等不足; 现代的阅卷方式采用了光学标记识别(Optica Mark Recognition, OMR) 技术, 考生只需在答题卡上填涂, 计算机会通过对答题卡进行处理从而实现自动阅卷, 但这种方式需使用特别设计的答题卡与铅笔,并且遵循一定的填涂规范。以上两种方法均给老师、考生带来了一定的限制,耗费了较多的时间;因此为了让被试者灵活、高效的进行答题,对手写体的字符识别进行研究十分有必要。
手写体的字符识别按照采取的技术路线大体上分为两类:一类是特征提取法;另一类是神经网络法。特征提取法按照提取字符特征的不同又可分为两类:一类是基于轮廓、结构特征的字符识别算法,这类算法通过识别字符图像的轮廓特征、端点特征、凹凸结构特征等,对字符进行细化处理,采用模板匹配的方式实现手写字符的自动识别。这类方式虽然能够对字符的结构进行直观地描述,但是对于噪声及产生形变的字符不能很好的识别,缺乏鲁棒性。
另一类是基于统计特征的手写体字符识别算法,这类算法通过对大量的样本训练相应的分类器,并利用这些分类器对待识别字符进行分类。优点是当采样样本足够充分时,这类方法能够具有较好的识别效果;缺点就是往往不能构造足够丰富的样本。神经网络法得到较高的识别率,但需要对大量样本进行训练,耗费较多时间,降低了识别的实时性;即使对神经网络进行改进、优化,也没有从根本上弥补其不足。
在考试中由于被试者的书写风格不一造成了手写字符的形态各异的特点,这就决定了在手写字符的识别中单一方案不会得到很好的识别效果。试卷客观题的评阅中,大多只包含A、B、C、D四个字符,字符个数少,仅对A~D四个字符进行识别能够得到较好的阅卷效率及较高的正确识别率。针对手写英文字母的特点及应用场景,本文提出一种基于组合特征的手写英文字母识别方法。该方法在轮廓特征提取的基础上加入形状特征提取,提取特征信息简单,同时不需要样本训练,因此提高了手写英文字母的识别成功率与识别速度。
1 图像预处理
由于手写字符形状存在风格不一的特点,且图像拍摄时的光照变化、纸张整洁程度等都会使得字符图像存在一定程度的噪声,因此必须对图像进行预处理,这样便于对后面的字母切分和特征提取,提高最终的字母识别准确率。图像预处理包括使用高斯滤波去除拍照设备产生的高斯噪声;对图像进行二值化,使得图像去掉背景;最后使用轮廓提取去除较大的噪点。
1.1 高斯滤波
数字图像在获取、传输的过程中都可能受到噪声的污染,而摄像机传感器内部元器件最容易产生的噪声是高斯噪声。高斯噪声是指它的概率密度函数服从高斯分布的一类噪声,对于此类噪声常用的方法为高斯滤波。高斯滤波是一种线性平滑滤波,适用于消除高斯噪声,广泛应用于图像处理的减噪过程。根据对测试样本分别使用1×1、3×3、5×5的高斯核进行实验发现,使用3×3高斯核的样本实验结果表现最好,因此本文选用3*3的高斯核对原始图像进行高斯滤波。
1.2 图像二值化
对图像进行二值化处理是利用手写字符区域与其背景存在灰度差异的特点,将手写字符与背景以灰度区分开,便于后期的处理。常用的二值化算法有最大类间方差法(OTSU法) 、迭代法、Bers en、Niblack、简单统计法、Niblack与模糊C均值法(Niblack and Fuzzy C-Means, NFC M) 等。OTSU法是一种自适应的阈值确定的方法, 其基本思想是求取最佳门限阈值,此阈值将图像灰度直方图分割成黑白两部分,使两部分类间方差取得最大值,并使类内方差值最小,因此OTSU法也称为最大类间方差法。本文图像中的手写英文字母与背景具有明显的灰度差异, 因此采用OTSU法较为合适。图1为图像二值化过程。
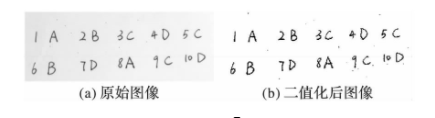
图1 图像二值化
1.3 轮廓去噪
经过高斯滤波后,可以去除或者减少部分由摄像头传感器引起的噪声,但是对于纸张本身存在的噪点处理效果达不到要求。在实际应用过程中,除字母以外的背景区域有可能会出现分布不均、不规则噪点,因此本文采用寻找连通域轮廓的方式,找到所有连通域的轮廓,并计算它们的轮廓面积,设定一个面积阈值,轮廓面积小于阈值的连通域可以判断为噪点,将其剔除。经过大量实验,本文设定将像素面积小于12的像素点去除。具体的轮廓提取方法在后文详细叙述。图2是轮廓去噪后的图像。
2 字符分割
图像的投影特征在图像处理中是重要技术之一,一般是通过计算图像在X轴或者Y轴的每个位置上的像素点(黑色或白色)总数量,并描绘出相应的投影曲线图来分析图像特征,该技术常用于图像分割、字符检测及提取等。公式(1)(2)分别是水平投影与垂直投影的计算公式。其中,h,w分别是二值化图像的高度和宽度;f(i,j)为图像第i行第j列元素的值1或0。

2.1 行分割
行分割就是对图像X轴方向进行水平投影,得到X轴方向上每个位置的白点总数,若某个位置上的白点总数为0,则说明该位置没有手写痕迹。因为人们的常用书写习惯是一行一行写,且行与行之间存在一定距离,所以通过行分割就能知道哪些位置是没有书写过的,这样就能大致将手写区域按行进行分割。

图3 行分割过程
2.2 列分割
列分割就是对图像Y轴方向进行垂直投影,得到Y轴方向上每个位置的白点总数,若某个位置上的白点总数为0,则说明该位置为字母间的间隙。通过列分割很容易地将每个字母提取出来进行后面的识别。
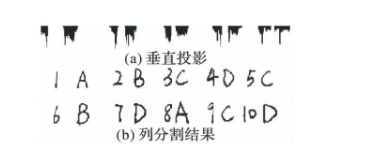
图4 列分割过程
2.3 最小图像分割
在进行过行分割与列分割后,基本将字母分割成单独的图像,但是此时的图像往往尺寸较大,字母在整个图像中所占比例较小,为了减少图像处理时间,方便后面的字母识别,需要对分割后的字母再次进行切割,使得字母尽量占满整个图片。图5中的黑色边框为图像边界。

图5 最小图像示意图
3 分类识别
对于字母A~D很容易发现它们的轮廓特征,字母A、D包含一个闭合曲线;字母B包含2个闭合曲线;字母C包含0个闭合曲线,因此可以通过提取字母的闭合曲线数量对字母进行粗分,然后再对A、D进行区分。提取轮廓特征后接着提取形状特征,将两种特征的识别结果进行融合即可得到最后的识别结果
3.1 轮廓特征提取
轮廓提取在图像处理中是常用方法之一,轮廓可以简单认为成将连续的点连在一起的曲线,具有相同的颜色或者灰度。通过对二值图像进行拓扑分析,对图像进行行扫描,为不同的轮廓赋予不同的整数值,从而确定外轮廓、内轮廓以及它们的层级关系。如图6有2个黑色轮廓,1a为第一个黑色轮廓的外边界,1b为第一个黑色轮廓的孔边界,2a为第二个黑色轮廓的外边界,2b为第二个黑色轮廓的孔边界。

图6 轮廓示意图
具体的操作是先对二值图像进行行扫描,判断像素点的像素值,用式(3)表示图像的像素值,i是图像的行数,j是图像的列数。

当行扫描到轮廓的外边界与孔边界时,扫描终止,式(4)为外边界终止条件,式(5)为孔边界终止条件。以扫描终止时的f(i,j)为起点,标记边界上的像素,给边界赋予一个数值(如1),以后每次发现一个新边界即在数值上加1,在图6中有两条轮廓,第一条轮廓的标记值为1,第二条轮廓标记值为2,这样即完成了轮廓的检测。

本文中,通过对分割后的手写英文字母进行轮廓提取可以很容易地将A~D分为3类:轮廓数为0的有C;轮廓数为1的有
A、D;轮廓数为2的有B。
由于字母A、D具有相同的轮廓数,因此需要对两个字母进行区分。通过对字母A、D的轮廓特征进行分析可以发现,对于同样尺寸的字母A和字母D,A字母轮廓面积比D字母轮廓面积小;对于已是最小图象的字母A和字母D,经过对182份手写英文字母数据进行统计分析得到字母A轮廓面积占图像面积的比例为0.075194884,字母D轮廓面积占图像面积比例为0.321412412。由此可见,A字母轮廓面积占尺寸面积的比例小于字母D。因此在王识别中只需对待识别的字母轮廓面积占比分别与字母A的占比系数和字母D的占比系数求差值,相比较即可判别A、D。图7为字母A与字母D提取轮廓面积示意图。
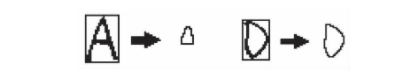
图7 字母A与字母D轮廓面积提取示意图
3.2形状特征提取
通过对英文字母A~D的形状进行分析可以找到各个字母的形状特征,具体操作为:将预处理后得到的二值图像(如图8(a))进行填充,得到图8(b),可以看出字母A的形状近似三角形;字母B的形状包含两个凸起部分和一个凹进部分;字母C同样包含两个凸起部分和一个凹进部分;字母D只有一个凸起部分。然后对图8(b)进行水平投影将字母每行的像素和显示在投影直方图上(图8©),对各个字母的像素和数据进行分析,可以得到字母A的数据曲线呈现单调递增;字母B的数据曲线包含2个波峰一个波谷;字母C的数据曲线同样包含2个波峰一个波谷;字母D的数据曲线包含1个波峰。

图8 形状特征提取过程
得到各个字母的数据后, 对数据曲线进行差分运算, 曲线的峰值点满足一阶导数为0, 二阶导数为负;波谷点满足一阶导数为0, 二阶导数为正;单调性曲线满足一阶导数不为0, 由此可以将字母区分为A、B和C、D三类。算法流程如下:数据曲线可以看作是一维向量如下:

其中, vi (i∈[1, 2, …, N]) 代表图像在第i行上的白色像素和。计算V的一阶差分向量Diffv:
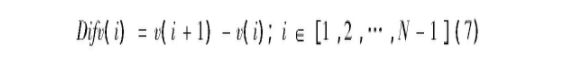
得到差分向量后进行符号函数运算, 如式 (8) :
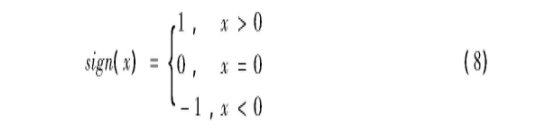
此时可以得到各点的变化情况,但是有些点值相同,却不是波峰波谷,那么再进行一次一阶差分即可得到数据曲线的波峰或波谷点。
3.3特殊处理
由于在考试中难免出现答案填写错误的情况,因此对于这种情况需要作特殊处理。本文在对字母识别的基础上设计一种错误答案标注方式,对于填写错误的答案,可在答案上从左至右划2笔不重复的斜杠,从右至左划2笔不重复的斜杠,如图9所示,经过标注后的错误答案轮廓数会超出正常字母的轮廓数,这样即可区分出填写错误的答案。

图9 特殊情况处理
二、部分源代码
function [ output_args ] = main( input_args )
% 识别过程可能比较慢,因为区域生长比较耗时间,而且模板是多文件的形式存储在
%硬盘上,每比对一个字符都要从硬盘访问所有模板图片,大概需要2s
clear all
warning off
clc
fid = fopen('text.txt', 'wt');
%%对图片进行前期处理
imgIn = imread('test2.bmp');
figure();set(gcf,'Name','前期处理');subplot(1,2,1);imshow(imgIn);title('原图');
% imgIn = imnoise(imgIn,'salt & pepper',0.03);%添加椒盐噪声
% imgIn = imnoise(imgIn,'gaussian',0,0.03);%添加高斯噪声
% imwrite(imgIn,'out','bmp');
imgGr = imgIn(:,:,3);%抠取蓝色通道
imgMed = medfilt2(imgGr);%采用中值滤波去掉椒盐噪声
imgMed = medfilt2(imgMed);%继续采用中值滤波使图像区域表现更加明显
imgBw = im2bw(imgMed);%转换为二值图
imgBw = ones(size(imgBw)) - imgBw;%反色处理
imgBw = imclose(imgBw ,strel('disk',3));%对图像进行闭操作
imgBw(:,1)=0;imgBw(:,size(imgBw,2))=0;imgBw(1,:)=0;imgBw(size(imgBw,1),:)=0;%将图片最外围一周的像素置为0,中值滤波和闭操作均处理不了此位置
subplot(1,2,2);imshow(imgBw);title('处理后的二值图');
%%分割图片并识别每一个字符
%loca是一个矩阵[5,:],用来记录识别结果以及字符所在位置
figure;set(gcf,'Name','识别');
[lines,cols]=size(imgBw);
loca = [];
m=0;
for i=1:lines
for j=1:cols
if imgBw(i,j)==1
imgCut = areaGrow(imgBw,[i,j]);%区域生长法抠出一个字符
[x,y]=find(imgCut==1);
imgBw = imgBw - imgCut;%从原二值图中消去本次抠出的字符
imgSl = imgSlim(imgCut);%消除黑边
imgOP = imresize(imgSl,[42,24]);%将抠出的图片缩放到[42 24]
charNum = identify(imgOP);%进行字符识别
m=m+1;subplot(4,4,m);imshow(imgSl);xlabel(['识别为: ' char(charNum)]);%显示图片和单字符识别结果
loca = [loca [charNum;min(x);max(x);min(y);max(y)]];%记录识别结果以及该字符在图片中的位置
end
end
end
%%字符排序 我采用的是与最上面字符的上边沿之间的距离差不大于所有字符平均高度的一半的字符为一行
%计算字符的平均高度
n = size(loca,2); %计算loca的列数(即字符的个数)
suma = 0; %suma用来记录所有字符的高度和
for x=1:n
suma = suma + loca(3,x)-loca(2,x);
end
[lines,cols]=size(imgBW); %获取imgBW的尺寸
imgCut=zeros(lines,cols); %建立一个跟imgOut同样尺寸的0矩阵,生长的区域保存在该矩阵中
imgCut(p(1),p(2))=1;%设置点(p(1),p(2))为种子点
count=1; %记录生长点周围8个像素中白色像素的个数,是下面循环结束的判断条件
while count>0
count=0;
for i=1:lines
for j=1:cols
if imgCut(i,j)==1%在imgCut中扫描到白
if (i-1)>0&&(i+1)<(lines+1)&&(j-1)>0&&(j+1)<(cols+1) %确认不为边界点
for u=-1:1
for v=-1:1
if imgCut(i+u,j+v)==0&& imgBW(i+u,j+v)==1 %在生长点周围寻找到未加入imgCut的白点
imgCut(i+u,j+v)=1;%将该点加入imgCut
count = count+1;
end
end
end
end
end
end
end
end
end

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
三、运行结果



四、matlab版本及参考文献
1 matlab版本
2014a
2 参考文献
[1] 蔡利梅.MATLAB图像处理——理论、算法与实例分析[M].清华大学出版社,2020.
[2]杨丹,赵海滨,龙哲.MATLAB图像处理实例详解[M].清华大学出版社,2013.
[3]周品.MATLAB图像处理与图形用户界面设计[M].清华大学出版社,2013.
[4]刘成龙.精通MATLAB图像处理[M].清华大学出版社,2015.
文章来源: qq912100926.blog.csdn.net,作者:海神之光,版权归原作者所有,如需转载,请联系作者。
原文链接:qq912100926.blog.csdn.net/article/details/119655652

- 点赞
- 收藏
- 关注作者
评论(0)