OpenCV 的 Non Local Means(CUDA 版) 源码解析

【摘要】
效果如图:
非局部均值滤波(Non Local Means)算法其出发点是——在同一幅图像中对具有相同性质的区域进行分类并加权平均得到的图片,应该降噪效果也会越好。意味着它使用的是图像中的所有像素(实际上是在一个搜索窗口内的所有像素),这些像素根据某种相似度进行加权平均。与双线性滤波、中值滤波等利用图像局部信息来滤...
效果如图:
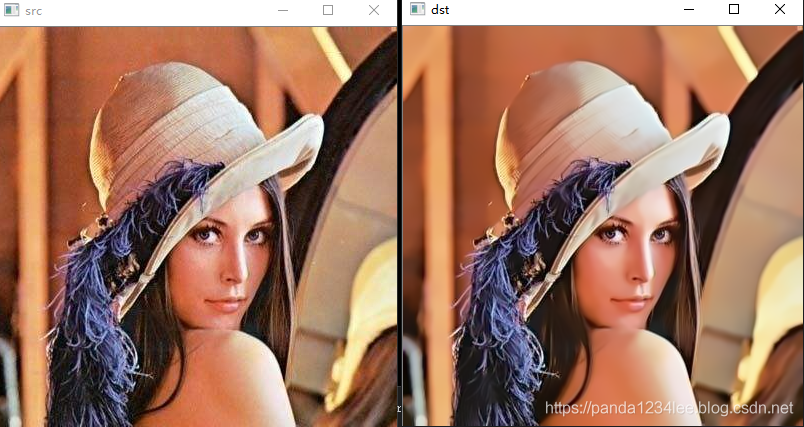
非局部均值滤波(Non Local Means)算法其出发点是——在同一幅图像中对具有相同性质的区域进行分类并加权平均得到的图片,应该降噪效果也会越好。意味着它使用的是图像中的所有像素(实际上是在一个搜索窗口内的所有像素),这些像素根据某种相似度进行加权平均。与双线性滤波、中值滤波等利用图像局部信息来滤波不同,它利用了整幅图像进行去噪。即以图像块(邻域)为单位在图像中寻找相似区域,再对这些区域取平均,较好地滤除图像中的高斯噪声。
图像邻域的相似度该怎么进行评价呢?由两两图像块(邻域)的像素颜色的欧氏距离来进行衡量,这也很容易理解,因为有噪声,单独的一个像素并不可靠,所以使用它们的邻域,只有邻域相似度高才能说这两个像素的相似度高。实际上在求欧式距离的时候,不同位置的像素的权重也是不一样的,距离块的中心越近,权重越大,距离中心越远,权重越小,权重服从高斯分布。
代码所依据的论文是

代码和注释如下(注意,src 的访问还是按照 row, col 的顺序)
-
__device__ __forceinline__ float norm2(const float& v) { return v*v; }
-
__device__ __forceinline__ float norm2(const float2& v) { return v.x*v.x + v.y*v.y; }
-
__device__ __forceinline__ float norm2(const float3& v) { return v.x*v.x + v.y*v.y + v.z*v.z; }
-
__device__ __forceinline__ float norm2(const float4& v) { return v.x*v.x + v.y*v.y + v.z*v.z + v.w*v.w; }
-
-
template<typename T, typename B>
-
__global__ void nlm_kernel(const PtrStep<T> src, PtrStepSz<T> dst, const B b, int search_radius, int block_radius, float noise_mult)
-
{
-
typedef typename TypeVec<float, VecTraits<T>::cn>::vec_type value_type;
-
-
const int i = blockDim.y * blockIdx.y + threadIdx.y;
-
const int j = blockDim.x * blockIdx.x + threadIdx.x;
-
-
if (j >= dst.cols || i >= dst.rows)
-
return;
-
-
int bsize = search_radius + block_radius;
-
int search_window = 2 * search_radius + 1;
-
float minus_search_window2_inv = -1.f/(search_window * search_window);
-
-
// value_type: 比如 float4
-
value_type sum1 = VecTraits<value_type>::all(0);
-
float sum2 = 0.f;
-
-
// 非边界情况
-
if (j - bsize >= 0 && j + bsize < dst.cols && i - bsize >= 0 && i + bsize < dst.rows)
-
{
-
// 遍历搜索窗口的像素
-
for(float y = -search_radius; y <= search_radius; ++y)
-
for(float x = -search_radius; x <= search_radius; ++x)
-
{
-
float dist2 = 0;
-
// 遍历邻域的像素
-
for(float ty = -block_radius; ty <= block_radius; ++ty)
-
for(float tx = -block_radius; tx <= block_radius; ++tx)
-
{
-
// 在搜索窗口内的邻域
-
value_type bv = saturate_cast<value_type>(src(i + y + ty, j + x + tx));
-
// 在当前像素的邻域
-
value_type av = saturate_cast<value_type>(src(i + ty, j + tx));
-
// 累加像素差分向量的内积
-
dist2 += norm2(av - bv);
-
}
-
// 计算高斯权重(搜索窗口的像素离当前像素越远,权值越小;之前统计的二范数越大,权重越小)
-
float w = __expf(dist2 * noise_mult + (x * x + y * y) * minus_search_window2_inv);
-
-
/*if (i == 255 && j == 255)
-
printf("%f %f\n", w, dist2 * minus_h2_inv + (x * x + y * y) * minus_search_window2_inv);*/
-
// 加权平均
-
sum1 = sum1 + w * saturate_cast<value_type>(src(i + y, j + x));
-
// 累加权重
-
sum2 += w;
-
}
-
}
-
else // 边界情况
-
{
-
for(float y = -search_radius; y <= search_radius; ++y)
-
for(float x = -search_radius; x <= search_radius; ++x)
-
{
-
float dist2 = 0;
-
for(float ty = -block_radius; ty <= block_radius; ++ty)
-
for(float tx = -block_radius; tx <= block_radius; ++tx)
-
{
-
//cudev::BrdConstant,
-
//cudev::BrdReplicate,
-
//cudev::BrdReflect,
-
//cudev::BrdWrap,
-
//cudev::BrdReflect101
-
// b 是 OpenCV 提供的边界处理的情况
-
value_type bv = saturate_cast<value_type>(b.at(i + y + ty, j + x + tx, src));
-
value_type av = saturate_cast<value_type>(b.at(i + ty, j + tx, src));
-
dist2 += norm2(av - bv);
-
}
-
-
float w = __expf(dist2 * noise_mult + (x * x + y * y) * minus_search_window2_inv);
-
-
sum1 = sum1 + w * saturate_cast<value_type>(b.at(i + y, j + x, src));
-
sum2 += w;
-
}
-
-
}
-
-
dst(i, j) = saturate_cast<T>(sum1 / sum2);
-
-
}
-
-
template<typename T, template <typename> class B>
-
void nlm_caller(const PtrStepSzb src, PtrStepSzb dst, int search_radius, int block_radius, float h, cudaStream_t stream)
-
{
-
dim3 block (32, 8);
-
dim3 grid (divUp (src.cols, block.x), divUp (src.rows, block.y));
-
-
// 超出边界时使用
-
B<T> b(src.rows, src.cols);
-
-
int block_window = 2 * block_radius + 1;
-
float minus_h2_inv = -1.f/(h * h * VecTraits<T>::cn);
-
float noise_mult = minus_h2_inv/(block_window * block_window);
-
-
cudaSafeCall( cudaFuncSetCacheConfig (nlm_kernel<T, B<T> >, cudaFuncCachePreferL1) );
-
nlm_kernel<<<grid, block>>>((PtrStepSz<T>)src, (PtrStepSz<T>)dst, b, search_radius, block_radius, noise_mult);
-
cudaSafeCall ( cudaGetLastError () );
-
-
if (stream == 0)
-
cudaSafeCall( cudaDeviceSynchronize() );
-
}
文章来源: panda1234lee.blog.csdn.net,作者:panda1234lee,版权归原作者所有,如需转载,请联系作者。
原文链接:panda1234lee.blog.csdn.net/article/details/88016834

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)