搞JAVA的你,怎么能没读过《Effective Java》?

写在前面
《Effective Java》读书笔记,更新中
第1章引言
第2章创建和销毁对象
第1条:用静态工厂方法代替构造器
- 静态工厂方法与构造器不同的第一大优势在于,它们有名称。
- 静态工厂方法与构造器不同的第二大优势在于,不必在每次调用它们的时候都创建一个新对象。 它从来不创建对象。 这种方法类似于享元 (Flyweight)模式 。 如果程序经常请求创建相同的对象,并且创建对象的代价 很高,则这项技术可以极大地提升性能。
public static Boolean valueOf(boolean b) {
return (b ? TRUE : FALSE);
}- 静态工厂方法与构造器不同的第三大优势在子,它们可以返回原返回类型的任何子类 型的对象。
- 静态工厂的第四大优势在于,所返回的对象的类可以随着每次调用而发生变化,这取 决于静态工厂方法的参数值。
EnumSet 没有公有的构造器,只有静态工厂方法。 在 OpenJDK 实现中, 它们返回两种子类之一的一个实例,具体则取决于底层枚举类型的大小:如果它的元素有 64 个或者更少,就像大多数枚举类型一样,静态工厂方法就会返回一个 RegalarEumSet 实例, 用单个 long 进行支持;如果枚举类型有 65 个或者更多元素,工厂就返回 JumboEnumSet 实例,用一个 long 数组进行支持。
/**
* Creates an empty enum set with the specified element type.
*
* @param <E> The class of the elements in the set
* @param elementType the class object of the element type for this enum
* set
* @return An empty enum set of the specified type.
* @throws NullPointerException if <tt>elementType</tt> is null
*/
public static <E extends Enum<E>> EnumSet<E> noneOf(Class<E> elementType) {
Enum<?>[] universe = getUniverse(elementType);
if (universe == null)
throw new ClassCastException(elementType + " not an enum");
if (universe.length <= 64)
return new RegularEnumSet<>(elementType, universe);
else
return new JumboEnumSet<>(elementType, universe);
}
在 Java 8 中仍要求接口的所有静态成员都必须是 公有的。 在 Java 9 中允许接口有私有的静态方法,但是静态域和静态成员类仍然需要是公 有的。
- 静态工厂的第五大优势在于,方法返回的对象所属的类,在编写包含该静态工厂方 法的类时可以不存在。
- 静态工厂方法的主要缺点在子,类如果不含公有的或者受保护的构造器,就不能被子 类化。
- 静态工厂方法的第二个缺点在于,程序员很难发现它们
Type 表示工厂方法所返回的对象类型,例如:
public static BufferedReader newBufferedReader(Path path, Charset cs)
throws IOException
{
CharsetDecoder decoder = cs.newDecoder();
Reader reader = new InputStreamReader(newInputStream(path), decoder);
return new BufferedReader(reader);
}/**
* Returns an array list containing the elements returned by the
* specified enumeration in the order they are returned by the
* enumeration. This method provides interoperability between
* legacy APIs that return enumerations and new APIs that require
* collections.
*
* @param <T> the class of the objects returned by the enumeration
* @param e enumeration providing elements for the returned
* array list
* @return an array list containing the elements returned
* by the specified enumeration.
* @since 1.4
* @see Enumeration
* @see ArrayList
*/
public static <T> ArrayList<T> list(Enumeration<T> e) {
ArrayList<T> l = new ArrayList<>();
while (e.hasMoreElements())
l.add(e.nextElement());
return l;
}
第2条:遇到多个构造器参数时要考虑使用构建器
静态工厂和构造器有个共同的局限性:它们都不能很好地扩展到大量的可选参数 ,
1.程序员一向习惯采用重叠构造器( telescoping constructor)模式,
简而言之,重叠构造器模式可行,但是当有许多参数的时候,客户端代码会很难缩写, 并且仍然较难以阅读。
2.JavaBeans 模式,先调用一个无参构造器来创建对象,然后再调用 setter 方法来设置每个必要的参 数,以及每个相关的可选参数:
JavaBeans 模式自身有着很严重的缺点。
因为构造过程被分到了几个调用中,在构造过程中 JavaBean 可能处于不一致的状态。 类无法仅仅通过检验构造器参数的有效性来保证一致性。 试图使用处于不一致状态的对象将会导致失败,这种失败与包含错误的代码 大相径庭,因此调试起来十分困难。 与此相关的另一点不足在于, JavaBeans 模式使得把 类做成不可变的可能性不复存在 .
package com.liruilong.common.demo;
/**
* @Auther Liruilong
* @Date 2020/8/4 12:34
* @Description:
*/
public class Demo {
private final int a;
private final int d;
private Demo(Bulider bulider) {
a = bulider.a;
d = bulider.d;
}
public static class Bulider {
private int a;
private int d;
public Bulider(int a) {
this.a = a;
}
public Demo build() {
return new Demo(this);
}
public Bulider setA(int a) {
this.a = a;
return this;
}
public Bulider setD(int d) {
this.d = d;
return this;
}
}
public static void main(String[] args) {
Demo build = new Demo.Bulider(3).setD(4).build();
}
}
注意Demo是不可变的,所有的默认参数值都单独放在个地方。builder的设值方法返回builder本身,以便把调用链接起来,得到一个流式的API。 BuiIde模式模拟了具名的可选参数。
为了简洁起见,示例中省略了有效性检查。要想尽快侦测到无效的参数,可以在builder的构造器和方法中检查参数的有效性。查看不可变量,包括build方法调用的构造器中的多个参数。为了确保这些不变量免受攻击,从builder复制完参数之后,要检查对象域(详见第50条)。如果检查失败,就抛出Il leg a lArgumen tExcept ion (详见第72条),其中的详细信息会说明哪些参数是无效的(详见第75条)
package com.liruilong.common;
import java.util.EnumSet;
import java.util.Objects;
import java.util.Set;
/**
* @Auther Liruilong
* @Date 2020/8/4 20:04
* @Description:
*/
public abstract class Pizza {
public enum Topping { HAM, MUSHROOM, ONION, PEPPER, SAUSAGE }
final Set<Topping> toppings;
abstract static class Builder<T extends Builder<T>>{
// TODO: 2020/8/4 noneOf(class <E> elementType) : 使用指定的元素类型创建一个空的枚举集
EnumSet<Topping> toppings= EnumSet.noneOf(Topping.class);
public T addTopping(Topping topping) {
// TODO: 2020/8/4 检查指定的对象引用不是 null : 检查指定的对象引用不是 null (抛异常)
toppings.add(Objects.requireNonNull(topping));
return self();
}
protected abstract T self();
}
Pizza (Builder<?> builder){
toppings = builder.toppings.clone();
}
}
Builder模式也适用于类层次结构
package com.liruilong.common;
import java.util.EnumSet;
import java.util.Objects;
import java.util.Set;
/**
* @Auther Liruilong
* @Date 2020/8/4 20:04
* @Description: 通过内部抽象类来构建成员。
*/
public abstract class Pizza {
public enum Topping {HAM, MUSHROOM, ONION, PEPPER, SAUSAGE}
final Set<Topping> toppings;
abstract static class Builder<T extends Builder<T>> {
// TODO: 2020/8/4 noneOf(class <E> elementType) : 使用指定的元素类型创建一个空的枚举集
EnumSet<Topping> toppings = EnumSet.noneOf(Topping.class);
public T addTopping(Topping topping) {
// TODO: 2020/8/4 检查指定的对象引用不是 null : 检查指定的对象引用不是 null (抛异常)
toppings.add(Objects.requireNonNull(topping));
return self();
}
protected abstract T self();
abstract Pizza build();
}
Pizza(Builder<?> builder) {
toppings = builder.toppings.clone();
}
}
Pizza.Builder的类型是泛型(generictype),带有一个递归类型参数(recursivetype parameter),详见第30条。它和抽象的self方法一样,允许在子类中适当地进行方法链接,不需要转换类型。这个针对Java缺乏self类型的解决方案,被称作模拟的self类型(simulatedself-type)。
package com.liruilong.common;
/**
* @Auther Liruilong
* @Date 2020/8/5 19:58
* @Description:
*/
public class Calzone extends Pizza {
private final boolean sauceInside;
public static class Builder extends Pizza.Builder<Builder> {
private boolean sauceInside = false; //default
public Builder sauceInside() {
sauceInside = true;
return this;
}
// TODO 方法重写 return 可以是子类型
@Override
public Calzone build() {
return new Calzone(this);
}
@Override
protected Builder self() {
return this;
}
}
private Calzone(Builder builder){
super(builder);
sauceInside = builder.sauceInside;
}
}
-------------------------------------
package com.liruilong.common;
import java.util.Objects;
/**
* @Auther Liruilong
* @Date 2020/8/5 19:47
* @Description:
*/
public class NyPizza extends Pizza {
public enum Size {SMALL, LARGE}
private final Size size;
public static class Builder extends Pizza.Builder<Builder> {
private final Size size;
public Builder(Size size) {
this.size = Objects.requireNonNull(size);
}
@Override
protected Builder self() {
return this;
}
@Override
NyPizza build() {
return new NyPizza(this);
}
}
private NyPizza(Builder builder) {
super(builder);
size = builder.size;
}
public static void main(String[] args) {
NyPizza pizza = new NyPizza.Builder(Size.SMALL).addTopping(Topping.ONION)
.addTopping(Topping.ONION).build();
Calzone calzone = new Calzone.Builder()
.addTopping(Topping.ONION).sauceInside().build();
}
}
在该方法中,子类方法声明返回超级类中声明的返回类型的子类型,这被称作协变返回类型(covariant return type)。它允许客户端无须转换类型就能使用这些构建器
- 与构造器相比,builder的微略优势在于,它可以有多个可变(varargs)参数。因为builder是利用单独的方法来设置每一个参数。
- 此外,构造器还可以将多次调用某一个方法而传人的参数集中到一个域中,如前面的调用了两次addToppiq方法的代码所示。
- Builder模式十分灵活,可以利用单个builder构建多个对象。build的参数可以在调用build方法来创建对象期间进行调整,也可以随着不同的对象而改变。
- builder可以自动填充某些域,例如每次创建对象时自动增加序列号。因此它只在有很多参数的时候才使用,比如4个或者更多个参数。
如果类的构造器或者静态工厂中具有多个参数,设计这种类时,Builde模式就是一种不错的选择,特别是当大多数参数都是可选或者类型相同的时候。与使用重叠构造器模式相比,使用Builder模式的客户端代码将更易于阅读和编写,构建器也比JavaBeans更加安全。
第3条:用私有构造器或者枚举类型强化Singleton属性
Singleton是指仅仅被实例化一次的类。Singleton通常被用来代表一个无状态的对象,如函数(详见第24条),或者那些本质上唯一的系统组件。使类成为Singleton会使它的害户端测试变得十分困难
package com.liruilong.common;
/**
* @Auther Liruilong
* @Date 2020/8/6 19:48
* @Description:
*/
public class Singleton {
public static final Singleton sin = new Singleton();
// todo 私有状态,保证全局唯一性。
/***
<p>AccessibleObject.setAccessible方法,通过反射机制(详见第65条)调用私有构造器<p/>
* @Description
* @author Liruilong
* @Date 2020年08月06日 20:08:39
**/
private Singleton(){}
public static Singleton getSin() {
return sin;
}
}
使用静态工厂的一个优势是,可以通过方法引用(method reference)作为提供者
序列化状态 添加 transient 是实例域为,并提供一个readResolve 方法
package com.liruilong.common;
import java.io.Serializable;
/**
* @Auther Liruilong
* @Date 2020/8/6 19:48
* @Description:
*/
public class Singleton implements Serializable {
//todo 序列化状态 添加 transient 是实例域为,并提供一个readResolve 方法
public transient static final Singleton sin = new Singleton();
// todo 私有状态,保证全局唯一性。
/***
<p>AccessibleObject.setAccessible方法,通过反射机制(详见第65条)调用私有构造器<p/>
* @Description
* @author Liruilong
* @Date 2020年08月06日 20:08:39
**/
private Singleton(){}
public static Singleton getSin() {
return sin;
}
public Singleton readResolve(){
return sin;
}
}
实现Singleton的第三种方法是声明一个包含单个元素的枚举类型:单元素的枚举类型经常成为实现Singleton的最佳方法。
package com.liruilong.singleton;
/**
* @Author: Liruilong
* @Date: 2019/7/20 17:55
*/
// final 不允许被继承
public final class Singleton {
// 实例变量
private byte[] bate = new byte[1024];
// 私有的构造函数,即不允许外部 new
private Singleton(){ }
/**
* @Author Liruilong
* @Description 基于枚举类线程安全
* 枚举类型不允许被继承,同样线程安全的,且只能被实例化一次。
* @Date 17:33 2019/7/26
* @Param []
* @return com.liruilong.singleton.Singleton
**/
private enum Singtetonss {
SINGTETONSS; //实例必须第一行,默认 public final static修饰
private Singleton singleton;
Singtetonss() { //构造器。默认私有
this.singleton = new Singleton();
}
public static Singleton getInstance() {
return SINGTETONSS.singleton;
}
}
public static Singleton getInstance3(){
return Singtetonss.getInstance();
}第4条 通过私有构造器强化不可实例化的能力
企图通过将类做成抽象类来强制该类不可被实例化是行不通的。该类可以被子类化,并且该子类也可以被实例化。
因此只要让这个类包含一个私有构造器,它就不能被实例化:
package com.liruilong.common;
/**
* @Auther Liruilong
* @Date 2020/8/6 20:31
* @Description:
*/
public class NoNewClass {
private NoNewClass(){
//
throw new AssertionError();
}
}
第5条:优先考虑依赖注入来引用资源
有许多类会依赖一个或多个底层的资源。例如,拼写检查器需要依赖词典。
不要用Singleton和静态工具类来实现依赖一个或多个底层资源的类,且该资源的行为会影响到该类的行为;也不要直接用这个类来创建这些资源。而应该将这些资源或者工厂传给构造器(或者静态工厂,或者构建器),通过它们来创建类。这个实践就被称作依赖注入,它极大地提升了类的灵活性、可重用性和可测试性
第6条:避免创建不必要的对象
一般来说,最好能重用单个对象,而不是在每次需要的时候就创建一个相同功能的新对象。重用方式既快速,又流行。
如果对象是不可变的(immutable)它就始终可以被重用。
对于同时提供了静态工厂方法(staticfactory method) 和构造器的不可变类,通常优先使用静态工厂方法而不是构造器
注意构造器Boolean(String)在Java9中已经被废弃了。
构造器在每次被调用的时候都会创建一个新的对象,而静态工厂方法则从来不要求这样做,实际上也不会这样做。除了重用不可变的对象之外,也可以重用那些已知不会被修改的可变对象。
public static void main(String[] args) {
// Boolean.valueOf(""); 优于 new Boolean("");
Boolean.valueOf("");
new Boolean("");
}对于字符串的正则匹配。虽然String.matches方法最易于查看一个字符串是否与正则表达式相匹配,但并不适合在注重性能的情形中重复使用
它在内部为正则表达式创建了一个Pattern实例,却只用了一次,之后就可以进行垃圾回收了。创建Patter口实例的戚本很高,因为需要将正则表达式编译成一个有限状态机(finitestate machine)。
private static final Pattern ROMAN = Pattern.compile("^(?=.)M*(C[MD]D?C{0,3})" +
"(X[CL]|L?X{0,3})(I[XV]|V?I{0,3})$");
static boolean isRomanNumeral(String s){
// 正确的写法:
ROMAN.matcher(s).matches();
return s.matches("^(?=.)M*(C[MD]D?C{0,3})" +
"(X[CL]|L?X{0,3})(I[XV]|V?I{0,3})$");
}自动装箱(autoboxing),它允许程序员将基本类型和装箱基本类型(BoxedPrimitive Type)混用,按需要自动装箱和拆箱。自动装箱使得基本类型和装箱基本类型之间的差别变得模糊起来,但是并没有完全消除 。
public static long sum(){
// long sum = 0; 比 Long 快很多
// 要优先使用基本类型,而不是封装类型,要当心无意识的使用自动装箱
Long sum = 0L;
for (long i = 0; i < Integer.MAX_VALUE; i++) {
sum += i;
}
return sum;
}第7条:消除过期的对象引用·
清空对象引用应该是一种例外,而不是一种规范行为。消除过期引用最好的方法是让包含该引用的变量结束其生命周期。如果你是在最紧凑的作用域范围内定义每一个变量(详见第57条),这种情形就会自然而然地发生
package com.liruilong.common;
import java.util.Arrays;
import java.util.EmptyStackException;
import java.util.Objects;
/**
* @Auther Liruilong
* @Date 2020/8/6 20:54
* @Description:
*/
public class Stack {
private Object[] element;
private int size = 0;
private static final int DEFAULT_INITIAL_CAPACITY = 16;
public Stack() {
this.element = new Object[DEFAULT_INITIAL_CAPACITY];
}
public void push(Object object){
ensureCapactity();
element[size++] = object;
}
public Object pop(){
if (size == 0){
throw new EmptyStackException();
}
return element[--size];
}
// TODO 程序中哪里发生了内存泄漏呢?如果一个栈先是增长,然后再收缩,
// 那么,从栈中弹出来的对象将不会被当作垃圾回收,
// 即使使用栈的程序不再引用这些对象,它们也不会被回收。
// 这是因为栈内部维护着对这些对象的过期引用(obsolete reference)。
// 所谓的过期引用,是指永远也不会再被解除的引用。
// 在本例中,凡是在elements数组的“活动部分”(active portion)之外的任何引用都是过期的。
// 活动部分是指elements中下标小于size的那些元素
private void ensureCapactity() {
if(element.length == size){
element = Arrays.copyOf(element, 2 * size + 1);
}
}
}
在支持垃圾回收的语言中,内存泄漏是很隐蔽的(称这类内存泄漏为“无意识的对象保持”(unintentionalobject retention)更为恰当)。如果一个对象引用被无意识地保留起来了,那么垃圾回收机制不仅不会处理这个对象.
public Object pop(){
if (size == 0){
throw new EmptyStackException();
}
Object result = element[--size];
element[size] = null;
return result;
}- 只要类是自己管理内存,程序员就应该警惕内存泄漏问题。
- 内存泄漏的另一个常见来源是缓存。
- 如果你正好要实现这样的缓存:只要在缓存之外存在对某个项的键的引用,该项就有意义,那么就可以用WeakHashMap代表缓存;当缓存中的项过期之后,它们就会自动被删除。记住只有当所要的缓存项的生命周期是由该键的外部引用而不是由值决定时,WeakHashMap才有用。
WeakHashMap:
public class WeakHashMap<K,V>extends AbstractMap<K,V>implements Map<K,V>以弱键 实现的基于哈希表的 Map。在 WeakHashMap 中,当某个键不再正常使用时,将自动移除其条目。更精确地说,对于一个给定的键,其映射的存在并不阻止垃圾回收器对该键的丢弃,这就使该键成为可终止的,被终止,然后被回收。丢弃某个键时,其条目从映射中有效地移除,因此,该类的行为与其他的 Map 实现有所不同。
null 值和 null 键都被支持。该类具有与 HashMap 类相似的性能特征,并具有相同的效能参数初始容量 和加载因子。
像大多数 collection 类一样,该类是不同步的。可以使用 方法来构造同步的 WeakHashMap。
该类主要与这样的键对象一起使用,其 equals 方法使用 == 运算符来测试对象标识。一旦这种键被丢弃,就永远无法再创建了,所以,过段时间后在 WeakHashMap 中查找此键是不可能的,不必对其项已移除而感到惊讶。该类十分适合与 equals 方法不是基于对象标识的键对象一起使用,比如,String 实例。然而,对于这种可重新创建的键对象,键若丢弃,就自动移除 WeakHashMap 条目,这种表现令人疑惑。
WeakHashMap 类的行为部分取决于垃圾回收器的动作,所以,几个常见的(虽然不是必需的)Map 常量不支持此类。因为垃圾回收器在任何时候都可能丢弃键,WeakHashMap 就像是一个被悄悄移除条目的未知线程。特别地,即使对 WeakHashMap 实例进行同步,并且没有调用任何赋值方法,在一段时间后 size 方法也可能返回较小的值,对于 isEmpty 方法,返回 false,然后返回 true,对于给定的键,containsKey 方法返回 true 然后返回 false,对于给定的键,get 方法返回一个值,但接着返回 null,对于以前出现在映射中的键,put 方法返回 null,而 remove 方法返回 false,对于键 set、值 collection 和条目 set 进行的检查,生成的元素数量越来越少。
WeakHashMap 中的每个键对象间接地存储为一个弱引用的指示对象。因此,不管是在映射内还是在映射之外,只有在垃圾回收器清除某个键的弱引用之后,该键才会自动移除。
实现注意事项:WeakHashMap 中的值对象由普通的强引用保持。因此应该小心谨慎,确保值对象不会直接或间接地强引用其自身的键,因为这会阻止键的丢弃。注意,值对象可以通过 WeakHashMap 本身间接引用其对应的键;这就是说,某个值对象可能强引用某个其他的键对象,而与该键对象相关联的值对象转而强引用第一个值对象的键。处理此问题的一种方法是,在插入前将值自身包装在 WeakReferences 中,如:m.put(key, new WeakReference(value)),然后,分别用 get 进行解包。
collection 的 iterator 方法所返回的迭代器(由该类所有“collection 视图方法”返回)均是快速失败的:在迭代器创建之后,如果从结构上对映射进行修改,除非通过迭代器自身的 remove 或 add 方法,其他任何时间任何方式的修改,迭代器都将抛出 。因此,面对并发的修改,迭代器很快就完全失败,而不是冒着在将来不确定的时间任意发生不确定行为的风险。
注意,迭代器的快速失败行为不能得到保证,一般来说,存在不同步的并发修改时,不可能作出任何坚决的保证。快速失败迭代器尽最大努力抛出 ConcurrentModificationException。因此,编写依赖于此异常程序的方式是错误的,正确做法是:迭代器的快速失败行为应该仅用于检测 bug。
此类是 的成员。
public static void main(String[] args) {
System.out.println(isRomanNumeral("IV"));
WeakHashMap<String, String> weakHashMap = new WeakHashMap<String, String>(){
{
for (int i = 0; i < 0 ; i++) {
put(i+"","==========="+i);
}
}
};
weakHashMap.forEach((o1,o2) -> System.out.println("原来的数据:"+o1+":"+o2));
//调用垃圾回收后没有数据
Runtime.getRuntime().gc();
System.out.println("额 ,数据呢:"+weakHashMap.get("1"));
weakHashMap.forEach((o1,o2) -> System.out.println("现在的数据:"+o1+":"+o2));
} 
![]()
缓存应该时不时地清除掉没用的项。这项清除工作可以由一个后台线程(可能是ScheduledThreadPoolExecutor)[在给定延时后执行异步任务或者周期性执行任务]来完成,或者也可以在给缓存添加新条目的时候顺便进行清理。LinkedHashMap类利用它的removeEldestEntry方法可以很容易地实现后一种方案。对于更加复杂的缓存,必须直接使用java.lang.ref
- 内存泄漏的第三个常见来源是监昕器和其他回调。
如果你实现了一个API,客户端在这个API中注册回调,却没有显式地取消注册,那么除非你采取某些动作,否则它们就会不断地堆积起来。确保回调立即被当作垃圾回收的最佳方法是只保存它们的弱引用(weakreference),例如,只将它们保存成WeakHashMap中的键.
package com.liruilong.common.util;
import java.util.Map;
import java.util.Objects;
import java.util.WeakHashMap;
import java.util.concurrent.ConcurrentHashMap;
/**
* @Author Liruilong
* @Date 2020/8/11 09:37
* @Description: 基于 WeakHashMap 的缓存实现
*/
public class WeakHashMapCache<K,V> {
private final int size;
private final Map<K,V> eden;
private final Map<K,V> longterm;
private WeakHashMapCache(Builder<K,V> builder){
this.size = builder.size;
this.eden = builder.eden;
this.longterm = builder.longterm;
}
public static class Builder<K,V>{
private volatile int size;
private volatile Map<K,V> eden;
private volatile Map<K,V> longterm;
public Builder(int size){
this.size = rangeCheck(size,Integer.MAX_VALUE,"缓存容器初始化容量异常");
this.eden = new ConcurrentHashMap<>(size);
this.longterm = new WeakHashMap<>(size);
}
private static int rangeCheck(int val, int i, String arg) {
if (val < 0 || val > i) {
throw new IllegalArgumentException(arg + ":" + val);
}
return val;
}
public WeakHashMapCache build(){
return new WeakHashMapCache(this);
}
}
public V get(K k){
V v = this.eden.get(k);
if (Objects.isNull(v)){
v = this.longterm.get(k);
if (Objects.nonNull(v)){
this.eden.put(k,v);
}
}
return v;
}
public void put(K k,V v){
if (this.eden.size() >= size){
this.longterm.putAll(this.eden);
this.eden.clear();
}
this.eden.put(k,v);
}
public static void main(String[] args) {
WeakHashMapCache cache = new WeakHashMapCache.Builder<String,String>(3).build();
for (int i = 0; i < 5; i++) {
cache.put(i+"",i+"");
}
System.gc();
for (int i = 0; i < 5; i++) {
System.out.println(cache.get(i + ""));
}
}
}
--- Ajax请求之后的数据会一直保存在内存中,等待下一次请求覆盖掉,还是会直接被js回收掉??
借助于Heap剖析工具(HeapProfiler)才能发现内存泄漏问题
第8条:避免使用终结方法和清除方法
终结方法(finalize「)通常是不可预测的,也是很危险的,一般情况下是不必要的,
在Java9 中用清除方法(cleaner)代替了终结方法。清除方法没有终结方法那么危险,但仍然是不可预测、运行缓慢,一般情况下也是不必要的
终结方法和清除方法的缺点在于不能保证会被及时执行。从一个对象变得不可到达开始,到它的终结方法被执行,所花费的这段时间是任意长的。这意味着,注重时间的任务不应该由终结方法或者清除方法来完成
终结方法线程的优先级比该应用程序的其他线程的优先级要低得多。
永远不应该依赖终结方法或者清除方法来更新重要的持久状态,不要被System.gc和System.runFinalization这两个方法所诱惑。
第9条: try-with-resources优先于try-finally
当Java7引人try-with-sources语句。要使用这个构造的资源,必须先实现AutoCloseable接口,其中包含了单个返回void的close方法。Java类库与第三方类库中的许多类和接口,现在都实现或扩展了AutoCloseable接口。如果编写了一个类,它代表的是必须被关闭的资源,那么这个类也应该实现AutoCloseable。当使用java7的写法时,可以主动的关闭资源。
public class Stack extends Exception implements AutoCloseable {
@Override
public void close() throws Exception {
System.out.println("资源关闭");
}
public static void main(String[] args) {
try(Stack stack = new Stack()){
stack.push("嘻嘻,加油");
System.out.println(stack.pop());
} catch (Exception e) {
e.printStackTrace();
}
}
}嘻嘻,加油
资源关闭第3章对于所有对象都通用的方法
Object所有的非final方法(equals、hashCode、toString、clone和finalize)都有明确的通用约定(general contract), 因为它们设计成是要被覆盖(override)的。任何一个类,它在覆盖这些方法的时·候,都有责任遵守这些通用约定;如果不能做到这一点,其他依赖于这些约定的类(例如HashMap和HashSet)就无法结合该类一起正常运作。
第10条:覆盖equals时请遵守通用约定
- 类的每个实例本质上都是唯一的。
- 类没有必要提供“逻辑相等”(logical equality)的测试功能
- 超类已经覆盖了equals,超类的行为对于这个类也是合适的
- 类是私有的,或者是包级私有的,可以确定它的equals方法永远不会被调用
什么时候应该覆盖equals方法呢?
有一种“值类”不需要覆盖equals方法,即用实例受控确保“每个值至多只存在一个对象”的类。枚举类型(详见第34条)就属于这种类。对于这样的类而言,逻辑相同与对象等同是一回事,因此Object的equals方法等同于逻辑意义上的equals方法
如果类具有自己特有的“逻辑相等”(logicalequality)概念(不同于对象等同的概念),而且超类还没有覆盖equals。这通常属于“值类”(value class)的情形。值类仅仅是一个表示值的类。
五个要求:
- 自反性(Reflexivity)
- 对称性(Symmetry)
- 传递性(Transitivity)平行性
- 一致性(Consistency)
- 非空性(Non-nullity)
在equals方法中用getClass测试代替instanceof测试,可以扩展可实例化的类和增加新的值组件,同时保留equals约定的不可行性。
我们无法在扩展可实例化的类的同时,既增加新的值组件,同时又保留equals约定
方法:
- 使用==操作符检查“参数是否为这个对象的引用”
- 使用instanceof操作符检查“参数是否为正确的类型”为空。
- 把参数转换成正确的类型
- 对于该类中的每个“关键”(significant )域,检查参数中的域是否与该对象中对应的域相匹配。
- 在编写完equals方法之后,应该问自己三个问题:它是否是对称的、传递的、一致的?
注意:
- 覆盖equals时总要覆盖hashCode
- 不要企图让equals方法过于智能
- 不要将equals声明中的Object对象替换为其他的类型:这个方法并没有覆盖(override)Object. equals,因为它的参数应该是Object类型,相反,它重载(overload)了Object.equals 。
- 里氏替换原则(Liskov substitution principle)认为,一个类型的任何重要属性也将适用于它的子类型,
package com.liruilong.common;
import java.util.Objects;
/**
* @Author Liruilong
* @Date 2020/8/8 17:25
* @Description:
*/
public class PhoneNumber {
private final short areaCode, prefix, lineNum;
public PhoneNumber(int areaCode, int prefix, int lineNum) {
this.areaCode = rangeChek(areaCode, 999, "area code");
this.prefix = rangeChek(prefix,999,"pre fix");
this.lineNum = rangeChek(lineNum,999,"lineNum");
}
private static short rangeChek(int val, int i, String arg) {
if (val < 0 || val > i) {
throw new IllegalArgumentException(arg + ":" + val);
}
return (short) val;
}
/**
* @param o
* @return boolean
* @Description
* 使用==操作符检查“参数是否为这个对象的引用”
* 使用instanceof操作符检查“参数是否为正确的类型”为空。
* 把参数转换成正确的类型
* 对于该类中的每个“关键”(significant )域,检查参数中的域是否与该对象中对应的域相匹配。
* @author Liruilong
* @Date 2020年08月08日 17:08:46
**/
@Override
public boolean equals(Object o) {
// 使用==操作符检查“参数是否为这个对象的引用”
if (this == o) {
return true;
}
// 使用instanceof操作符检查“参数是否为正确的类型”为空。测试等同性的同时,测试非空性。
if (!(o instanceof PhoneNumber)) {
return false;
}
// 把参数转换成正确的类型
PhoneNumber that = (PhoneNumber) o;
// 对于该类中的每个“关键”(significant )域,检查参数中的域是否与该对象中对应的域相匹配。
return areaCode == that.areaCode &&
prefix == that.prefix &&
lineNum == that.lineNum;
}
@Override
public int hashCode() {
return Objects.hash(areaCode, prefix, lineNum);
}
}
第11条:覆盖equals时总要覆盖hashCode
在每个覆盖了equals方法的类中,都必须覆盖hashCode方法。如果不这样做的话,就会违反hashCode的通用约定,从而导致该类无法结合所有基于散列的集合一起正常运作,这类集合包括HashMap和HashSet。

![]()
因没有覆盖hashCode而违反的关键约定是第二条:相等的对象必须具有相等的散到码(hashcode )。
@Override
public int hashCode() {
return Objects.hash(areaCode, prefix, lineNum);
}
//---------------------------
public static int hash(Object... values) {
return Arrays.hashCode(values);
}
//---------------------------
public static int hashCode(Object a[]) {
if (a == null)
return 0;
int result = 1;
for (Object element : a)
result = 31 * result + (element == null ? 0 : element.hashCode());
return result;
}第12条:始终要覆盖toString
提供好的t。String实现可以便类用起来更加舒适,使用了这个类的系统也更易于调试。
@Override
public String toString() {
return "PhoneNumber{" +
"areaCode=" + areaCode +
", prefix=" + prefix +
", lineNum=" + lineNum +
'}';
}
public static void main(String[] args) {
PhoneNumber phoneNumber = new PhoneNumber(12,23,34);
System.out.println(phoneNumber);
}com.liruilong.common.PhoneNumber@a456
PhoneNumber{areaCode=12, prefix=23, lineNum=34}在实际应用中,toString方法应该返回对象中包含的所有值得关注的信息,
public static void main(String[] args) {
PhoneNumber phoneNumber = new PhoneNumber(12,212323,34);
System.out.println(phoneNumber);
}要在你编写的每一个可实例化的类中覆盖Object的toString实现,除非已经在超类中这么做了。这样会使类使用起来更加舒适,也更易于调试。toString方法应该以美观的格式返回一个关于对象的简洁、有用的描述。
Exception in thread "main" java.lang.IllegalArgumentException: pre fix:212323
at com.liruilong.common.PhoneNumber.rangeChek(PhoneNumber.java:21)
at com.liruilong.common.PhoneNumber.<init>(PhoneNumber.java:15)
at com.liruilong.common.PhoneNumber.main(PhoneNumber.java:70)制定格式:
// 无论是否决定指定格式,都应该在文档中明确地表明你的意图
@Override
public String toString() {
return String.format("%03d-%03d-%04d",areaCode,prefix,lineNum);
}012-045-0034第13条:谨慎地覆盖clone
Cloneable接口的目的是作为一个标注接口。表明该类的实例允许克隆。
事实上,实现Cloneable接口的类是为了提供一个功能适当的公有的clone方法。
package com.liruilong.common;
import java.util.Objects;
/**
* @Author Liruilong
* @Date 2020/8/8 17:25
* @Description:
*/
public class PhoneNumber implements Cloneable{
@Override
protected PhoneNumber clone() throws CloneNotSupportedException {
try {
return ((PhoneNumber) super.clone());
}catch (CloneNotSupportedException e){
throw new AssertionError();
}
}
}因为Java支持协变返回类型(covariant return type)。换句话说,目前覆盖方法的返回类型可以是被覆盖方法的返回类型的子类了.
/* @return a clone of this instance.
* @throws CloneNotSupportedException if the object's class does not
* support the {@code Cloneable} interface. Subclasses
* that override the {@code clone} method can also
* throw this exception to indicate that an instance cannot
* be cloned.
* @see java.lang.Cloneable
*/
protected native Object clone() throws CloneNotSupportedException;对super.clone方法的调用应当包含在一个try-catch块中。这是因为Object声明其clone方法抛出CloneNotSupportedException,这是一个受检异常(checkedexception)。由于PhoneNumber实现了Cloneable接口
对于域中包含引用类的对象。
实际上,clone方法就是另一个构造器;必须确保它不会伤害到原始的对象,并确保正确地创建被克隆对象中的约束条件
Cloneable架构与引用可变对象的final域的正常用法是不相兼容的,
对象拷贝的更好的办法是提供一个拷贝构造器(copyconstructo「)或拷贝工厂(copy factory )。
总之,复制功能最好由构造器或者工厂提供。这条规则最绝对的例外是数组,最好利用clone方法复制数组。
第14条:考虑实现Comparable接口
compareTo方法并没有在Object类中声明。相反,它是Comparable接口中唯一的方法。将这个对象与指定的对象进行比较。当该对象小于、等于或大于指定对象的时候,分别返回一个负整数、零或者正整数。如果由于指定对象的类型而无法与该对象进行比较,则抛出ClassCastException异常
public interface Comparable<T> {
/* @param o the object to be compared.
* @return a negative integer, zero, or a positive integer as this object
* is less than, equal to, or greater than the specified object.
*
* @throws NullPointerException if the specified object is null
* @throws ClassCastException if the specified object's type prevents it
* from being compared to this object.
*/
public int compareTo(T o);
}compareTo方法不但允许进行简单的等同性比较,而且允许执行顺序比较,除此之外,它与Object的equals方法具有相似的特征,它还是个泛型(generic)。
类实现了Comparable接口,就表明它的实例具有内在的排序关系( natural ordering)。为实现Comparable接口的对象数组进行排序就这么简单。
Arrays.sort(new PhoneNumber[]{new PhoneNumber(12,23,34)});在compareTo方法中使用关系操作符〈和〉是非常烦琐的,并且容易出错,因此不再建议使用。
public static void main(String[] args) {
Demo build = new Bulider(3).setD(4).build();
Set<String> s = new TreeSet<String>();
Collections.addAll(s,args);
} Java 平台类库中的所有值类( value classes), 以及所有的枚 举类型(详见第 34 条)都实现了 Comparable 接口 。 如果你正在编写一个值类,它具有非 常明显的内在排序关系,比如按字母顺序、按数值顺序或者按年代顺序,那你就应该坚决考虑实现 Comparable 接口:
在 Java 8 中, Comparator 接口配置了一组 比较器构造方法 ( comparator construction methods),使得 比较器的构造工作变得非常流畅。 之后,按照 Comparable 接口 的要求, 这些比较器可以用来实现一个 compareTo 方法
static Comparator<Object> hashObject = new Comparator<Object>() {
public int compare(Object o1, Object o2) {
return o1.hashCode() -o2.hashCode();
}
};
static Comparator<Object> hashObjects = Comparator.comparingInt(( o) ->o.hashCode()); private static final Comparator<PhoneNumber> COMPARATOR = Comparator
.comparingInt((PhoneNumber phoneNumber) ->phoneNumber.areaCode)
.thenComparingInt((phoneNumber) ->phoneNumber.lineNum);第4章类和接口
第15条:使类和成员的可访问性最小化
区分一个组件设计得好不好,唯一重要的因素在于,它对于外部的其他组件而言,是 否隐藏了其内部数据和其他实现细节。
设计良好的组件会隐藏所有的实现细节, 把API 与 实现清晰地隔离开来。 然后,组件之间只通过 API 进行通信,一个模块不需要知道其他模 块的内部工作情况。
这个概念被称为信息隐藏( info1mation hiding)或封装( encapsulation), 是软件设计的基本原则之一。
它可以有效地解除组成系统 的各组件之间的藕合关系,即解相( decouple),使得这些组件可以独立地开发、 测试、优 化、使用、理解和修改。 因为这些组件可以并行开发,
Java 提供了许多机制(facility)来协助信息隐藏。 访问控制(access control)机制决定了类、接口和成员的可访问性( accessibility)
实体的可访问性是由该实体声明所 在的位置,以及该实体声明中所出现的访问修饰符( private 、 protected 和 public) 共同决定的。
尽可能地使每个类或者成员不被外界访问。 换句话说,应该使用与你 在编写的软件的对应功能相一致的、 尽可能最小的访问级别。
对于顶层的(非嵌套的)类和接口,只有两种可能的访问级别:包级私有的( packageprivat巳)和公有的( public)。 如果你用 public 修饰符声明了顶层类或者接口,那它就是公有 的;否则,它将是包级私有的。
包级私有:如果类或者接口能够被做成包级私有的,它就应该被做成包 级私有。 通过把类或者接口做成包级私有,它实际上成了这个包的实现的一部分,而不是该包导出的 API 的一部分,在以后的发行版本中,可以对它进行修改、替换或者删除,而无 须担心会影响到现有的客户端程序。 如果把它做成公有的,你就有责任永远支持它,以保持 它们的兼容性。
私有嵌套类:如果一个包级私有的顶层类(或者接口) 只是在某一个类的内部被用到,就应该考虑使 它成为唯一使用它的那个类的私有嵌套类(详见第 24 条)。 这样可以将它的可访问范围从包 中的所有类缩小到使用它的那个类。
降低不必要公有类的可访问性,比降低包级私有 的顶层类的可访问性重要得多:
对于成员(域、方法、嵌套类和嵌套接口)有四种可能的访问级别,下面按照可访问性 的递增顺序罗列出来:
- 私有的 (private) 一-只有在声明该成员的顶层类内部才可以访问这个成员 。
- 包级私有的 ( package-private) 一一声明该成员的包内部的任何类都可以访问这个 成员 。 从技术上讲,它被称为“缺省”( default)访问级别,如果没有为成员指定访 问修饰符,就采用这个访问级别(当然,接口成员除外,它们默认的访问级别是公 有的)。
- 受保护的 ( protected) 一一声明该成员的类的子类可以访问这个成员(但有一些限制 [ JLS. 6.6.2 ]),并且声明该成员的包内部的任何类也可以访问这个成员。
- 公有的 (public) -一在任何地方都可以访问该成员。
当你仔细地设计了类的公有 API 之后,可能觉得应该把所有其他的成员都变成私有 的。 其实,只有当同一个包内的另一个类真正需要访问一个成员的时候,你才应该删除 private 修饰符,使该成员变成包级私有的。
私有成员和包级私有成员都是一个类的实现中的一部分,一般不会影响导出 的 API。 然而,如果这个类实现了 Serializable 接口(详见第 86 条和第 87 条),这些域就有可能会被“泄漏”(leak)到导出的 API 中。
对于公有类的成员,当访问级别从包级私有变成保护级别时,会大大增强可访问性。 受保护的成员是类的导出的 API 的一部分,必须永远得到支持。 导出的类的受保护成员也 代表了该类对于某个实现细节的公开承诺(详见第四条)。 应该尽量少用受保护的成员 。
有一条规则限制了降低方法的可访问性的能力。 如果方法覆盖了超类中的一个方法, 子类中的访问级别就不允许低于超类中的访问级别 。 这样可以确保任何可使用超类的实例的地方也都可以使用子类的实例(里氏替换原则,详见第 10 条)。 如果违反 了这条规则,那么当你试图编译该子类的时候,编译器就会产生一条错误消息。
这条规则有 一个特例:如果一个类实现了一个接口,那么接口中所有的方法在这个类中也都必须被声明 为公有的。
如果实例域是非 final 的,或者是一 个指向可变对象的 final 引用, 那么一旦使这个域成为公有的,就等于放弃了对存储在这个 域中的值进行限制的能力;这意味着,你也放弃了强制这个域不可变的能力。 同时,当这个 域被修改的时候,你也失去了对它采取任何行动的能力。
因此, 包含公有可变域的类通常并 不是线程安全的。 即使域是 final 的,并且引用不可变的对象,但当把这个域变成公有的时 候,也就放弃了“切换到一种新的内部数据表示法”的灵活性。
如果 final 域包含可变对 象的引用,它便具有非 final 域的所有缺点。 虽然引用本身不能被修改,但是它所引用的对 象却可以被修改,这会导致灾难性的后果。 注意,长度非零的数组总是可变的,所以让类具有公有的静态 final 数组域,或者返回 这种域的访问方法,这是错误的。 如果类具有这样的域或者访问方法,客户端将能够修改数 组中的内容。 这是安全漏洞的一个常见根源:
修正这个问题有两种方法。 可以使公有数组变成私有的,并增加一个公有的不可变 列表:
另一种方法是,也可以使数组变成私有的,并添加一个公有方法,它返回私有数组的 一个拷贝 :
package com.liruilong.common.util;
import java.util.Arrays;
import java.util.List;
/**
* @author Liruilong
* @Date 2020/8/22 14:02
* @Description:
*/
public class Demo {
// 长度为零的数组总数可变的
public static final String[] VALUE ={};
// 方法一
private static final String [] PRAVATE_VALUES = {};
public static final List<String> VALUES = Arrays.asList(PRAVATE_VALUES);
// 方法二
public static final String[] value(){
return PRAVATE_VALUES.clone();
}
}
从 Java 9 开始,又新增了两种隐式访问级别,作为模块系统( module system)的一部 分。
一个模块就是一组包,就像一个包就是一组类一样。 模块可以通过其模块声明( module declaration)中的导出声明 ( export declaration) 显式地导出它的一部分包(按照惯例,这包含在名为 module-info.java 的源文件中)。
模块中未被导出的包在模块之外是不可访问 的;在模块内部,可访问性不受导出声明的影响。 使用模块系统可以在模块内部的包之间共 享类,不用让它们对全世界都可见。 未导出的包中公有类的公有成员和受保护的成员都提 高了两个隐式访问级别,这是正常的公有和受保护级别在模块内部的对等体( intramodular analogues)。 对于这种共享的需求相对罕见,经常通过在包内部重新安排类来解决。
总而言之,应该始终尽可能(合理)地降低程序元素的可访问性。 在仔细地设计了一个 最小的公有 API 之后,应该防止把任何散乱的类、接口或者成员变成 API 的一部分。 除了 公有静态 final 域的特殊情形之外(此时它们充当常量),公有类都不应该包含公有域,并且 要确保公有静态 final 域所引用的对象都是不可变的。
第16条:要在公有类而非公有域中使用访问
如果类可以在 它所在的包之外进行访问,就提供访问方法,。
如果类是包级私有的,或者是私有的嵌套类, 直接暴露它的数据域并没有本质 的错误。
公有类永远都不应该暴露可变的域。 虽然还是有问题,但是让公有类暴露 不可变的域,其危害相对来说比较小。 但有时候会需要用包级私有的或者私有的嵌套类来暴 露域,无论这个类是可变的还是不可变的。
第17条:使可变性最小化
不可变类是指其实例不能被修改的类。
每个实例中包含的所有信息都必须在创建该实例的时候就提供,并在对象的整个生命周期( lifetime)内固定不变。 Java 平台类库中包含许 多不可变的类,
有 String 、基本类型的包装类、 Biginteger 和 BigDecimal。 存在不可变的类有许多理由:不可变的类比可变类更加易于设计、实现和使用。 它们不容易出 错,且更加安全。
为了使类成为不可变,要遵循下面五条规则:
1. 不要提供任何会修改对象状态的方法 (也称为设值方法)。
2. 保证类不会被扩展。
3. 声明所有的域都是 final 的。 通过系统的强制方式可以清楚地表明你的意图。
4. 声明所有的域都为私有的。 这样可以防止客户端获得访问被域引用的可变对象的权限,
5.确保对于任何可变组件的互斥访问。如果类具有指向可变对象的域,则必须确保该 类的客户端无法获得指向这些对象的引用。
不可变对象本质上是线程安全的,它们不要求同步。 当多个线程并发访问这样的对象 时它们不会遭到破坏。 这无疑是获得线程安全最容易的办法。 实际上,没有任何线程会注意到其他线程对于不可变对象的影响。 所以, 不可变对象可以被自由地共享。 不可变类应该 充分利用这种优势,鼓励客户端尽可能地重用现有的实例。
- 永远也不需要进行保护性拷贝(defensive copy) 。
- 不仅可以共享不可变对象,甚至也可以共享它们的内部信息。
- 不可变对象为其他对象提供了大量的构件 。
- 不可变对象无偿地提供了失败的原子性
- 不可变类真正唯一的缺点是 , 对于每个不同的值都需要一个单独的对象
除非有很好的理由要让类 成为可变的类,否则它就应该是不可变的。
如果类不能被做成不可变的,仍然应该 尽可能地限制它的可变性。
除非有令人信服的理由要 使域变成是非 final 的,否则要使每个域都是 private final 的。 构造器应该创建完全初始化的对象,并建立起所有的约束关系。
第18条:复合优先于继承
继承( inheritanc巳)是实现代码重用的有力手段,但它并非永远是完成这项工作的最佳工具。
与方法调用不同的是,继承打破了封装性[ Snyder86 ]。 换句话说,子类依赖于其超 类中特定功能的实现细节。 超类的实现有可能会随着发行版本的不同而有所变化,如果真的 发生了变化,子类可能会遭到破坏,即使它的代码完全没有改变。 因而,子类必须要跟着其 超类的更新而演变,除非超类是专门为了扩展而设计的,并且具有很好的文挡说明。 为了说明得更加具体一点,我们假设有一个程序使用了 HashSet。 为了调优该程序的性能,需要查询 HashSet ,看一看自从它被创建以来添加了多少个元素(不要与它当前的 元素数目泪淆起来, 它会随着元素的删除而递减)。 为了提供这种功能,我们得编写一个 HashSet 变体,定义记录试图插入的元素的数量 addCount,井针对该计数值导出一个访问 方法。 HashSet 类包含两个可以增加元素的方法: add 和 addAll ,因此这两个方法都要 被覆盖:
package com.liruilong.common.util;
import java.util.*;
/**
* @author Liruilong
* @Date 2020/8/22 14:02
* @Description:
*/
public class InstrumentedHashSet<E> extends HashSet<E>{
private int addCount = 0;
public InstrumentedHashSet() {
}
public InstrumentedHashSet(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
}
@Override
public boolean add(E e) {
addCount++;
return super.add(e);
}
@Override
public boolean addAll(Collection<? extends E> c) {
addCount += c.size();
return super.addAll(c);
}
public int getAddCount(){
return addCount;
}
}在 HashSet 的 内 部, addAll 方法是基于它的 add 方法来实现的

![]()
即不扩展现有的类,而是在新 的类中增加一个私有域,它引用现有类的一个实例。 这种设计被称为“复合”(composition), 因为现有的类变成了新类的一个组件。 新类中的每个实例方法都可以调用被包含的现有类 实例中对应的方法,并返回它的结果。 这被称为转发( forwarding)
类本身和可重用的转发类( forwarding class),其中包含了所有的转发方法,没有任何其 他的方法:
package com.liruilong.common.util.ziptar;
import org.jetbrains.annotations.NotNull;
import java.util.Collection;
import java.util.Iterator;
import java.util.Set;
/**
* @author Liruilong
* @Date 2020/8/22 17:02
* @Description:
*/
public class ForwardingSet<E> implements Set<E> {
private final Set<E> s;
public ForwardingSet(Set<E> s) {
this.s = s;
}
@Override
public int size() {
return s.size();
}
@Override
public boolean isEmpty() {
return s.isEmpty();
}
@Override
public boolean contains(Object o) {
return s.contains(o);
}
package com.liruilong.common.util;
import com.liruilong.common.util.ziptar.ForwardingSet;
import java.util.*;
/**
* @author Liruilong
* @Date 2020/8/22 14:02
* @Description:
*/
public class InstrumentedHashSet<E> extends ForwardingSet<E> {
private int addCount = 0;
public InstrumentedHashSet(Set<E> s) {
super(s);
}
@Override
public boolean add(E e) {
addCount++;
return super.add(e);
}
@Override
public boolean addAll(Collection<? extends E> c) {
addCount += c.size();
return super.addAll(c);
}
public int getAddCount(){
return addCount;
}
}因为每一个 InstrumentedSet 实例都把另一个 Set 实例包装起来了,所以 InstrumentedSet 类被称为包装类(wrapper class)。 这也正是 Decorator(修饰者)模式 。
因为 InstrumentedSet 类对一个集合进行了修饰,为它增加了计数特性。 有时复合和转 发的结合也被宽松地称为“委托” ( d巳legatio口)。 从技术的角度而言,这不是委托,除非包装 对象把自身传递给被包装的对象
包装类几乎没有什么缺点。 需要注意的一点是, 包装类不适合用于回调框架。Guava 就为所有的集合接口提供了转发类 。
只有当子类真正是超类的子类型( subtyp巳)时,才适合用继承。 换句话说,对于两个类 A 和 B,只有当两者之间确实存在“ is-a”关系的时候,类 B 才应该扩展类 A。
继承的功能非常强大,但是也存在诸多问题,因为它违背了封装原则。 只 有当子类和超类之间确实存在子类型关系时,使用继承才是恰当的。 即使如此,如果子 类和超类处在不同的包中,并且超类并不是为了继承而设计的,那么继承将会导致脆弱性 ( fragility)。 为了避免这种脆弱性,可以用复合和转发机制来代替继承,尤其是当存在适当 的接口可以实现包装类的时候。 包装类不仅比子类更加健壮,而且功能也更加强大。
第19条:要么设计继承并提供文档说明,要么禁止继承。
该类的文档必须精确地描述覆盖每个方法所带来的影响。 换句话说, 该类必须 有文档说明它可覆盖( ove「「idable )的方法的自用性( se协use )。
好的 API 文档应该描述一个给定的方法做了什么工作,而不 是描述它是如何做到的。
对于为了继承而设计的类,唯一的测试方法就是编写子类。
必须在发布类之前先编写子类对类进行测试。
为了允许继承,类还必须遵守其他一些约束。 构造器决不能调用可被覆盖的方法, 无论是直接调用还是间接调用。 如果违反了这条规则,很有可能导致程序失败。 超类的构造器 在子类的构造器之前运行,所以,子类中覆盖版本的方法将会在子类的构造器运行之前先被 调用。 如果该覆盖版本的方法依赖于子类构造器所执行的任何初始化工作,该方法将不会如 预期般执行。
构造器决不能调用可被覆盖的方法,
package com.liruilong;
/**
* @author Liruilong
* @Date 2020/8/29 19:31
* @Description:
*/
public class Super {
public Super() {
overrideMe();
}
public void overrideMe() {
}
}
package com.liruilong.fserve;
import com.liruilong.Super;
import java.time.Instant;
/**
* @author Liruilong
* @Date 2020/8/29 19:32
* @Description:
*/
public final class Sub extends Super {
private final Instant instant;
Sub() {
instant = Instant.now();
}
@Override
public void overrideMe() {
System.out.println(instant);
}
public static void main(String[] args) {
Sub sub = new Sub();
sub.overrideMe();
}
}
无论是 clone 还是readObject, 都不可以调用可覆盖的方 法,不管是以直接还是间接的方式。
对于 readObject 方法,覆盖的方法将在子类的状态 被反序列化 ( deserialized)之前先被运行;而对于 clone 方法,覆盖的方法则是在子类的 clone 方法有机会修正被克隆对象的状态之前先被运行。
如果你决定在一个为了继承而设计的类中实现 Serializable 接口,并且该类 有一个 readResolve 或者 writeReplace 方法,就必须使 readResolve 或者 wr工teReplace 成为受保护的方法,而不是私有的方法。 如果这些方法是私有的,那么子类将会 不声不响地忽略掉这两个方法。 这正是“为了允许继承, 而把实现细节变成一个类的 API 的一部分”的另一种情形。
为了继承而设计类,对这个类会有一些实质性的限 制。
这个问题的最佳解决方案是,对于那些并非为了安全地进行子类化而设计和编写文 档的类,要禁止子类化。
专门为了继承而设计类是一件很辛苦的工作。 你必须建立文档说明其所有的自用模式,并且一旦建立了文档,在这个类的整个生命周期中都必须遵守。 如果没有做到,子类就会依赖超类的实现细节,如果超类的实现发生了变化,它就有可能遭到破坏。 为 了允许其他人能编写出高效的子类,还你必须导出一个或者多个受保护的方法。 除非知道 真正需要子类,否则最好通过将类声明为 final,或者确保没有可访问的构造器来禁止类被 继承。
第20条:接口优于抽象类
Java 提供了两种机制,可以用来定义允许多个实现的类型 : 接口和抽象类。
自从 Java 8 为继承引入了缺省方法( default method),这两种机制都允许为某些实例方法提供实现。
主要的区别在于,为了实现由抽象类定义的类型,类必须成为抽象类的一个子类。 因为 Java 只允许单继承,所以用抽象类作为类型定义受到了限制。
任何定义了所有必要的方法并遵守通用约定的类,都允许实现一个接口,无论这个类是处在类层次结构中的什么位置。
- 现有的类可以很容易被更新,以实现新的接口(如果你希望两个 类扩展同一个抽象类,就必须把抽象类放到类型层次( type hierarchy )的高处,这样它就成 了那两个类的一个祖先 遗憾的是,这样做会间接地伤害到类层次,迫使这个公共祖先的所 有后代类都扩展这个新的抽象类,)
- 接口是定义 mixin (混合类型)的理想选择。
- 接口允许构造非层次结构的类型框架。
- 接口使得安全地增强类的功能成为 可能。
- 通过对接口提供一个抽象的骨架实现( skeletal implementation)类,可以把接口 和抽象类的优点结合起来。 接口负责定义类型,或许还提供一些缺省方法,而骨架实现类则负责实现除基本类型接口方法之外,剩下的非基本类型接口方法。 扩展骨架实现占了实现接 口之外的大部分工作。 这就是模板方法(Templat巳 Method)模式。
骨架实现类被称为 Abstractinterface,这里的 Interface 是指所实现的接 口的名字。 例如, Collections Framework 为每个重要的集合接口都提供了一个骨架实现,包 括 AbstractCollection 、 AbstractSet 、 AbstractList 和 AbstractMap。 将它 们称作 SkeletalCollection, SkeletalSet, SkeletalList 和 SkeletalMap 也 是有道理的,但是现在 Abstract 的用法已经根深蒂固。 如果设计得当 ,骨架实现(无论 是单独一个抽象类,还是接口中唯一包含的缺省方法) 可以使程序员非常容易地提供他们自 己的接口实现。 例如,下面是一个静态工厂方法,除 AbstractList 之外,它还包含了一个完 整的、功能全面的 List 实现:
static List<Integer>intArrayAsList(int[] a){
Objects.requireNonNull(a);
return new AbstractList<Integer>() {
@Override
public Integer get(int index) {
return a[index];
}
@Override
public Integer set(int index, Integer element) {
int oldVal = a[index];
a[index] = element;
return oldVal;
}
@Override
public int size() {
return a.length;
}
};
}第21条:为后代设计接口
Java 中,增加了缺省方法( default method )构造[ JLS 9.4 ,目的就是允许给 现有的接口添加方法 但是给现有接口添加新方法还是充满风险。
缺省方法的声明中包括一个缺省实现( default imp ementation ),这是给实现了该接 没有实现默认方法的所有类使用的
并非每一个可能的实现的所有变体,始终都可以编写出一个缺省方法remove If

![]()
有了缺省方法,接口的现有实现就不会出现编译时没有报错或 告,运行时却失败的 情况
第22条:接口只用于定义类型
当类实现接口时 ,接口就充当可以引用这个类实例的类型(type 因此,类实现了接口, 就表明客户端可以对这个类的实例实施某些动作
有一种接口被称为常量接口( constant interface ),它不满足上面的条件 这种接口不包 任何方法,它只含静态的 final 域, 每个域都导出数个常量, 使用这些常类实现这 个接口,以避免用类名来修饰常量名
常量接口模式是对接口的不良使用 类在内部使用某些常量,这纯粹是实现细节,实现常量接 口会导致把这样的实现细节泄露到该类的导出 API ,类实现常量接口对于该类的用户而言并没有什么价值 实际上,这样做反而会使他们 加糊涂 更糟糕的是,它代表 了一种承诺:如果在将 发行版本中,这 类被修改了,它不再需要使用这些常量了, 依然必须实现这个接口,以确保进制兼容性 如果非 final 类实现了常量接 口,它的所有子类的命名空 间也会被接 口中的常量所“污染” 解决办法:
不太懂?进制兼容性
-
直接添加到对应的类实例
-
做枚举
-
使用不可实例化的工具类
有候会在数字的字面量中使用下划线() Java 7开始可以使用下划线

![]()
第23条:类层次优于标签类,
标签类正是对类层次的一种简单的仿效。
接口可以用来反映类型之间本质上的层次关系,有助于增 强灵活性,并有助于更好地进行编译时类型检查。
当你想要编写 个包含显式标签域的类时,应 该考虑一下,这个标签是否可以取消,这个类是否可以用类层次来代替 你遇到 个包含 标签域的现有类时,就要考虑将它重构到 个层次结构中去
第24条:静态成员类优于非静态成员类
嵌套类( sted class )是指定义在另 个类的内部的类 嵌套类存在的目的应该只是为 它的外围类(巳nclosing ass )提供服务 如果嵌套类将来可能会用于其他的某个环境中,它 就应该是顶层类( top-level class 嵌套类有 四种: 静态成员类( static mber class )、非静 态成员类( nonstatic memb class )、匿名类( anonymous class )和局 部类( local class 了第一种之外,其他三种都称为内部类( inner class 本条目将告诉你什么时候应该使用哪 种嵌套类,以及这样做的原因 静态成员类是最简单 种嵌套类 最好把它看作是普通 类,
静态成员类( static mber class ):它可以访问外围类的所有成员,包括那些声明为私有的成员,静态成员类是外围类的一个静态成员,与其他的静态成员一样,也遵守同样的可访问性,如果它被声明为私有的,它就只能在外围类的内部才可以被访问,
非静态成员类的每个实例都隐含地与外围类的一个外围实例(enclosing instance )相关联 ,在非静态成员类的实例方法内部,可以调用外围实例上的方法,或者利用修饰过的 this ( qualifiedis )构造获得外围实例的引用。
如果嵌 套类的实例可以在它外围类的实例之外独立存在,这个嵌套类就必须是静态成员类:在没有外围实例的情况下,要想创建非静态成员类的实例是不可能的
非静态成员类的种常见用法是定义 Adapter(适配器)它允许外部类的实例被看作是另一个不相关的类的实例
例如, Map 接口的实现往往使用非静态成员类来实现它们的集合视图( collection view )这些集合视图是由 Map的keySet, entrySet, values,方法返回
final class KeySet extends AbstractSet<K> {
public final int size() { return size; }
public final void clear() { HashMap.this.clear(); }
public final Iterator<K> iterator() { return new KeyIterator(); }
public final boolean contains(Object o) { return containsKey(o); }
public final boolean remove(Object key) {
return removeNode(hash(key), key, null, false, true) != null;
}
public final Spliterator<K> spliterator() {
return new KeySpliterator<>(HashMap.this, 0, -1, 0, 0);
}
public final void forEach(Consumer<? super K> action) {
Node<K,V>[] tab;
if (action == null)
throw new NullPointerException();
if (size > 0 && (tab = table) != null) {
int mc = modCount;
for (int i = 0; i < tab.length; ++i) {
for (Node<K,V> e = tab[i]; e != null; e = e.next)
action.accept(e.key);
}
if (modCount != mc)
throw new ConcurrentModificationException();
}
}
}
![]()
同样地,诸如 List 这种集合接口的实现往往也使用非静态成员类来实现它们的迭代器( iterator):
ArrayList
/**
* An optimized version of AbstractList.Itr
*/
private class Itr implements Iterator<E> {
int cursor; // index of next element to return
int lastRet = -1; // index of last element returned; -1 if no such
int expectedModCount = modCount;
Itr() {}
public boolean hasNext() {
return cursor != size;
}
@SuppressWarnings("unchecked")
public E next() {
checkForComodification();
int i = cursor;
if (i >= size)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1;
return (E) elementData[lastRet = i];
}
public void remove() {
if (lastRet < 0)
throw new IllegalStateException();
checkForComodification();
try {
ArrayList.this.remove(lastRet);
cursor = lastRet;
lastRet = -1;
expectedModCount = modCount;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
@Override
@SuppressWarnings("unchecked")
public void forEachRemaining(Consumer<? super E> consumer) {
Objects.requireNonNull(consumer);
final int size = ArrayList.this.size;
int i = cursor;
if (i >= size) {
return;
}
final Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length) {
throw new ConcurrentModificationException();
}
while (i != size && modCount == expectedModCount) {
consumer.accept((E) elementData[i++]);
}
// update once at end of iteration to reduce heap write traffic
cursor = i;
lastRet = i - 1;
checkForComodification();
}
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
}
第25条:限制源文件为单个顶级类
虽然 Java 编译器允许在一个源文件中定义多个顶级类,但这么做并没有什么好处,只会带来巨大的风险。
因为在一个源文件中定义多个顶级类,可能导致给一个类提供多个定义。 哪一个定义会被用到,取决于源文件被传给编译器的顺序。

![]()
如果你侥幸是用命令javac Main. java Dessert. java来编译程序,那么编译就会失败,此时编译器会提醒你定义了多个Utensil和Dessert类。这是因为编译器会先编译Main.java,当它看到Utensil的引用(在Dessert引用之前),就会在Utensil. java中查看这个类,结果找到Utensil和Dessert这两个类。当编译器在命令行遇到Dessert.java时,也会去查找该文件,结果会遇到Utensil和Dessert这两个定义。
如果用命令javac Main.java或者javac Main.java Utensil.java编译程序,结果将如同你还没有编写Dessert. java文件一样,输出pancake。但如果是用命令javac Dessert.java Main.java编译程序,就会输出potpie,程序的行为受源文件被传给编译器的顺序影响,这显然是让人无法接受的。
永远不要把多个顶级类或者接口放在一个源文件中
package com.company;
/**
* @Description : TODO
* @author Liruilong
* @Date 2020-11-23 20:44
**/
public class Main {
public static void main(String[] args) {
// write your code here
System.out.println(Utensil.NAME + Dessert.NAME);
}
private static class Utensil {
static final String NAME = "pan";
}
private static class Dessert {
static final String NAME = "cake";
}
}
第5章泛型
从Java5开始,泛型( generic)已经成了Java编程语言的一部分。
在没有泛型之前,从集合中读取到的每一个对象都必须进行转换。如果有人不小心插入了类型错误的对象,在运行时的转换处理就会出错。有了泛型之后,你可以告诉编译器每个集合中接受哪些对象类型。编译器自动为你的插入进行转换,并在编译时告知是否插入了类型错误的对象。这样可以使程序更加安全,也更加清楚,但是要享有这些优势(不限于集合)有一定的难度。
第26条:请不要使用原生态类型
如果使用原生态类型,就失掉了泛型在安全性和描述性方面的所有优势。
如果使用像List这样的原生态类型,就会失掉类型安全性,但是如果使用像List<object>这样的参数化类型,则不会。
声明中具有一个或者多个类型参数( type parameter )的类或者接 口,就是泛型( generic )类或者接口,
这个接口的全称是 List<E> (读作“ E的列表”),但是 人们经常把它简称为 List ,泛型类和接口统称为泛型( generic type )
每一种泛型定义一组参数化的类型( parameterized type)
- 必须在元类(class literal)中使用原生态类型。规范不允许使用参数化类型(虽然允许数组类型和基本类型)

![]()
- 这条规则的第二个例外与instanceof操作符有关。由于泛型信息可以在运行时被擦除,因此在参数化类型而非无限制通配符类型上使用instanceof操作符是非法的。用无限制通配符类型代替原生态类型,对instanceof操作符的行为不会产生任何影响。在这种情况下,尖括号(<)和问号(?)就显得多余了。下面是利用泛型来使用instanceof的方法


总而言之,使用原生态类型会在运行时导致异常,因此不要使用。原生态类型只是为了与引入泛型之前的遗留代码进行兼容和互用而提供的。
- Set<object>是个参数化类型,表示可以包含任何对象类型的一个集合;
- Set<?>则是一个通配符类型,表示只能包含某种未知对象类型的一个集合;
- Set是一个原生态类型,它脱离了泛型系统。前两种是安全的,最后一种不安全。
第27条:消除非受检的警告
如果无法消除警告,同时可以证明引起警告的代码是类型安全的, (只有在这种情况下)才可以用一个asuppresswarnings ( "unchecked" )注解来禁止这条警告。
应该始终在尽可能小的范围内使用SuppressWarnings注解。它通常是个变量声明,或是非常简短的方法或构造器。永远不要在整个类上使用suppresswarnings,这么做可能会掩盖重要的警告。
每当使用suppresswarnings ( "unchecked" )注解时,都要添加一条注释,说明为什么这么做是安全的。这样可以帮助其他人理解代码,

![]()
第28条:列表优于数组
数组与泛型相比,有两个重要的不同点。首先,数组是协变的(covariant),表示如果Sub为Super的子类型,那么数组类型Sub []就是Super []的子类型。相反,泛型则是可变的( invariant) :对于任意两个不同的类型Type1和Type2, List<Typel>既不是List<Type2>的子类型,也不是List<Type2>的超类型。你可能认为,这意味着泛型是有缺陷的,但实际上可以说数组才是有缺陷的。下面的代码片段是合法的:

![]()
数组是具体化的(reified) 。因此数组会在运行时知道和强化它们的元素类型。,如果企图将string保存到Long数组中,就会得到一个ArraystoreException异常。相比之下,泛型则是通过擦除( erasure)来实现的。这意味着,泛型只在编译时强化它们的类型信息,并在运行时丢弃(或者擦除)它们的元素类型信息。擦除就是使泛型可以与没有使用泛型的代码随意进行互用(详见第26条),以确保在Java5中平滑过渡到泛型。
从技术的角度来说,像E、List<E>和List<string>这样的类型应称作不可具体化的( nonreifiable)类型。直观地说,不可具体化的( non-reifiable)类型是指·其运行时表示法包含的信息比它的编译时表示法包含的信息更少的类型。唯一可具体化的(reifiable)参数化类型是无限制的通配符类型,如List<?>和Map<?, ?> (详见第26条)。
数组是协变且可以具体化的; 泛型是可变的且可以被擦除的。因此,数组提供了运行时的类型安全,但是没有编译时的类型,安全,反之,对于泛型也一样。一般来说,数组和泛型不能很好地混合使用。如果你发现自己将它们混合起来使用,并且得到了编译时错误或者警告,你的第一反应就应该是用列表代替数组。
第29:优先考虑泛型
从JDK5.0开始,Java引入“参数化类型”的概念,泛型指将数据类型参数化,即在编写代码的时候将数据类型定义成参数,在使用之前在进行指明。
泛型提高了代码的重用性,是的程序更加灵活,安全和简洁。泛型的好处在在程序编译期会对类型进行检查,捕捉类型不匹配错误,以免引起ClassCastException异常。
import java.util.Arrays;
import java.util.EmptyStackException;
/**
* @Description :
* @Author: Liruilong
* @Date: 2020/12/2 0:47
*/
public class Stack<E> {
private E[] element;
private int size = 0;
private static final int DEFAULT_INITIAL_CAPACITY = 16;
@SuppressWarnings("unchecked")
public Stack() {
// TODO this.element = new E[DEFAULT_INITIAL_CAPACITY]; 解决办法:
this.element = (E[]) new Object[DEFAULT_INITIAL_CAPACITY];
}
public void push(E e){
ensureCapactity();
element[size++] = e;
}
private void ensureCapactity() {
if(element.length==size){
element = Arrays.copyOf(element,2 * size +1);
}
}
public E pop(){
if (size == 0){
throw new EmptyStackException();
}
// @SuppressWarnings("unchecked") 使用 private Object[] element;
// E o = (E)element[--size];
E e = element[--size];
element[size] = null;
return e ;
}
public static void main(String[] args) {
new Stack<>();
}
}
总而言之,使用泛型比使用需要在客户端代码中进行转换的类型来得更加安全,也更加容易。在设计新类型的时候,要确保它们不需要这种转换就可以使用。这通常意味着要把·类做成是泛型的。只要时间允许,就把现有的类型都泛型化。这对于这些类型的新用户来说会变得更加轻松,又不会破坏现有的客户端(详见第26条)。
第30条:优先考虑泛型方法
静态工具方法尤其适合于泛型化。collections中的所有“算法”方法(例如binarySearch和sort)都泛型化了。
public static Set union(Set s1, Set s2){
Set result = new HashSet(s1);
result.addAll(s2);
return result;
}
public static <E> Set<E> union(Set<E> s1, Set<E> s2){
Set<E> result = new HashSet<>(s1);
result.addAll(s2);
return result;
}
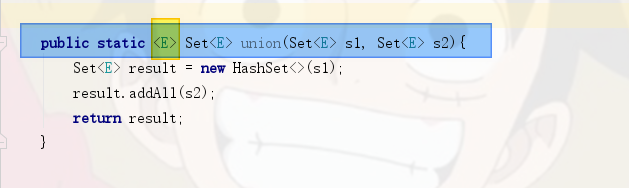
声明的泛型参数的泛型表示,在方法的修饰符和返回值之间。
当需要对泛型参数进行限制的时候,利用有限制的通配符类型( bounded wildcard type )可以使方法变得更加灵活
有时可能需要创建一个不可变但又适用于许多不同类型的对象。即传递的泛型参数是不可变得,但是有要求是任意的,由于泛型是通过擦除实现的,可以给所有必要的类型参数使用单个对象,但是需要编写一个静态工厂方法,让它重复地给每个必要的类型参数分发对象。这种模式称作泛型单例工厂(generic singleton factory),常用于函数对象(详见第42条),如collections . reverseOrder,有时也用于像collections. emptySet这样的集合。
假设要编写一个恒等函数( identity function)分发器、类库中提供了Function.identity,因此不需要自己编写(详见第59条),但是自己编写也很有意义。如果在每次需要的时候都重新创建一个,这样会很浪费,因为它是无状态的(stateless)。

![]()
如果Java泛型被具体化了,每个类型都需要一个恒等函数,但是它们被擦除后,就只需要一个泛型单例。请看以下示例:
private static UnaryOperator<Object> IDENTITY_FN = (t) ->t;
@SuppressWarnings("unchecked")
public static <T> UnaryOperator<T> identityFunction(){
return (UnaryOperator<T>) IDENTITY_FN;
}
IDENTITY-FN转换成(UnaryFunction<T>),产生了一条未受检的转换警告,
private static UnaryOperator<Object> IDENTITY_FN = (t) ->t;
@SuppressWarnings("unchecked")
public static <T> UnaryOperator<T> identityFunction(){
return (UnaryOperator<T>) IDENTITY_FN;
}
public static void main(String[] args) {
String[] strings = {"Li","Rui","Long"};
UnaryOperator<String> stringUnaryOperator = identityFunction();
for (String s : strings) {
System.out.println(stringUnaryOperator.apply(s));
}
Number[] numbers = {1,2,3L};
UnaryOperator<Number> numberUnaryOperator = identityFunction();
for (Number number : numbers) {
System.out.println(numberUnaryOperator.apply(number));
}
}虽然相对少见,但是通过某个包含该类型参数本身的表达式来限制类型参数是允许的。这就是递归类型限制( recursive type bound)。递归类型限制最普遍的用途与Comparable接口有关,它定义类型的自然顺序(详见第14条),这个接口的内容如下:
public interface Comparable<T> {
public int compareTo(T o);
}
泛型方法就像泛型一样,使用起来比要求客户端转换输入参数并返回值的方法来得更加安全,也更加容易。就像类型一样,应该确保方法不用转换就能使用,这通常意味着要将它们泛型化。并且就像类型一样,还应该将现有的方法泛型化,使新用户使用起来更加轻松,且不会破坏现有的客户端(详见第26条)。
第31条:利用有限制通配符来提升API的灵活
所谓有限制通配符也叫泛型通配符,super和 extends ,
extends一般用户定义上界,extends用于读取,
// pushAll method without wildcard type - deficient
public void pushAll(Iterable<E> src){
for (E e:src){
// push(e) push()为
}
}
// TODO 由于泛型是不可变的,即不能类似数组那样协变,
// 所以通过泛型通配符 extends 实现对要读取的类型限制。
// 限制读取的类型只能是约定泛型的子类,即限定了泛型的父类(上界)
public void pushAll( Iterable<? extends E> src){
for (E e : src) {
}
}pushAll的输入参数类型不应该,为“E 的 Iterable接口”,而应该为“E的某个子类型的Iterable接口(当然也包括自己)”通配符类型Iterable<?extends E>正是这个意思。
super一般用于定义下界,用于限制写入容器的类型,即你要写入时,要
// 弹出栈内所有的元素放入指定的集合。
// 当 dst 集合于 栈里弹出的元素类型不一致时,编译是没有问题的。
// 当类型不一致时,会报错
public void popAll(Collection<E> dst){
while (!isEmporrt()){
dst.add(pop());
}
}
List list = new LinkedList();
LinkedList linkedList = new List<Integer>();
// 限制要写入的类型, 即要写入的容器类型必须是写入类型的父类,超类。
// 即 你可以用一个父类申明 存放子类引用。但你不能用一个子类申明去存放一个父类引用。
public void popAll(Collection< ? super E > dst){
while (!isEmporrt()){
dst.add(pop());
}
}popAll的输入参数类型不应该为“E的集合”,而应该为“E的某种超类的集合” (这里的超类是确定的,因此E是它自身的一个超类型)。
结论很明显:为了获得最大限度的灵活性,要在表示生产者或者消费者的输入参数上·使用通配符类型。如果某个输入参数既是生产者,又是消费者,那么通配符类型对你就没有什么好处了;因为你需要的是严格的类型匹配,这是不用任何通配符而得到的。
PECS表示 producer-extends, consumer-super.
- 如果参数化类型表示一个生产者T,就使用<? extends T> ;
- 如果它表示一个消费者T,就使用<? super T>。
在我们的stack示例中:
- pushAll的src参数产生E实例供stack使用,因此src相应的类型为Iterable<? extends E> ;
- popAll的dst参数通过stack消费E实例,因此dst相应的类型为collection<? super E>.
PECS这个助记符突出了使用通配符类型的基本原则。Naftalin和Wadler称之为Get and Put Principle [Naftalin07, 2.4]
同时读写(即生产消费同时进行)的实例;
JDK的Collections.comp方法实现了把源列表中的所有元素拷贝到目标列表对应的索引上。public static <T> void copy(List<? super T> dest, List<? extends T> src) { int srcSize = src.size(); if (srcSize > dest.size()) throw new IndexOutOfBoundsException("Source does not fit in dest"); if (srcSize < COPY_THRESHOLD || (src instanceof RandomAccess && dest instanceof RandomAccess)) { for (int i=0; i<srcSize; i++) dest.set(i, src.get(i)); } else { ListIterator<? super T> di=dest.listIterator(); ListIterator<? extends T> si=src.listIterator(); for (i)nt i=0; i<srcSize; i++) { di.next(); di.set(si.next()); } } }
如果类的用户必须考虑通配符类型,类的API或许就会出错,不要用通配符类型作为返回类型。
参数化类型Comparable<T>被有限制通配符类型Comparable<? super T>取代。comparable始终是消费者,因此使用时始终应该是Comparable<? superT>优先于Comparable<T>。对于comparator接口也一样,因此使用时始终应该是comparator<? superT>优先于Comparator<T>。

![]()
一般来说,
- 如果类型参数只在方法声明中出现一次,就可以用通配符取代它。
- 如果是无限制的类型參数,就用无限制的通配符取代它;
- 如果是有限制的类型参数,就用有限制的通配符取代它。

![]()
总而言之,在API中使用通配符类型虽然比较需要技巧,但是会使API变得灵活得多。如果编写的是将被广泛使用的类库,则一定要适当地利用通配符类型。记住基本的原则: producer-extends,consumer-super (PECS)。还要记住所有的comparable和comparator都是消费者。
第32条:谨慎并用泛型和可变参数
可变参数( vararg)方法(详见第53条)和泛型都是在Java 5中就有了
可变参数的作用在于让客户端能够将可变数量的参数传给方法
非具体化( non-reifiable)类型是指其运行时代码信息比编译时少,并且显然所有的泛型和参数类型都是非具体化的。
如果一个方法声明其可变参数为nonreifiable类型,编译器就会在声明中产生一条警告。如果方法是在类型为non-reifiable的可变参数上调用,编译器也会在调用时发出一条警告信息。

![]()
当一个参数化类型的变量指向一个不是该类型的对象时,会产生堆污染(heap pollution)[JLS, 4.12.2]。它导致编辑器的自动生成转换失败,破坏了泛型系统的基本保证。
public static void demo(List<String>... str){
List<Integer> list = Arrays.asList(12,12);
// 数组的协变
Object[] objects = str;
objects[0] = list;
String s = str[0].get(0);// TODO ClassCastException
// 将值保存在泛型可变参数数组中是不安全的。
}这个方法没有可见的转换,但是在调用一个或者多个参数时会抛出ClassCastException异常。上述最后一行代码中有一个不可见的转换,这是由编译器生成的。这个转换失败证明类型安全已经受到了危及,因此将值保存在泛型可变参数数组参数中是不安全的。
为什么显式创建泛型数组是非法的,用泛型可变参数声明方法却是合法的呢?
答案在于,带有泛型可变参数或者参数化类型的方法在实践中用处很大,因此Java语言的设计者选择容忍这一矛盾的存在。事实上,Java类库导出了好几个这样的方法,包括
Arrays.asList(...a)、 Collections.addAll (Collection<? super T> c, r...elements), 以及EnumSet.of (E first,E... rest)
与前面提到的危险方法不一样,这些类库方法是类型安全的。
在Java 7之前,带泛型可变参数的方法的设计者,对于在调用处出错的警告信息一点办法也没有。这使得这些API使用起来非常不愉快。用户必须忍受这些警告,要么最好在每处调用点都通过@SuppressWarnings ("unchecked")注解来消除警告
在Java 7中,增加了@Safevarargs注解,它让带泛型vararg参数的方法的设计者能够自动禁止客户端的警告。本质上, safevarargs注解是通过方法的设计者做出承诺,声明这是类型安全的。作为对于该承诺的交换,编译器同意不再向该方法的用户发出警告说这些调用可能不安全。
重要的是,不要随意用@safeVarargs对方法进行注解,除非它真正是安全的。那么它凭什么确保安全呢?回顾一下,泛型数组是在调用方法的时候创建的,用来保存可变参数。
如果该方法没有在数组中保存任何值,也不允许对数组的引用转义(这可能导致不被信任的代码访问数组),那么它就是安全的。换句话说,如果可变参数数组只用来将数量可变的参数从调用程序传到方法(毕竟这才是可变参数的目的),那么该方法就是安全的。值得注意的是,从来不在可变参数的数组中保存任何值,这可能破坏类型安全性。以下面的泛型可变参数方法为例,它返回了一个包含其参数的数组。乍看之下,这似乎是一个方便的小工具:
第33条:优先考虑类型安全的异构容器
泛型最常用于集合,`如Set<E>和Map<K, V),以及单个元素的容器,如ThreadLocal<T>和AtomicRe ference<T>。在所有这些用法中,它都充当被参数化了的容器。这样就限制每个容器只能有固定数目的类型参数。
一般来说,这种情况正是你想要的。一个Set, 只有一个类型参数,表示它的元素类型;一个Map有两个类型参数,表示它的键和值类型
例如,数据库的行可以有任意数量的列,如果能以类型安全的方式访问所有列就好了。幸运的是,有一种方法可以很容易地做到这一点。这种方法就是将键( key)进行参数化而不是将容器( container)参数化。然后将参数化的键提交给容器来插入或者获取值。用泛型系统来确保值的类型与它的键相符。
以Favorites类为例,它允许其客户端从任意数量的其他类中,保存并获取一个“最喜爱”的实例。Class对象充当参数化键的部分。之所以可以这样,是因为类Class被泛型化了。类的类型从字面上来看不再只是简单的Class,而是Class<T>,例如, string.class属于Class<string>类型, Integer.class属于Class<Integer>类型。当一个类的字面被用在方法中,来传达编译时和运行时的类型信息时,就被称作类型令牌(type token)。
package com.hhwy.pwps.util;
import java.util.HashMap;
import java.util.Map;
import java.util.Objects;
/**
* @author Liruilong
* @Date 2020-12-17 23:28
* @Description:
*/
public class Favorites {
private Map<Class<?>, Object> favorites = new HashMap<>();
public <T> void putFavorites(Class<T> type, T instance) {
favorites.put(Objects.requireNonNull(type), instance);
}
public <T> T getFavorite(Class<T> type) {
return type.cast(favorites.get(type));
}
public static void main(String[] args) {
Favorites favorites = new Favorites();
favorites.putFavorites(String.class, "Java");
favorites.putFavorites(Integer.class, 0xcafebabe);
favorites.putFavorites(Class.class, Favorites.class);
String f = favorites.getFavorite(String.class);
int f1 = favorites.getFavorite(Integer.class);
Class<?> f2 = favorites.getFavorite(Class.class);
System.out.printf("%s %x %s%n",f,f1,f2.getName());
}
}
Favorites实例是类型安全(typesafe)的:当你向它请求string的时候,它从来不会返回一个Integer给你。同时它也是异构的(heterogeneous):不像普通的映射,它的所有键都是不同类型的。因此,我们将Favorites称作类型安全的异构容器( typesafeheterogeneous container)

![]()
getFavorite方法先从favorites映射中获得与指定Class对象相对应的值。这正是要返回的对象引用,但它的编译时类型是错误的。它的类型只是object ( favorites映射的值类型),我们需要返回一个T。因此,getFavorite方法的实现利用Class的cast方法,将对象引用动态地转换(dynamicallycast)成了Class对象所表示的类型。
cast方法是Java的转换操作符的动态模拟。它只检验它的参数是否为class对象所,表示的类型的实例。如果是,就返回参数;否则就抛出ClassCastException异常。

![]()
cast方法的签名充分利用了Class类被泛型化的这个事实。它的返回类型是Class对象的类型参数:

![]()
Favorites类有两种局限性值得注意。
首先,恶意的客户端可以很轻松地破坏Favorites实例的类型安全,只要以它的原生态形式(raw form)使用Class对象(我理解put进去一个Set,Map,取出来可能为HashSet或者HashMap,其实也没明白...........:)
第二种局限性在于它不能用在不可具体化的(non-reifiable)类型中(详见第28条),换句话说,你可以保存String或者string[],但不能保存的List<string>。
如果试图保存List<String>,程序就不能进行编译。原因在于你无法为List<string>获得一个Class对象: List<string>.Class是个语法错误
List<string>和List<Integer>共用一个class对象,即List.class.
如果从“类型的字面" (type literal)上来看, List<string>.class和List<Integer>.class是合法的,并返回了相同的对象引用,这会破坏Favorites对象的内部结构。对于这种局限性,还没有完全令人满意的解决办法。
Favorites使用的类型令牌(type token)是无限制的: getFavorite和putFavorite接受任何Class对象。有时可能需要限制那些可以传给方法的类型。这可以通过有限制的类型令牌(bounded type token)来实现,它只是一个类型令牌,利用有限制类型参数(详见第30条)或者有限制通配符(详见第31条),来限制可以表示的类型.
总而言之,集合API说明了泛型的一般用法,限制每个容器只能有固定数目的类型参数。你可以通过将类型参数放在键上而不是容器上来避开这一限制。对于这种类型安全的异构容器,可以用Class对象作为键。以这种方式使用的Class对象称作类型令牌。你也可以使用定制的键类型。例如,用一个DatabaseRow类型表示一个数据库行(容器),用泛型column<T>作为它的键。
還是不太明白.....理解: 構造一個可以使用汎型的容器,比如 A類,B類,C類,可以放到一個容器裏,傳統的做法卻沒辦法做到容易造成堆污染。
第6章枚举和注解
Java支持两种特殊用途的引用类型:
- 一种是类,称作枚举类型(enum type);
- 一种是接口,称作注解类型(annotation type)。
第34条:用enum代替int常量

![]()
采用int枚举模式的程序是十分脆弱的。因为int枚举是编译时常量它们的int值会被编译到使用它们的客户端中。如果与int枚举常量关联的值发生了变化,客户端必须重新编译。
java从1.5开始,提供了枚举的支持。java枚举本质上是Int值,final类,客户端不能创建枚举类型的实例,也不能对他进行扩展,枚举类型是可控的,即单例的泛型化。

![]()
- 枚举类型还允许添加任意的方法和域,并实现任意的接口。
- 提供了所有object方法,实现了comparable和Serializable接口,
- 针对枚举类型的可任意改变性设计了序列化方式。
package com.hhwy.pwps.util;
/**
* @author Liruilong
* @Date 2020-12-22 19:54
* @Description:
*/
public enum Planet {
MERCURY(3.302e+23, 2.439e6),
VENUS(4.869e+24, 6.052e6),
EARTH(5.975e+24, 6.378e6),
MARS(6.419e+23, 3.393e6),
JUPITER(1.899e+27, 7.149e7),
SATURN(5.685e+26, 6.027e7),
URANUS(8.683e+25, 2.556e7),
NEPTUNE(1.024e+26, 2.477e7);
private final double mass;
private final double radius;
private final double surfaceGravity;
private static final double G = 6.677300E-11;
// In kilograms
Planet(double mass, double radius) {
this.mass = mass;
this.radius = radius;
surfaceGravity = G * mass / (radius * radius);
}
public double getMass() {
return mass;
}
public double getRadius() {
return radius;
}
public double getSurfaceGravity() {
return surfaceGravity;
}
public double getSurfaceGravity(double mass){
return mass * surfaceGravity;
}
}

![]()
- 如果一个枚举具有普遍适用性,它就应该成为一个顶层类(top-level class);
- 如果它只是被用在一个特定的顶层类中,它就应该成为该顶层类的一个成员类(详见第24条)。
java .math. RoundingMode枚举表示十进制小数的舍入模式(rounding mode)。

![]()
这些舍入模式被用于BigDecimal类,但是它们却不属于BigDecimal类的一个抽象。通过使RoundingMode变成一个顶层类,库的设计者鼓励任何需要舍入模式的程序员重用这个枚举,从而增强API之间的一致性。
特定于常量的方法实现(constant-specific method implementation):
可以将不同的行为与每个常量实例关联起来。在枚举类中申明一个抽象apply方法,并在特定的常量的类主体中,用具体的方法覆盖每个常量的抽象apply方法,

![]()
或者這樣。...........................
package com.hhwy.pwps.util;
import java.util.Map;
import java.util.Optional;
import java.util.stream.Collectors;
import java.util.stream.Stream;
/**
* @author Liruilong
* @Date 2020-12-22 20:42
* @Description:
*/
public enum Operation {
PLUS("+") {
@Override
public double apply(double x, double y) { return x + y; }
},
MINUS("-") {
@Override
public double apply(double x, double y) { return x - y; }
},
TIMES("*") {
@Override
public double apply(double x, double y) { return x * y; }
},
DIVIDE("/") {
@Override
public double apply(double x, double y) { return x / y; }
},
MO("%") {
@Override
public double apply(double x, double y) { return x % y; }
};
private final String symbol;
Operation(String symbol) {
this.symbol = symbol;
}
public abstract double apply(double x, double y);
@Override
public String toString() {
return "Operation{" +
"symbol='" + symbol + '\'' +
'}';
}
//在枚举类型上实现fromString方法
private static final Map<String,Operation> stringToEnum =
Stream.of(values()).collect(Collectors.toMap(Object::toString, e ->e));
//返回字符串的操作,如果有的话
public static Optional<Operation> fromString(String symbol){
return Optional.ofNullable(stringToEnum.get(symbol));
}
}

![]()
在Java 8之前,我们将创建一个空的散列映射并遍历values数组,将字符串到枚举的映射插入到映射中,当然,如果你愿意,现在仍然可以这么做。但是,
试图使每个常量都从自己的构造器将自身放入到映射中是不起作用的。它会导致编译时错误,这是好事,因为如果这是合法的,可能会引发Null PointerException异常。除了编译时常量域(见第34条)之外,枚举构造器不可以访问枚举的静态域。这一限制是有必要的,因为构造器运行的时候,这些静态域还没有被初始化。
这条限制有一个特例:枚举常量无法通过其构造器访问另一个构造器。
public static void main(String[] args) {
Operation.PLUS.apply(12,12);
Operation.Demo.PLUS.apply(12,23);
}
枚举中的switch语句适合于给外部的枚举类型增加特定于常量的行为。
我们真正想要的就是每当添加一个枚举常量时,就强制选择一种加班报酬策略。幸运的是,有一种很好的方法可以实现这一点。这种想法就是将加班工资计算移到一个私有的嵌,套枚举中,将这个策略枚举(strategy enum)的实例传到Payrol1Day枚举的构造器中。之后PayrollDay枚举将加班工资计算委托给策略枚举, Payrol1Day中就不需要switch语句或者特定于常量的方法实现了。虽然这种模式没有switch语句那么简洁
什么时候应该使用枚举呢?
- 每当需要一组固定常量,并且在编译时就知道其成员的时候,就应该使用枚举。
- 专门设计枚举特性是考虑到枚举类型的二进制兼容演变。总而言之,与int常量相比,枚举类型的优势是不言而喻的。
- 许多枚举都不需要显式的构造器或者成员,但许多其他枚举则受益于属性与每个常量的关联以及其行为受该属性影响的方法。只有极少数的枚举受益于将多种行为与单个方法关联。
- 特定于常量的方法要优先于启用自有值的枚举。如果多个(但非所有)枚举常量同时共享相同的行为,则要考虑策略枚举。
第35条:用实例域代替序数

![]()
// TODO 如果常量进行重新排序, numberOfMusicians方法就会遭到破坏。
public enum Ensemble_1{
SOLO, DUET, TRIO, QUARTET, QUINTET, SEXTET, SEPTET, OCTET, NONET, DECTET;
public int numberOfMusicians() { return ordinal() +1;}
}
// TODO 永远不要根据枚举的序数导出与它关联的值,而是要将它保存在一个实例域中:
public enum Ensemble_2{
SOLO(1),DUET (2), TRIO(3), QUARTET (4)
, QUINTET(5),SEXTET (6), SEPTET (7), оCTET(8)
, DOUBLE_QUARTET (8), NONET (9), DECTET (10), TRIPLE_QUARTET (12);
private final int numberOfMusicians;
Ensemble_2(int size){
this.numberOfMusicians = size;
}
public int getNumberOfMusicians(){
return numberOfMusicians;
}
}第36条:用EnumSet代替位域
private class Text {
public static final int STYLE_BOLD = 1 << 0; //1
public static final int STYLE_ITALIC = 1 << 1; //2
public static final int STYLE_UNDERLINE = 1 << 2; //4
public static final int STYLE_STRIKETHROUGH = 1 << 3; // 8
// TODO Parameter is bitwise OR of zero or more STYLE_ constants
public void applyStyles(int styles) {
}
public void main(String[] args) {
applyStyles(STYLE_BOLD|STYLE_ITALIC | STYLE_UNDERLINE);
}
}

![]()
这种表示法让你用OR位运算将几个常量合并到一个集合中,称作位域(bit field):text. applystyles (STYLE_BOLD I STYLE_ITALIC);
关于位域:我们类比bitmap这种数据结构
bitmap 就是用bit的每一位来代表一个特殊的状态值, 或者说标签属性等等.举例来说, 8位的数值, 用 0000 0001 代表 北, 0000 0010 代表南, 0000 0100 代表西 依次类推.
那么当我们拿到一串bit, 如:0100 0000 自然可以去对应的映射关系表中查找到 究竟是属于哪一种类型, 如果我们想同时传递两个数值呢?只需要 0000 0011 这样就可以表示 北 南 两个方向了, 当然 至多可以表示 8个方向.
在java中,int数据底层以补码形式存储。int型变量使用32bit存储数据,其中最高位是符号位,0表示正数,1表示负数,可通过Integer.toBinaryString()转换为bit字符串,

在java中,一个int类型占32个比特,我们用一个int数组来表示时为 new int[32],总计占用内存32*32bit,现假如我们用int字节码的每一位表示一个数字的话,那么32个数字只需要一个int类型所占内存空间大小就够了,这样在大数据量的情况下会节省很多内存。
具体思路:
1个int占4字节即4*8=32位,那么我们只需要申请一个int数组长度为 int tmp[1+N/32]即可存储完这些数据,其中N代表要进行查找的总数,tmp中的每个元素在内存在占32位可以对应表示十进制数0~31,所以可得到BitMap表:
- tmp[0]:可表示0~31
- tmp[1]:可表示32~63
- tmp[2]可表示64~95
.......
那么接下来就看看十进制数如何转换为对应的bit位:
假设这40亿int数据为:6,3,8,32,36,......,那么具体的BitMap表示为:

![]()
java.util包提供了EnumSet类来有效地表示从单个枚举类型中提取的多个值的多个集合。这个类实现Set接口,提供了丰富的功能、类型安全性,以及可以从任何其他Set实现中得到的互用性。
在内部具体的实现上,每个EnumSet内容都表示为位矢量。如果底层的枚举类型有64个或者更少的元素(大多如此)整个EnumSet就使用单个long来表示,因此它的性能比得上位域的性能。批处理操作,如removeAll和retainAll,都是利用位算法来实现的,就像手工替位域实现的那样。但是可以避免手工位操作时容易出现的错误以及丑陋的代码,因为Enumset替你完成了这项艰巨的工作。下面是前一个范例改成用枚举代替位域之后的代码,

![]()
第37条:用EnumMap代替序数索引
现在假设有一个香草的数组,表示一座花园中的植物,你想要按照类型(一年生、多年生或者两年生植物)进行组织之后将这些植物列出来。如果要这么做,需要构建三个集合,每种类型一个,并且遍历整座花园,将每种香草放到相应的集合中。有些程序员会将这些集合放到一个按照类型的序数进行索引的数组中来实现这一点:
package com.hhwy.pwps.util;
import java.util.ArrayList;
import java.util.HashSet;
import java.util.List;
import java.util.Set;
/**
* @author Liruilong
* @Date 2020-12-29 20:43
* @Description:
*/
public class Plant {
enum LifeCycle{ ANNUAL,PERENNIAL,BIENNAL}
final String name;
final LifeCycle lifeCycle;
Plant(String name,LifeCycle lifeCycle){
this.name = name;
this.lifeCycle = lifeCycle;
}
@Override
public String toString(){
return name;
}
public static void main(String[] args) {
Set<Plant>[] plantSet = new Set[Plant.LifeCycle.values().length];
for (int i = 0; i < plantSet.length; i++) {
plantSet[i] = new HashSet<>();
}
List<Plant> garden = new ArrayList<>();
for (Plant p: garden) {
plantSet[p.lifeCycle.ordinal()].add(p);
}
for (int i = 0; i < plantSet.length; i++) {
System.out.printf("%s:%s%n",Plant.LifeCycle.values()[i]
plantSet[i]);
}
}
}
因为数组不能与泛型(详见第28条)兼容,程序需要进行未受检的转换,并且不能正确无误地进行编译。因为数组不知道它的索引代表,着什么,你必须手工标注( label)这些索引的输出。但是这种方法最严重的问题在于,当你访问一个按照枚举的序数进行索引的数组时,使用正确的int值就是你的职责了; int不能提供枚举的类型安全。你如果使用了错误的值,程序就会悄悄地完成错误的工作,或者幸运的话,会抛出ArrayIndexoutofBoundException异常。
EnumMap在运行速度方面之所以能与通过序数索引的数组相媲美,正是因为EnuMap在内部使用了这种数组。但是它对程序员隐藏了这种实现细节,集Map的丰富功能和类型安全与数组的快速于一身。注意EnumMap构造器采用键类型的Class对象:这是一个有限制的类型令牌(bounded type token),它提供了运行时的泛型信息(详见第33条)。
package com.hhwy.pwps.util;
import org.docx4j.wml.P;
import java.util.*;
/**
* @author Liruilong
* @Date 2020-12-29 20:43
* @Description:
*/
public class Plant {
enum LifeCycle{ ANNUAL,PERENNIAL,BIENNAL}
final String name;
final LifeCycle lifeCycle;
Plant(String name,LifeCycle lifeCycle){
this.name = name;
this.lifeCycle = lifeCycle;
}
@Override
public String toString(){
return name;
}
public static void main(String[] args) {
//Set<Plant>[] plantSet = new Set[Plant.LifeCycle.values().length];
Map<Plant.LifeCycle,Set<Plant>> plantSet = new EnumMap<>(Plant.LifeCycle.class);
//for (int i = 0; i < plantSet.length; i++) { plantSet[i] = new HashSet<>(); }
for (Plant.LifeCycle lc: Plant.LifeCycle.values()) {
plantSet.put(lc,new HashSet<>());
}
List<Plant> garden = new ArrayList<>();
//for (Plant p: garden) { plantSet[p.lifeCycle.ordinal()].add(p); }
for (Plant plant : garden) {
plantSet.get(plant.lifeCycle).add(plant);
}
//for (int i = 0; i < plantSet.length; i++) { System.out.printf("%s:%s%n",Plant.LifeCycle.values()[i],plantSet[i]); }
System.out.println(plantSet);
}
// TODO 用一行代碼解決:要使用有三种参数形式的groupingBy方法,它允许调用者利用mapFactory参数定义映射实现
System.out.println(Arrays.stream(garden).collect(
Collectors.groupingBy( p -> p.lifeCycle,() -> new EnumMap<>(LifeCycle.class),Collectors.toSet())));
}

第38条:用接口模拟可扩展的枚举
第39条:注解优先于命名模式
第40条:坚持使用Override注解
第41条:用标记接口定义类型
第7章Lambda和Stream
第42条: Lambda优先于匿名类
第43条:方法引用优先于Lambda
第44条:坚持使用标准的函数接口
第45条:谨慎使用Stream
第10章 异常
充分发挥异常的优点,可以提高程序的可读性、可靠性和可维护性。
第69条:只针对异常的情况才使用异常
异常应该只用于异常的情况下;它们永远不应该用于正常的控制流。
一般地,应该优先使用标准的、容易理解的模式,而不是那些声称可以提供更好性能的、弄巧成拙的方法。即使真的能够改进性能,面对平台实现的不断改进,这种模式的性能优势也不可能一直保持。然而,由这种过度聪明的模式带来的微妙的Bug,以及维护的痛苦却依然存在。
设计良好的API不应该强迫它的客户端为了正常的,控制流而使用异常。
如果类具有“状态相关” (state-dependent)的方法,即只有在特定的不可预知的条件下才可以被调用的方法,这个类往往也应该有个单独的“状态测试" (statetesting)方法,即指示是否可以调用这个状态相关的方法。
例如, Iterator接口有一个“状态相关”的next方法,及相应的状态测试方法hasNext。这使得利用传统的for循环(以及for-each循环,在内部使用了hasNext方法)对集合进行迭代的标准模式成为可能:
第70条:对可恢复的情况使用受检异常,对编程错误使用运行时异常
Java程序设计语言提供了三种可抛出结构(throwable) :受检异常(checked exception)、运行时异常( run-time exception)和错误( error)。
在决定使用受检异常或是未受检异常时,主要的原则是:
如果期望调用者能够适当地恢复,对于这种情况就应该使用受检异常。通过抛出受检的异常,强迫调用者在一个catch子句中处理该异常,或者将它传播出去。
因此,方法中声明要抛出的每个受检异常,都是对API用户的一种潜在指示:与异常相关联的条件是调用这个方法的一种可能的结果。API的设计者让API用户面对受检异常,以此强制用户从这个异常条件中恢复。用户可以忽视这样的强制要求,只需捕获异常并忽略即可,但这往往不是个好办法(详见第77条)。
有两种未受检的可抛出结构:运行时异常和错误。在行为上两者是等同的:它们都是不需要也不应该被捕获的可抛出结构。
如果程序抛出未受检的异常或者错误,往往就属于不"可恢复的情形,继续执行下去有害无益。
如果程序没有捕捉到这样的可抛出结构,将会导致当前线程中断(halt),并出现适当的错误消息。
第71条:避免不必要地使用受检异常
第72条:优先使用标准的异常
第73条:抛出与抽象对应的异常
第74条:每个方法抛出的所有异常都要建立文档
第75条:在细节消息中包含失败捕获信息
第76条:努力使失败保持原子性
当对象抛出异常之后,通常我们期望这个对象仍然保持在一种定义良好的可用状态之中,即使失败是发生在执行某个操作的过程中间。对于受检异常而言,这尤为重要,因为调用者期望能从这种异常中进行恢复。一般而言,失败的方法调用应该使对象保持在被调用之前的状态。具有这种属性的方法被称为具有失败原子性(failure atomic)
- 一种类似的获得失败原子性的办法是,调整计算处理过程的顺序,使得任何可能会失败的计算部分都在对象状态被修改之前发生。如果对参数的检查只有在执行了部分计算之后才能进行,这种办法实际上就是上一种办法的自然扩展。
比如,以TreeMap的情形为例,它的元素被按照某种特定的顺序做了排序。为了向TreeMap中添加元素,该元素的类型就必须是可以利用TreeMap的排序准则与其他元素进行比较的。如果企图增加类型不正确的元素,在tree以任何方式被修改之前, 自然会导致ClassCastException异常。
总而言之,作为方法规范的一部分,它产生的任何异常都应该让对象保持在调用该方法之前的状态。如果违反这条规则, API文档就应该清楚地指明对象将会处于什么样的状态。遗憾的是,大量现有的API文档都未能做到这一点。
第77条:不要忽略异常
忽略一个异常很容易,空的catch块会使异常达不到应有的目的
public static void catch_demo_(){
try {
// 可能出现异常代码
}catch (Exception e){
// 空的catch块会使异常达不到应有的目的
}
}如果选择忽略异常, catch块中应该包含条注释,说明为什么可以这么做,并且变量应该命名为ignored:

![]()

- 点赞
- 收藏
- 关注作者
评论(0)