深度学习应用篇-元学习[14]:基于优化的元学习-MAML模型、LEO模型、Reptile模型
1.Model-Agnostic Meta-Learning
Model-Agnostic Meta-Learning (MAML):
与模型无关的元学习,可兼容于任何一种采用梯度下降算法的模型。
MAML 通过少量的数据寻找一个合适的初始值范围,从而改变梯度下降的方向,
找到对任务更加敏感的初始参数,
使得模型能够在有限的数据集上快速拟合,并获得一个不错的效果。
该方法可以用于回归、分类以及强化学习。
该模型的Paddle实现请参考链接:PaddleRec版本
1.1 MAML
MAML 是典型的双层优化结构,其内层和外层的优化方式如下:
1.1.1 MAML 内层优化方式
内层优化涉及到基学习器,从任务分布
p(T) 中随机采样第
i 个任务
Ti。任务
Ti 上,基学习器的目标函数是:
ϕminLTi(fϕ)
其中,
fϕ 是基学习器,
ϕ 是基学习器参数,
LTi(fϕ) 是基学习器在
Ti 上的损失。更新基学习器参数:
θiN=θiN−1−α[∇ϕLTi(fϕ)]ϕ=θiN−1
其中,
θ 是元学习器提供给基学习器的参数初始值
ϕ=θ,在任务
Ti 上更新
N 后
ϕ=θiN−1.
1.1.2 MAML 外层优化方式
外层优化涉及到元学习器,将
θiN 反馈给元学匀器,此时元目标函数是:
θminTi∼p(T)∑LTi(fθiN)
元目标函数是所有任务上验证集损失和。更新元学习器参数:
θ←θ−βTi∼p(T)∑∇θ[LTi(fϕ)]ϕ=θiN
1.2 MAML 算法流程
- randomly initialize
θ
- while not done do:
- sample batch of tasks
Ti∼p(T)
- for all
Ti do:
- evaluate
∇ϕLTi(fϕ) with respect to K examples
- compute adapted parameters with gradient descent: $\theta_{i}^{N}=\theta_{i}^{N-1} -\alpha\left[\nabla_{\phi}L_{T_{i}}\left(f_{\phi}\right)\right]{\phi=\theta{i}^{N-1}} $
- end for
- update $\theta \leftarrow \theta-\beta \sum_{T_{i} \sim p(T)} \nabla_{\theta}\left[L_{T_{i}}\left(f_{\phi}\right)\right]{\phi=\theta{i}^{N}} $
- end while
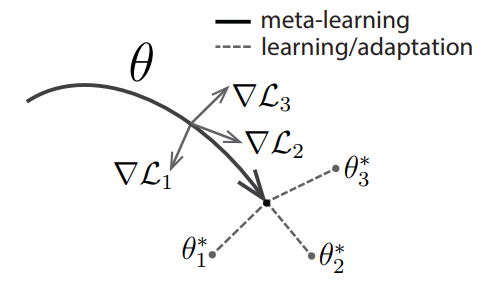
MAML 中执行了两次梯度下降 (gradient by gradient),分别作用在基学习器和元学习器上。图1给出了 MAML 中特定任务参数
θi∗ 和元级参数
θ 的更新过程。

图1 MAML 示意图。灰色线表示特定任务所产生的梯度值(方向);黑色线表示元级参数选择更新的方向(黑色线方向是几个特定任务产生方向的平均值);虚线代表快速适应,不同的方向代表不同任务更新的方向。
1.3 MAML 模型结构
MAML 是一种与模型无关的元学习方法,可以适用于任何基于梯度优化的模型结构。
基准模型:4 modules with a 3
× 3 convolutions and 64 filters,
followed by batch normalization,
a ReLU nonlinearity,
and 2
× 2 max-pooling。
1.4 MAML 分类结果
表1 MAML 在 Omniglot 上的分类结果。
| Method |
5-way 1-shot |
5-way 5-shot |
20-way 1-shot |
20-way 5-shot |
| MANN, no conv (Santoro et al., 2016) |
82.8
% |
94.9
% |
– |
– |
| MAML, no conv |
89.7
± 1.1
% |
97.5
± 0.6
% |
– |
– |
| Siamese nets (Koch, 2015) |
97.3
% |
98.4
% |
88.2
% |
97.0
% |
| matching nets (Vinyals et al., 2016) |
98.1
% |
98.9
% |
93.8
% |
98.5
% |
| neural statistician (Edwards & Storkey, 2017) |
98.1
% |
99.5
% |
93.2
% |
98.1
% |
| memory mod. (Kaiser et al., 2017) |
98.4
% |
99.6
% |
95.0
% |
98.6
% |
| MAML |
98.7
± 0.4
% |
99.9
± 0.1
% |
95.8
± 0.3
% |
98.9
± 0.2
% |
表1 MAML 在 miniImageNet 上的分类结果。
| Method |
5-way 1-shot |
5-way 5-shot |
| fine-tuning baseline |
28.86
± 0.54
% |
49.79
± 0.79
% |
| nearest neighbor baseline |
41.08
± 0.70
% |
51.04
± 0.65
% |
| matching nets (Vinyals et al., 2016) |
43.56
± 0.84
% |
55.31
± 0.73
% |
| meta-learner LSTM (Ravi & Larochelle, 2017) |
43.44
± 0.77
% |
60.60
± 0.71
% |
| MAML, first order approx. |
48.07
± 1.75
% |
63.15
± 0.91
% |
| MAML |
48.70
± 1.84
% |
63.11
± 0.92
% |
1.5 MAML 的优缺点
优点
缺点
1.6 对 MAML 的探讨
每个任务上的基学习器必须是一样的,对于差别很大的任务,最切合任务的基学习器可能会变化,那么就不能用 MAML 来解决这类问题。
MAML 适用于所有基于随机梯度算法求解的基学习器,这意味着参数都是连续的,无法考虑离散的参数。对于差别较大的任务,往往需要更新网络结构。使用 MAML 无法完成这样的结构更新。
MAML 使用的损失函数都是可求导的,这样才能使用随机梯度算法来快速优化求解,损失函数中不能有不可求导的奇异点,否则会导致优化求解不稳定。
MAML 中考虑的新任务都是相似的任务,所以没有对任务进行分类,也没有计算任务之间的距离度量。对每一类任务单独更新其参数初始值,每一类任务的参数初始值不同,这些在 MAML 中都没有考虑。
[1] Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks.
2.Latent Embedding Optimization
Latent Embedding Optimization (LEO) 学习模型参数的低维潜在嵌入,并在这个低维潜在空间中执行基于优化的元学习,将基于梯度的自适应过程与模型参数的基础高维空间分离。
2.1 LEO
在元学习器中,使用 SGD 最小化任务验证集损失函数,
使得模型的泛化能力最大化,计算元参数,元学习器将元参数输入基础学习器,
继而,基础学习器最小化任务训练集损失函数,快速给出任务上的预测结果。
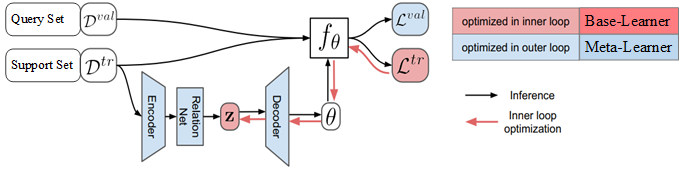
LEO 结构如图1所示。
图1 LEO 结构图。
Dtr 是任务
ε 的 support set,
Dval 是任务
ε 的 query set,
z 是通过编码器计算的
N 个类别的类别特征,
fθ 是基学习器,
θ 是基学习器参数,
Ltr=fθ(Dtr),
Lval=fθ(Dval)。
LEO 包括基础学习器和元学习器,还包括编码器和解码器。
在基础学习器中,编码器将高维输入数据映射成特征向量,
解码器将输入数据的特征向量映射成输入数据属于各个类别的概率值,
基础学习器使用元学习器提供的元参数进行参数更新,给出数据标注的预测结果。
元学习器为基础学习器的编码器和解码器提供元参数,
元参数包括特征提取模型的参数、编码器的参数、解码器的参数等,
通过最小化所有任务上的泛化误差,更新元参数。
2.2 基础学习器
编码器和解码器都在基础学习器中,用于计算输入数据属于每个类别的概率值,
进而对输入数据进行分类。
元学习器提供编码器和解码器中的参数,基础学习器快速的使用编码器和解码器计算输入数据的分类。
任务训练完成后,基础学习器将每个类别数据的特征向量和任务
ε 的基础学习器参数
θε 输入元学习器,
元学习器使用这些信息更新元参数。
2.2.1 编码器
编码器模型包括两个主要部分:编码器和关系网络。
编码器
gϕe ,其中
ϕe 是编码器的可训练参数,
其功能是将第
n 个类别的输入数据映射成第
n 个类别的特征向量。
关系网络
gϕr ,其中
ϕr 是关系网络的可训练参数,
其功能是计算特征之间的距离。
第
n 个类别的输入数据的特征记为
zn 。
对于输入数据,首先,使用编码器
gϕe 对属于第
n 个类别的输入数据进行特征提取;
然后,使用关系网络
gϕr 计算特征之间的距离,
综合考虑训练集中所有样本点之间的距离,计算这些距离的平均值和离散程度;
第
n 个类别输入数据的特征
zn 服从高斯分布,
且高斯分布的期望是这些距离的平均值,高斯分布的方差是这些距离的离散程度,
具体的计算公式如下:
μne,σne=NK21kn=1∑Km=1∑Nkm=1∑Kgϕr[gϕe(xnkn),gϕe(xmkm)]zn∼q(zn∣Dntr)=N{μne,diag(σne)2}
其中,
N 是类别总数,
K 是每个类别的图片总数,
Dntr 是第
n 个类别的训练数据集。
对于每个类别的输入数据,每个类别下有
K 张图片,
计算这
K 张图片和所有已知图片之间的距离。
总共有
N 个类别,通过编码器的计算,形成所有类别的特征,
记为
z=(z1,⋯,zN)。
2.2.2 解码器
解码器
gϕd ,其中
ϕd 是解码器的可训练参数,
其功能是将每个类别输入数据的特征向量
zn
映射成属于每个类别的概率值
wn:
μnd,σnd=gϕd(zn)wn∼q(w∣zn)=N{μnd,diag(σnd)2}
其中,任务
ε 的基础学习器参数记为
θε,
基础学习器参数由属于每个类别的概率值组成,
记为
θε=(w1,w2,⋯,wN),
基础学习器参数
wn 指的是输入数据属于第
n 个类别的概率值,
gϕd 是从特征向量到基础学习器参数的映射。
图2 LEO 基础学习器工作原理图。
2.2.3 基础学习器更新过程
在基础学习器中,任务
ε 的交叉熵损失函数是:
Lεtr(fθε)=(x,y)∈Dεtr∑[−wyx+logj=1∑Newjx]
其中,
(x,y) 是任务
ε 训练集
Dεtr 中的样本点,
fθε 是任务
ε 的基础学习器,
最小化任务
ε 的损失函数更新任务专属参数
θε 。
在解码器模型中,任务专属参数为
wn∼q(w∣zn),
更新任务专属参数
θε 意味着更新特征向量
zn:
zn′=zn−α∇znLεtr(fθε),
其中,
zn′ 是更新后的特征向量,
对应的是更新后的任务专属参数
θε′。
基础学习器使用
θε′ 来预测任务验证集数据的标注,
将任务
ε 的验证集
Dεval
损失函数
Lεval(fθε′) 、
更新后的特征向量
zn′、
更新后的任务专属参数
θε′ 输入元学习器,
在元学习器中更新元参数。
2.3 元学习器更新过程
在元学习器中,最小化所有任务
ε 的验证集的损失函数的求和,
最小化任务上的模型泛化误差:
ϕe,ϕr,ϕdminε∑[Lεval(fθε′)+βDKL{q(zn∣Dntr)∥p(zn)}+γ∥s(zn′)−zn∥22]+R
其中,
Lεval(fθε′) 是任务
ε 验证集的损失函数,
衡量了基础学习器模型的泛化误差,损失函数越小,模型的泛化能力越好。
p(zn)=N(0,I) 是高斯分布,
DKL{q(zn∣Dntr)∥p(zn)} 是近似后验分布
q(zn∣Dntr ) 与先验分布
p(zn) 之间的 KL 距离 (KL-Divergence),
最小化
KL 距离可使后验分布
q(zn∣Dntr) 的估计尽可能准确。
最小化距离
∥s(zn′)−zn∥ 使得参数初始值
zn 和训练完成后的参数更新值
zn′ 距离最小,
使得参数初始值和参数最终值更接近。
R 是正则项, 用于调控元参数的复杂程度,避免出现过拟合,正则项
R 的计算公式如下:
R=λ1(∥ϕe∥22+∥ϕr∥22+∥ϕd∥22)+λ2∥Cd−I∥2
其中,
∥ϕr∥22 指的是调控元参数的个数和大小,
Cd 是参数
ϕd 的行和行之间的相关性矩阵,
超参数
λ1,λ2>0,
∥Cd−I∥2 使得
Cd 接近单位矩阵,
使得参数
ϕd 的行和行之间的相关性不能太大,
每个类别的特征向量之间的相关性不能太大,
属于每个类别的概率值之间的相关性也不能太大,分类要尽量准确。
2.4 LEO 算法流程
LEO 算法流程
- randomly initialize
ϕe,ϕr,ϕd
- let
ϕ={ϕe,ϕr,ϕd,α}
- while not converged do:
- for number of tasks in batch do:
- sample task instance
Ti∼Str
- let
(Dtr,Dval)=Ti
- encode
Dtr to z using
gϕe and
gϕr
- decode
z to initial params
θi using
gϕd
- initialize
z′=z,θi′=θi
- for number of adaptation steps do:
- compute training loss
LTitr(fθi′)
- perform gradient step w.r.t.
z′:
-
z′←z′−α∇z′LTitr(fθi′)
- decode
z′ to obtain
θi′ using
gϕd
- end for
- compute validation loss
LTival(fθi′)
- end for
- perform gradient step w.r.t
ϕ:
ϕ←ϕ−η∇ϕ∑TiLTival(fθi′)
- end while
(1) 初始化元参数:编码器参数
ϕe、关系网络参数
ϕr、解码器参数
ϕd,
在元学习器中更新的元参数包括
ϕ={ϕe,ϕr,ϕd}。
(2) 使用片段式训练模式,
随机抽取任务
ε,
Dεtr 是任务
ε 的训练集,
Dεval 是任务
ε 的验证集。
(3) 使用编码器
gϕe 和关系网络
gϕr 将任务
ε 的训练集
Dεtr 编码成特征向量
z,
使用 解码器
gϕd 从特征向量映射到任务
ε 的基础学习器参数
θε,
基础学习器参数指的是输入数据属于每个类别的概率值向量;
计算任务
ε 的训练集的损失函数
Lεtr(fθε),
最小化任务
ε 的损失函数,更新每个类别的特征向量:
zn′=zn−α∇znLεtr(fθε)
使用解码器
gϕd 从更新后的特征向量映射到更新后的任务
ε 的基础学习器参数
θε′;
计算任务
ε 的验证集的损失函数
Lεval(fθs′);
基础学习器将更新后的参数和验证集损失函数值输入元学习器。
(4) 更新元参数,
ϕ←ϕ−η∇ϕ∑εLεval(fθε′),
最小化所有任务
ε 的验证集的损失和,
将更新后的元参数输人基础学习器,继续处理新的分类任务。
2.5 LEO 模型结构
LEO 是一种与模型无关的元学习,[1] 中给出的各部分模型结构及参数如表1所示。
表1 LEO 各部分模型结构及参数。
| Part of the model |
Architecture |
Hiddenlayer |
Shape of the output |
| Inference model (
fθ) |
3-layer MLP with ReLU |
40 |
(12, 5, 1) |
| Encoder |
3-layer MLP with ReLU |
16 |
(12, 5, 16) |
| Relation Network |
3-layer MLP with ReLU |
32 |
(12,
2×16) |
| Decoder |
3-layer MLP with ReLU |
32 |
(12,
2×1761) |
2.6 LEO 分类结果
表1 LEO 在 miniImageNet 上的分类结果。
| Model |
5-way 1-shot |
5-way 5-shot |
| Matching networks (Vinyals et al., 2016) |
43.56
± 0.84
% |
55.31
± 0.73
% |
| Meta-learner LSTM (Ravi & Larochelle, 2017) |
43.44
± 0.77
% |
60.60
± 0.71
% |
| MAML (Finn et al., 2017) |
48.70
± 1.84
% |
63.11
± 0.92
% |
| LLAMA (Grant et al., 2018) |
49.40
± 1.83
% |
– |
| REPTILE (Nichol & Schulman, 2018) |
49.97
± 0.32
% |
65.99
± 0.58
% |
| PLATIPUS (Finn et al., 2018) |
50.13
± 1.86
% |
– |
| Meta-SGD (our features) |
54.24
± 0.03
% |
70.86
± 0.04
% |
| SNAIL (Mishra et al., 2018) |
55.71
± 0.99
% |
68.88
± 0.92
% |
| (Gidaris & Komodakis, 2018) |
56.20
± 0.86
% |
73.00
± 0.64
% |
| (Bauer et al., 2017) |
56.30
± 0.40
% |
73.90
± 0.30
% |
| (Munkhdalai et al., 2017) |
57.10
± 0.70
% |
70.04
± 0.63
% |
| DEML+Meta-SGD (Zhou et al., 2018) |
58.49
± 0.91
% |
71.28
± 0.69
% |
| TADAM (Oreshkin et al., 2018) |
58.50
± 0.30
% |
76.70
± 0.30
% |
| (Qiao et al., 2017) |
59.60
± 0.41
% |
73.74
± 0.19
% |
| LEO |
61.76
± 0.08
% |
77.59
± 0.12
% |
表1 LEO 在 tieredImageNet 上的分类结果。
| Model |
5-way 1-shot |
5-way 5-shot |
| MAML (deeper net, evaluated in Liu et al. (2018)) |
51.67
± 1.81
% |
70.30
± 0.08
% |
| Prototypical Nets (Ren et al., 2018) |
53.31
± 0.89
% |
72.69
± 0.74
% |
| Relation Net (evaluated in Liu et al. (2018)) |
54.48
± 0.93
% |
71.32
± 0.78
% |
| Transductive Prop. Nets (Liu et al., 2018) |
57.41
± 0.94
% |
71.55
± 0.74
% |
| Meta-SGD (our features) |
62.95
± 0.03
% |
79.34
± 0.06
% |
| LEO |
66.33
± 0.05
% |
81.44
± 0.09
% |
2.7 LEO 的优点
3.Reptile
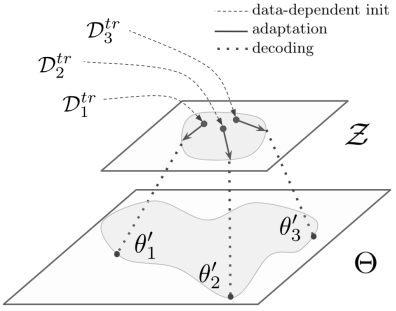
Reptil 是 MAML 的特例、近似和简化,主要解决 MAML 元学习器中出现的高阶导数问题。
因此,Reptil 同样学习网络参数的初始值,并且适用于任何基于梯度的模型结构。
在 MAML 的元学习器中,使用了求导数的算式来更新参数初始值,
导致在计算中出现了任务损失函数的二阶导数。
在 Reptile 的元学习器中,参数初始值更新时,
直接使用了任务上的参数估计值和参数初始值之间的差,
来近似损失函数对参数初始值的导数,进行参数初始值的更新,从而不会出现任务损失函数的二阶导数。
Peptile 有两个版本:Serial Version 和 Batched Version,两者的差异如下:
3.1 Serial Version Reptile
单次更新的 Reptile,每次训练完一个任务的基学习器,就更新一次元学习器中的参数初始值。
(1) 任务上的基学习器记为
fϕ ,其中
ϕ 是基学习器中可训练的参数,
θ 是元学习器提供给基学习器的参数初始值。
在任务
Ti 上,基学习器的损失函数是
LTi(fϕ) ,
基学习器中的参数经过
N 次迭代更新得到参数估计值:
θiN=SGD(LTi,θ,N)
(2) 更新元学习器中的参数初始值:
θ←θ+ε(θiN−θ)
Serial Version Reptile 算法流程
- initialize
θ, the vector of initial parameters
- for iteration=1, 2, … do:
- sample task
Ti, corresponding to loss
LTi on weight vectors
θ
- compute
θiN=SGD(LTi,θ,N)
- update
θ←θ+ε(θiN−θ)
- end for
3.2 Batched Version Reptile
批次更新的 Reptile,每次训练完多个任务的基学习器之后,才更新一次元学习器中的参数初始值。
(1) 在多个任务上训练基学习器,每个任务从参数初始值开始,迭代更新
N 次,得到参数估计值。
(2) 更新元学习器中的参数初始值:
θ←θ+εn1i=1∑n(θiN−θ)
其中,
n 是指每次训练完
n 个任务上的基础学习器后,才更新一次元学习器中的参数初始值。
Batched Version Reptile 算法流程
- initialize
θ
- for iteration=1, 2, … do:
- sample tasks
T1,
T2, … ,
Tn,
- for i=1, 2, … , n do:
- compute
θiN=SGD(LTi,θ,N)
- end for
- update
θ←θ+εn1∑i=1n(θiN−θ)
- end for
3.3 Reptile 分类结果
表1 Reptile 在 Omniglot 上的分类结果。
| Algorithm |
5-way 1-shot |
5-way 5-shot |
20-way 1-shot |
20-way 5-shot |
| MAML + Transduction |
98.7
± 0.4
% |
99.9
± 0.1
% |
95.8
± 0.3
% |
98.9
± 0.2
% |
|
1st-order MAML + Transduction |
98.3
± 0.5
% |
99.2
± 0.2
% |
89.4
± 0.5
% |
97.9
± 0.1
% |
| Reptile |
95.32
± 0.05
% |
98.87
± 0.02
% |
88.27
± 0.30
% |
97.07
± 0.12
% |
| Reptile + Transduction |
97.97
± 0.08
% |
99.47
± 0.04
% |
89.36
± 0.20
% |
97.47
± 0.10
% |
表1 Reptile 在 miniImageNet 上的分类结果。
| Algorithm |
5-way 1-shot |
5-way 5-shot |
| MAML + Transduction |
48.70
± 1.84
% |
63.11
± 0.92
% |
|
1st-order MAML + Transduction |
48.07
± 1.75
% |
63.15
± 0.91
% |
| Reptile |
45.79
± 0.44
% |
61.98
± 0.69
% |
| Reptile + Transduction |
48.21
± 0.69
% |
66.00
± 0.62
% |
更多优质内容请关注公重号:汀丶人工智能


评论(0)