【VRP】基于matlab模拟退火算法求解单中心的车辆路径规划问题【含Matlab源码 1340期】

一、VRP简介
1 VRP基本原理
车辆路径规划问题(Vehicle Routing Problem,VRP)是运筹学里重要的研究问题之一。VRP关注有一个供货商与K个销售点的路径规划的情况,可以简述为:对一系列发货点和收货点,组织调用一定的车辆,安排适当的行车路线,使车辆有序地通过它们,在满足指定的约束条件下(例如:货物的需求量与发货量,交发货时间,车辆容量限制,行驶里程限制,行驶时间限制等),力争实现一定的目标(如车辆空驶总里程最短,运输总费用最低,车辆按一定时间到达,使用的车辆数最小等)。
VRP的图例如下所示:
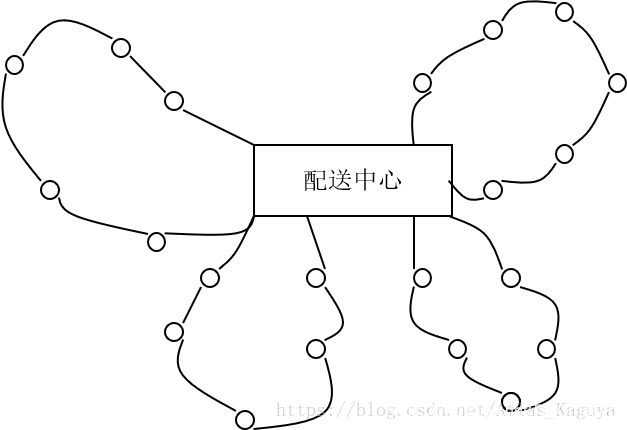
2 问题属性与常见问题
车辆路径问题的特性比较复杂,总的来说包含四个方面的属性:
(1)地址特性包括:车场数目、需求类型、作业要求。
(2)车辆特性包括:车辆数量、载重量约束、可运载品种约束、运行路线约束、工作时间约束。
(3)问题的其他特性。
(4)目标函数可能是总成本极小化,或者极小化最大作业成本,或者最大化准时作业。
3 常见问题有以下几类:
(1)旅行商问题
(2)带容量约束的车辆路线问题(CVRP)



该模型很难拓展到VRP的其他场景,并且不知道具体车辆的执行路径,因此对其模型继续改进。



(3)带时间窗的车辆路线问题
由于VRP问题的持续发展,考虑需求点对于车辆到达的时间有所要求之下,在车辆途程问题之中加入时窗的限制,便成为带时间窗车辆路径问题(VRP with Time Windows, VRPTW)。带时间窗车辆路径问题(VRPTW)是在VRP上加上了客户的被访问的时间窗约束。在VRPTW问题中,除了行驶成本之外, 成本函数还要包括由于早到某个客户而引起的等待时间和客户需要的服务时间。在VRPTW中,车辆除了要满足VRP问题的限制之外,还必须要满足需求点的时窗限制,而需求点的时窗限制可以分为两种,一种是硬时窗(Hard Time Window),硬时窗要求车辆必须要在时窗内到达,早到必须等待,而迟到则拒收;另一种是软时窗(Soft Time Window),不一定要在时窗内到达,但是在时窗之外到达必须要处罚,以处罚替代等待与拒收是软时窗与硬时窗最大的不同。


模型2(参考2017 A generalized formulation for vehicle routing problems):
该模型为2维决策变量

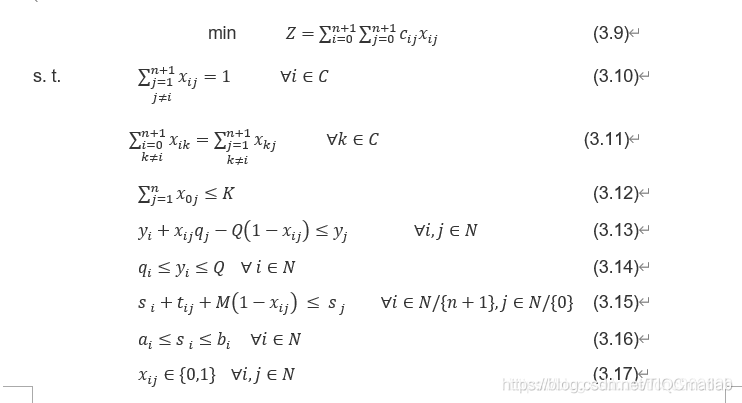

(4)收集和分发问题
(5)多车场车辆路线问题
参考(2005 lim,多车场车辆路径问题的遗传算法_邹彤, 1996 renaud)
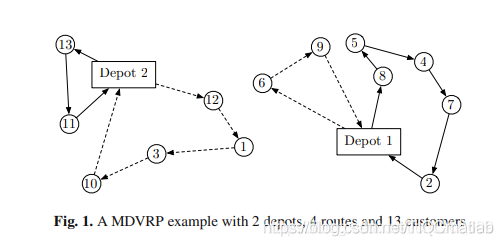
由于车辆是同质的,这里的建模在变量中没有加入车辆的维度。


(6)优先约束车辆路线问题
(7)相容性约束车辆路线问题
(8)随机需求车辆路线问题
4 解决方案
(1)数学解析法
(2)人机交互法
(3)先分组再排路线法
(4)先排路线再分组法
(5)节省或插入法
(6)改善或交换法
(7)数学规划近似法
(8)启发式算法
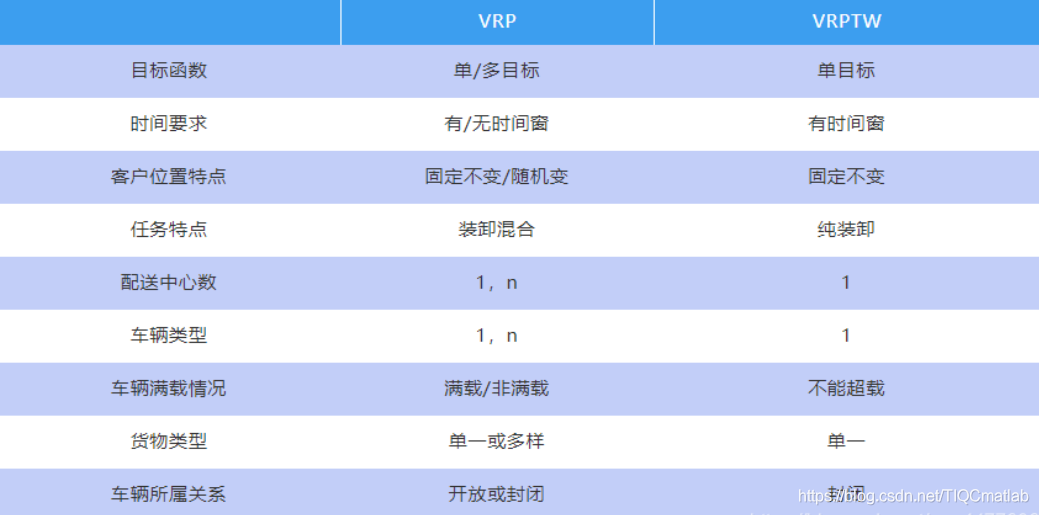
5 VRP与VRPTW对比
二、模拟退火算法简介
1 引言
模拟退火算法(Simulated Annealing,SA)的思想最早由Metropolis等人于1953年提出:Kirkpatrick于1983年第一次使用模拟退火算法求解组合最优化问题[1] 。模拟退火算法是一种基于MonteCarlo迭代求解策略的随机寻优算法, 其出发点是基于物理中固体物质的退火过程与一般组合优化问题之间的相似性。其目的在于为具有NP(Non-deterministic Polynomial) 复杂性的问题提供有效的近似求解算法,它克服了其他优化过程容易陷入局部极小的缺陷和对初值的依赖性。
模拟退火算法是一种通用的优化算法,是局部搜索算法的扩展。它不同于局部搜索算法之处是以一定的概率选择邻域中目标值大的劣质解。从理论上说,它是一种全局最优算法。模拟退火算法以优化问
题的求解与物理系统退火过程的相似性为基础, 它利用Metropolis算法并适当地控制温度的下降过程来实现模拟退火,从而达到求解全局优化问题的目的[2].
模拟退火算法是一种能应用到求最小值问题的优化过程。在此过程中,每一步更新过程的长度都与相应的参数成正比,这些参数扮演着温度的角色。与金属退火原理相类似,在开始阶段为了更快地最小
化,温度被升得很高,然后才慢慢降温以求稳定。
目前,模拟退火算法迎来了兴盛时期,无论是理论研究还是应用研究都成了十分热门的课题[3-7]。尤其是它的应用研究显得格外活跃,已在工程中得到了广泛应用,诸如生产调度、控制工程、机器学习、神经网络、模式识别、图像处理、离散/连续变量的结构优化问题等领域。它能有效地求解常规优化方法难以解决的组合优化问题和复杂函数优化问题,适用范围极广。
模拟退火算法具有十分强大的全局搜索性能,这是因为比起普通的优化搜方法,它采用了许多独特的方法和技术:在模拟退火算法中,基本不用搜索空间的知识或者其他的辅助信息,而只是定义邻域
结构,在其邻域结构内选取相邻解,再利用目标函数进行评估:模拟退火算法不是采用确定性规则,而是采用概率的变迁来指导它的搜索方向,它所采用的概率仅仅是作为一种工具来引导其搜索过程朝着更优化解的区域移动。因此,虽然看起来它是一种盲目的搜索方法,但实际上有着明确的搜索方向。
2 模拟退火算法理论
模拟退火算法以优化问题求解过程与物理退火过程之间的相似性为基础,优化的目标函数相当于金属的内能,优化问题的自变量组合状态空间相当于金属的内能状态空间,问题的求解过程就是找一个组
合状态, 使目标函数值最小。利用Me to polis算法并适当地控制温度的下降过程实现模拟退火,从而达到求解全局优化问题的目的[8].
2.1物理退火过程
模拟退火算法的核心思想与热力学的原理极为类似。在高温下,液体的大量分子彼此之间进行着相对自由移动。如果该液体慢慢地冷却,热能原子可动性就会消失。大量原子常常能够自行排列成行,形成一个纯净的晶体,该晶体在各个方向上都被完全有序地排列在几百万倍于单个原子的距离之内。对于这个系统来说,晶体状态是能量最低状态,而所有缓慢冷却的系统都可以自然达到这个最低能量状态。实际上,如果液态金属被迅速冷却,则它不会达到这一状态,而只能达到一种只有较高能量的多晶体状态或非结晶状态。因此,这一过程的本质在于缓慢地冷却,以争取足够的时间,让大量原子在丧失可动性之前进行重新分布,这是确保能量达到低能量状态所必需的条件。简单而言,物理退火过程由以下几部分组成:加温过程、等温过程和冷却过程。
加温过程
其目的是增强粒子的热运动,使其偏离平衡位置。当温度足够高时,固体将熔解为液体,从而消除系统原先可能存在的非均匀态,使随后进行的冷却过程以某一平衡态为起点。熔解过程与系统的能量增
大过程相联系,系统能量也随温度的升高而增大。
等温过程
通过物理学的知识得知,对于与周围环境交换热量而温度不变的封闭系统,系统状态的自发变化总是朝着自由能减小的方向进行:当自由能达到最小时,系统达到平衡态。
冷却过程
其目的是使粒子的热运动减弱并逐渐趋于有序,系统能量逐渐下降,从而得到低能量的晶体结构。
2.2 模拟退火原理
模拟退火算法来源于固体退火原理,将固体加温至充分高,再让其徐徐冷却。加温时,固体内部粒子随温升变为无序状,内能增大:而徐徐冷却时粒子渐趋有序,在每个温度上都达到平衡态,最后在常
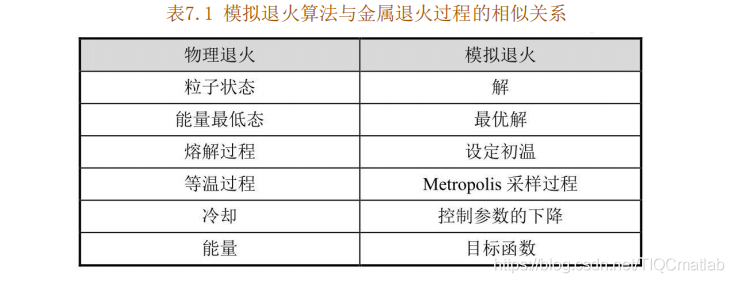
温时达到基态,内能减为最小。模拟退火算法与金属退火过程的相似关系如表7.1所示。根Metropolis准则, 粒子在温度7时趋于平衡的概率为exp(-▲E/T) , 其中E为温度7时的内能, ▲E为其改变量。用
固体退火模拟组合优化问题,将内能E模拟为目标函数值,温度7演化成控制参数,即得到解组合优化问题的模拟退火算法:由初始解%和控制参数初值7开始,对当前解重复“产生新解→计算目标函数差一接受或舍弃”的迭代,并逐步减小T值,算法终止时的当前解即为所得近似最优解, 这是基MonteCarlo迭代求解法的一种启发式随机搜索过程。退火过程由冷却进度表控制,包括控制参数的初值7及其衰
减因子K、每个7值时的迭代次数I和停止条件。
2.3 模拟退火算法思想
模拟退火的主要思想是:在搜索区间随机游走(即随机选择点),再利用Metropolis抽样准则, 使随机游走逐渐收敛于局部最优解。而温度是Metropolis算法中的一个重要控制参数,可以认为这个参数的大小控制了随机过程向局部或全局最优解移动的快慢。Metropolis是一种有效的重点抽样法, 其算法为:系统从一个能量状态变化到另一个状态时,相应的能量从E变化到E,其概率为

这样经过一定次数的迭代,系统会逐渐趋于一个稳定的分布状态。
重点抽样时,新状态下如果向下,则接受(局部最优);若向上(全局搜索),则以一定概率接受。模拟退火算法从某个初始解出发,经过大量解的变换后,可以求得给定控制参数值时组合优化问题的相对最优解。然后减小控制参数7的值, 重复执行Metropolis算法,就可以在控制参数T趋于零时,最终求得组合优化问题的整体最优解。控制参数的值必须缓慢衰减。温度是Metropolis算法的一个重要控制参数, 模拟退火可视为递减控制参数7时Metro pl is算法的迭代。开始时7值大, 可以接受较差的恶化解;随着7的减小,只能接受较好的恶化解;最后在7趋于0时,就不再接受任何恶化解了。
在无限高温时,系统立即均匀分布,接受所有提出的变换。T的衰减越小, 7到达终点的时间越长; 但可使马尔可夫(Markov) 链减小,以使到达准平衡分布的时间变短。
2.4 模拟退火算法的特点
模拟退火算法适用范围广,求得全局最优解的可靠性高,算法简单,便于实现;该算法的搜索策略有利于避免搜索过程因陷入局部最优解的缺陷,有利于提高求得全局最优解的可靠性。模拟退火算法具
有十分强的鲁棒性,这是因为比起普通的优化搜索方法,它采用许多独特的方法和技术。主要有以下几个方面:
(1)以一定的概率接受恶化解。
模拟退火算法在搜索策略上不仅引入了适当的随机因素,而且还引入了物理系统退火过程的自然机理。这种自然机理的引入,使模拟退火算法在迭代过程中不仅接受使目标函数值变“好”的点,而且还能够以一定的概率接受使目标函数值变“差”的点。迭代过程中出现的状态是随机产生的,并且不强求后一状态一定优于前一状态,接受概率随着温度的下降而逐渐减小。很多传统的优化算法往往是确定性
的,从一个搜索点到另一个搜索点的转移有确定的转移方法和转移关系,这种确定性往往可能使得搜索点远达不到最优点,因而限制了算法的应用范围。而模拟退火算法以一种概率的方式来进行搜索,增加了搜索过程的灵活性。
(2)引进算法控制参数。
引进类似于退火温度的算法控制参数,它将优化过程分成若干阶段, 并决定各个阶段下随机状态的取舍标准, 接受函数由Metropolis算法给出一个简单的数学模型。模拟退火算法有两个重要的步骤:一
是在每个控制参数下,由前迭代点出发,产生邻近的随机状态,由控制参数确定的接受准则决定此新状态的取舍,并由此形成一定长度的随机Markov链; 二是缓慢降低控制参数, 提高接受准则, 直至控制参数趋于零,状态链稳定于优化问题的最优状态,从而提高模拟退火算法全局最优解的可靠性。
(3)对目标函数要求少。
传统搜索算法不仅需要利用目标函数值,而且往往需要目标函数的导数值等其他一些辅助信息才能确定搜索方向:当这些信息不存在时,算法就失效了。而模拟退火算法不需要其他的辅助信息,而只是
定义邻域结构,在其邻域结构内选取相邻解,再用目标函数进行评估。
2.5模拟退火算法的改进方向
在确保一定要求的优化质量基础上,提高模拟退火算法的搜索效率,是对模拟退火算法改进的主要内容[9-10]。有如下可行的方案:选择合适的初始状态;设计合适的状态产生函数,使其根据搜索进程的
需要表现出状态的全空间分散性或局部区域性:设计高效的退火过程;改进对温度的控制方式:采用并行搜索结构;设计合适的算法终止准则:等等。
此外,对模拟退火算法的改进,也可通过增加某些环节来实现。
主要的改进方式有:
(1)增加记忆功能。为避免搜索过程中由于执行概率接受环节而遗失当前遇到的最优解,可通过增加存储环节,将到目前为止的最好状态存储下来。
(2)增加升温或重升温过程。在算法进程的适当时机,将温度适当提高,从而可激活各状态的接受概率,以调整搜索进程中的当前状态,避兔算法在局部极小解处停滞不前。
(3)对每一当前状态,采用多次搜索策略,以概率接受区域内的最优状态,而不是标准模拟退火算法的单次比较方式。
(4)与其他搜索机制的算法(如遗传算法、免疫算法等)相结合。可以综合其他算法的优点,提高运行效率和求解质量。
3 模拟退火算法流程
模拟退火算法新解的产生和接受可分为如下三个步骤:
(1)由一个产生函数从当前解产生一个位于解空间的新解;为便于后续的计算和接受,减少算法耗时,通常选择由当前解经过简单变换即可产生新解的方法。注意,产生新解的变换方法决定了当前新解
的邻域结构,因而对冷却进度表的选取有一定的影响。
(2)判断新解是否被接受,判断的依据是一个接受准则,最常用的接受准则是Metropolis准则:若AK 0, 则接受X作为新的当前解否则, 以概率exp(-▲E/7) 接受X”作为新的当前解X.
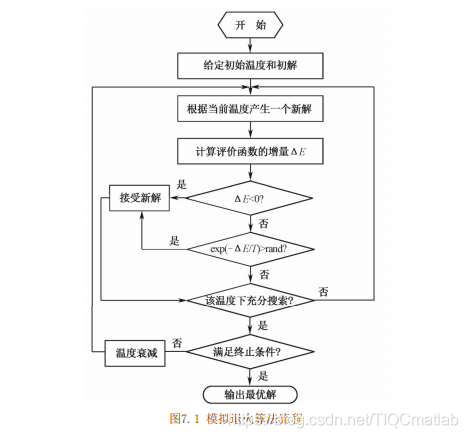
(3)当新解被确定接受时,用新解代替当前解,这只需将当前解中对应于产生新解时的变换部分予以实现,同时修正目标函数值即可。此时,当前解实现了一次迭代,可在此基础上开始下一轮试验。若当新解被判定为舍弃,则在原当前解的基础上继续下一轮试验。模拟退火算法求得的解与初始解状态(算法迭代的起点)无关,具有渐近收敛性,已在理论上被证明是一种以概率1收敛于全局最优解的优化算法。模拟退火算法可以分解为解空间、目标函数和初始解三部分。该算法具体流程如下[8]:
(1)初始化:设置初始温度7(充分大)、初始解状态%(是算
法迭代的起点)、每个7值的迭代次数L:
(2)对k=1,…,L做第(3)至第(6)步;
(3)产生新解X;
(4) 计算增量A BE(X) -E(X) , 其中E() ) 为评价函数:
(5)若AK0,则接受X作为新的当前解,否则以概率
exp(-▲E/7) 接受X作为新的当前解;
(6)如果满足终止条件,则输出当前解作为最优解,结束程序:
(7)7逐渐减小,且T→0,然后转第(2)步。
模拟退火算法流程如图7.1所示。
4 关键参数说明
模拟退火算法的性能质量高,它比较通用,而且容易实现。不过,为了得到最优解,该算法通常要求较高的初温以及足够多次的抽样,这使算法的优化时间往往过长。从算法结构知,新的状态产生函
数、初温、退温函数、Markov链长度和算法停止准则, 是直接影响算法优化结果的主要环节。
状态产生函数
设计状态产生函数应该考虑到尽可能地保证所产生的候选解遍布全部解空间。一般情况下状态产生函数由两部分组成,即产生候选解的方式和产生候选解的概率分布。候选解的产生方式由问题的性质决
定,通常在当前状态的邻域结构内以一定概率产生。
初温
温度7在算法中具有决定性的作用,它直接控制着退火的走向。由随机移动的接受准则可知:初温越大,获得高质量解的几率就越大,且Metropolis的接收率约为1。然而, 初温过高会使计算时间增加。
为此,可以均匀抽样一组状态,以各状态目标值的方差为初温。
退温函数
退温函数即温度更新函数,用于在外循环中修改温度值。目前,最常用的温度更新函数为指数退温函数, 即T(n+1) =KXT(n) , 其中0<K1是一个非常接近于1的常数。
Markov链长度L的选取
Markov链长度是在等温条件下进行迭代优化的次数, 其选取原则是在衰减参数7的衰减函数己选定的前提下,L应选得在控制参数的每一取值上都能恢复准平衡,一般L取100~1000.
算法停止准则
算法停止准则用于决定算法何时结束。可以简单地设置温度终值T,当F=T,时算法终止。然而,模拟火算法的收敛性理论中要求T趋向于零,这其实是不实际的。常用的停止准则包:设置终止温度的阈
值,设置迭代次数阈值,或者当搜索到的最优值连续保持不变时停止搜索。
三、部分源代码
%
clc;
clear;
close all;
%% Problem Definition
model=SelectModel(); % Select Model of the Problem
model.eta=0.1;
CostFunction=@(q) MyCost(q,model); % Cost Function
%% SA Parameters
MaxIt=1200; % Maximum Number of Iterations
MaxIt2=80; % Maximum Number of Inner Iterations
T0=100; % Initial Temperature
alpha=0.98; % Temperature Damping Rate
%% Initialization
% Create Initial Solution
x.Position=CreateRandomSolution(model);
[x.Cost, x.Sol]=CostFunction(x.Position);
% Update Best Solution Ever Found
BestSol=x;
% Array to Hold Best Cost Values
BestCost=zeros(MaxIt,1);
% Set Initial Temperature
T=T0;
%% SA Main Loop
for it=1:MaxIt
for it2=1:MaxIt2
% Create Neighbor
xnew.Position=CreateNeighbor(x.Position);
[xnew.Cost, xnew.Sol]=CostFunction(xnew.Position);
if xnew.Cost<=x.Cost
% xnew is better, so it is accepted
x=xnew;
else
% xnew is not better, so it is accepted conditionally
delta=xnew.Cost-x.Cost;
p=exp(-delta/T);
if rand<=p
x=xnew;
end
end
% Update Best Solution
if x.Cost<=BestSol.Cost
BestSol=x;
end
end
% Store Best Cost
BestCost(it)=BestSol.Cost;
% Display Iteration Information
if BestSol.Sol.IsFeasible
FLAG=' *';
else
FLAG='';
end
disp(['Iteration ' num2str(it) ': Best Cost = ' num2str(BestCost(it)) FLAG]);
% Reduce Temperature
T=alpha*T;
% Plot Solution
figure(1);
PlotSolution(BestSol.Sol,model);
pause(0.01);
end
%% Results
figure;
plot(BestCost,'LineWidth',2);
xlabel('Iteration');
ylabel('Best Cost');
grid on;
%
function qnew=CreateNeighbor(q)
m=randi([1 3]);
switch m
case 1
% Do Swap
qnew=Swap(q);
case 2
% Do Reversion
qnew=Reversion(q);
case 3
% Do Insertion
qnew=Insertion(q);
end
end
function qnew=Swap(q)
n=numel(q);
i=randsample(n,2);
i1=i(1);
i2=i(2);
qnew=q;
qnew([i1 i2])=q([i2 i1]);
end
function qnew=Reversion(q)
n=numel(q);
i=randsample(n,2);
i1=min(i(1),i(2));
i2=max(i(1),i(2));
qnew=q;
qnew(i1:i2)=q(i2:-1:i1);
end
function qnew=Insertion(q)
n=numel(q);
i=randsample(n,2);
i1=i(1);
i2=i(2);
if i1<i2
qnew=[q(1:i1-1) q(i1+1:i2) q(i1) q(i2+1:end)];
else
qnew=[q(1:i2) q(i1) q(i2+1:i1-1) q(i1+1:end)];
end
end
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
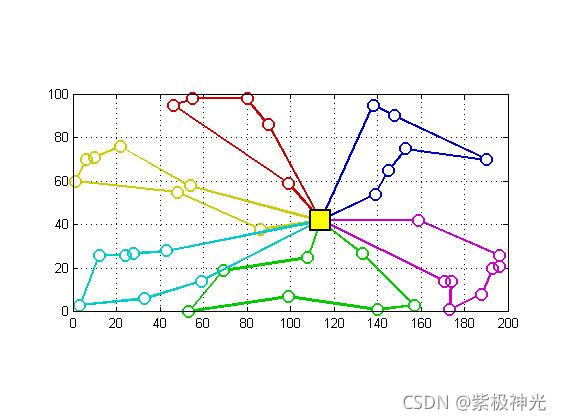
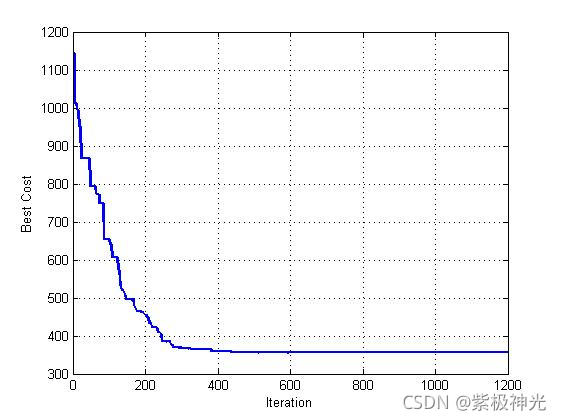
四、运行结果
五、matlab版本及参考文献
1 matlab版本
2014a
2 参考文献
[1] 包子阳,余继周,杨杉.智能优化算法及其MATLAB实例(第2版)[M].电子工业出版社,2016.
[2]张岩,吴水根.MATLAB优化算法源代码[M].清华大学出版社,2017.
文章来源: qq912100926.blog.csdn.net,作者:海神之光,版权归原作者所有,如需转载,请联系作者。
原文链接:qq912100926.blog.csdn.net/article/details/120498067

- 点赞
- 收藏
- 关注作者
评论(0)