关系数据库——范式/反范式的利弊权衡和建议

范式(避免数据冗余和操作异常)
函数依赖
A->B A和B是两个属性集,来自同一关系模式,对于同样的A属性值,B属性值也相同
平凡的函数依赖
X->Y,如果Y是X的子集
非平凡的函数依赖
X->Y,如果Y不是X的子集
部分函数依赖
X->Y,如果存在W->Y,且W⊂X
传递函数依赖
在R(U)中,如果X→Y(非平凡函数依赖,完全函数依赖),Y→Z, 则称Z对X传递函数依赖。
记为:X![]() Z
Z
super key&candidate key&primary key&主属性&非主属性
super key:在关系中能唯一标识元素的属性集
candidate key或key:不含有多余属性的super key
primary key:在candidate key 中任选一个
candidate key中X决定所有属性的函数依赖是完全函数依赖
包含在任何一个candidate key中的属性 ,称为主属性
不包含在candidate key中的属性称为非主属性
1NF 列不可分
列不可分
2NF 消除了非主属性对键的部分函数依赖
在关系T上有函数依赖集F,F+是F的闭包。
F满足2NF,当且仅当 每个非平凡的函数依赖X->A(F+),A是单个非主属性,要求X不是任何key的真子集(有可能是super key,也有可能是非key)。
3NF 消除了非主属性对键的传递函数依赖
F满足3NF,当且仅当 每个非平凡的函数依赖X->A(F+),A是单个非主属性,要求X是T的super key。
BCNF 消除了主属性对键的部分函数依赖和传递函数依赖
F满足BCNF,当且仅当 每个非平凡的函数依赖X->A(F+),A是单个属性,要求X是T的super key。
对于F+中 的任意一个X->A,如果A是单个属性,且A不在X中,那么X一定是T的super key。
反范式(减少连接,提高查询效率)
没有冗余的数据库未必是最好的数据库,有时为了提高运行效率,就必须降低范式标准,适当保留冗余数据。具体做法是: 在概念数据模型设计时遵守第三范式,降低范式标准的工作放到物理数据模型设计时考虑。降低范式就是增加字段,减少了查询时的关联,提高查询效率,因为在数据库的操作中查询的比例要远远大于DML的比例。但是反范式化一定要适度,并且在原本已满足三范式的基础上再做调整的。
Pattern1:合并1对1关系
| car_id |
car_name |
| 1 |
c1 |
| 2 |
c2 |
| 3 |
c3 |
teacher
| teacher_id |
teacher_name |
| 1 |
t1 |
| 2 |
t2 |
| 3 |
t3 |
| 4 |
t4 |
合并后
car_and_teacher
| car_id |
car_name |
teacher_id |
teacher_name |
| 1 |
c1 |
1 |
t1 |
| 2 |
c2 |
2 |
t2 |
| 3 |
c3 |
3 |
t3 |
| NULL |
NULL |
4 |
t4 |
问题:会产生大量空值,若两边都部分参与则不能合并;
部分参与为大部分参与时比较适合Pattern1
Pattern2:1对N关系中复制非键属性以减少连接
两表连接时复制非键属性以减少连接
例:查询学生以及所在学院名,可以在学生表中不仅存储学院id,并且存储学院名
faculty
| fid |
fname |
| 1 |
f1 |
student
| sid |
sname |
fid |
fname |
| 1 |
s1 |
1 |
f1 |
维护时:
1)如果在UI中,只允许用户进行选择,不能自行输入,保证输入一致性
2)如果是程序员,对于类似学院名这种一般不变的代码表,在修改时直接对两张表都进行修改;如果经常变化,则可以加一个触发器。
Pattern3:1对N关系中复制外键以减少连接
把另一张表的主键复制变成外键

应用后:
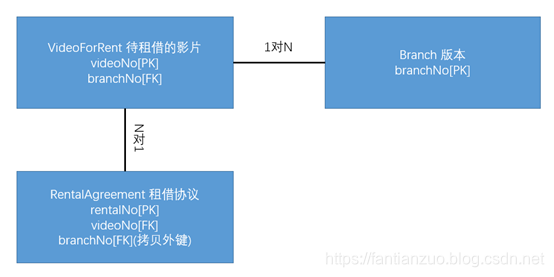
Pattern4:N对N关系中复制属性,把两张表中经常需要的内容复制到中间关系表中以减少连接

Pattern5:引入重复值
通常对于一个多值属性,值不太多,且不会经常变,可以在表中建立多个有关此属性的列
address1 | address2 | address3 | address4
Pattern6:建立提取表
为了解决查询和更新之间不可调和的矛盾,可以将更新和查询放在两张表中,从工作表中提取查询表,专门用于查询。只适用于查询实时性不高的情况。
Pattern7:分表
水平拆分
垂直拆分
文章来源: fantianzuo.blog.csdn.net,作者:兔老大RabbitMQ,版权归原作者所有,如需转载,请联系作者。
原文链接:fantianzuo.blog.csdn.net/article/details/103324706

- 点赞
- 收藏
- 关注作者
评论(0)