秒懂算法 | MNIST手写体识别


来源于谷歌的TensorFlow是目前Python编程领域最热门的深度学习框架。Google不仅是大数据和云计算的领导者,在机器学习和深度学习上也有很好的实践和积累,在2015年年底开源了内部使用的深度学习框架TensorFlow。
与Caffe、Theano、Torch、MXNet等框架相比,TensorFlow在Github上Fork数和Star数都是最多的,而且在图形分类、音频处理、推荐系统和自然语言处理等场景下都有丰富的应用。
最近流行的Keras框架底层默认使用TensorFlow,著名的斯坦福CS231n课程使用TensorFlow作为授课和作业的编程语言,国内外多本TensorFlow书籍已经在筹备或者发售中,AlphaGo开发团队Deepmind也计划将神经网络应用迁移到TensorFlow中,这无不印证了TensorFlow在业界的流行程度。
TensorFlow的流行让深度学习门槛变得越来越低,只要有Python和机器学习基础,入门和使用神经网络模型就会变得非常简单。
TensorFlow支持Python和C++两种编程语言,再复杂的多层神经网络模型都可以用Python实现,如果业务使用其他编程也不用担心,使用跨语言的gRPC或者HTTP服务也可以访问使用TensorFlow训练好的智能模型。
那使用Python如何编写TensorFlow应用呢?从入门到应用究竟有多难呢?

下面介绍一个神经网络中的经典示例———MNIST手写体识别。
这个任务相当于是机器学习中的HelloWorld程序。本文以TensorFlow源码中自带的手写数字识别Example为例,引出TensorFlow中的几个主要概念,并结合Example源码一步步分析该模型的实现过程。
什么是TensorFlow?这里引入TensorFlow中文社区首页中的两段描述:
TensorFlowTM是一个基于数据流图(dataflowgraphs)用于数值计算的开源软件库。结点(nodes)在图中表示数学操作,图中的边(edges)则表示在结点间相互联系的多维数据数组,即张量(tensor)。它灵活的架构让你可以在多种平台上展开计算,例如,台式计算机中的一个或多个CPU(或GPU)、服务器、移动设备等。TensorFlow最初由Google大脑小组(隶属于Google机器智能研究机构)的研究员和工程师们开发,用于机器学习和深度神经网络方面的研究,但这个系统的通用性使其也可广泛用于其他计算领域。
数据流图用“结点”和“边”的有向图描述数学计算。“结点”一般用来表示施加的数学操作,但也可以表示数据输入(feedin)的起点/输出(pushout)的终点,或者是读取/写入持久变量(persistentvariable)的终点。“边”表示“结点”之间的输入/输出关系。这些数据“边”可以输运“规模可动态调整”的多维数据数组,即“张量”。张量从图中流过的直观图像是这个工具取名为TensorFlow的原因。一旦输入端的所有张量都准备好了,结点将被分配到各种计算设备异步并行地执行运算。
01、MNIST数据集
MNIST是一个简单的图片数据集(数据集下载地址http://yann.lecun.com/exdb/minist/),包含了大量的数字手写体图片。MNIST数据集是含标注信息的。图B-1为代表5,0,4和1的图片示例。

图 B-1 代表5,0,4和1 的图片示例
由于MNIST数据集是TensorFlow的示例数据,所以不必下载。只需要下面两行代码,即可实现数据集的读取工作。
from tensorflow.examples.tutorials.mnist import input_data
mnist =input_data.read_data_sets("MNIST_data/", one_hot=True)MNIST数据集一共包含3个部分:训练数据集(55000份,mnist.train)、测试数据集(10000份,mnist.test)和验证数据集(5000份,mnist.validation)。一般来说,训练数据集用来训练模型;验证数据集可以检验训练出来的模型的正确性和是否过拟合;测试数据集是不可见的(相当于一个黑盒),但我们最终的目的是使得训练出来的模型在测试数据集上的效果(这里是准确性)达到最佳。
MNIST中的一个数据样本包含两块:手写体图片和对应的label。这里我们用xs和ys分别代表图片和对应的label,训练数据集和测试数据集都有xs和ys,我们使用mnist.train.images和mnist.train.labels表示训练数据集中图片数据和对应的label数据。
一张图片可以用28×28的像素点矩阵表示,也可以用一个同大小的二维矩阵表示,如图B-2所示。

图 B-2 一张图片用28×28的像素点矩阵表示
但是,这里我们可以先简单地使用一个长度为28×28=784的一维数组表示图像,因为下面仅使用softmax回归对图片进行识别分类(尽管这样做会损失图片的二维空间信息,所以实际上最好的计算机视觉算法是会利用图片的二维信息的)。
所以,MNIST的训练数据集可以视为一个形状为55000×784位的tensor,也就是一个多维数组,第一维表示图片的索引,第二维表示图片中像素的索引(tensor中的像素值在0~1)。
训练数据集如图B-3所示。

图 B-3 训练数据集
MNIST中的数字手写体图片的label值在1~9之间,是图片表示的真实数字。这里用One-hotvector表述label值,vector的长度为label值的数目,vector中有且只有一位为1,其他为0。为了方便,我们表示某个数字时在vector中对应的索引位置设置1,其他位置元素为0。例如,用[0,0,0,1,0,0,0,0,0,0]表示3。所以,mnist.train.labels是一个55000×10的二维数组。训练数据集上的标注如图B-4所示。

图 B-4 训练数据集上的标注
以上是MNIST数据集的描述及TensorFlow中的表示。
下面介绍Softmax回归模型。
02、Softmax回归模型
数字手写体图片的识别实际上可以转换成一个概率问题,如果知道一张图片表示9的概率为80%,而剩下的20%概率分布在8,6和其他数字上,那么从概率的角度上,可以大致推断该图片表示的是9。
Softmax回归(regression)是一个简单的模型,很适合用来处理得到一个待分类对象在多个类别上的概率分布。所以,这个模型通常是很多高级模型的最后一步。
Softmax回归大致分为两步。
步骤1:将输入证据累加到某一类中。
步骤2:将证据转换成概率。
为了利用图片中各个像素点的信息,我们将图片中的各个像素点的值与一定的权值相乘并累加,权值的正负是有意义的,如果是正的,那么表示对应像素值(不为0)对表示该数字类别是正面的;否则,对应像素值(不为0)对表示该数字类别起负面作用。
图B-5是一个直观的例子,图片中蓝色表示正值,红色表示负值(蓝色区域的形状趋于数字形状)。

图 B-5 像素点对数字类别的权重
我们也需要加入一个额外的偏置量(bias),因为输入往往会带有一些无关的干扰量。
因此,对于给定的输入图片x,它代表的是数字 i 的证据可以表示为

其中,Wi,j代表权重;bi代表数字i类的偏置量;j代表给定图片x的像素索引用于像素求和。然后用softmax函数可以把这些证据转换成概率y。
y=softmax(evidence)
这里的softmax可以看成是一个激励(activation)函数或者链接(link)函数,把我们定义的线性函数的输出转换成我们想要的格式,也就是关于10个数字类的概率分布。
因此,给定一张图片,它对于每一个数字的吻合度可以被softmax函数转换成为一个概率值。softmax函数可以定义为softmax(x)=normalize(exp(x))
展开等式右边的子式,可以得到
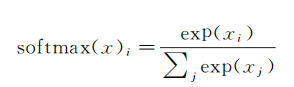
但是,更多的时候是把softmax模型函数定义为前一种形式:把输入值当成幂指数求值,再正则化这些结果值。这个幂运算表示,更大的证据对应更大的假设模型(hypothesis)里的乘数权重值。
反之,拥有更少的证据意味着在假设模型里拥有更小的乘数系数。假设模型里的权值不可以是0值或者负值。Softmax会正则化这些权重值,使它们的总和等于1,以此构造一个有效的概率分布。
softmax回归模型可以用图B-6解释。对于输入的x1,x2,x3加权求和,再分别加上一个偏置量,最后再输入到softmax函数中。
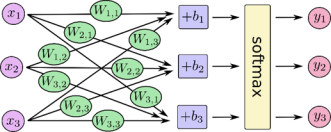
图 B-6 softmax函数的计算过程
如果将这个过程公式化,将得到
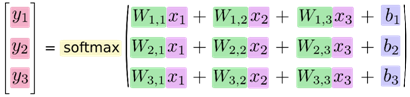
也可以用向量表示这个计算过程:用矩阵乘法和向量相加。这有助于提高计算效率。

进一步,可以写成更加紧凑的方式:
y=softmax(Wx+b)
03、Softmax回归的程序实现
为了用Python实现高效的数值计算,我们通常会使用函数库,如NumPy,会把类似矩阵乘法这样的复杂运算使用其他外部语言实现。但从外部计算切换回Python的每一个操作仍然是一个很大的开销。如果用GPU进行外部计算,这样的开销会更大。用分布式的计算方式也会花费更多的资源用来传输数据。
TensorFlow也把复杂的计算放在Python之外完成,但是为了避免前面说的那些开销,它做了进一步完善。TensorFlow不单独地运行单一的复杂计算,而是让我们可以先用图描述一系列可交互的计算操作,然后全部一起在Python之外运行。(这样类似的运行方式可以在不少的机器学习库中看到。)
使用TensorFlow之前,首先导入它:
import tensorflow as tf利用一些符号变量描述交互计算的过程,创建如下。
x =tf.placeholder(tf.float32, [None, 784])
x不是一个特定的值,而是一个占位符(placeholder),我们在TensorFlow运行计算时输入这个值。
我们希望能够输入任意数量的MNIST图像,每一张图展平成784维的向量。
我们用二维的浮点数张量表示这些图,这个张量的形状是None,784。
使用Variable(变量)表示模型中的权值和偏置,这些参数是可变的。具体如下。
W =tf.Variable(tf.zeros([784, 10]))
b =tf.Variable(tf.zeros([10]))
这里的W和b均被初始化为0值矩阵。W的维数为784×10,是因为我们需要将一个784维的像素值经过相应的权值之乘转换为10个类别上的证据值;b是十个类别上累加的偏置值。
实现softmax回归模型仅需要如下代码:
y =tf.nn.softmax(tf.matmul(x, W) +b)其中,matmul函数实现了x和W的乘积,这里的x为二维矩阵,所以放在前面。
可以看出,在TensorFlow中实现softmax回归模型很简单。
04、模型的训练
在机器学习中,通常需要选择一个代价函数(或者损失函数),指示训练模型的好坏。这里使用交叉熵函数(cross-entropy)作为代价函数,交叉熵是一个源于信息论中信息压缩领域的概念,但是现在已经应用在多个领域。
它的定义如下。

y是我们预测的概率分布;y'是实际的分布(我们输入的one-hotvector)。比较粗糙的理解是,交叉熵用来衡量我们的预测用于描述真相的低效性。
为了实现交叉熵函数,需要先设置一个占位符在存放图片的正确label值,
y_ =tf.placeholder(tf.float32, [None, 10])然后得到交叉熵,即

计算交叉熵:
cross_entropy =-tf.reduce_sum(y_*tf.log(y))注意,以上的交叉熵不局限于一张图片,而是整个可用的数据集。
接下来以代价函数最小化为目标训练模型,以得到相应的参数值(即权值和偏置)。
TensorFlow知道你的计算目标,它会自动利用反向传播算法得到相应的参数调整,并满足代价函数最小化的要求。
然后,可以选择一个优化算法决定如何最小化代价函数。具体代码如下:
train_step =tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)这里使用了一个学习率为0.01的梯度下降算法来最小化代价函数。梯度下降是一个简单的计算方式,即使得变量值朝着减小代价函数值的方向变化。
TensorFlow也提供了许多其他的优化算法,仅需要一行代码即可实现调用。
TensorFlow提供了以上简单抽象的函数调用功能,你不需要关心其底层实现,可以更加专心于整个计算流程。在模型训练之前,还需要对所有的参数进行初始化。
init =tf.initialize_all_variables()可以在一个Session里面运行模型,并且进行初始化。
sess =tf.Session()
sess.run(init)接下来进行模型的训练。
for i in range(1000): batch_xs,
batch_ys =mnist.train.next_batch(100)
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})在每一次的循环中,我们都取训练数据中的100个随机数据,这种操作称为批处理(batch)。然后,每次运行train_step时,将之前选择的数据填充至所设置的占位符中,作为模型的输入。
以上过程称为随机梯度下降,这里使用它是非常合适的。因为它既能保证运行效率,也能一定程度上保证程序运行的正确性(理论上,我们应该在每一次循环过程中利用所有的训练数据得到正确的梯度下降方向,但这样将非常耗时)。
05、模型的评价
怎样评价训练出来的模型?显然,可以用图片预测类别的准确率。
首先,利用tf.argmax()函数得到预测和实际的图片label值,再用一个tf.equal()函数判断预测值和真实值是否一致。代码如下。
correct_prediction =tf.equal(tf.argmax(y,1), tf.argmax(y_,1))correct_prediction是一个布尔值的列表,如[True,False,True,True]。可以使用tf.cast()函数将其转换为[1,0,1,1],以方便准确率的计算(以上的准确率为0.75)。
accuracy =tf.reduce_mean(tf.cast(correct_prediction, "float"))最后,获取模型在测试集上的准确率,代码如下。print(sess.run(accuracy, feed_dict= {x: mnist.test.images, y_: mnist.test. labels}))Softmax回归模型由于模型较简单,所以在测试集上的准确率在91%左右,这个结果并不算太好。
通过一些简单的优化,准确率可以达到97%,目前最好模型的准确率为99.7%。
06、完整代码及运行结果
利用Softmax模型实现手写体识别的完整代码如下。
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist =input_data.read_data_sets("MNIST_data/", one_hot=True)
print("Download Done!")
x =tf.placeholder(tf.float32, [None, 784])
#paras
W =tf.Variable(tf.zeros([784, 10]))
b =tf.Variable(tf.zeros([10]))
y =tf.nn.softmax(tf.matmul(x, W) +b)
y_ =tf.placeholder(tf.float32, [None, 10])
#loss func
cross_entropy =-tf.reduce_sum(y_ * tf.log(y))
train_step=tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)
#init
init =tf.initialize_all_variables()
sess =tf.Session()
sess.run(init)
#train
for i in range(1000):
batch_xs, batch_ys =mnist.train.next_batch(100)
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
correct_prediction =tf.equal(tf.arg_max(y, 1),tf.arg_max(y_, 1))
accuracy =tf.reduce_mean(tf.cast(correct_prediction, "float"))
print("Accuarcy on Test- dataset: ", sess.run(accuracy, feed_dict= {x: mnist. test.images, y_: mnist.test.labels}))运行结果如图B-7所示。
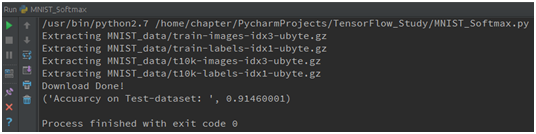图 B-7 运行结果

- 点赞
- 收藏
- 关注作者
评论(0)