机器学习进阶 第一节 第八课

概述
算法是核心, 数据和计算是基础. 这句话很好的说明了机器学习中算法的重要性. 那么我们开看下机器学习的几种分类:
- 监督学习
分类 k-近邻算法, 决策树, 贝叶斯, 逻辑回归 (LR), 支持向量机 (SVM)
回归 线性回归, 岭回归
标注 隐马尔可夫模型 (HMM) - 无监督学习
聚类 k-means
如何选择合适的算法模型
在解决问题的时候, 必须考虑下面两个问题: 1. 使用机器学习算法的目的, 想要算法完成何种任务, 比如是预测明天下雨的概率是对投票者按照兴趣分组. 2. 需要分析或者收集的数据是什么.
首先考虑使用机器学习算法的目的. 如果想要预测目标变量的值, 则可以选择监督学习算法. 否则可以选择无监督学习算法, 确定选择监督学习算法之后, 需要进一步确定目标变量类型. 如果目标变量是离散型, 如 是/否, 1/2/3, A/B/C 或者 红/黑/黄 等, 则可以选择分类算法. 如果目标变量是连续的数值, 如 0.0~100.0, -999~999 等, 则需要选择回归算法.
如果不想预测目标变量的值, 则可以选择无监督算法. 进一步分析是否需要将数据划分为离散的组. 如果这是唯一的需求, 则使用聚类算法.
其次考虑的是数据问题, 我们应该充分了解数据, 对实际数据了解的越充分, 越容易创建符合实际需求的应用程序. 主要应了解数据的特征: 特征值是离散型变量还是连续型变量. 特征值中是否存在缺失的值, 何种原因造成缺失值, 数据中是否存在异常值, 某个特征发生的频率如何,等等. 充分了解上面提到的这些数据特征可以缩短选择及其学习算法的时间.
监督学习中三类问题的解释
分类问题
分类问题是监督学习的一个核心问题. 在监督学习中, 当输出变量取有限个离散值时, 预测问题变成为分类问题. 这是, 输入变量可以是离散的. 也可以是连续的. 监督学习从数据中学习一个分类模型活分类决策函数, 称为分类器. 分类器对新的输入进行输出的预测, 称为分类. 最基础的便是二分类问题, 即判断是非, 从两个类别中选择一个作为预测结果. 除此之外还有多分类的问题, 即在多于两个类别中选择一个.
分类问题包括学习和分类两个过程, 在学习过程中. 根据已知的训练数据集利用有效的学习方法学习一个分类器, 在分类过程, 利用学习的分类器对新的输入实例进行分类. 图中 (X1, Y1), (X2,Y2)…都是训练数据集, 学习系统有训练数据学习一个分类器 P(Y|X) 或 Y=f(X). 分类系统通过学习到的分类器对于新输入的实例 Xn+1 进行分类, 即预测其输出的标记 Yn + 1.
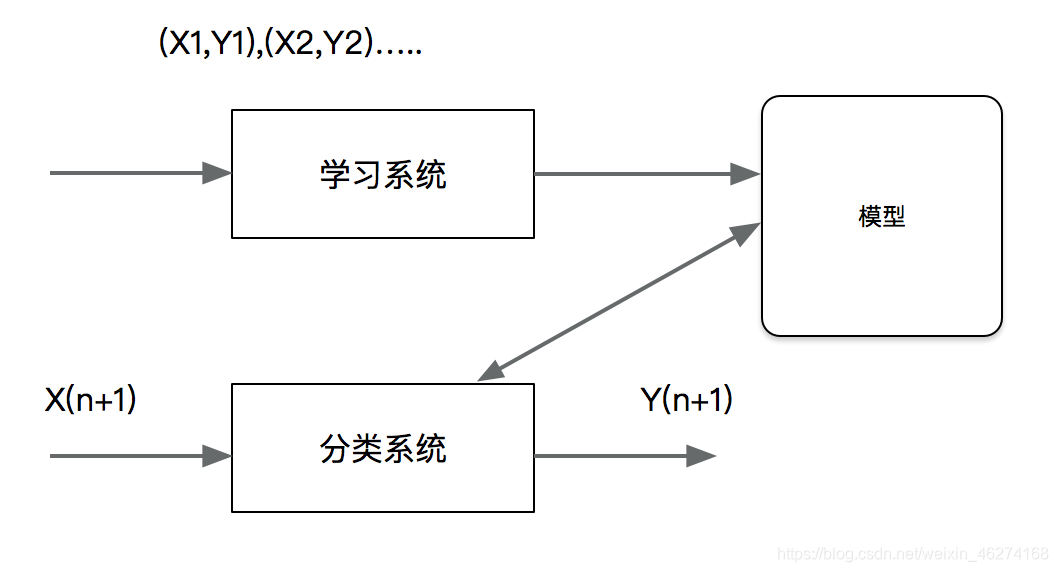
分类在于根据其特性将数据 “分门别类”, 所以在许多领域都有广泛的应用. 例如, 在银行业务中, 可以构建一个客户分类模型, 按客户按照贷款风险的大小进行分类. 在网络安全领域, 可以利用日志数据的分类对非法入侵进行检测. 在图像处理中, 分类可以用来检测图像中是否有人脸出现. 在手写识别中, 分类可以用于识别手写的数字. 在互联网搜索中, 网页的分类可以帮助网页的抓取, 索引和排序.
回归问题
回归是监督学习的另一个重要问题. 回归用于预测输入变量和输出变量之间的关系, 特别是当初如变量的值发生变化时, 输出的变量值随之发生变化. 回归模式正式表示从输入到输出变量之间映射的函数. 回归问题的学习等价与函数拟合: 选择一条函数曲线时期更好的拟合已知数据且很好的预测位置数据.
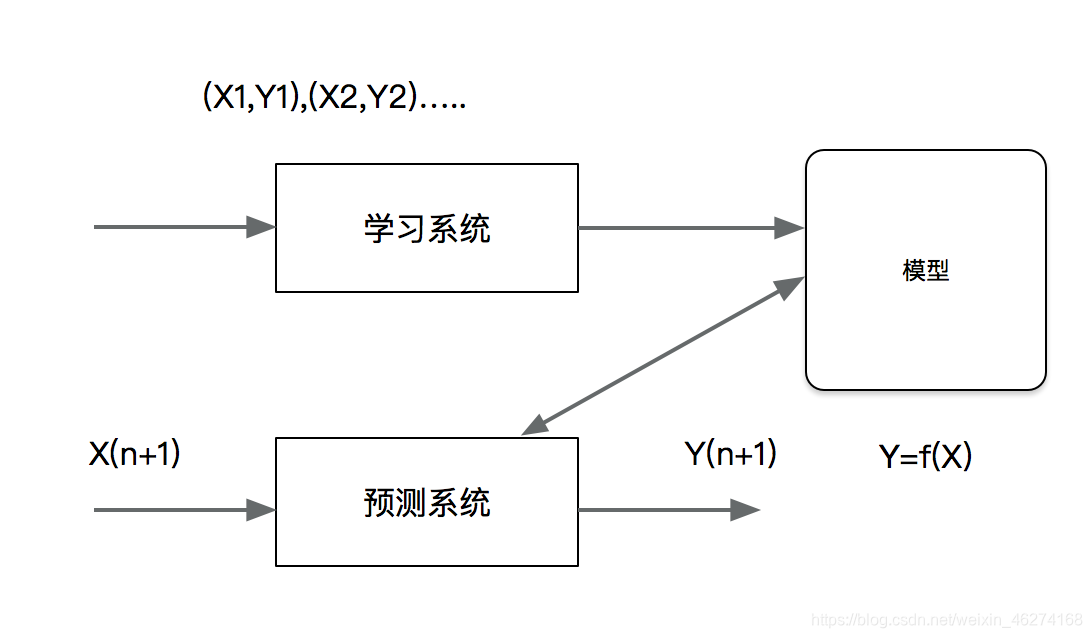
回归问题按照输入变量的个数, 分为一元回归和多元回归. 按照输入变量和输出变量之间关系的类型, 分为线性回归和非线性回归.
许多领域的任务都可以形式化为回归问题, 比如, 回归可以用于商务领域, 作为市场趋势预测, 产品质量管理, 客户满意度调查, 偷袭风险分析的工具.
标注问题
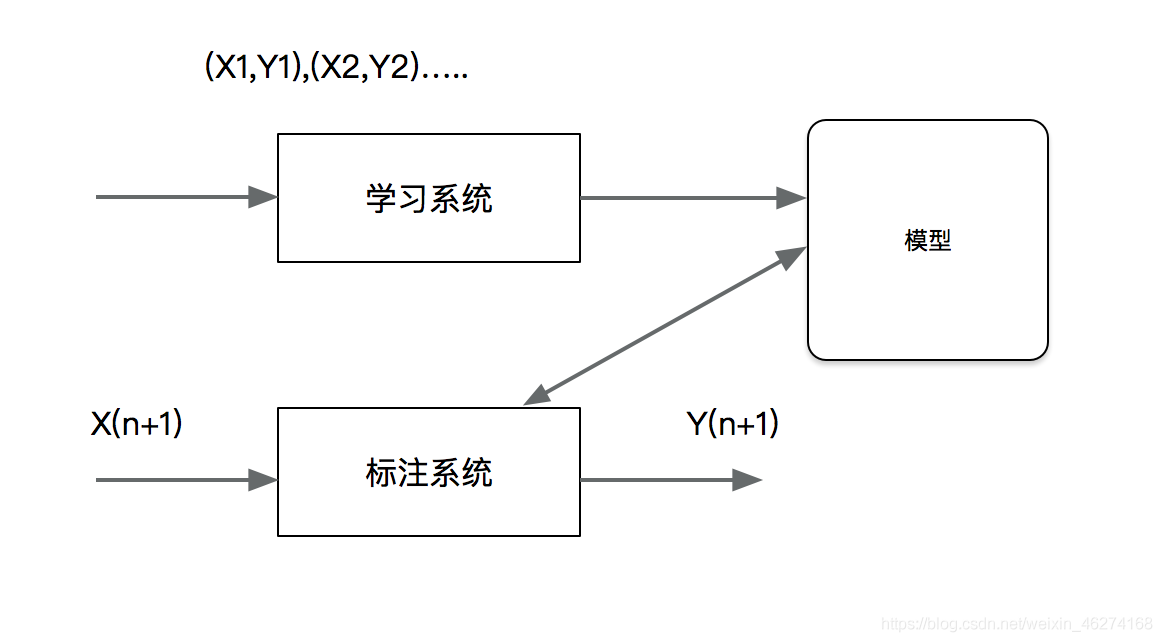
标注也是一个监督学习问题. 可以认为标注问题是分类问题的一个推广, 标注问题又是更复杂的结构预测问题的简单形式. 标注问题的输入的一个观测序列, 输出是一个标记序列或状态序列. 标注问题在系信息抽取, 自然语言处理等领域广泛应用, 是这些领域的基本问题. 例如, 自然语言处理的词性标注就对一个典型的标注, 即对一个单词序列预测其相应的词性标记.
文章来源: iamarookie.blog.csdn.net,作者:我是小白呀,版权归原作者所有,如需转载,请联系作者。
原文链接:iamarookie.blog.csdn.net/article/details/110849299

- 点赞
- 收藏
- 关注作者
评论(0)